
Cours
Streaming de données avec AWS Kinesis et Lambda
4 h
9.2K
Si vous créez des applications modernes, vous savez à quel point il est important de traiter efficacement de grands volumes de données. Les plateformes de streaming d'événements sont la solution idéale pour le traitement et l'analyse des données en temps réel.
Dans cet article, nous allons explorer deux des plateformes les plus populaires dans ce domaine : Apache Kafka et Amazon Simple Queue Service (SQS). Nous comparerons les forces et les faiblesses de chaque plateforme et fournirons des informations pratiques pour vous aider à prendre des décisions éclairées pour vos projets axés sur les données.
Pour ceux qui savent précisément ce qu'ils recherchent et qui veulent juste une comparaison rapide entre Apache Kafka et Amazon SQS, le tableau ci-dessous servira de guide concis. Toutefois, si vous recherchez une comparaison plus détaillée, poursuivez votre lecture pour obtenir un comparatif complet.
|
Catégorie |
Kafka |
SQS |
Gagnant |
|
Architecture |
Distribué, pub-sub |
Centralisé, basé sur la traction |
Kafka |
|
Évolutivité |
Hautement évolutif pour les grands volumes |
Hautement évolutif pour les petits volumes |
Kafka pour les grandes entreprises, SQS pour les petites entreprises |
|
Persistance des messages |
Périodes de rétention configurables |
Périodes de conservation limitées |
Kafka |
|
Remise des messages |
Au moins une fois, exactement une fois avec les transactions |
Au moins une fois, exactement une fois avec déduplication |
Cravate |
|
Groupes de consommateurs |
Soutenu |
Non pris en charge |
Kafka |
|
Integration |
Vaste écosystème, connecteurs |
Intégration étroite avec AWS |
Kafka pour les sites non-AWS, SQS pour les sites AWS |
|
Facilité d'utilisation |
Courbe d'apprentissage plus prononcée |
Entièrement géré, plus facile à démarrer |
SQS |
|
Coût |
Logiciels libres, coûts d'infrastructure |
Pay-as-you-go |
SQS pour les petites charges de travail, Kafka pour les plus grandes. |
|
Conservation des messages |
Plus long |
14 jours |
Kafka |
|
Soutien au protocole |
Multiple |
Limitée |
Kafka |
|
Difficultés syntaxiques |
Plus complexe |
Simple et direct |
SQS |
Les plateformes de flux d'événements comme Apache Kafka et Amazon SQS sont des choix de premier ordre dans les environnements modernes axés sur les données. Ils vous permettent de collecter, de traiter et d'analyser les données au fur et à mesure qu'elles sont générées, ce qui accélère la prise de décision et améliore la réactivité.
Voici quelques-unes des raisons pour lesquelles les plateformes de d'événements comme Kafka et SQS comme Kafka et SQS sont importantes :
Les plateformes de flux d'événements permettent de collecter des données en continu et de les traiter en temps réel. Cette capacité est utile pour les applications qui requièrent des informations et des actions immédiates, telles que les systèmes financiers, la détection des fraudeset la surveillance des médias sociaux. En traitant les données au fur et à mesure qu'elles arrivent, vous pouvez prendre des décisions opportunes et réagir rapidement aux événements qui se présentent.
Ces plateformes prennent en charge la communication asynchrone, en découplant les producteurs et les consommateurs de données. Ce découplage permet aux différents composants du système de fonctionner de manière indépendante, ce qui améliore la résilience et la flexibilité. La communication asynchrone permet également aux services de s'adapter de manière indépendante et d'évoluer sans perturber les autres composants.
Kafka et SQS sont tous deux conçus pour offrir une grande évolutivité et une grande fiabilité. Kafka peut gérer des millions d'événements par seconde en s'adaptant horizontalement par l'ajout de courtiers supplémentaires. SQS s'adapte automatiquement à l'augmentation des volumes de messages, ce qui lui permet de s'adapter à des charges de travail variées. Ces capacités garantissent que les plateformes peuvent répondre aux exigences des tâches de traitement de données à grande échelle.
