Course
Introduction to Python
4 hr
6.9M
Run and edit the code from this tutorial online
Run codeThis tutorial covers how to read text files in Python. This is an essential first step in any project involving text data, particularly Natural Language Processing (“NLP”). There are some nuances and common pitfalls when importing text files into Python, meaning data scientists often have to move away from familiar packages such as pandas to handle text data most efficiently.
To get the most from this article, you should have a basic knowledge of Python, in particular, understanding data types such as the differences between strings, integers, and lists. An understanding of pandas and what a dataframe is would also be useful.
If you want to know about importing data from .csv files, this is covered in the pandas read csv() Tutorial: Importing Data. To learn more about importing from JSON and pickle (.pkl) files, take a look at to the Importing Data into pandas tutorial. If you’re interested in web scraping HTML pages, Web Scraping using Python (and Beautiful Soup) may be for you. Alternatively, you can get started by learning directly on DataCamp with our interactive course on Introduction to Importing Data in Python, the first chapter is for free.
For this tutorial, we will use a simple text file which is just a copy and paste of the first paragraph of the Wikipedia page for Natural Language Processing. This has been saved as a file called nlp_wiki.txt. It contains the following:
"Natural language processing (NLP) is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves. Challenges in natural language processing frequently involve speech recognition, natural-language understanding, and natural-language generation."The pandas read_table() function is designed to read delimited text files (e.g. a spreadsheet saved as a text file, with commas separating columns) into a dataframe. Our text file isn’t delimited. It's just a copy and paste of some text. However, using pandas can be a useful way to quickly view the contents as the syntax of this function is similar to read_csv(), which most data scientists will be familiar with.
The code below can be used to read a text file using pandas.
pd.read_table('nlp_wiki.txt', header=None, delimiter=None)Output:

We pass the name of the text file and two arguments to our read_table() function.
header=None tells pandas that the first row contains text, not a header. delimiter=None tells pandas not to split the lines anywhere (except newlines) so there is a single column with one row per line.In this situation, a DataFrame isn’t always ideal. The paragraphs are separated into individual lines (pandas is using the newline character to do this), and we can’t see the full output. Another option is to call the .to_list() method for the column.
pd.read_table('nlp_wiki.txt', header=None, delimiter=None)[0].to_list()Output:
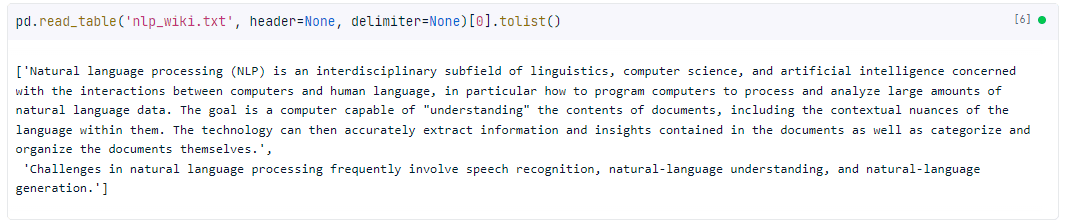
This returns a list of lists that can be accessed like a normal Python list. It also prints out the full text.
The read_table() function has a lot of optional keyword arguments, which you can read about in the official documentation. Here are a few of the most useful:
skiprows=n
This skips the first n rows. In our example, we skipped the first row.
nrows=n
This keeps the first n rows. In our example, we’ve kept the first row.
skip_blank_lines= True pandas will skip any NaN values rather than return an empty row.
NumPy's loadtxt() is designed to read arrays of numbers from a text file; however, it can be used to read lines of text. This is convenient if you are using NumPy in the rest of your analysis, as the output is a NumPy array.
