programa
Fundamentos de la IA
10 h
En el campo en rápida evolución de los grandes modelos lingüísticos (LLM), es crucial mantenerse al día de los enfoques más avanzados, como el ajuste rápido. Esta técnica, aplicada a modelos fundacionales ya entrenados, mejora el rendimiento sin los elevados costes computacionales asociados al entrenamiento tradicional de modelos.
En este artículo, exploraremos los fundamentos del ajuste rápido, lo compararemos con el ajuste fino y la ingeniería rápida, y discutiremos sus importantes ventajas. También ofreceremos un ejemplo práctico utilizando la plataforma de HuggingFace, en el que pondremos a punto un modelo bloomz-560m. Esta guía pretende profundizar en tu comprensión del ajuste rápido e inspirar su integración en tus proyectos.
La sintonización de pronósticos es una técnica diseñada para mejorar el rendimiento de un modelo lingüístico preentrenado sin alterar su arquitectura central. En lugar de modificar los pesos estructurales profundos del modelo, el ajuste de las indicaciones ajusta las indicaciones que guían la respuesta del modelo. Este método se basa en la introducción de "indicaciones suaves", un conjunto de parámetros sintonizables insertados al principio de la secuencia de entrada.
Fuente de la imagen
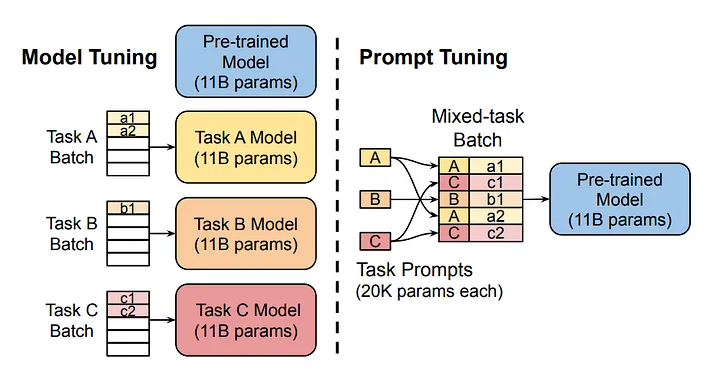
El diagrama compara el enfoque tradicional de ajuste del modelo con el ajuste rápido. Observa que en el ajuste de modelos, cada tarea requiere un modelo distinto. Por otro lado, el ajuste de las indicaciones utiliza el mismo modelo básico en varias tareas ajustando las indicaciones específicas de cada tarea.
Las indicaciones suaves son fichas construidas artificialmente que se añaden a la secuencia de entrada del modelo. Estas indicaciones se pueden inicializar de varias formas. La inicialización aleatoria es habitual, aunque también se pueden inicializar basándose en ciertas heurísticas. Una vez inicializados, los avisos suaves se adjuntan al inicio de los datos de entrada. Cuando el modelo procesa estos datos, tiene en cuenta tanto las indicaciones suaves como la entrada real.
El proceso de entrenamiento suele ser similar al del entrenamiento de una red neuronal profunda (DNN) estándar. Comienza con un paso hacia delante en el que el modelo procesa la entrada combinada a través de sus capas, produciendo una salida. A continuación, este resultado se evalúa con respecto al resultado deseado mediante una función de pérdida, que mide la discrepancia entre el resultado del modelo y el valor real esperado.
Durante la retropropagación, los errores se propagan hacia atrás a través de la red. Sin embargo, en lugar de ajustar los pesos de la red, sólo modificamos los parámetros de prontitud suave. Este proceso se repite a lo largo de varias épocas, en las que las indicaciones suaves aprenden gradualmente a moldear el procesamiento de las entradas por parte del modelo de forma que se minimice el error de la tarea en cuestión.
El proceso de paso hacia delante, evaluación de pérdidas y retropropagación se repite en varias épocas. Con el tiempo, estas indicaciones suaves aprenden a moldear la entrada de forma que se reduzca sistemáticamente la puntuación de pérdida, mejorando así el rendimiento específico de la tarea del modelo sin comprometer sus capacidades subyacentes.
La sintonización de pronósticos, la sintonización fina y la ingeniería de pronósticos son tres métodos distintos que se aplican a los LLM preentrenados para mejorar su rendimiento en una tarea específica. Estos métodos no se excluyen mutuamente y cada uno es adecuado para un caso de uso concreto.
El ajuste fino es el que consume más recursos, ya que implica un reentrenamiento exhaustivo del modelo en un conjunto de datos específico para un fin concreto. Esto ajusta los pesos del modelo preentrenado, optimizándolo para los matices detallados de los datos, pero requiere importantes recursos informáticos y aumenta el riesgo de sobreajuste. Muchos LLM, como Chat GPT, se someten a un ajuste fino tras su entrenamiento genérico inicial en la siguiente tarea de predicción de palabras. El ajuste fino enseña a estos modelos a funcionar como asistentes digitales, haciéndolos mucho más útiles que un modelo entrenado de forma general.
La sintonización de avisos ajusta un conjunto de parámetros adicionales, conocidos como "avisos suaves", que se integran en el procesamiento de entrada del modelo. Este método modifica la forma en que el modelo interpreta las indicaciones de entrada sin una revisión completa de sus ponderaciones, ofreciendo un equilibrio entre la mejora del rendimiento y la eficiencia de los recursos. Es especialmente valioso cuando los recursos informáticos son limitados o cuando se requiere flexibilidad en múltiples tareas, porque tras aplicar la técnica las ponderaciones originales del modelo permanecen inalteradas.
La ingeniería rápida, en cambio, no implica formación ni reciclaje en absoluto. Se basa completamente en que el usuario diseñe indicaciones para el modelo. Requiere una comprensión matizada de las capacidades de procesamiento del modelo y aprovecha el conocimiento intrínseco incorporado en él. La ingeniería rápida no requiere ningún recurso computacional, ya que se basa únicamente en la formulación estratégica de las entradas para obtener resultados. Consulta el curso de DataCamp sobre ingeniería rápida para desarrolladores para saber más.
Cada una de estas técnicas ofrece un enfoque diferente para aprovechar las capacidades de los modelos preentrenados. La elección entre ellos depende de las necesidades específicas de la aplicación, como la disponibilidad de recursos informáticos, el requisito de personalización del modelo y el nivel deseado de interacción con los parámetros de aprendizaje del modelo.
|
Método |
Intensidad de recursos |
Formación necesaria |
Lo mejor para |
|
Ajuste fino |
Alta |
Sí |
Tareas que requieren una profunda personalización del modelo |
|
Ajuste rápido |
Baja |
Sí |
Mantener la integridad del modelo en todas las tareas |
|
Ingeniería rápida |
Ninguno |
No |
Adaptaciones rápidas sin coste computacional. |
Cada método tiene su lugar en función de las necesidades específicas de tu proyecto.
El ajuste rápido aporta varias ventajas clave, lo que lo convierte en una técnica indispensable para optimizar grandes modelos lingüísticos.
El ajuste rápido mantiene inalterados los parámetros del modelo preentrenado, reduciendo significativamente la potencia de cálculo necesaria. Esta eficacia es especialmente crucial en entornos con recursos limitados, ya que permite el uso de modelos sofisticados sin su elevado coste. A medida que aumenta el tamaño medio de los modelos fundacionales, "congelar" los parámetros del modelo resulta aún más atractivo, ya que no es necesario desplegar un modelo distinto para cada tarea.
A diferencia de la sintonización fina global, la sintonización de avisos sólo requiere ajustes en un pequeño conjunto de parámetros de avisos suaves. Esto acelera el proceso de adaptación, permitiendo transiciones más rápidas entre diferentes tareas y reduciendo el tiempo de inactividad.
Al mantener intactos la arquitectura central y los pesos del modelo, el ajuste rápido conserva las capacidades y conocimientos originales incorporados al modelo preentrenado. Esto es fundamental para mantener la fiabilidad y la generalizabilidad del modelo en diversas aplicaciones.
El ajuste de las instrucciones facilita el uso de un único modelo básico para múltiples tareas, simplemente cambiando las instrucciones suaves. Este enfoque reduce la necesidad de entrenar y mantener modelos separados para cada tarea específica, mejorando la escalabilidad y la simplicidad en la gestión de modelos.
El ajuste de los avisos requiere mucha menos intervención humana que la ingeniería de avisos, en la que la elaboración cuidadosa de avisos que se adapten a una tarea concreta puede ser propensa a errores y requerir mucho tiempo. En cambio, la optimización automatizada de las indicaciones suaves durante el entrenamiento minimiza el error humano y maximiza la eficacia.
Las investigaciones indican que, para los modelos grandes, el ajuste rápido puede alcanzar niveles de rendimiento comparables a los del ajuste fino. Esta ventaja se hace cada vez más significativa a medida que aumenta el tamaño de los modelos, combinando una gran eficacia con unos resultados sólidos.
Para esta guía, aplicaremos el ajuste rápido al modelo bloomz-560m de BigScience. Trabajaremos dentro del ecosistema Cara Abrazada utilizando la biblioteca PEFT (Parameter-Efficient Fine-Tuning).
Aunque aquí nos centraremos en la tarea de modelado causal del lenguaje, la biblioteca PEFT admite varias tareas, modelos y técnicas de ajuste. Puedes encontrar métodos PEFT compatibles para otros modelos y tareas en la página de documentación de PEFT.