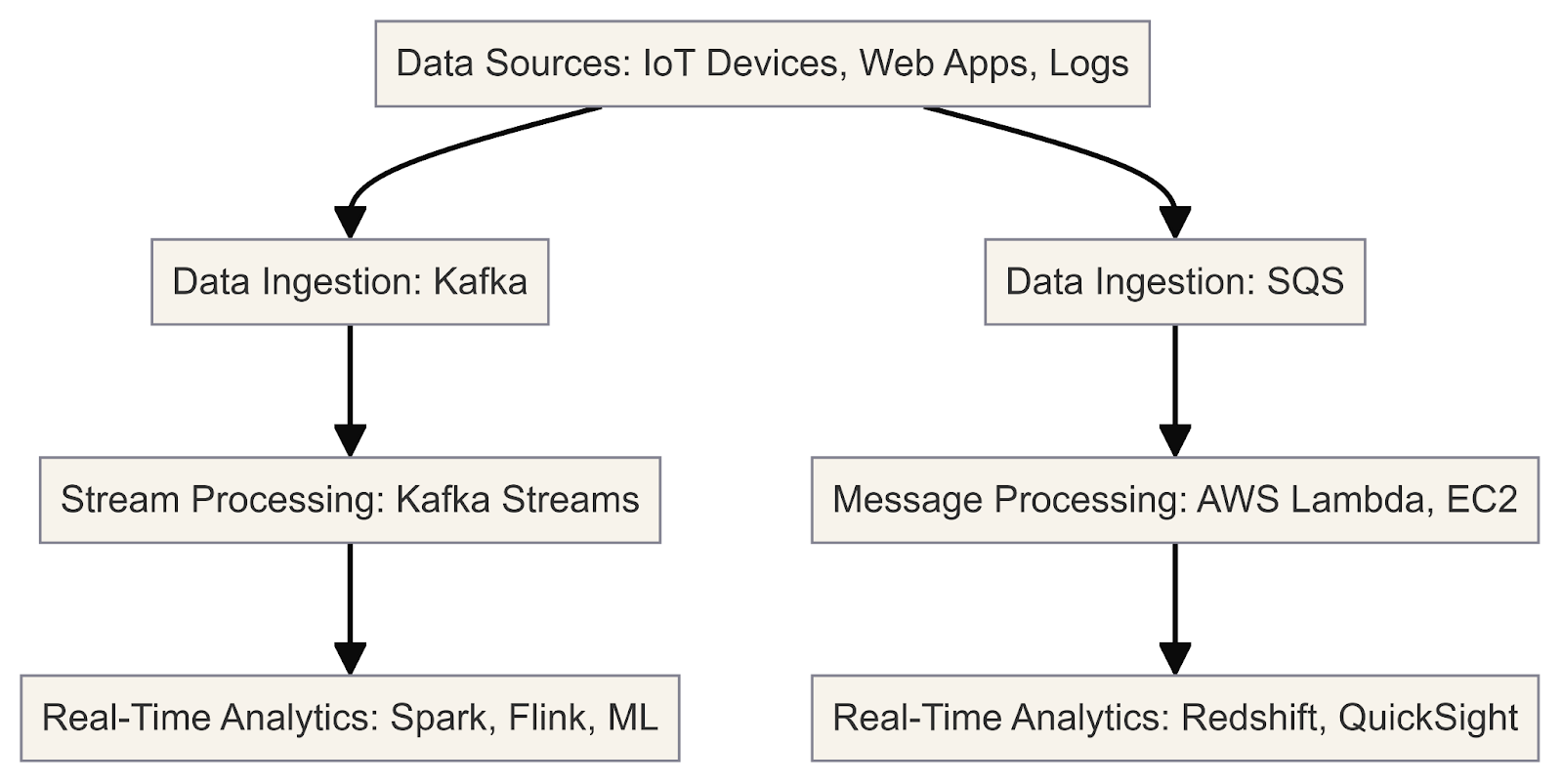
Ce diagramme illustre le processus de traitement et d'analyse des données en temps réel à l'aide de Kafka et de SQS.
Maintenant que nous avons clarifié l'importance des plateformes de streaming, examinons Kafka et SQS en détail.