np.loadtxt('nlp_wiki.txt', dtype="str", delimiter="\0")Output:
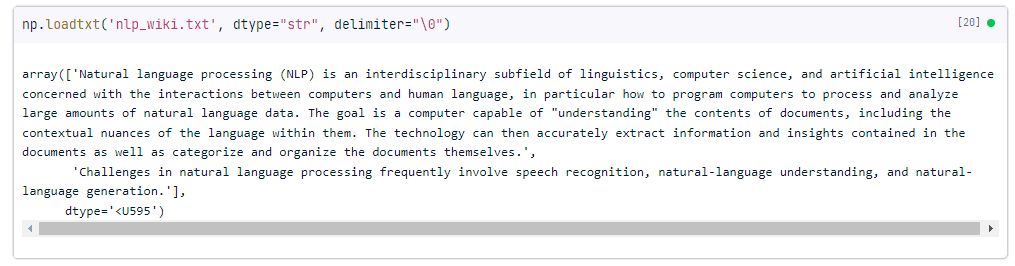
Like the pandas example, we pass the delimiter argument to prevent the lines from being split up. In this case, the delimiter must be a single character (using None has a different behavior), so we use a "null termination" character, \0. Since this cannot be contained in the middle of a string, using this means "do not use a delimiter".
We also pass dtype="str" which tells NumPy what data type to give the resulting array. In our case, we use “str” which returns a string. This can also be converted to a list using the .tolist() function.
Maximum flexibility can be achieved using Python's built-in functionality. This is less user-friendly and primarily designed for software engineering. The pandas or NumPy solutions are generally sufficient for data analysis.
To use open(), you also need a context manager, which is the with keyword. This allocates your computer's resources only while the indented code underneath the with is running. In this case, we open the file, loop through and store it in memory to the lines variable, then close it.
The for loop here uses a list comprehension, each line is a line as interpreted by the open() function, which in this case is a newline (\n).
This block of code also uses the strip() function, which removes additional whitespace before and after each object (or line).
with open(filename) as file:
lines = [line.strip() for line in file]Output:
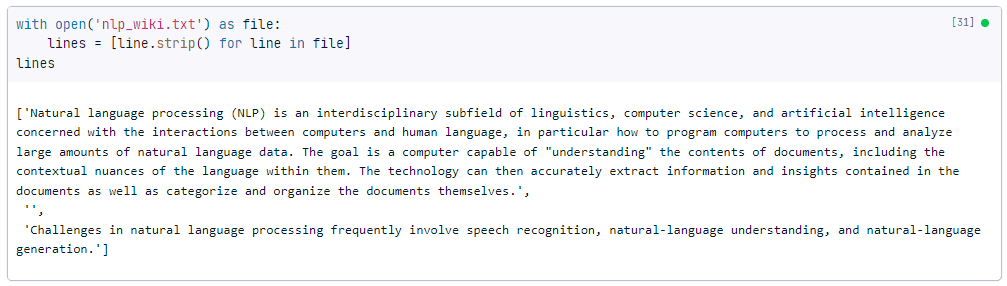
As you can see this outputs a single list, where each item in the list is a paragraph. Unlike the pandas and NumPy examples, we have three objects here, because the original text has two newlines between the paragraphs.
Now that we've covered how to import text files in Python, let's take a look at how to write text files. By writing files, we mean saving text files to your machine from Python. This is especially useful when you’ve manipulated text files in Python, and want to save the output.
You can write text files in Python using the built-in write() method. It also requires using open(), and you also need a context manager, which is the with keyword. Let’s illustrate with an example:
with open("new_nlp_wiki.txt", "w") as file:
file.write("New wiki entry: ChatGPT")In this example, we opened a file called new_nlp_wiki.txt in write mode (the 'w' argument), which means that any existing contents of the file will be overwritten. We then called the write() method on the file object to write the string “New wiki entry: ChatGPT” to the file.
If you want to append text to an existing file instead of overwriting it, you can open the file in append mode (the 'a' argument) instead:
with open("new_nlp_wiki.txt", "a") as file:
file.write("New wiki entry: ChatGPT")Probably the easiest way to write a text file using pandas is by using the to_csv() method. Let’s check it out in action!
nlp_wiki = pd.read_table("nlp_wiki.txt", header=None, delimiter=None)
nlp_wiki.to_csv("nlp_wiki_pandas.txt", sep="\t", index=False)In the first line of code, we read a text file using the read_table() method as outlined in an earlier section. Then we saved the file using the to_csv() method and specified the separator as a tab character ('\t') and set the index argument to False to exclude the row index from the output.
We hope you enjoyed this tutorial! As a recap, here’s what we covered:
Python Courses
Course
Course
Course
cheat-sheet
Karlijn Willems
cheat-sheet
Richie Cotton
Tutorial
Olivia Smith
Tutorial
Natassha Selvaraj
Tutorial
Kurtis Pykes
Tutorial
Aditya Sharma

