





Course
Introduction to R
4 hr
3M
As you know by now, machine learning is a subfield in Computer Science (CS). Deep learning, then, is a subfield of machine learning that is a set of algorithms that is inspired by the structure and function of the brain and which is usually called Artificial Neural Networks (ANN). Deep learning is one of the hottest trends in machine learning at the moment, and there are many problems where deep learning shines, such as robotics, image recognition and Artificial Intelligence (AI).
Today’s tutorial will give you a short introduction to deep learning in R with Keras with the keras package:
Do you want to know more about the original Keras or critical concepts in deep learning such as perceptrons and Multi-Layer Perceptrons (MLPs)? Consider or taking DataCamp’s Deep Learning in Python course or doing the Keras Tutorial: Deep Learning in Python.
Tip: find our Keras cheat sheet here.
With the rise in popularity of deep learning, CRAN has been enriched with more R deep learning packages; Below you can see an overview of these packages, taken from the Machine Learning and Statistical Learning CRAN task view. The “Percentile” column indicates the percentile as found on RDocumentation:
| R Package | Percentile | Description |
|---|---|---|
| nnet | 96th | Software for feed-forward neural networks with a single hidden layer, and for multinomial log-linear models. |
| neuralnet | 96th | Training of neural networks using backpropagation |
| h2o | 95th | R scripting functionality for H2O |
| RSNNS | 88th | Interface to the Stuttgart Neural Network Simulator (SNNS) |
| tensorflow | 88th | Interface to TensorFlow |
| deepnet | 84th | Deep learning toolkit in R |
| darch | 79th | Package for Deep Architectures and Restricted Boltzmann Machines |
| rnn | 73rd | Package to implement Recurrent Neural Networks (RRNs) |
| FCNN4R | 52nd | Interface to the FCNN library that allows user-extensible ANNs |
| rcppDL | 7th | Implementation of basic machine learning methods with many layers (deep learning), including dA (Denoising Autoencoder), SdA (Stacked Denoising Autoencoder), RBM (Restricted Boltzmann machine) and DBN (Deep Belief Nets) |
| deepr | ??* | Package to streamline the training, fine-tuning and predicting processes for deep learning based on darch and deepnet |
| MXNetR | ??* | Package that brings flexible and efficient GPU computing and state-of-art deep learning to R |
Tip: for a comparison of deep learning packages in R, read this blog post. For more information on ranking and score in RDocumentation, check out this blog post.
The deepr and MXNetR were not found on RDocumentation.org, so the percentile is unknown for these two packages.
Recently, two new packages found their way to the R community: the kerasR package, which was authored and created by Taylor Arnold, and RStudio’s keras package.
Both packages provide an R interface to the Python deep learning package Keras, of which you might have already heard, or maybe you have even worked with it! For those of you who don’t know what the Keras package has to offer to Python users, it’s “a high-level neural networks API, written in Python and capable of running on top of either TensorFlow, Microsoft Cognitive Toolkit (CNTK) or Theano”.
You see, getting started with Keras is one of the easiest ways to get familiar with deep learning in Python, and that also explains why the kerasR and keras packages provide an interface for this fantastic package for R users.
In this case, it’s good for you to understand what it exactly means when a package, such as the R keras, is “an interface” to another package, the Python Keras. In simple terms, this means that the keras R package with the interface allows you to enjoy the benefit of R programming while having access to the capabilities of the Python Keras package.
Note that this is not an uncommon practice: for example, also the h2o package provides an interface, but in this case -and as the name kind of already suggests- to H2O, an open source math engine for big data that you can use to compute parallel distributed machine learning algorithms. Other packages that you might know that provide interfaces are RWeka (R interface to Weka), tensorflow (R interface to TensorFlow), openml-r (R interface to OpenML), … You can keep on going on and on!
Now that you know all of this, you might ask yourself the following question first: how would you compare the original Python package with the R packages?
In essence, you won’t find too many differences between the R packages and the original Python package, mostly because the function names are almost all the same; The only differences that you notice are mainly in the programming languages themselves (variable assignment, library loading, …), but the most important thing to notice lies in the fact of how much of the original functionality has been incorporated in the R package.
Note that this remark isn’t only valid for the keras library, but also for the tensorflow, openml-r, … and other interface packages that were mentioned above!
