
Cursus
Principes fondamentaux de l'IA
10 h
Dans le domaine en évolution rapide des grands modèles de langage (LLM), il est crucial de rester à la pointe des approches de pointe telles que l'accord rapide. Cette technique, appliquée à des modèles fondamentaux déjà formés, améliore les performances sans les coûts de calcul élevés associés à la formation traditionnelle des modèles.
Dans cet article, nous allons explorer les principes fondamentaux du réglage rapide, le comparer au réglage fin et à l'ingénierie rapide, et discuter de ses avantages significatifs. Nous fournirons également un exemple pratique utilisant la plateforme de HuggingFace, où nous avons Prompt tune un modèle bloomz-560m. Ce guide a pour but d'approfondir votre compréhension du prompt tuning et d'inspirer son intégration dans vos projets.
L'optimisation des invites est une technique conçue pour améliorer les performances d'un modèle de langage pré-entraîné sans modifier son architecture de base. Au lieu de modifier les poids structurels profonds du modèle, le réglage des invites ajuste les invites qui guident la réponse du modèle. Cette méthode est basée sur l'introduction de "soft prompts", un ensemble de paramètres réglables insérés au début de la séquence d'entrée.
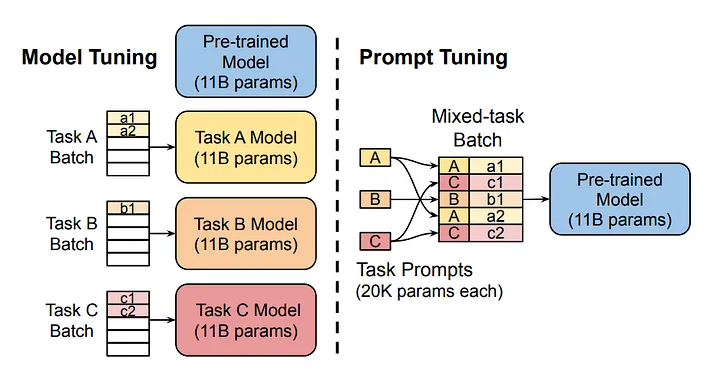
Source de l'image
Le diagramme compare l'approche traditionnelle de la mise au point du modèle avec la mise au point rapide. Notez que dans le cadre du model tuning, chaque tâche nécessite un modèle distinct. D'autre part, le réglage des invites utilise le même modèle fondamental pour plusieurs tâches en ajustant les invites spécifiques à chaque tâche.
Les invites douces sont des éléments construits artificiellement qui sont ajoutés à la séquence d'entrée du modèle. Ces invites peuvent être initialisées de plusieurs manières. L'initialisation aléatoire est courante, mais il est également possible de les initialiser sur la base de certaines heuristiques. Une fois initialisés, les messages d'aide sont attachés au début des données d'entrée. Lorsque le modèle traite ces données, il prend en compte à la fois les invites et les données réelles.
Le processus de formation est généralement similaire à celui de la formation d'un réseau neuronal profond (DNN) standard. Il commence par un passage vers l'avant où le modèle traite l'entrée combinée à travers ses couches, produisant une sortie. Cette sortie est ensuite évaluée par rapport au résultat souhaité à l'aide d'une fonction de perte, qui mesure l'écart entre la sortie du modèle et la valeur réelle attendue.
Lors de la rétropropagation, les erreurs sont propagées dans le réseau. Cependant, au lieu d'ajuster les poids du réseau, nous ne modifions que les paramètres de l'invite douce. Ce processus se répète sur plusieurs époques, les invites douces apprenant progressivement à modeler le traitement des entrées par le modèle de manière à minimiser l'erreur pour la tâche donnée.
Le processus de passage vers l'avant, d'évaluation des pertes et de rétropropagation est répété sur plusieurs époques. Au fil du temps, ces invites douces apprennent à façonner l'entrée de manière à réduire constamment le score de perte, améliorant ainsi la performance spécifique du modèle sans compromettre ses capacités sous-jacentes.
