Programa
Fundamentos da IA
10 h
No campo de rápida evolução dos modelos de linguagem de grande porte (LLMs), é fundamental manter-se atualizado sobre as abordagens mais modernas, como o ajuste rápido. Essa técnica, aplicada a modelos básicos já treinados, melhora o desempenho sem os altos custos computacionais associados ao treinamento tradicional de modelos.
Neste artigo, exploraremos os fundamentos do ajuste imediato, comparando-o com o ajuste fino e a engenharia imediata, e discutiremos seus benefícios significativos. Também forneceremos um exemplo prático utilizando a plataforma da HuggingFace, em que ajustamos o Prompt em um modelo bloomz-560m. Este guia tem o objetivo de aprofundar sua compreensão sobre o ajuste de prompt e inspirar sua integração em seus projetos.
O ajuste de prompt é uma técnica projetada para melhorar o desempenho de um modelo de linguagem pré-treinado sem alterar sua arquitetura principal. Em vez de modificar os pesos estruturais profundos do modelo, o ajuste do prompt ajusta os prompts que orientam a resposta do modelo. Esse método baseia-se na introdução de "soft prompts", um conjunto de parâmetros ajustáveis inseridos no início da sequência de entrada.
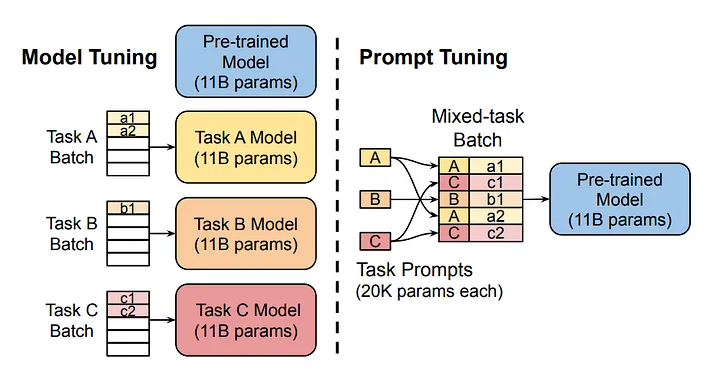
Fonte da imagem
O diagrama compara a abordagem tradicional de ajuste de modelo com o ajuste imediato. Observe que, no ajuste de modelos, cada tarefa requer um modelo separado. Por outro lado, o ajuste do prompt utiliza o mesmo modelo básico em várias tarefas, ajustando os prompts específicos da tarefa.
Os soft prompts são tokens construídos artificialmente que são adicionados à sequência de entrada do modelo. Esses prompts podem ser inicializados de várias maneiras. A inicialização aleatória é comum, mas eles também podem ser inicializados com base em determinadas heurísticas. Depois de inicializados, os prompts de software são anexados ao início dos dados de entrada. Quando o modelo processa esses dados, ele considera tanto os prompts flexíveis quanto a entrada real.
O processo de treinamento geralmente é semelhante ao treinamento de uma rede neural profunda (DNN) padrão. Ele começa com uma passagem direta em que o modelo processa a entrada combinada por meio de suas camadas, produzindo uma saída. Esse resultado é então avaliado em relação ao resultado desejado usando uma função de perda, que mede a discrepância entre o resultado do modelo e o valor real esperado.
Durante a retropropagação, os erros são propagados de volta pela rede. No entanto, em vez de ajustar os pesos da rede, modificamos apenas os parâmetros do soft prompt. Esse processo se repete em várias épocas, com os avisos suaves aprendendo gradualmente a moldar o processamento de entradas do modelo de forma a minimizar o erro para a tarefa em questão.
O processo de passagem para frente, avaliação de perda e retropropagação é repetido em várias épocas. Com o passar do tempo, esses avisos suaves aprendem a moldar a entrada de forma a reduzir consistentemente a pontuação de perda, melhorando assim o desempenho específico da tarefa do modelo sem comprometer seus recursos subjacentes.
O ajuste de prompt, o ajuste fino e a engenharia de prompt são três métodos distintos aplicados a LLMs pré-treinados para melhorar seu desempenho em uma tarefa específica. Esses métodos não são mutuamente exclusivos e cada um é adequado a um caso de uso específico.
O ajuste fino é o que consome mais recursos, envolvendo um retreinamento abrangente do modelo em um conjunto de dados específico para uma finalidade específica. Isso ajusta os pesos do modelo pré-treinado, otimizando-o para as nuances detalhadas dos dados, mas exigindo recursos computacionais substanciais e aumentando o risco de ajuste excessivo. Muitos LLMs, como o Chat GPT, passam por um ajuste fino após o treinamento genérico inicial na próxima tarefa de previsão de palavras. O ajuste fino ensina esses modelos a funcionar como assistentes digitais, tornando-os significativamente mais úteis do que um modelo treinado em geral.
O ajuste de prompts ajusta um conjunto de parâmetros extras, conhecidos como "soft prompts", que são integrados ao processamento de entrada do modelo. Esse método modifica a forma como o modelo interpreta os avisos de entrada sem uma revisão completa de seus pesos, oferecendo um equilíbrio entre o aprimoramento do desempenho e a eficiência dos recursos. Ela é particularmente valiosa quando os recursos de computação são limitados ou quando é necessária flexibilidade em várias tarefas, pois, após a aplicação da técnica, os pesos do modelo original permanecem inalterados.
A engenharia imediata, por outro lado, não envolve nenhum tipo de treinamento ou reciclagem. Ele se baseia totalmente nos prompts de design do usuário para o modelo. Isso requer uma compreensão diferenciada dos recursos de processamento do modelo e aproveita o conhecimento intrínseco incorporado ao modelo. A engenharia imediata não requer recursos computacionais, pois depende apenas da formulação estratégica de entradas para obter resultados. Para que você saiba mais, confira o curso da DataCamp sobre engenharia de prompt para desenvolvedores.
Cada uma dessas técnicas oferece uma abordagem diferente para aproveitar os recursos dos modelos pré-treinados. A escolha entre eles depende das necessidades específicas do aplicativo, como a disponibilidade de recursos computacionais, o requisito de personalização do modelo e o nível desejado de interação com os parâmetros de aprendizado do modelo.
|
Método |
Intensidade de recursos |
Treinamento necessário |
Melhor para |
|
Ajuste fino |
Alta |
Sim |
Tarefas que exigem personalização profunda do modelo |
|
Ajuste do prompt |
Baixa |
Sim |
Manter a integridade do modelo em todas as tarefas |
|
Engenharia imediata |
Nenhum |
Não |
Adaptações rápidas sem custo computacional. |
Cada método tem seu lugar, dependendo das necessidades específicas do seu projeto.
O ajuste de prompt traz vários benefícios importantes para a tabela, tornando-o uma técnica indispensável para otimizar grandes modelos de linguagem.
O ajuste imediato mantém os parâmetros do modelo pré-treinado inalterados, reduzindo significativamente a potência computacional necessária. Essa eficiência é especialmente importante em ambientes com recursos limitados, permitindo o uso de modelos sofisticados sem o alto custo. À medida que o tamanho médio dos modelos básicos aumenta, o "congelamento" dos parâmetros do modelo se torna ainda mais atraente, pois não é necessário implantar um modelo separado para cada tarefa.
Ao contrário do ajuste fino abrangente, o ajuste do prompt requer ajustes apenas em um pequeno conjunto de parâmetros do prompt suave. Isso acelera o processo de adaptação, permitindo transições mais rápidas entre diferentes tarefas e reduzindo o tempo de inatividade.
Ao manter a arquitetura central e os pesos do modelo intactos, o ajuste imediato preserva os recursos originais e o conhecimento incorporado no modelo pré-treinado. Isso é fundamental para manter a confiabilidade e a generalização do modelo em vários aplicativos.
O ajuste de prompts facilita o uso de um único modelo básico para várias tarefas, bastando que você altere os prompts flexíveis. Essa abordagem reduz a necessidade de treinar e manter modelos separados para cada tarefa específica, aumentando a escalabilidade e a simplicidade do gerenciamento de modelos.
O ajuste de prompts exige muito menos intervenção humana do que a engenharia de prompts, em que a elaboração cuidadosa de prompts para atender a uma tarefa específica pode ser propensa a erros e consumir muito tempo. Em vez disso, a otimização automatizada de prompts flexíveis durante o treinamento minimiza o erro humano e maximiza a eficiência.
Pesquisas indicam que, para modelos grandes, o ajuste imediato pode atingir níveis de desempenho comparáveis aos do ajuste fino. Esse benefício se torna cada vez mais significativo à medida que o tamanho dos modelos aumenta, combinando alta eficiência com resultados sólidos.
Para este guia, aplicaremos o ajuste imediato ao modelo bloomz-560m da BigScience. Trabalharemos no ecossistema Hugging Face usando a biblioteca PEFT (Parameter-Efficient Fine-Tuning).
Embora aqui nos concentremos na tarefa de modelagem de linguagem causal, a biblioteca PEFT oferece suporte a várias tarefas, modelos e técnicas de ajuste. Você pode encontrar métodos PEFT compatíveis para outros modelos e tarefas na página de documentação do PEFT.
