
Cours
Manipuler des séries temporelles en Python
4 h
71.6K
Dans le monde de l'analyse de données, Python est un langage populaire en raison de sa polyvalence et de son vaste écosystème de bibliothèques. La manipulation et l'analyse des données jouent un rôle crucial dans l'extraction d'informations et la prise de décisions éclairées. Cependant, comme les ensembles de données continuent de croître en taille et en complexité, le besoin de solutions à haute performance devient primordial.
Le traitement efficace de grands ensembles de données nécessite des outils capables de fournir des calculs rapides et des opérations optimisées. C'est là que Polars entre en scène. Polars est une puissante bibliothèque open-source spécialement conçue pour la manipulation et l'analyse de données haute performance en Python.
Polars est une bibliothèque DataFrame entièrement écrite en Rust et construite pour permettre aux développeurs Python de disposer d'un cadre évolutif et efficace pour le traitement des données. Elle est considérée comme une alternative à la très populaire bibliothèque pandas. Il offre un large éventail de fonctionnalités qui facilitent diverses tâches de manipulation et d'analyse des données. Voici quelques-uns des principaux avantages et caractéristiques de l'utilisation de Polars :
Polars est conçu dans un souci de performance. Il s'appuie sur des techniques de traitement parallèle et d'optimisation de la mémoire, ce qui lui permet de traiter des ensembles de données volumineux beaucoup plus rapidement que les méthodes traditionnelles.
Polars fournit une boîte à outils complète pour la manipulation des données, englobant des opérations essentielles telles que le filtrage, le tri, le regroupement, la jonction et l'agrégation des données. Bien que Polars n'ait pas les mêmes fonctionnalités que pandas en raison de sa relative nouveauté, il couvre environ 80% des opérations courantes trouvées dans Pandas.
Polars utilise une syntaxe concise et intuitive, ce qui facilite son apprentissage et son utilisation. Sa syntaxe rappelle celle des bibliothèques Python populaires comme pandas, ce qui permet aux utilisateurs de s'adapter rapidement à Polars et de tirer parti de leurs connaissances existantes.
Au cœur de Polars se trouvent les structures DataFrame et Series, qui fournissent une abstraction familière et puissante pour travailler avec des données tabulaires. Les opérations DataFrame dans Polars peuvent être enchaînées, ce qui permet des transformations de données efficaces et concises.
Polars intègre l'évaluation paresseuse, qui consiste à examiner et à optimiser les requêtes afin d'améliorer leurs performances et de minimiser la consommation de mémoire. Lorsque vous travaillez avec les Polars, la bibliothèque analyse vos requêtes et cherche à accélérer leur exécution ou à réduire l'utilisation de la mémoire. En revanche, Pandas ne prend en charge que l'évaluation anticipée, dans laquelle les expressions sont rapidement évaluées lorsqu'elles sont rencontrées.
pandas, une bibliothèque largement adoptée, est connue pour sa flexibilité et sa facilité d'utilisation. Cependant, lorsqu'il traite de grands ensembles de données, Pandas peut souffrir de goulots d'étranglement au niveau des performances en raison de sa dépendance à l'égard de l'exécution à un seul fil. Au fur et à mesure que la taille des ensembles de données augmente, les temps de traitement peuvent devenir prohibitifs, ce qui limite la productivité.
Polars a été spécialement conçu pour traiter efficacement les grands ensembles de données. Grâce à sa stratégie d'évaluation paresseuse et à ses capacités d'exécution parallèle, Polars excelle dans le traitement rapide de grandes quantités de données. En répartissant les calculs sur plusieurs cœurs de processeurs, Polars exploite le parallélisme pour offrir des gains de performance impressionnants. Voir le test de comparaison de vitesse entre Pandas et Polars par Yuki.
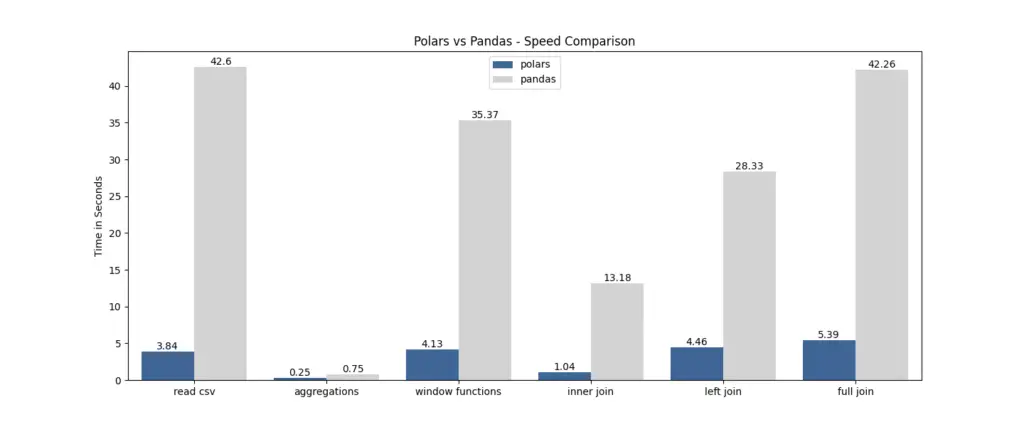
Pour une comparaison complète entre les polars et les pandas, consultez notre article séparé.