Le réglage des invites, le réglage fin et l'ingénierie des invites sont trois méthodes distinctes appliquées à des LLM pré-entraînés afin d'améliorer leurs performances dans une tâche spécifique. Ces méthodes ne s'excluent pas mutuellement et sont chacune adaptées à un cas d'utilisation particulier.
Le réglage fin est celui qui nécessite le plus de ressources, car il implique un réentraînement complet du modèle sur un ensemble de données spécifique dans un but précis. Cela permet d'ajuster les poids du modèle pré-entraîné, en l'optimisant pour les nuances détaillées des données, mais cela nécessite des ressources informatiques considérables et augmente le risque de surajustement. De nombreux LLM, comme le Chat GPT, subissent un réglage fin après leur formation générique initiale sur la tâche de prédiction de mots suivante. Le réglage fin apprend à ces modèles à fonctionner comme des assistants numériques, ce qui les rend nettement plus utiles qu'un modèle généralement entraîné.
Le réglage des invites permet d'ajuster un ensemble de paramètres supplémentaires, connus sous le nom d'"invites douces", qui sont intégrés dans le traitement des entrées du modèle. Cette méthode modifie la façon dont le modèle interprète les messages d'entrée sans modifier complètement ses poids, offrant ainsi un équilibre entre l'amélioration des performances et l'utilisation efficace des ressources. Cette technique est particulièrement utile lorsque les ressources informatiques sont limitées ou lorsqu'il faut faire preuve de souplesse dans l'exécution de plusieurs tâches, car après l'application de la technique, les poids du modèle d'origine restent inchangés.
L'ingénierie rapide, quant à elle, n'implique aucune formation ou recyclage. Il est entièrement basé sur la conception par l'utilisateur de messages-guides pour le modèle. Elle nécessite une compréhension nuancée des capacités de traitement du modèle et exploite les connaissances intrinsèques du modèle. L'ingénierie rapide ne nécessite pas de ressources informatiques puisqu'elle repose uniquement sur la formulation stratégique d'intrants pour obtenir des résultats. Consultez le cours de DataCamp sur l' ingénierie rapide pour les développeurs pour en savoir plus.
Chacune de ces techniques offre une approche différente pour exploiter les capacités des modèles pré-entraînés. Le choix de l'un ou l'autre dépend des besoins spécifiques de l'application, tels que la disponibilité des ressources informatiques, l'exigence de personnalisation du modèle et le niveau d'interaction souhaité avec les paramètres d'apprentissage du modèle.
|
Méthode |
Intensité des ressources |
Formation requise |
Meilleur pour |
|
Mise au point |
Haut |
Oui |
Tâches nécessitant une personnalisation approfondie du modèle |
|
Prompt Tuning |
Faible |
Oui |
Maintien de l'intégrité du modèle entre les tâches |
|
Ingénierie rapide |
Aucun |
Non |
Adaptations rapides sans coût de calcul. |
Chaque méthode a sa place en fonction des besoins spécifiques de votre projet.
L'optimisation des invites apporte plusieurs avantages clés au tableau, ce qui en fait une technique indispensable pour l'optimisation des modèles de langage de grande taille.
Un réglage rapide permet de maintenir inchangés les paramètres du modèle pré-entraîné, ce qui réduit considérablement la puissance de calcul nécessaire. Cette efficacité est particulièrement cruciale dans les environnements où les ressources sont limitées, car elle permet d'utiliser des modèles sophistiqués sans en supporter le coût élevé. À mesure que la taille moyenne des modèles fondamentaux augmente, la "congélation" des paramètres du modèle devient encore plus attrayante, car il n'est pas nécessaire de déployer un modèle distinct pour chaque tâche.
Contrairement à la mise au point globale, la mise au point de l'invite ne nécessite d'ajuster qu'un petit ensemble de paramètres de l'invite douce. Cela accélère le processus d'adaptation, permet des transitions plus rapides entre les différentes tâches et réduit les temps d'arrêt.
En gardant intacts l'architecture de base et les poids du modèle, le réglage rapide préserve les capacités et les connaissances originales intégrées dans le modèle pré-entraîné. Cela est essentiel pour maintenir la fiabilité et la généralisation du modèle dans diverses applications.
L'ajustement des invites facilite l'utilisation d'un seul modèle de base pour plusieurs tâches en changeant simplement les invites logicielles. Cette approche réduit la nécessité de former et de maintenir des modèles distincts pour chaque tâche spécifique, améliorant ainsi l'évolutivité et la simplicité de la gestion des modèles.
Le réglage des invites nécessite beaucoup moins d'intervention humaine que l'ingénierie des invites, où l'élaboration minutieuse d'invites adaptées à une tâche particulière peut être sujette à des erreurs et prendre beaucoup de temps. Au contraire, l'optimisation automatisée des messages non techniques pendant la formation minimise l'erreur humaine et maximise l'efficacité.
La recherche indique que pour les grands modèles, l'ajustement rapide peut atteindre des niveaux de performance comparables à ceux de l'ajustement fin. Cet avantage devient de plus en plus important au fur et à mesure que la taille des modèles augmente, combinant une grande efficacité avec des résultats solides.
Pour ce guide, nous appliquerons le réglage rapide au modèle bloomz-560m de BigScience. Nous travaillerons dans l'écosystème Hugging Face en utilisant la bibliothèque PEFT (Parameter-Efficient Fine-Tuning).
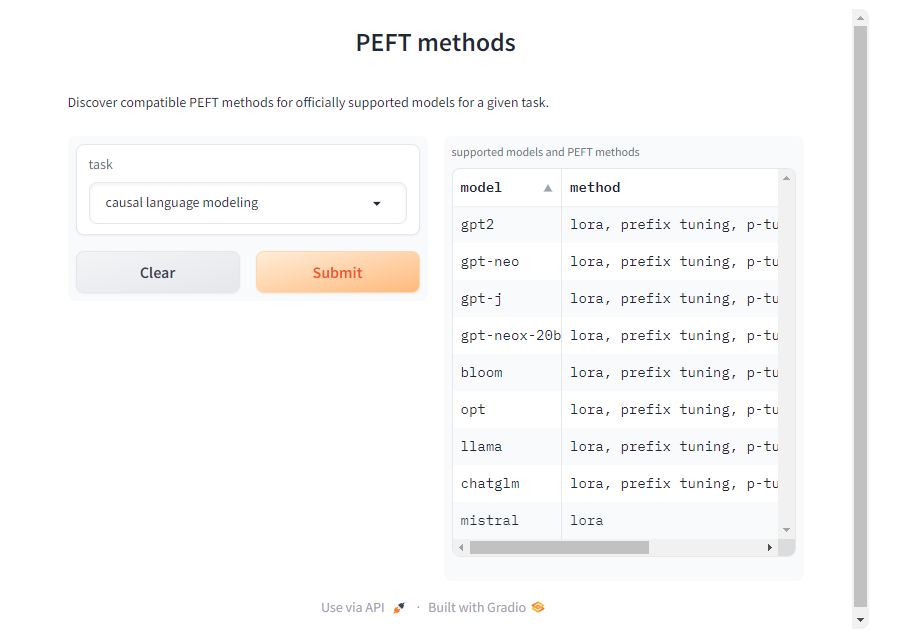
Bien que nous nous concentrions ici sur la tâche de modélisation du langage causal, la bibliothèque PEFT prend en charge diverses tâches, modèles et techniques de réglage. Vous trouverez des méthodes PEFT compatibles avec d'autres modèles et tâches sur la page de documentation PEFT.
Pour commencer, nous chargeons le modèle et le tokenizer du modèle BigScience bloomz-560m. Le tokenizer est utilisé pour traiter les entrées textuelles, tandis que le modèle fondamental gère les tâches de modélisation causale du langage. Le paramètre trust_remote_code=True vous permet d'utiliser le code personnalisé fourni par les responsables du modèle pour des architectures spécifiques.
Bien que cela soit utile pour obtenir toutes les fonctionnalités, ne vous fiez au code du modèle que s'il provient d'une source fiable. Évitez d'utiliser du code non fiable pour des modèles provenant de créateurs inconnus ou non vérifiés, car il peut présenter des risques pour la sécurité ou la stabilité.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloomz-560m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)Avant toute mise au point, il est essentiel d'établir une base de référence en effectuant une inférence avec le modèle de base non mis au point. En utilisant une invite telle que "Je veux que vous agissiez comme un logisticien", nous pouvons observer comment le modèle génère des réponses sans réglage supplémentaire. Veillez à inclure un espace supplémentaire après l'invite, sinon le modèle risque de ne rien générer.
Cela sert de référence pour comparer les améliorations après la mise au point.
Nous utiliserons une fonction personnalisée generate_text pour nous faciliter la tâche.
def generate_text(model, tokenizer, prompt_text, max_tokens):
prompt_text = tokenizer(prompt_text, return_tensors="pt")
outputs = model.generate(
input_ids=prompt_text["input_ids"],
attention_mask=prompt_text["attention_mask"],
max_length=max_tokens,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
initial_output = generate_text(model, tokenizer, "I want you to act as a logistician. ", 100)
print("Initial model output:", initial_output)Il s'agit de la sortie du modèle :
['I want you to act as a logistician. You will be able to: Analyze the data']
Comme vous pouvez le constater, le modèle n'est pas tout à fait sûr du contexte.
L'ensemble des données est un élément crucial du réglage rapide. Nous utilisons le jeu de données `awesome-chatgpt-prompts` pour la mise au point. Cet ensemble de données fournit un contenu motivant pour le réglage, ce qui permet au modèle d'adapter ses réponses en conséquence.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda x: tokenizer(x["prompt"]), batched=True)
train_prompts = data_prompt["train"].select(range(50))Nous symbolisons l'ensemble de données et préparons un petit sous-ensemble pour l'entraînement.
Maintenant, la partie la plus intéressante ; nous configurons l'accord de l'invite en utilisant la classe PromptTuningConfig de la bibliothèque PEFT.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
tuning_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=4, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name
)
peft_model = get_peft_model(model, tuning_config)Les arguments de formation sont spécifiés à l'aide de la classe TrainingArguments.
from transformers import TrainingArguments
training_args = TrainingArguments(
use_cpu=True, # This is necessary for CPU clusters.
output_dir = "./",
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically, you can also use a custom batch size
learning_rate= 0.005,
num_train_epochs=5
)Un objet Trainer gère le processus de formation. Avec DataCollatorForLanguageModeling, le collecteur de données s'assure que les échantillons d'apprentissage sont correctement formatés. La phase de formation commence par la méthode train, qui permet d'affiner le modèle bloomz-560m pour les tâches spécifiques de l'invite.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_prompts, #The dataset used to train the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
trainer.train()Le modèle accordé est stocké dans l'objet "trainer", nous pouvons utiliser trainer.model pour y accéder. Nous utilisons la fonction generate_text pour lancer l'inférence avec le modèle ajusté !
tuned_output = generate_text(trainer.model, tokenizer, "I want you to act as a logistician. ", 100)
print("Tuned model output:", tuned_output)Voici le résultat du modèle ajusté :
['I want you to act as a logistician. You will be responsible for the logistics of your business.']
Comme vous pouvez le constater, le modèle sait ce que fait le logisticien. N'hésitez pas à expérimenter avec différents messages-guides, modèles et ensembles de données !
Le réglage des invites est un outil puissant qui permet de rendre les grands modèles de langage plus efficaces pour une tâche spécifique. Nous avons exploré l'accord rapide en expliquant d'abord ce qu'il est et comment il fonctionne. Nous l'avons ensuite comparée à d'autres techniques similaires : le réglage fin et l'ingénierie rapide. Enfin, nous avons discuté de ses avantages et nous avons suivi un guide étape par étape de l'application de l'accord rapide à un modèle pré-entraîné.
Le domaine de l'IA générative continuant d'évoluer, il est important de se tenir au courant des derniers développements. Pour améliorer encore vos compétences et votre compréhension de l'IA, DataCamp propose une variété de ressources approfondies. Je vous encourage à explorer ces tutoriels complets :
Continuez à apprendre avec DataCamp
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min