Para empezar, cargamos el modelo y el tokenizador del modelo bloomz-560m de BigScience. El tokenizador se utiliza para procesar las entradas de texto, mientras que el modelo fundacional se encarga de las tareas de modelado causal del lenguaje. El parámetro trust_remote_code=True te permite utilizar código personalizado proporcionado por los mantenedores del modelo para arquitecturas específicas.
Aunque esto es útil para obtener una funcionalidad completa, sólo confía en el código del modelo si procede de una fuente acreditada. Evita utilizar código no fiable para modelos de creadores desconocidos o no verificados, ya que puede plantear riesgos de seguridad o estabilidad.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloomz-560m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)Antes de cualquier ajuste, es esencial establecer una línea de base ejecutando la inferencia con el modelo fundacional sin ajustar. Utilizando una indicación como "Quiero que actúes como un logista", podemos observar cómo el modelo genera respuestas sin necesidad de afinar más. Asegúrate de incluir un espacio extra después de la indicación, de lo contrario el modelo podría no generar nada.
Esto sirve de referencia para comparar las mejoras tras el ajuste.
Utilizaremos una función personalizada de generate_text para facilitarnos la vida.
def generate_text(model, tokenizer, prompt_text, max_tokens):
prompt_text = tokenizer(prompt_text, return_tensors="pt")
outputs = model.generate(
input_ids=prompt_text["input_ids"],
attention_mask=prompt_text["attention_mask"],
max_length=max_tokens,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
initial_output = generate_text(model, tokenizer, "I want you to act as a logistician. ", 100)
print("Initial model output:", initial_output)Este es el resultado del modelo:
['I want you to act as a logistician. You will be able to: Analyze the data']
Como puedes ver, el modelo no está muy seguro del contexto.
El conjunto de datos es un elemento crucial del ajuste rápido. Utilizamos el conjunto de datos `awesome-chatgpt-prompts` para el ajuste. Este conjunto de datos proporciona contenido motivador para el ajuste, asegurando que el modelo adapte sus respuestas en consecuencia.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda x: tokenizer(x["prompt"]), batched=True)
train_prompts = data_prompt["train"].select(range(50))Tokenizamos el conjunto de datos y preparamos un pequeño subconjunto para el entrenamiento.
Ahora, la parte más interesante; configuramos la sintonización del aviso utilizando la clase PromptTuningConfig de la biblioteca PEFT.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
tuning_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=4, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name
)
peft_model = get_peft_model(model, tuning_config)Los argumentos de entrenamiento se especifican utilizando la clase TrainingArguments.
from transformers import TrainingArguments
training_args = TrainingArguments(
use_cpu=True, # This is necessary for CPU clusters.
output_dir = "./",
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically, you can also use a custom batch size
learning_rate= 0.005,
num_train_epochs=5
)Un objeto Trainer gestiona el proceso de entrenamiento. Con DataCollatorForLanguageModeling, el recopilador de datos se asegura de que las muestras de entrenamiento tengan el formato adecuado. La fase de entrenamiento se inicia con el método train, afinando el modelo bloomz-560m para las tareas puntuales específicas.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_prompts, #The dataset used to train the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
trainer.train()El modelo sintonizado se almacena en el objeto entrenador, podemos utilizar trainer.model para acceder a él. ¡Utilizamos la función generate_text para ejecutar la inferencia con el modelo sintonizado!
tuned_output = generate_text(trainer.model, tokenizer, "I want you to act as a logistician. ", 100)
print("Tuned model output:", tuned_output)Aquí tienes el resultado del modelo sintonizado:
['I want you to act as a logistician. You will be responsible for the logistics of your business.']
Como puedes ver ahora, el modelo sabe lo que hace el logístico. Siéntete libre de experimentar con diferentes preguntas, modelos y conjuntos de datos.
La sintonización de pronósticos es una potente herramienta para hacer que los grandes modelos lingüísticos sean más eficientes en una tarea específica. Hemos explorado la sintonización rápida explicando primero qué es y cómo funciona. Luego lo comparamos con otras técnicas similares: el ajuste fino y la ingeniería rápida. Por último, discutimos sus ventajas y seguimos una guía paso a paso para aplicar el ajuste rápido a un modelo preentrenado.
Como el campo de la IA generativa sigue evolucionando, es importante mantenerse al día de los últimos avances. Para mejorar aún más tus habilidades y tu comprensión de la IA, Datacamp ofrece una variedad de recursos en profundidad. Te animo a que explores estos completos tutoriales:
Sigue aprendiendo con DataCamp
programa
Curso
Curso
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze

