programa
Fundamentos de la IA
10 h
Databricks ha presentado recientemente DBRX, su gran modelo de lenguaje (LLM) abierto de propósito general, construido sobre una arquitectura de mezcla de expertos (MoE) con un enfoque de grano fino. En lugar de utilizar una única red neuronal para todas las tareas, el sistema consta de múltiples redes "expertas" especializadas, cada una optimizada para distintos tipos de tareas o datos.
Este modelo ha funcionado mejor que los LLM tradicionales, como GPT-3.5 y Llama 2, porque es más rápido y rentable. Según las pruebas, el DBRX obtiene una puntuación del 73,7%, superior a la del LLaMa2 (69,8%) en las tareas de comprensión lingüística.
En este artículo hablaremos con más detalle de sus posibilidades y de cómo empezar a utilizar Databricsk DBRX.
El DBRX utiliza una arquitectura de sólo descodificador basada en transformadores, entrenada mediante la predicción del siguiente token. Emplea una arquitectura de mezcla de expertos (MDE) de grano fino. Estos "expertos" se refieren a agentes especializados basados en LLM, mejorados con conocimientos específicos del dominio y habilidades de razonamiento.
DBRX tiene un gran número de expertos más pequeños (16 expertos en total) y elige un subconjunto de ellos (4 expertos) para cualquier entrada dada.
En pocas palabras, este enfoque de grano fino con 65 veces más combinaciones posibles de expertos mejora la calidad del modelo en comparación con otros modelos abiertos de ME como Mixtral y Grok-1, que tienen menos expertos y eligen menos expertos por entrada.
Aquí tienes algunos detalles clave sobre el DBRX:
El modelo se preentrenó en un conjunto de datos impresionantemente grande, que se calcula que es el doble de eficaz que los conjuntos de datos anteriores utilizados por Databricks. Para entrenar el modelo se utilizó un conjunto de herramientas Databricks, como Apache Spark y los cuadernos Databricks para el procesamiento de datos y Unity Catalog para el gobierno de datos.
Durante su formación, se empleó el aprendizaje curricular y se modificó la mezcla de datos para mejorar sustancialmente la calidad del modelo. Tales alteraciones estratégicas en la mezcla de datos de entrenamiento optimizaron la capacidad del modelo para manejar diversas entradas con eficacia.
Algunas de las tecnologías clave utilizadas para la formación previa de DBRX son:
Databricks afirma que su modelo DBRX es superior a varios de los principales modelos de código abierto en términos de eficacia y rendimiento de las tareas.
Aquí tienes una comparación detallada de cómo se compara el DBRX con sus competidores:
A continuación, hemos recopilado las comparaciones en una tabla y mostrado un gráfico basado en algunos de los resultados:
|
Model Comparison |
Conocimientos generales |
Razonamiento de sentido común |
Guantelete Databricks |
Programación Razonamiento |
Razonamiento matemático |
|
DBRX vs LLaMA2-70B |
+9.8% |
+3.1% |
+14% |
+37.9% |
+40.2% |
|
DBRX vs Mixtral Instruct |
+2.3% |
+1.4% |
+6.1% |
+15.3% |
+5.8% |
|
DBRX vs Grok-1 |
+0.7% |
No disponible |
No disponible |
+6.9% |
+4% |
|
DBRX vs Base Mixtral |
+1.8% |
+2.5% |
+10% |
+29.9% |
No disponible |
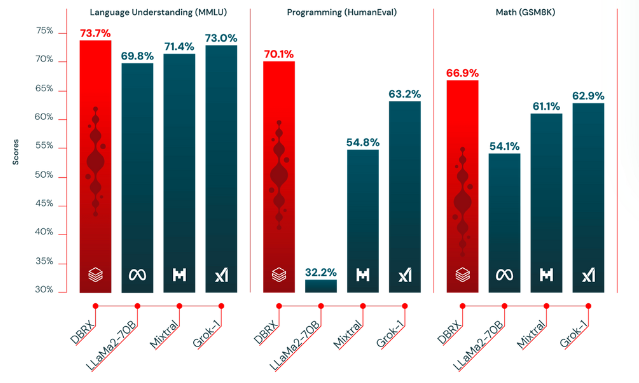
Comparación de la calidad de DBRX con otros LLM de código abierto - fuente
Antes de acceder al DBRX, asegúrate de que tu sistema tiene al menos 320 GB de memoria. A continuación, sigue estos pasos para acceder al DBRX:
transformers pip install "transformers>=4.40.0"from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-base", token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-base", device_map="auto", torch_dtype=torch.bfloat16, token="hf_YOUR_TOKEN")