Polars peut être installé via pip, le gestionnaire de paquets Python. Ouvrez votre interface de ligne de commande et exécutez la commande suivante :
install polars
Polars fournit des méthodes pratiques pour charger des données à partir de diverses sources, notamment des fichiers CSV, des fichiers Parquet et des DataFrame Pandas. Les méthodes de lecture des fichiers CSV ou parquet sont les mêmes que celles de la bibliothèque pandas.
# read csv file
import polars as pl
data = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check the head
data.head()
Sortie :
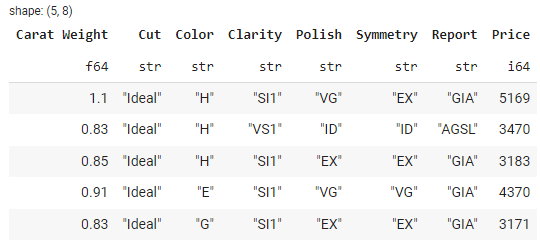
Le type de data est polars.DataFrame.
type(data)
>>> polars.dataframe.frame.DataFrame
Sortie :
Polars offre un ensemble complet de fonctionnalités pour la manipulation des données, vous permettant de sélectionner, filtrer, trier, transformer et nettoyer vos données avec facilité. Examinons quelques tâches courantes de manipulation de données et la manière de les accomplir à l'aide de Polars :
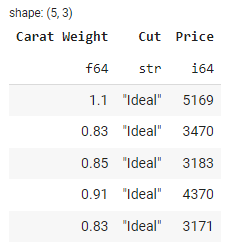
Pour sélectionner des colonnes spécifiques dans un DataFrame, vous pouvez utiliser la méthode select(). En voici un exemple :
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# Select specific columns: carat, cut, and price
selected_df = df.select(['Carat Weight', 'Cut', 'Price'])
# show selected_df head
selected_df.head()
Sortie :
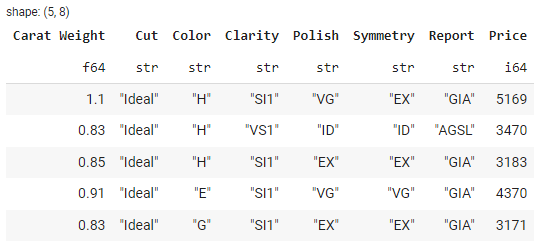
La méthode filter() permet de filtrer les lignes en fonction de certaines conditions. Par exemple, pour filtrer les lignes où le carat est supérieur à 1,0, vous pouvez procéder comme suit :
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# filter the df with condition
filtered_df = df.filter(pl.col('Carat Weight') > 2.0)
# show filtered_df head
filtered_df.head()
Sortie :
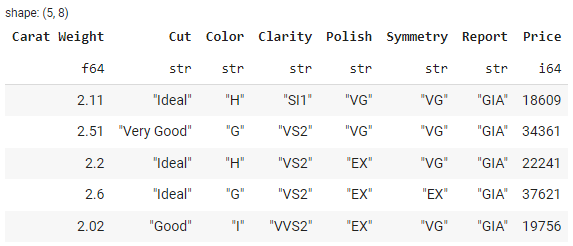
Polars fournit la méthode sort() pour trier un DataFrame sur la base d'une ou plusieurs colonnes. En voici un exemple :
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# sort the df by price
sorted_df = df.sort(by='Price')
# show sorted_df head
sorted_df.head()
Sortie :
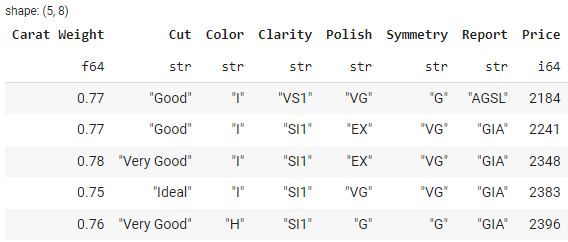
Polars propose des méthodes pratiques pour traiter les valeurs manquantes. La méthode drop_nulls() vous permet de supprimer les lignes qui contiennent des valeurs manquantes :
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# drop missing values
cleaned_df = df.drop_nulls()
# show cleaned_df head
cleaned_df.head()
Sortie :
Vous pouvez également utiliser la méthode fill_nulls() pour remplacer les valeurs manquantes par une valeur par défaut ou une méthode de remplissage spécifiée.