Secondly, you might also wonder what then the difference is between these two R packages. Well, if you want to consider how the two differ, you might want to consider the following points:
The keras package uses the pipe operator (%>%) to connect functions or operations together, while you won’t find this in kerasR: for example, to make your model with kerasR, you’ll see that you need to make use of the $ operator. The usage of the pipe operator generally improves the readability of your code, and you’ll have definitely seen this operator already if you’ve worked with Tidyverse packages before.
You’ll see that kerasR contains functions that are named in a similar, but not entirely the same way as the original Keras package. For example, the initial (Python) compile() function is called keras_compile(); The same holds for other functions, such as for instance fit(), which becomes keras_fit(), or predict(), which is keras_predict when you make use of the kerasR package. These are all custom wrappers.
You can argue that the installation of RStudio’s keras package is easier than the installation of the kerasR package; To get the latter installed, you need to first make sure that you configure which Python version to use and this can get tricky if you’re working on a pc that has multiple environments or Python versions installed. But I’ll leave you to decide on this :)

Now that you have gathered some background, it’s time to get started with Keras in R for real. As you will have read in the introduction of this tutorial, you’ll first go over the setup of your workspace. Then, you’ll load in some data and after a short data exploration and preprocessing step, you will be able to start constructing your MLP!
Let’s get on with it!
As always, the first step to getting started with any package is to set up your workspace: install and load in the library into RStudio or whichever environment you’re working in.
No worries, for this tutorial, the package will be loaded in for you!
First, make sure that you install the keras: you can easily do this by running devtools::install_github("rstudio/keras") in your console. Next, you can load in the package and install TensorFlow:
# Load in the keras package library(keras) # Install TensorFlow install_tensorflow()
When you have done this, you’re good to go! That’s fast, right?
Tip: for more information on the installation process, check out the package website.
Now that the installation process is transparent and your workspace is ready, you can start loading in your data! At this point, you have three big options when it comes to your data: you can pick to use one of the built-in datasets that comes with the keras package, you can load your own dataset from, for example, CSV files, or you can make some dummy data.
Whichever situation you’re in, you’ll see that you’ll be able to get started with the package quickly. This section will quickly go over the three options and explain how you can load (or create) in the data that you need to get started!
If you have some previous experience with the Keras package in Python, you probably will have already accessed the Keras built-in datasets with functions such as mnist.load_data(), cifar10.load_data(), or imdb.load_data().
Here are some examples where you load in the MNIST, CIFAR10 and IMDB data with the keras package:
# Read in MNIST data mnist <- dataset_mnist() # Read in CIFAR10 data cifar10 <- dataset_cifar10() # Read in IMDB data imdb <- dataset_imdb()
Note that all functions to load in built-in data sets with keras follow the same pattern; For MNIST data, you’ll use the dataset_mnist() function to load in your data.
Alternatively, you can also quickly make some dummy data to get started. You can easily use the matrix() function to accomplish this:
Note that it’s a good idea to check out the data structure of your data; It’s crucial to be already aware of what data you’re working with because it will be necessary for the later steps that you’ll need to take. You’ll learn more about this later on in the tutorial!
Besides the built-in datasets, you can also load in data from files. For this tutorial, you’ll focus on loading in data from CSV files, but if you want to know more about importing files in R, consider DataCamp’s R Data Import Tutorial.
Let’s use the read.csv() function from the read.table package to load in a data set from the UCI Machine Learning Repository:
It’s always a good idea to check out whether your data import was successful. You usually use functions such as head(), str() and dim() like in the DataCamp Light chunk above to quickly do this.
The results of these three functions do not immediately point out anything out of the ordinary; By looking at the output of the str() function, you see that the strings of the Species column are read in as factors. This is no problem, but it’s definitely good to know for the next steps, where you’re going to explore and preprocess the data.
For this tutorial, you’ll continue to work with the famous iris dataset that you imported with the read.csv() function.
For those of you who don’t have the biology knowledge that is needed to work with this data, here’s some background information: all flowers contain a sepal and a petal. The sepal encloses the petals and is typically green and leaf-like, while the petals generally are colored leaves. For the iris flowers, this is just a little bit different, as you can see in the following picture:

You might have already seen in the previous section that the iris data frame didn’t have any column names after the import. Now, for the remainder of the tutorial, that’s not too important: even though the read.csv() function returns the data in a data.frame to you, the data that you’ll need to pass to the fit() function needs to be a matrix or array.