Apache Kafka est une plateforme open-source de streaming d'événements distribués conçue pour traiter de grands volumes de données en temps réel. Il est souvent utilisé pour des tâches telles que la messagerie, l'agrégation de journaux, le traitement de flux et les journaux de validation.
L'architecture de Kafka est conçue pour offrir une grande évolutivité et une grande tolérance aux pannes, ce qui en fait une solution de choix pour les applications axées sur les données. Considérez Kafka comme un pipeline de données haute performance qui vous permet de créer facilement des données en temps réel et des applications.
En tant que développeur, vous pouvez exploiter les composants de base de Kafka pour gérer efficacement les flux de données en temps réel. Voici un exemple pratique du fonctionnement de Kafka avec Python :
Visitez le site web d'Apache Kafka et téléchargez la dernière version. Choisissez le téléchargement binaire correspondant à votre système d'exploitation.
Extrayez l'archive téléchargée dans un répertoire de votre choix. Ce répertoire sera votre répertoire d'installation de Kafka.
Dans un terminal, naviguez jusqu'au répertoire Kafka extrait et démarrez les services Zookeeper et Kafka broker en utilisant les scripts fournis :
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka broker
bin/kafka-server-start.sh config/server.propertiesNotez que Zookeeper est actuellement considéré comme obsolète et qu'il devrait être supprimé dans Apache Kafka 4.0. Pour plus de détails, consultez la documentation.
Les courtiers sont les serveurs Kafka qui gèrent le stockage et la réplication des flux de données. Vous pouvez interagir avec les courtiers à l'aide d'outils de ligne de commande ou par programmation à l'aide de bibliothèques clientes.
Voici un exemple d'utilisation d'outils en ligne de commande pour gérer et interagir avec les sujets Kafka :
bin/kafka-topics.sh --create --topic my_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1bin/kafka-topics.sh --list --bootstrap-server localhost:9092bin/kafka-console-producer.sh --topic my_topic --bootstrap-server localhost:9092bin/kafka-console-consumer.sh --topic my_topic --bootstrap-server localhost:9092 --from-beginningAssurez-vous que vous avez installé Python est installé sur votre système. Les bibliothèques client Python de Kafka prennent en charge Python 3.7 et les versions ultérieures.
Créez un environnement virtuel pour isoler les dépendances de votre projet. Vous pouvez utiliser venv.
Il s'agit de la bibliothèque client officielle Apache Kafka Python :
pip install kafka-pythonEn fonction des exigences de votre projet, vous devrez peut-être installer des bibliothèques supplémentaires, telles que json, pour la sérialisation/désérialisation JSON.
Utilisez ensuite le script suivant pour dresser la liste des courtiers de manière programmatique :
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# List the available brokers
brokers = admin_client.describe_cluster()
print("Brokers:", brokers['brokers'])Les partitions sont un moyen pour Kafka d'assurer le parallélisme et l'évolutivité. Chaque partition est une séquence ordonnée et immuable d'enregistrements qui est continuellement complétée. Vous pouvez configurer le nombre de partitions d'un thème lors de sa création :
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# Create a new topic with 3 partitions
topic = NewTopic(name="social-media-posts", num_partitions=3, replication_factor=1)
admin_client.create_topics([topic])Comprendre les partitions peut vous aider à optimiser vos applications pour de meilleures performances et une meilleure tolérance aux pannes.
Avec Kafka et les bibliothèques Python requises installées, vous pouvez maintenant commencer à écrire vos applications productrices et consommatrices Kafka en Python.
Voici un exemple de la façon dont vous pouvez créer un producteur Kafka pour publier des messages sur les médias sociaux et un consommateur pour les traiter :
Les producteurs sont les clients qui publient des flux de données dans les sujets Kafka. Ils peuvent être intégrés dans vos applications, services ou sources de données pour envoyer des données dans Kafka en temps réel.
from kafka import KafkaProducer
import json
# Create a Kafka producer
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('utf-8'))
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Publish the social media post to the 'social-media-posts' topic
producer.send('social-media-posts', social_media_post)Les consommateurs sont les clients qui s'abonnent à un ou plusieurs sujets et consomment les flux de données de Kafka. Ils peuvent mettre en œuvre différents modèles de consommation en fonction des exigences de votre application.
from kafka import KafkaConsumer
import json
# Create a Kafka consumer
consumer = KafkaConsumer('social-media-posts',
bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
# Consume and process social media posts
for message in consumer:
social_media_post = message.value
print(f"Received post: {social_media_post}")
# Process the social media post...Cet exemple de code donne un aperçu complet de l'installation de Kafka, de la configuration de l'environnement Python et de la mise en œuvre des producteurs et des consommateurs Kafka pour le traitement des données en temps réel.
SQS est un service de mise en file d'attente service de mise en file d'attente des messages fourni par AWS. Il vous permet de découpler et de mettre à l'échelle des microservices, des systèmes distribués et des applications sans serveur.
À la base, SQS est un système de file d'attente distribué qui vous permet d'envoyer, de stocker et de recevoir des messages entre des composants logiciels de manière asynchrone. Ces messages peuvent être des données textuelles, des notifications système ou même des pointeurs vers des données plus importantes stockées dans d'autres services AWS tels que S3 ou DynamoDB.
L'un des principaux avantages de SQS est qu'il vous dispense de gérer votre infrastructure de mise en file d'attente des messages. AWS s'occupe de la gestion des files d'attente, de la mise à l'échelle et de la tolérance aux pannes, ce qui vous permet de vous concentrer sur la logique de votre application.
SQS propose deux types de files d'attente :
L'un des avantages de SQS est qu'il fait partie de l'écosystème AWS. l'écosystème AWSet qu'il peut donc facilement s'intégrer à d'autres services AWS. La manière dont cette intégration s'effectue dépend du fait que le service est producteur ou consommateur :
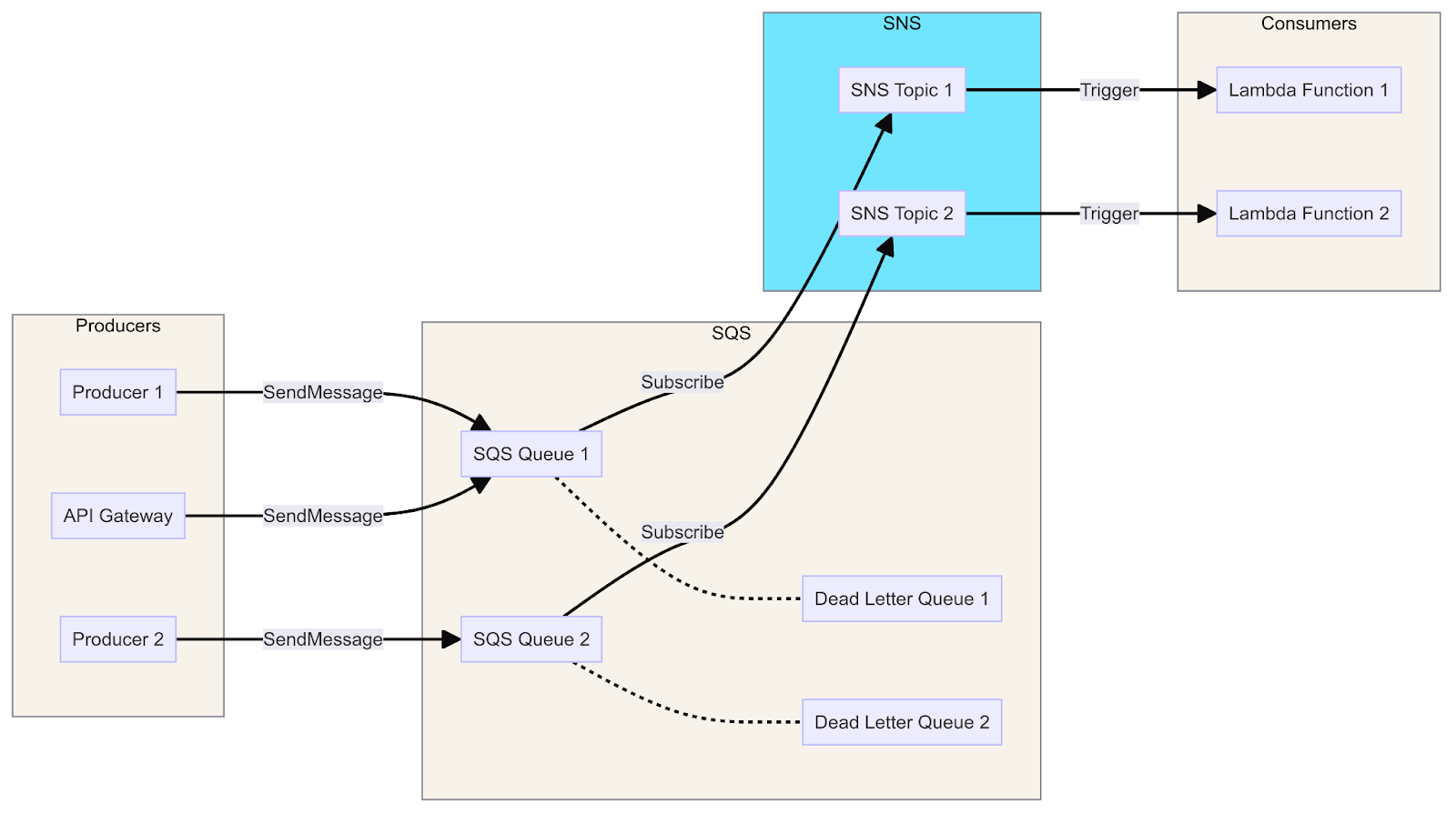
Un diagramme montrant l'intégration de SQS avec Lambda, SNS et API Gateway, illustre le flux de messages des producteurs vers les consommateurs via les files d'attente, les sujets et les fonctions.
Voyons maintenant les producteurs et les consommateurs en action. Voici un guide pour configurer et utiliser AWS SQS avec Python, y compris les étapes de base pour l'installation et un exemple de producteur et de consommateur pour SQS :
Si vous n'en avez pas encore, créez un compte AWS à l'adresse suivante AWS Free Tier.
Installez et configurez l'interface de ligne de commande AWS (CLI) pour gérer vos ressources AWS.
# Install AWS CLI
pip install awscli
# Configure AWS CLI with your credentials
aws configureIndiquez votre clé d'accès AWS, votre clé secrète, votre région et le format de sortie lorsque vous y êtes invité.