Para começar, carregamos o modelo e o tokenizador do modelo bloomz-560m do BigScience. O tokenizador é usado para processar entradas de texto, enquanto o modelo básico lida com tarefas de modelagem de linguagem causal. O parâmetro trust_remote_code=True permite que você use o código personalizado fornecido pelos mantenedores do modelo para arquiteturas específicas.
Embora isso seja útil para obter funcionalidade total, você só deve confiar no código do modelo se ele for de uma fonte confiável. Evite usar código não confiável para modelos de criadores desconhecidos ou não verificados, pois isso pode representar riscos de segurança ou estabilidade.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloomz-560m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)Antes de qualquer ajuste, é essencial estabelecer uma linha de base executando a inferência com o modelo básico não ajustado. Usando um prompt do tipo "Quero que você atue como um especialista em logística", podemos observar como o modelo gera respostas sem ajustes adicionais. Certifique-se de incluir um espaço extra após o prompt, caso contrário, o modelo poderá não gerar nada.
Isso serve como referência para comparar as melhorias após o ajuste.
Usaremos uma função generate_text personalizada para facilitar nossa vida.
def generate_text(model, tokenizer, prompt_text, max_tokens):
prompt_text = tokenizer(prompt_text, return_tensors="pt")
outputs = model.generate(
input_ids=prompt_text["input_ids"],
attention_mask=prompt_text["attention_mask"],
max_length=max_tokens,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
initial_output = generate_text(model, tokenizer, "I want you to act as a logistician. ", 100)
print("Initial model output:", initial_output)Este é o resultado do modelo:
['I want you to act as a logistician. You will be able to: Analyze the data']
Como você pode ver, o modelo não tem certeza do contexto.
O conjunto de dados é um elemento crucial para o ajuste imediato. Usamos o conjunto de dados `awesome-chatgpt-prompts` para ajuste. Esse conjunto de dados fornece conteúdo motivacional para ajuste, garantindo que o modelo adapte suas respostas de acordo.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda x: tokenizer(x["prompt"]), batched=True)
train_prompts = data_prompt["train"].select(range(50))Nós tokenizamos o conjunto de dados e preparamos um pequeno subconjunto para treinamento.
Agora, a parte mais interessante: configuramos o ajuste do prompt usando a classe PromptTuningConfig da biblioteca PEFT.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
tuning_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=4, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name
)
peft_model = get_peft_model(model, tuning_config)Os argumentos de treinamento são especificados usando a classe TrainingArguments.
from transformers import TrainingArguments
training_args = TrainingArguments(
use_cpu=True, # This is necessary for CPU clusters.
output_dir = "./",
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically, you can also use a custom batch size
learning_rate= 0.005,
num_train_epochs=5
)Um objeto Trainer gerencia o processo de treinamento. Com DataCollatorForLanguageModeling, o coletor de dados garante que as amostras de treinamento sejam formatadas adequadamente. A fase de treinamento é iniciada com o método train, ajustando o modelo bloomz-560m para as tarefas específicas do prompt.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_prompts, #The dataset used to train the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
trainer.train()O modelo ajustado é armazenado no objeto do instrutor. Podemos usar trainer.model para acessá-lo. Usamos a função generate_text para executar a inferência com o modelo ajustado!
tuned_output = generate_text(trainer.model, tokenizer, "I want you to act as a logistician. ", 100)
print("Tuned model output:", tuned_output)Aqui está o resultado do modelo ajustado:
['I want you to act as a logistician. You will be responsible for the logistics of your business.']
Como você pode ver agora, o modelo sabe o que o operador logístico faz. Sinta-se à vontade para experimentar diferentes prompts, modelos e conjuntos de dados!
O ajuste de prompts é uma ferramenta poderosa para tornar grandes modelos de linguagem mais eficientes em uma tarefa específica. Exploramos o prompt tuning explicando primeiro o que ele é e como funciona. Em seguida, comparamos com outras técnicas semelhantes: ajuste fino e engenharia imediata. Por fim, discutimos seus benefícios e fizemos um guia passo a passo para aplicar o ajuste imediato a um modelo pré-treinado.
Como o campo da IA generativa continua a evoluir, é importante que você fique por dentro dos últimos desenvolvimentos. Para que você possa aprimorar ainda mais suas habilidades e sua compreensão da IA, o DataCamp oferece uma variedade de recursos detalhados. Incentivo você a explorar esses tutoriais abrangentes:
Continue aprendendo com a DataCamp
Programa
Curso
Curso
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
Zoumana Keita