Some things to keep in mind about these two data structures that were just mentioned: - Matrices and arrays don’t have column names; - Matrices are two-dimensional objects of a single data type; - Arrays are multi-dimensional objects of a single data type;
Tip: Check out this video if you want a recap of the data structures in R!
Note that the data frame, on the other hand, is a special kind of named list where all elements have the same length. It’s a multi-dimensional object that can contain multiple data types. You already saw that this is true when you checked out the structure of the iris data frame in the previous section. Knowing this and taking into account that you’ll need to work towards a two- or multi-dimensional object of a single data type, you should already prepare to do some preprocessing before you start building your neural network!
For now, column names can be handy for exploring purposes, and they will most definitely facilitate your understanding of the data, so let’s add some column names with the help of the names() function. Next, you can immediately use the iris variable in your data exploration! Plot, for example, how the petal length and the petal width correlate with the plot() function.
Note that you use the unclass() function to convert the names of the species, that is, “setosa, versicolor”, and “virginica”, to the numeric 1, 2, and 3.
Now take a closer look at the result of the plotting function:

The graph indicates a positive correlation between the Petal.Length and the Petal.Width for the different species of the iris flowers. However, this is something that you probably want to test with the cor() function, which will give you the overall correlation between all attributes that are included in the data set:
Additionally, you can use the corrplot package in combination with the cor() function to plot the correlations between your data’s attributes; In this case, you calculate the overall correlation for all attributes of the iris data frame. You store the result of this calculation in a variable M and pass it to the corrplot() function.
Also, don’t forget to specify a method argument to indicate how you want the data to be plotted!
You can further experiment with the visualization method in the DataCamp Light chunk below:

Make use of the R console to explore your data further.
If you want to make plots for this data with the ggvis package, which is the interactive grammar of graphics, take a look at DataCamp’s Machine Learning in R For Beginners tutorial or take DataCamp’s ggvis course.
Before you can build your model, you also need to make sure that your data is cleaned, normalized (if applicable) and divided into training and test sets. Since the dataset comes from the UCI Machine Learning Repository, you can expect it to already be somewhat clean, but let’s double check the quality of your data anyway.
At first sight, when you inspected the data with head(), you didn’t really see anything out of the ordinary, right? Let’s make use of summary() and str() to briefly recap what you learned when you checked whether the import of your data was successful:
Now that you’re sure that the data is clean enough, you can start by checking if the normalization is necessary for any of the data with which you’re working for this tutorial.
From the result of the summary() function in the DataCamp Light chunk above, you see that the Iris data set doesn’t need to be normalized: the Sepal.Length attribute has values that go from 4.3 to 7.9 and Sepal.Width contains values from 2 to 4.4, while Petal.Length’s values range from 1 to 6.9 and Petal.Width goes from 0.1 to 2.5. In other words, all values of all the attributes of the Iris data set are contained within the range of 0.1 and 7.9, which you can consider acceptable.
However, it can still be a good idea to study the effect of normalization on your data; You can even go as far as passing the normalized data to your model to see if there is any effect. This is outside the scope of this tutorial, but feel free to try it out on your own! The code is all here in this tutorial :)
You can make your own function to normalize the iris data; In this case, it’s a min-max normalization function, which linearly transforms your data to the function (x-min)/(max-min). From that perspective, translating this formula to R is pretty simple: you make a function to which you pass x or some data. You’ll then calculate the result of the first subtraction x-min and store the result in num. Next, you also calculate max-min and store the result in denom. The result of your normalize() function should return the division of num by max.
To apply this user-defined function on your iris data (target values excluded), you need to not only use normalize, but also the lapply() function to normalize the data, just like here below:
Tip use the hist() function in the R console to study the distribution of the Iris data before (iris) and after the normalization (iris_norm).
To use the normalize() function from the keras package, you first need to make sure that you’re working with a matrix. As you probably remember from earlier, the characteristic of matrices is that the matrix data elements are of the same basic type; In this case, you have target values that are of type factor, while the rest is all numeric.
This needs to change first.
You can use the as.numeric() function to convert the data to numbers:
A numerical data frame is alright, but you’ll need to convert the data to an array or a matrix if you want to make use of the keras package. You can easily do this with the as.matrix() function; Don’t forget here to set the dimnames to NULL.
As you might have read in the section above, normalizing the Iris data is not necessary. Nevertheless, it’s still a good idea to study normalization and its effect, and to see how this can not only be done with a UDF but also with the keras built-in normalize() function.