Nous utiliserons le logiciel boto3 le SDK officiel d'AWS pour Python, pour interagir avec SQS en utilisant Python.
boto3pip install boto3Créez une file d'attente SQS à l'aide de la console de gestion AWS ou par programmation à l'aide de boto3.
import boto3
# Create SQS client
sqs = boto3.client('sqs')
# Create a new queue
response = sqs.create_queue(
QueueName='social-media-posts',
Attributes={
'DelaySeconds': '0',
'MessageRetentionPeriod': '86400' # 1 day
}
)
print(response['QueueUrl'])Un producteur envoie des messages à la file d'attente SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Send message to SQS queue
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(social_media_post)
)
print(response['MessageId'])Un consommateur reçoit et traite les messages de la file d'attente SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Receive messages from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=10,
WaitTimeSeconds=10
)
if 'Messages' in response:
for message in response['Messages']:
social_media_post = json.loads(message['Body'])
print(f"Received post: {social_media_post}")
# Process the social media post...
# Delete received message from queue
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=message['ReceiptHandle']
)
else:
print('No messages received')C'est ainsi que vous pouvez facilement créer une file d'attente SQS, envoyer des messages en tant que producteur et recevoir des messages en tant que consommateur. L'exemple précédent couvre les étapes de base pour vous aider à démarrer.
Pour plus de détails sur les étapes de configuration, consultez la documentation AWS SQS.
Comparons maintenant Kafka et SQS côte à côte et voyons leurs similitudes.
Kafka et SQS sont tous deux des systèmes de mise en file d'attente de messages conçus pour faciliter la communication asynchrone entre les différents composants d'un système distribué. Ils agissent comme des intermédiaires, permettant aux producteurs d'envoyer des messages et aux consommateurs de recevoir et de traiter ces messages.