# Directing tensors to "cuda" (GPU) for faster computation as GPUs are better at handling parallel tasks.
input_text = "Databricks was founded in "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
# DBRX accepts a context length of up to 32768 tokens. Here`max_new_tokens` specifies the maximum number of tokens to generate.
outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))¿Quieres aprender a utilizar Transformers y Cara de Abrazo? Lee nuestro tutorial sobre el uso de Transformadores y Cara de Abrazo.
DRBX puede ayudarte con tareas básicas de creación de contenidos y respuesta rápida como cualquier LLM. Esto es lo que puedes hacer con el DBRX:
El DBRX también puede realizar tareas avanzadas relacionadas con la codificación para ayudar a los profesionales o codificadores de datos:

DBRX respondiendo a comandos simples - fuente
Puedes ajustar DBRX con la fundición LLM de código abierto de Github. Sin embargo, el ajuste fino requiere que los ejemplos de entrenamiento se formateen como diccionarios:
formatted_example = {'prompt': <prompt_text>, 'response': <response_text>}Prompt: Es la pregunta o instrucción inicial que das al modelo.
Respuesta: Esta es la respuesta que el modelo está entrenado para generar.
Puedes utilizar tres conjuntos de datos diferentes para afinar cualquier LLM:
Si quieres afinar utilizando un conjunto de datos del Hub HuggingFace, y la función
conjunto de datos tiene una función de preprocesamiento predefinida o ya sigue la
formato "pregunta"/"respuesta", puedes simplemente dirigir el cargador de datos a ese conjunto de datos.
train_loader:
name: finetuning
dataset:
hf_name: tatsu-lab/alpaca
split: train
...Si no se define ninguna función de preprocesamiento, utiliza preprocessing_fn para especificar una función de preprocesamiento personalizada para el cargador de datos.
train_loader:
name: finetuning
dataset:
hf_name: mosaicml/doge-facts
preprocessing_fn: my_data.formatting:dogefacts_prep_fn
split: train
...
Si ya tienes un conjunto de datos de ajuste fino en tu dispositivo, define archivos JSONL locales en
la configuración YAML yamls/finetune/1b_local_data_sft.yaml.
train_loader:
name: finetuning
dataset:
hf_name: json # assuming data files are json formatted
hf_kwargs:
data_dir: /path/to/data/dir/
preprocessing_fn: my.import.path:my_preprocessing_fn
split: train
...
Omite preprocessing_fn si tus datos locales ya están en formato "pregunta"/"respuesta".
Convierte tu conjunto de datos HuggingFace al formato MDS utilizando la función
convert_finetuning_dataset.py guión.
Después de convertir tu conjunto de datos HuggingFace a un formato de flujo, sólo tienes que ajustar tu configuración YAML de la siguiente manera.
train_loader:
name: finetuning
dataset:
remote: s3://my-bucket/my-copy-doge-facts
local: /tmp/mds-cache/
split: train
...
Si quieres ver el ajuste completo de los parámetros, consulta la configuración YAML en
Databricks DBRX utiliza múltiples redes especializadas para mejorar la velocidad y la rentabilidad del modelo. Este enfoque de grano fino le permite superar a otros LLM en el manejo de tareas complejas.
¿Quieres saber más sobre los grandes modelos lingüísticos y cómo afinarlos? Consulta estos recursos:
¡Continúa hoy tu viaje por la IA!
programa
Curso
Curso
blog
Abid Ali Awan
7 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer


