
Lernpfad
Grundlagen der KI
10 Std.
In dem sich schnell entwickelnden Bereich der großen Sprachmodelle (LLMs) ist es wichtig, dass du immer auf dem neuesten Stand der Technik bleibst, z.B. beim Prompt Tuning. Diese Technik, die auf bereits trainierte Grundmodelle angewendet wird, verbessert die Leistung ohne die hohen Rechenkosten, die mit dem traditionellen Modelltraining verbunden sind.
In diesem Artikel gehen wir auf die Grundlagen des Prompt-Tunings ein, vergleichen es mit dem Feintuning und dem Prompt-Engineering und erörtern seine wesentlichen Vorteile. Außerdem stellen wir ein praktisches Beispiel vor, bei dem wir die HuggingFace-Plattform nutzen und ein bloomz-560m-Modell mit Prompt tunen. Dieser Leitfaden soll dein Verständnis von Prompt Tuning vertiefen und dich dazu inspirieren, es in deine Projekte zu integrieren.
Das Prompt-Tuning ist eine Technik, mit der die Leistung eines vorab trainierten Sprachmodells verbessert werden kann, ohne dass dessen Kernarchitektur verändert wird. Anstatt die tiefen strukturellen Gewichte des Modells zu verändern, werden beim Prompt-Tuning die Prompts angepasst, die die Reaktion des Modells steuern. Diese Methode basiert auf der Einführung von "Soft Prompts", einer Reihe von einstellbaren Parametern, die am Anfang der Eingabesequenz eingefügt werden.
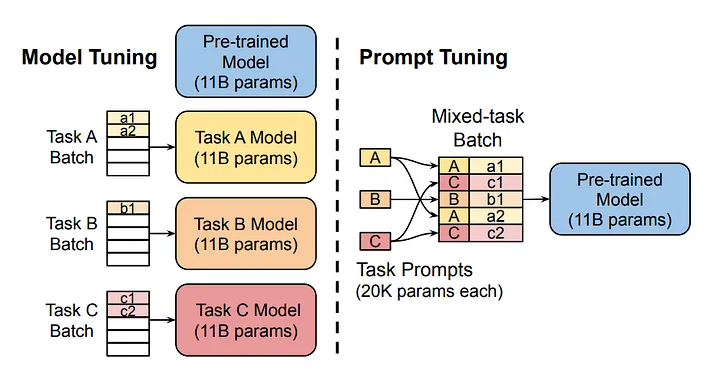
Das Diagramm vergleicht den traditionellen Ansatz der Modellabstimmung mit der zeitnahen Abstimmung. Beachte, dass beim Modelltuning jede Aufgabe ein eigenes Modell erfordert. Beim Prompt-Tuning hingegen wird das gleiche Grundmodell für mehrere Aufgaben verwendet, indem die aufgabenspezifischen Prompts angepasst werden.
Soft Prompts sind künstlich konstruierte Tokens, die der Eingabesequenz des Modells hinzugefügt werden. Diese Prompts können auf verschiedene Arten initialisiert werden. Eine zufällige Initialisierung ist üblich, aber sie kann auch auf der Grundlage bestimmter Heuristiken erfolgen. Nach der Initialisierung werden die Soft Prompts an den Anfang der Eingabedaten angehängt. Wenn das Modell diese Daten verarbeitet, berücksichtigt es sowohl die Soft Prompts als auch die tatsächlichen Eingaben.
Der Trainingsprozess ähnelt in der Regel dem Training eines normalen tiefen neuronalen Netzwerks (DNN). Es beginnt mit einem Vorwärtsdurchlauf, bei dem das Modell die kombinierte Eingabe durch seine Schichten verarbeitet und eine Ausgabe erzeugt. Diese Ausgabe wird dann mithilfe einer Verlustfunktion, die die Diskrepanz zwischen der Ausgabe des Modells und dem tatsächlich erwarteten Wert misst, mit dem gewünschten Ergebnis verglichen.
Bei der Backpropagation werden die Fehler durch das Netzwerk zurückverfolgt. Anstatt die Gewichte des Netzes anzupassen, ändern wir jedoch nur die Soft Prompt Parameter. Dieser Prozess wiederholt sich über mehrere Epochen, wobei die Soft Prompts nach und nach lernen, die Verarbeitung der Eingaben durch das Modell so zu gestalten, dass der Fehler für die jeweilige Aufgabe minimiert wird.
Der Prozess des Vorwärtsdurchlaufs, der Verlustbewertung und der Backpropagation wird über mehrere Epochen hinweg wiederholt. Im Laufe der Zeit lernen diese Soft Prompts, die Eingaben so zu gestalten, dass die Verlustquote stetig sinkt, wodurch die aufgabenspezifische Leistung des Modells verbessert wird, ohne seine grundlegenden Fähigkeiten zu beeinträchtigen.
Prompt-Tuning, Fine-Tuning und Prompt-Engineering sind drei verschiedene Methoden, die auf vortrainierte LLMs angewendet werden, um ihre Leistung bei einer bestimmten Aufgabe zu verbessern. Diese Methoden schließen sich nicht gegenseitig aus und sind jeweils für einen bestimmten Anwendungsfall geeignet.
Die Feinabstimmung ist am ressourcenintensivsten und beinhaltet ein umfassendes Neutraining des Modells auf einem bestimmten Datensatz für einen bestimmten Zweck. Dadurch werden die Gewichte des vortrainierten Modells angepasst, wodurch es für die detaillierten Nuancen der Daten optimiert wird, was jedoch erhebliche Rechenressourcen erfordert und das Risiko einer Überanpassung erhöht. Viele LLMs wie Chat GPT werden nach ihrem anfänglichen allgemeinen Training für die nächste Wortvorhersageaufgabe feinabgestimmt. Durch die Feinabstimmung lernen diese Modelle, wie sie als digitale Assistenten funktionieren, und sind dadurch wesentlich nützlicher als ein allgemein trainiertes Modell.
Beim Prompt-Tuning wird eine Reihe von zusätzlichen Parametern, die sogenannten "Soft Prompts", angepasst, die in die Eingabeverarbeitung des Modells integriert sind. Diese Methode ändert die Art und Weise, wie das Modell die Eingabeaufforderungen interpretiert, ohne dass die Gewichtung komplett überarbeitet werden muss. Sie ist besonders wertvoll, wenn die Rechenressourcen begrenzt sind oder wenn Flexibilität für mehrere Aufgaben erforderlich ist, denn nach Anwendung der Technik bleiben die ursprünglichen Modellgewichte unverändert.
Promptes Engineering hingegen erfordert überhaupt keine Ausbildung oder Umschulung. Es basiert vollständig darauf, dass der/die Nutzer/in Aufforderungen für das Modell entwirft. Sie erfordert ein differenziertes Verständnis der Verarbeitungsmöglichkeiten des Modells und nutzt das im Modell eingebettete Wissen. Promptes Engineering benötigt keine Rechenressourcen, da es sich allein auf die strategische Formulierung von Eingaben stützt, um Ergebnisse zu erzielen. Mehr darüber erfährst du im DataCamp-Kurs " Prompt Engineering für Entwickler ".
Jede dieser Techniken bietet einen anderen Ansatz, um die Fähigkeiten der vortrainierten Modelle zu nutzen. Die Wahl zwischen ihnen hängt von den spezifischen Bedürfnissen der Anwendung ab, wie z. B. der Verfügbarkeit von Rechenressourcen, der Anforderung an die Modellanpassung und dem gewünschten Grad der Interaktion mit den Lernparametern des Modells.
|
Methode |
Ressourcenintensität |
Ausbildung erforderlich |
Am besten für |
|
Feinabstimmung |
Hoch |
Ja |
Aufgaben, die eine tiefgreifende Modellanpassung erfordern |
|
Promptes Tuning |
Niedrig |
Ja |
Wahrung der Modellintegrität über Aufgaben hinweg |
|
Schnelles Engineering |
Keine |
Nein |
Schnelle Anpassungen ohne Berechnungsaufwand. |
Jede Methode hat ihre Berechtigung, je nach den spezifischen Bedürfnissen deines Projekts.
Promptes Tuning bringt mehrere wichtige Vorteile mit sich, die es zu einer unverzichtbaren Technik für die Optimierung großer Sprachmodelle machen.
Durch die prompte Abstimmung bleiben die Parameter des trainierten Modells unverändert, wodurch die benötigte Rechenleistung erheblich reduziert wird. Diese Effizienz ist vor allem in ressourcenbeschränkten Umgebungen entscheidend, da sie die Nutzung anspruchsvoller Modelle ohne hohe Kosten ermöglicht. Da die durchschnittliche Größe von Basismodellen steigt, wird das "Einfrieren" von Modellparametern noch attraktiver, da nicht für jede Aufgabe ein eigenes Modell eingesetzt werden muss.
Im Gegensatz zur umfassenden Feinabstimmung müssen bei der Promptabstimmung nur einige wenige Soft-Prompt-Parameter angepasst werden. Das beschleunigt den Anpassungsprozess, ermöglicht schnellere Übergänge zwischen verschiedenen Aufgaben und reduziert Ausfallzeiten.
Da die Kernarchitektur und die Gewichte des Modells intakt bleiben, bleiben die ursprünglichen Fähigkeiten und das Wissen des trainierten Modells erhalten. Dies ist wichtig, um die Zuverlässigkeit und Verallgemeinerbarkeit des Modells für verschiedene Anwendungen zu gewährleisten.
Das Prompt-Tuning erleichtert die Verwendung eines einzigen Basismodells für mehrere Aufgaben, indem einfach die Soft Prompts geändert werden. Dieser Ansatz reduziert die Notwendigkeit, für jede spezifische Aufgabe ein eigenes Modell zu trainieren und zu pflegen, was die Skalierbarkeit und Einfachheit der Modellverwaltung verbessert.
Die Abstimmung von Prompts erfordert deutlich weniger menschliches Eingreifen als das Prompt-Engineering, bei dem die sorgfältige Erstellung von Prompts für eine bestimmte Aufgabe fehleranfällig und zeitaufwändig sein kann. Stattdessen werden durch die automatische Optimierung der Soft Prompts während der Ausbildung menschliche Fehler minimiert und die Effizienz maximiert.
Die Forschung zeigt, dass bei großen Modellen eine schnelle Abstimmung ein vergleichbares Leistungsniveau wie eine Feinabstimmung erreichen kann. Dieser Vorteil wird mit zunehmender Modellgröße immer bedeutender und kombiniert hohe Effizienz mit starken Ergebnissen.
In diesem Leitfaden wenden wir das Prompt-Tuning auf das Modell bloomz-560m von BigScience an. Wir arbeiten im Hugging Face Ökosystem mit der PEFT (Parameter-Efficient Fine-Tuning) Bibliothek.
Obwohl wir uns hier auf die Aufgabe der kausalen Sprachmodellierung konzentrieren, unterstützt die PEFT-Bibliothek verschiedene Aufgaben, Modelle und Tuning-Techniken. Du kannst kompatible PEFT-Methoden für andere Modelle und Aufgaben auf der PEFT-Dokumentationsseite finden.
Zu Beginn laden wir das Modell und den Tokenizer aus dem BigScience bloomz-560m-Modell. Der Tokenizer wird verwendet, um Texteingaben zu verarbeiten, während das Basismodell kausale Sprachmodellierungsaufgaben übernimmt. Der Parameter trust_remote_code=True ermöglicht es dir, benutzerdefinierten Code zu verwenden, der von den Betreuern des Modells für bestimmte Architekturen bereitgestellt wird.
Auch wenn dies nützlich ist, um die volle Funktionalität zu erhalten, solltest du dem Code des Modells nur vertrauen, wenn er aus einer seriösen Quelle stammt. Vermeide es, nicht vertrauenswürdigen Code für Modelle von unbekannten oder nicht verifizierten Erstellern zu verwenden, da dieser ein Sicherheits- oder Stabilitätsrisiko darstellen kann.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloomz-560m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)Vor dem Tuning ist es wichtig, eine Basislinie zu erstellen, indem du mit dem ungetunten Basismodell Inferenzen durchführst. Mit einer Aufforderung wie "Ich möchte, dass du dich als Logistiker/in betätigst" können wir beobachten, wie das Modell ohne weitere Abstimmung Antworten erzeugt. Achte darauf, ein zusätzliches Leerzeichen nach der Aufforderung einzufügen, sonst erzeugt das Modell möglicherweise nichts.
Dies dient als Referenz für den Vergleich von Verbesserungen nach dem Tuning.
Wir werden eine benutzerdefinierte generate_text Funktion verwenden, um uns das Leben zu erleichtern.
def generate_text(model, tokenizer, prompt_text, max_tokens):
prompt_text = tokenizer(prompt_text, return_tensors="pt")
outputs = model.generate(
input_ids=prompt_text["input_ids"],
attention_mask=prompt_text["attention_mask"],
max_length=max_tokens,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
initial_output = generate_text(model, tokenizer, "I want you to act as a logistician. ", 100)
print("Initial model output:", initial_output)Dies ist die Ausgabe des Modells:
['I want you to act as a logistician. You will be able to: Analyze the data']
Wie du siehst, ist sich das Modell über den Kontext nicht ganz sicher.
Der Datensatz ist ein entscheidendes Element für eine schnelle Abstimmung. Wir verwenden den Datensatz `awesome-chatgpt-prompts` für das Tuning. Dieser Datensatz liefert motivierende Inhalte für das Tuning und sorgt dafür, dass das Modell seine Reaktionen entsprechend anpasst.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda x: tokenizer(x["prompt"]), batched=True)
train_prompts = data_prompt["train"].select(range(50))Wir tokenisieren den Datensatz und bereiten eine kleine Teilmenge für das Training vor.
Jetzt kommt der interessanteste Teil: Wir konfigurieren die Prompt-Abstimmung mit der Klasse PromptTuningConfig aus der Bibliothek PEFT.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
tuning_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=4, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name
)
peft_model = get_peft_model(model, tuning_config)Die Trainingsargumente werden mit der Klasse TrainingArguments angegeben.
from transformers import TrainingArguments
training_args = TrainingArguments(
use_cpu=True, # This is necessary for CPU clusters.
output_dir = "./",
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically, you can also use a custom batch size
learning_rate= 0.005,
num_train_epochs=5
)Ein Trainer Objekt verwaltet den Ausbildungsprozess. Mit DataCollatorForLanguageModeling stellt der Data Collator sicher, dass die Trainingsbeispiele richtig formatiert sind. Die Trainingsphase wird mit der train Methode eingeleitet, um das bloomz-560m Modell für die spezifischen Prompt-Aufgaben fein abzustimmen.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_prompts, #The dataset used to train the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
trainer.train()Das abgestimmte Modell ist im Trainer-Objekt gespeichert, auf das wir mit trainer.model zugreifen können. Wir verwenden die Funktion generate_text, um mit dem abgestimmten Modell Inferenzen durchzuführen!
tuned_output = generate_text(trainer.model, tokenizer, "I want you to act as a logistician. ", 100)
print("Tuned model output:", tuned_output)Hier ist die Ausgabe des abgestimmten Modells:
['I want you to act as a logistician. You will be responsible for the logistics of your business.']
Wie du jetzt sehen kannst, weiß das Modell, was der Logistiker macht. Du kannst gerne mit verschiedenen Aufforderungen, Modellen und Datensätzen experimentieren!
Prompt-Tuning ist ein mächtiges Werkzeug, um große Sprachmodelle für eine bestimmte Aufgabe effizienter zu machen. Wir haben uns mit dem Prompt Tuning beschäftigt, indem wir zunächst erklärt haben, was es ist und wie es funktioniert. Dann haben wir sie mit anderen ähnlichen Techniken verglichen: Feinabstimmung und Sofortengineering. Abschließend haben wir die Vorteile dieser Methode besprochen und eine Schritt-für-Schritt-Anleitung für die Anwendung von Prompt-Tuning auf ein vortrainiertes Modell erstellt.
Da sich der Bereich der generativen KI ständig weiterentwickelt, ist es wichtig, über die neuesten Entwicklungen auf dem Laufenden zu bleiben. Um deine Fähigkeiten und dein Verständnis von KI weiter zu verbessern, bietet das DataCamp eine Reihe von detaillierten Ressourcen an. Ich ermutige dich, diese umfassenden Tutorials zu erkunden:
Weiter lernen mit DataCamp
Lernpfad
Kurs
Kurs