Kafka et SQS découplent les producteurs et les consommateurs, ce qui leur permet de fonctionner et d'évoluer de manière indépendante. Ce découplage favorise le couplage lâche, la tolérance aux pannes et l'évolutivité des systèmes distribués.
Kafka et SQS fournissent tous deux des mécanismes de persistance des messages, garantissant que les messages ne sont pas perdus en cas de défaillance ou de redémarrage du système. Kafka stocke les messages dans un journal distribué, tandis que SQS les stocke dans une file d'attente hautement durable et disponible.
Kafka et SQS sont conçus pour être des systèmes hautement évolutifs. Kafka peut évoluer horizontalement en ajoutant des courtiers au cluster, tandis que SQS peut évoluer automatiquement pour gérer des volumes de messages croissants.
Kafka et SQS offrent tous deux des capacités d'intégration avec d'autres systèmes et services. Kafka dispose d'un vaste écosystème de connecteurs et d'intégrations, tandis que SQS s'intègre de manière transparente à d'autres services AWS.
Bien que Kafka et SQS offrent des garanties d'ordre différentes par défaut, les deux systèmes fournissent des mécanismes permettant de préserver l'ordre des messages lorsque cela est nécessaire. Kafka offre une livraison ordonnée au sein des partitions, tandis que SQS propose des files d'attente FIFO pour un traitement des messages strictement ordonné.
Kafka et SQS offrent des fonctionnalités de surveillance et de métriques, permettant aux utilisateurs de suivre et de contrôler les performances et la santé de leurs systèmes de messagerie.
Kafka et SQS offrent tous deux des fonctions de sécurité, telles que le chiffrement, le contrôle d'accès et les mécanismes d'authentification, afin de protéger les données en transit et au repos.
Comparons maintenant Kafka et SQS côte à côte et notons leurs principales différences.
Kafka est une plateforme de diffusion en continu distribuée qui suit un modèle de publication et d'abonnement. Il se compose d'une grappe de courtiers qui stockent et gèrent des flux de données dans des thèmes. Les producteurs publient des messages dans des rubriques et les consommateurs s'abonnent à des rubriques pour recevoir des messages.
SQS est un service de messagerie entièrement géré fourni par AWS. Il suit un modèle basé sur une file d'attente où les messages sont envoyés à une file d'attente et où les consommateurs interrogent la file d'attente pour recevoir des messages.
Kafka propose une sémantique de livraison "at-least-once", ce qui signifie que les messages peuvent être livrés une ou plusieurs fois. Il prend également en charge la livraison "exactement une fois" grâce à l'utilisation de producteurs idempotents et d'écritures transactionnelles.
La SQS garantit une livraison "au moins une fois". Pour les autres protocoles tels que HTTP/HTTPS, le courrier électronique et les SMS, Amazon SNS doit être utilisé conjointement avec SQS.
Kafka maintient l'ordre des messages dans les partitions, garantissant que les messages sont livrés dans l'ordre où ils ont été produits.
Par défaut, SQS ne garantit pas l'ordre des messages. Toutefois, il prend en charge les sujets FIFO, qui préservent l'ordre exact des messages.
Kafka stocke les messages sur disque dans un journal d'engagement distribué, ce qui garantit la durabilité et la tolérance aux pannes. Les messages peuvent être conservés pendant une période configurable, ce qui permet aux consommateurs de revenir en arrière et de réécouter les messages.
SQS n'assure pas la persistance des messages à long terme. Les messages sont stockés temporairement jusqu'à ce qu'ils soient distribués à tous les abonnés ou jusqu'à ce qu'ils expirent (en fonction de la période de conservation configurée).
Kafka est conçu pour évoluer horizontalement en ajoutant des courtiers au cluster. Il prend également en charge le partitionnement des sujets pour le parallélisme et l'équilibrage de la charge.
SQS est un service entièrement géré qui s'adapte automatiquement à l'augmentation des volumes de messages sans nécessiter d'intervention manuelle.
Kafka dispose d'un riche écosystème de connecteurs et d'intégrations avec diverses sources de données, puits et frameworks de traitement, tels que Apache Spark, Apache Flink et Apache Kafka Streams.