With your data converted to a matrix, you can indeed also use the keras package to study the effect of a possible normalization on your data:
Note that here, you use dimnames() to set the dimnames of iris to NULL. This ensures that there are no column names in your data.
Now that you have checked the quality of your data and you know that it’s not necessary to normalize your data, you can continue to work with the original data and split it into training and test sets so that you’re finally ready to start building your model. By doing this, you ensure that you can make honest assessments of the performance of your predicted model afterwards.
Before you split your data into training and test sets, you best first set a seed. You can easily do this with set.seed(): use this exact function and just pass a random integer to it. A seed is a number of R’s random number generator. The major advantage of setting a seed is that you can get the same sequence of random numbers whenever you supply the same seed in the random number generator.
This is great for the reproducibility of your code!
You use the sample() function to take a sample with a size that is set as the number of rows of the Iris data set, or 150. You sample with replacement: you choose from a vector of 2 elements and assign either 1 or 2 to the 150 rows of the Iris data set. The assignment of the elements is subject to probability weights of 0.67 and 0.33.
The replace argument of the sample() function is set to TRUE, which means that you assign a 1 or a 2 to a certain row and then reset the vector of 2 to its original state.
In other words, for the next rows in your data set, you can either assign a 1 or a 2, each time again. The probability of choosing a 1 or a 2 should not be proportional to the weights amongst the remaining items, so you specify probability weights.
Side note: if you would have used a built-in dataset with the specific dataset_imdb() function, for example, your data can easily be split by using the $ operator:
x_train <- imdb$train$x y_train <- imdb$train$y x_test <- imdb$test$x y_test <- imdb$test$y
You have successfully split your data, but there is still one step that you need to go through to start building your model. Can you guess which one?
When you want to model multi-class classification problems with neural networks, it is generally a good practice to make sure that you transform your target attribute from a vector that contains values for each class value to a matrix with a boolean for each class value and whether or not a given instance has that class value or not.
This is a loose explanation of One Hot Encoding (OHE). It sounds quite complex, doesn’t it?
Luckily, the keras package has a to_categorical() function that will do all of this for you; Pass in the iris.trainingtarget and the iris.testtarget to this function and store the result in iris.trainLabels and iris.testLabels:
Now you have officially reached the end of the exploration and preprocessing steps in this tutorial. You can now go on to building your neural network with keras!
To start constructing a model, you should first initialize a sequential model with the help of the keras_model_sequential() function. Then, you’re ready to start modeling.
However, before you begin, it’s a good idea to revisit your original question about this data set: can you predict the species of a certain Iris flower? It’s easier to work with numerical data, and you have preprocessed the data and one hot encoded the values of the target variable: a flower is either of type versicolor, setosa or virginica and this is reflected with binary 1 and 0 values.
A type of network that performs well on such a problem is a multi-layer perceptron. This type of neural network is often fully connected. That means that you’re looking to build a relatively simple stack of fully-connected layers to solve this problem. As for the activation functions that you will use, it’s best to use one of the most common ones here for the purpose of getting familiar with Keras and neural networks, which is the relu activation function. This rectifier activation function is used in a hidden layer, which is generally speaking a good practice.
In addition, you also see that the softmax activation function is used in the output layer. You do this because you want to make sure that the output values are in the range of 0 and 1 and may be used as predicted probabilities:
Note how the output layer creates 3 output values, one for each Iris class (versicolor, virginica or setosa). The first layer, which contains 8 hidden notes, on the other hand, has an input_shape of 4. This is because your training data iris.training has 4 columns.
You can further inspect your model with the following functions:
Now that you have set up the architecture of your model, it’s time to compile and fit the model to the data. To compile your model, you configure the model with the adam optimizer and the categorical_crossentropy loss function. Additionally, you also monitor the accuracy during the training by passing 'accuracy' to the metrics argument.
The optimizer and the loss are two arguments that are required if you want to compile the model.
Some of the most popular optimization algorithms used are the Stochastic Gradient Descent (SGD), ADAM and RMSprop. Depending on whichever algorithm you choose, you’ll need to tune certain parameters, such as learning rate or momentum. The choice for a loss function depends on the task that you have at hand: for example, for a regression problem, you’ll usually use the Mean Squared Error (MSE).