Pour regrouper des données sur la base de colonnes spécifiques, vous pouvez utiliser la méthode groupby(). Voici un exemple qui regroupe les données en fonction de la colonne Cut et calcule la moyenne de Price pour chaque groupe :
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# group by cut and calc mean of price
grouped_df = df.groupby(by='Cut').agg(pl.col('Price').mean())
# show grouped_df head
grouped_df.head()
Sortie :
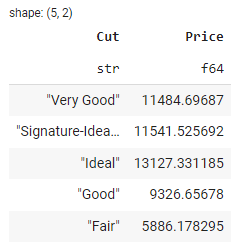
Dans le résultat ci-dessus, vous pouvez voir le prix moyen des diamants par dimension Cut.
Polars offre des options flexibles pour joindre et combiner des DataFrame, ce qui vous permet de fusionner et de concaténer des données provenant de différentes sources. Pour effectuer une opération de jointure, vous pouvez utiliser la méthode join(). Voici un exemple de jointure interne entre deux DataFrame sur la base d'une colonne clé commune :
import polars as pl
# Create the first DataFrame
df1 = pl.DataFrame({
'id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David']
})
# Create the second DataFrame
df2 = pl.DataFrame({
'id': [2, 3, 5],
'age': [25, 30, 35]
})
# Perform an inner join on the 'id' column
joined_df = df1.join(df2, on='id')
# Display the joined DataFrame
joined_df
Sortie :

Dans cet exemple, nous créons deux DataFrame (df1 et df2) à l'aide du constructeur pl.DataFrame. Le premier DataFrame df1 contient les colonnes id et name, et le second DataFrame df2 contient les colonnes id et age. Nous effectuons ensuite une jointure interne sur la colonne id à l'aide de la méthode join(), en spécifiant la colonne id comme clé de jointure.
Polars offre une intégration transparente avec d'autres bibliothèques Python populaires, permettant aux analystes de données de tirer parti d'un large éventail d'outils et de fonctionnalités. Examinons deux aspects clés de l'intégration : le travail avec d'autres bibliothèques et l'interopérabilité avec Pandas.
Polars s'intègre facilement à des bibliothèques telles que NumPy et PyArrow, ce qui permet aux utilisateurs de combiner les forces de plusieurs outils dans leurs flux de travail d'analyse de données. Avec l'intégration NumPy, Polars convertit sans effort entre les DataFrame Polars et les tableaux NumPy, en tirant parti des puissantes capacités de calcul scientifique de NumPy. Cette intégration garantit une transition fluide des données et permet aux analystes d'appliquer directement les fonctions NumPy aux données Polars.
De même, en s'appuyant sur PyArrow, Polars optimise le transfert de données entre Polars et les systèmes basés sur Arrow. Cette intégration permet de travailler de manière transparente avec des données stockées au format Arrow et d'exploiter les capacités de manipulation de données très performantes de Polars.
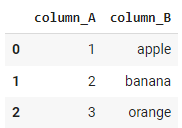
Polars permet une conversion transparente des DataFrames Polars en DataFrames Pandas. Voici un exemple illustrant la conversion de Polars en pandas.
import polars as pl
import pandas as pd
# Create a Polars DataFrame
df_polars = pl.DataFrame({
'column_A': [1, 2, 3],
'column_B': ['apple', 'banana', 'orange']
})
# Convert Polars DataFrame to Pandas DataFrame
df_pandas = df_polars.to_pandas()
# Display the Pandas DataFrame
df_pandas
Sortie :
Polars est une bibliothèque puissante pour la manipulation et l'analyse de données haute performance en Python. Sa vitesse et ses optimisations de performances en font un choix idéal pour traiter efficacement de grands ensembles de données.
Avec sa syntaxe expressive et ses structures DataFrame, Polars offre une interface familière et intuitive pour les tâches de manipulation de données. En outre, Polars s'intègre parfaitement à d'autres bibliothèques Python telles que NumPy et PyArrow, ce qui élargit ses capacités et permet aux utilisateurs de tirer parti d'un écosystème diversifié d'outils.
La possibilité de convertir les DataFrames Polars en DataFrames pandas garantit l'interopérabilité et facilite l'intégration de Polars dans les flux de travail existants. Que vous travailliez avec des types de données complexes, que vous manipuliez de grands ensembles de données ou que vous cherchiez à améliorer les performances, Polars fournit une boîte à outils complète pour libérer tout le potentiel de vos efforts d'analyse de données.
Les meilleurs cours de manipulation de données en Python
Cours
Cours