As you see in this example, you used categorical_crossentropy loss function for the multi-class classification problem of determining whether an iris is of type versicolor, virginica or setosa. However, note that if you would have had a binary-class classification problem, you should have made use of the binary_crossentropy loss function.
Next, you can also fit the model to your data; In this case, you train the model for 200 epochs or iterations over all the samples in iris.training and iris.trainLabels, in batches of 5 samples.
Tip if you want, you can also specify the verbose argument in the fit() function. By setting this argument to 1, you indicate that you want to see progress bar logging.
What you do with the code above is training the model for a specified number of epochs or exposures to the training dataset. An epoch is a single pass through the entire training set, followed by testing of the verification set. The batch size that you specify in the code above defines the number of samples that going to be propagated through the network. Also, by doing this, you optimize efficiency because you make sure that you don’t load too many input patterns into memory at the same time.
Also, it’s good to know that you can also visualize the fitting if you assign the lines of code in the DataCamp Light chunk above to a variable. You can then pass the variable to the plot() function, as you see in this particular code chunk!
Make sure to study the plot in more detail.
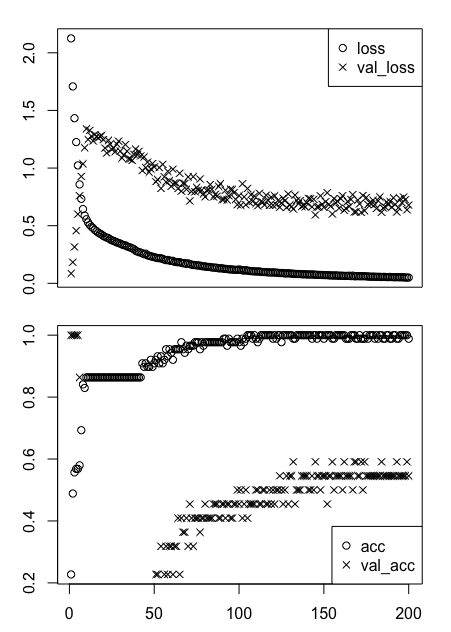
At first sight, it’s no surprise that this all looks a tad messy. You might not entirely know what you’re looking at, right?
One good thing to know is that the loss and acc indicate the loss and accuracy of the model for the training data, while the val_loss and val_acc are the same metrics, loss and accuracy, for the test or validation data.
But, even as you know this, it’s not easy to interpret these two graphs. Let’s try to break this up into pieces that you might understand more easily! You’ll split up these two plots and make two separate ones instead: you’ll make one for the model loss and another one for the model accuracy. Luckily, you can easily make use of the $ operator to access the data and plot it step by step.
Check out the DataCamp Light box below to see how you can do this:
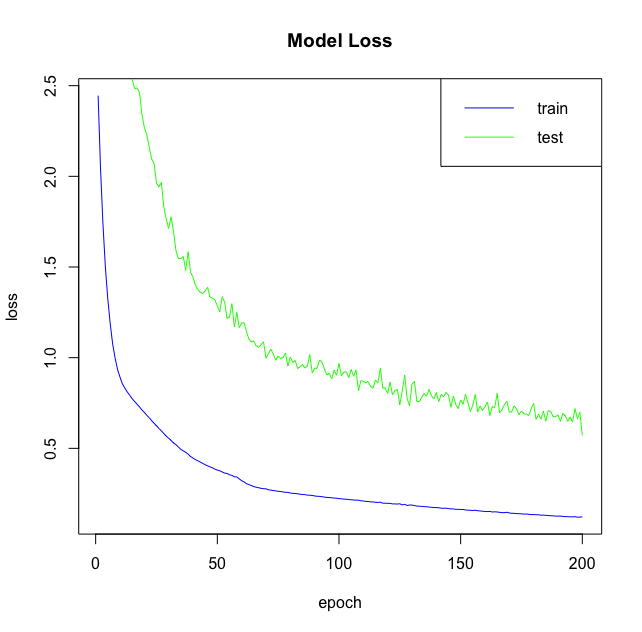
In this first plot, you plotted the loss of the model on the training and test data. Now it’s time to also do the same, but then for the accuracy of the model:
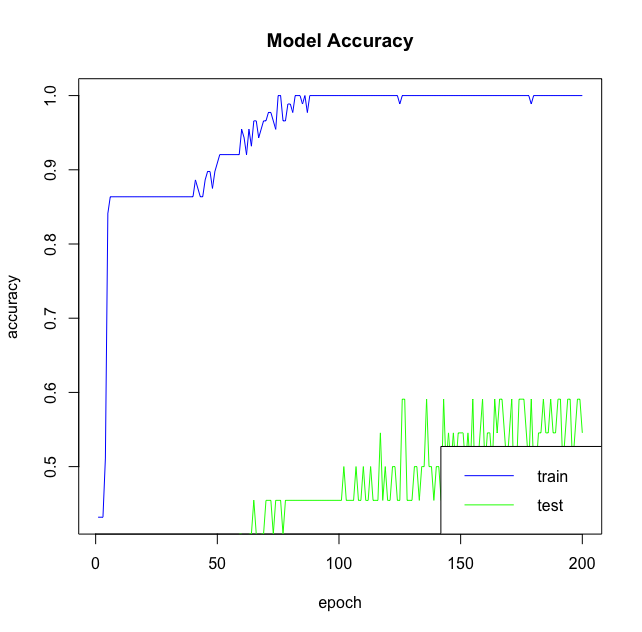
Some things to keep in mind here are the following:
Now that your model is created, compiled and has been fitted to the data, it’s time to actually use your model to predict the labels for your test set iris.test. As you might have expected, you can use the predict() function to do this. After, you can print out the confusion matrix to check out the predictions and the real labels of the iris.test data with the help of the table() function.
What do you think of the results? At first sight, does this model that you have created make the right predictions?
Even though you already have a slight idea of how your model performed by looking at the predicted labels for iris.test, it’s still important that you take the time to evaluate your model. Use the evaluate() function to do this: pass in the test data iris.test, the test labels iris.testLabels and define the batch size. Store the result in a variable score, like in the code example below:
By printing score, you’ll get back the loss value and the metric value (in this case 'accuracy') back.
Fine-tuning your model is probably something that you’ll be doing a lot, especially in the beginning, because not all classification and regression problems are as straightforward as the one that you saw in the first part of this tutorial. As you read above, there are already two key decisions that you’ll probably want to adjust: how many layers you’re going to use and how many “hidden units” you will choose for each layer.
In the beginning, this will really be quite a journey.
Besides playing around with the number of epochs or the batch size, there are other ways in which you can tweak your model in the hopes that it will perform better: by adding layers, by increasing the number of hidden units and by passing your own optimization parameters to the compile() function. This section will go over these three options.
What would happen if you add another layer to your model? What if it would look like this?
Note that you can also visualize the loss and accuracy metrics of this new model! Try this out in the DataCamp Light chunk below:
|
|
|
Besides adding layers and playing around with the hidden units, you can also try to adjust (some of) the parameters of the optimization algorithm that you give to the compile() function. Up until now, you have always passed a vector with a string, adam, to the optimizer argument.
But that doesn’t always need to be like this!
Also, try out experimenting with other optimization algorithms, like the Stochastic Gradient Descent (SGD). Try, for example, using the optimizer_sgd() function to adjust the learning rate lr. Do you notice an effect?
Besides using another optimizer, you can also try using a smaller learning rate to train your network. This is one of the most common fine-tuning techniques; A common practice is to make the initial learning rate 10 times smaller than the one that you used to train the model before.
Let’s visualize the training history one more time to see the effect of this small adjustment:
|
|
|
There is one last thing that remains in your journey with the keras package and that is saving or exporting your model so that you can load it back in at another moment.
save_model_hdf5(model, "my_model.h5")
model <- load_model_hdf5("my_model.h5")
save_model_weights_hdf5("my_model_weights.h5")
model %>% load_model_weights_hdf5("my_model_weights.h5")
json_string <- model_to_json(model) model <- model_from_json(json_string) yaml_string <- model_to_yaml(model) model <- model_from_yaml(yaml_string)

Congrats! You’ve made it through this deep learning tutorial in R with keras. This tutorial was just one small step in your deep learning journey with R; There’s much more to cover! If you haven’t taken DataCamp’s Deep Learning in Python course, you might consider doing so.
In the meantime, also make sure to check out the Keras documentation and the RStudio keras documentation if you haven’t done so already. You’ll find more examples and information on all functions, arguments, more layers, etc… Also, check out François Chollet’s book “Deep Learning with Python”. All these resources will undoubtedly be indispensable in learning how to work with neural networks in R!
Related courses
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Karlijn Willems
Tutorial
Karlijn Willems
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Ryan Sheehy