SQS s'intègre de manière transparente à d'autres services AWS, ce qui vous permet d'envoyer des notifications à différents points de terminaison, notamment des fonctions AWS Lambda, des files d'attente SQS et des points de terminaison HTTP/HTTPS.
Kafka utilise principalement des outils d'interface en ligne de commande tels que kafka-topics pour gérer les sujets et d'autres tâches administratives. Il n'y a pas d'interface utilisateur intégrée dédiée, mais des outils tiers tels que Kafka Manager, Kafka Tool et Confluent Control Center offrent des interfaces web pour gérer les clusters Kafka.
SQS, en tant que service entièrement géré, s'intègre parfaitement à la console de gestion AWS. Cette interface web permet aux utilisateurs de créer, de configurer et de surveiller facilement les files d'attente SQS sans avoir besoin d'outils supplémentaires.
Kafka propose des bibliothèques clientes pour différents langages, tels que Java, Python et Go. Sa syntaxe peut être complexe en raison de concepts tels que les sujets, les partitions, les décalages et les groupes de consommateurs.
SQS fournit des SDK pour plusieurs langages, notamment Java, Python et Node.js. Sa syntaxe est plus simple et se concentre sur l'envoi et la réception de messages vers et depuis des files d'attente. La syntaxe de SQS est plus simple, tandis que celle de Kafka est plus complexe en raison de sa nature distribuée et de ses fonctionnalités avancées.
La tarification de Kafka varie en fonction du modèle de déploiement (autogéré ou services gérés comme Confluent Cloud ou Amazon MSK).
SQS suit un modèle de tarification "pay-as-you-go" basé sur le nombre de requêtes et de transferts de données.
Après avoir passé en revue les similitudes et les différences, voici une comparaison détaillée entre Apache Kafka et Amazon SQS, en mettant l'accent sur celui qui l'emporte dans chaque catégorie, selon le cas.
Kafka est un système de messagerie distribué, pub-sub, qui fonctionne sur une architecture de journal distribué, où les messages sont conservés dans un journal de validation distribué.
D'autre part, SQS est un système de messagerie à tirage entièrement géré qui repose sur une architecture de courtier de messages, avec un service central orchestrant la gestion des files d'attente.
L'architecture distribuée de Kafka la rend plus évolutive et tolérante aux pannes, tandis que l'architecture centralisée de SQS simplifie la gestion mais peut devenir un goulot d'étranglement.
Kafka et Amazon SQS offrent tous deux une grande évolutivité. Kafka est connu pour ses capacités de diffusion en continu à haut débit, tolérantes aux pannes et extensibles horizontalement. Il peut traiter d'importants volumes de données et offre des périodes de conservation des données étendues.
Amazon SQS est réputé pour sa capacité à gérer des millions de messages par seconde et à s'adapter automatiquement aux variations de trafic.
Kafka est plus évolutif pour traiter de gros volumes de données et fournir des périodes de rétention plus longues, tandis que SQS est plus facile à faire évoluer automatiquement pour les petites charges de travail.
Kafka est conçu pour assurer la persistance des données grâce à son système de journaux répliqués. Il offre une grande flexibilité en permettant de configurer à la fois la période de rétention et l'espace disque utilisé pour le stockage des données.
D'autre part, SQS assure la persistance des messages en les stockant dans plusieurs centres de données, ce qui améliore la durabilité du système. Il est livré avec une période de conservation par défaut de 4 jours, qui peut être ajustée jusqu'à un maximum de 14 jours en fonction des besoins de l'utilisateur.
Les deux plateformes offrent une persistance des messages, mais Kafka offre plus de flexibilité dans la configuration des périodes de rétention et du stockage.
Apache Kafka et Amazon SQS offrent tous deux de solides capacités de messagerie avec livraison garantie. Kafka garantit la livraison des messages "au moins une fois" et peut atteindre une sémantique "exactement une fois" grâce à des mécanismes tels que l'écriture idempotente de messages et le support transactionnel.
D'autre part, SQS assure également la livraison des messages "au moins une fois" et fournit une sémantique de livraison "exactement une fois" grâce à ses mécanismes de déduplication.
Les deux plateformes offrent des garanties similaires en matière de livraison de messages, Kafka proposant des fonctionnalités plus avancées telles que les écritures idempotentes et les transactions.
L'une des principales différences entre Kafka et SQS est la manière dont ils gèrent la consommation des messages.
Kafka utilise des groupes de consommateurs pour une lecture indépendante à partir de différentes partitions, ce qui permet l'équilibrage de la charge et la tolérance aux pannes. SQS ne dispose pas d'un support intégré pour les groupes de consommateurs, de sorte que des files d'attente distinctes sont nécessaires pour chaque consommateur afin d'obtenir une fonctionnalité similaire.
Cela montre les différentes approches adoptées par Kafka et SQS pour gérer les interactions entre les consommateurs et les messages.
La prise en charge des groupes de consommateurs par Kafka le rend plus adapté aux scénarios impliquant des consommateurs multiples et un équilibrage de la charge.
Kafka dispose d'un écosystème d'intégration plus large et propose des connecteurs pour différents systèmes de données et frameworks. D'autre part, SQS est étroitement intégré aux autres services AWS, ce qui permet de l'incorporer facilement dans toute architecture basée sur AWS.
SQS l'emporte pour les architectures basées sur AWS, tandis que Kafka offre plus de souplesse pour l'intégration avec des systèmes et des cadres non AWS.
Lorsque l'on compare Kafka et SQS, il est clair qu'ils répondent à des besoins différents. Kafka est un peu plus exigeant en termes d'installation et de configuration, et présente une courbe d'apprentissage plus raide, en particulier lorsque l'on aborde les concepts des systèmes distribués.
D'autre part, la SQS se distingue par sa simplicité. En tant que service entièrement géré, il nécessite une installation et une configuration minimales, ce qui en fait un choix plus accessible pour les cas d'utilisation simples.
SQS est plus facile à utiliser et à démarrer, tandis que Kafka nécessite plus d'expertise en matière de systèmes distribués et de configuration.
Kafka, une plateforme open-source, nécessite un investissement dans l'infrastructure et la gestion, mais elle peut être plus rentable pour gérer des charges de travail à grande échelle. D'autre part, SQS offre un service entièrement géré avec un modèle de tarification à la carte, ce qui le rend potentiellement plus économique pour les petites charges de travail.
SQS est généralement plus rentable pour les petites charges de travail, tandis que Kafka peut être plus rentable pour les charges de travail à grande échelle, en fonction des coûts d'infrastructure et de gestion.
Pour comprendre Kafka, il faut se plonger dans les systèmes distribués et le traitement des flux. Il est riche en concepts tels que les thèmes, les partitions, les décalages et les groupes de consommateurs. En revanche, SQS dispose d'une API conviviale qui facilite l'envoi et la réception de messages à partir de files d'attente grâce à des kits de développement logiciel (SDK) dans plusieurs langages de programmation.
La SQS l'emporte en termes de difficulté syntaxique. Il offre une API plus simple et plus conviviale, ce qui facilite son intégration dans les applications. La syntaxe de Kafka peut être plus complexe en raison de sa nature distribuée et de ses fonctions de streaming avancées.
|
Kafka |
SQS |
|
Distribué, pub-sub |
Centralisé, basé sur la traction |
|
Hautement évolutif pour les grands volumes |
Hautement évolutif pour les petits volumes |
|
Périodes de rétention configurables |
Périodes de conservation limitées |
|
Au moins une fois, exactement une fois avec les transactions |
Au moins une fois, exactement une fois avec déduplication |
|
Soutenu |
Non pris en charge |
|
Vaste écosystème, connecteurs |
Intégration étroite avec AWS |
|
Courbe d'apprentissage plus prononcée |
Entièrement géré, plus facile à démarrer |
|
Logiciels libres, coûts d'infrastructure |
Pay-as-you-go |
|
Plus long |
14 jours |
|
Multiple |
Limitée |
|
Plus complexe |
Simple et direct |
En conclusion, si vous avez besoin d'un service géré et rapide à déployer qui s'intègre bien dans l'écosystème AWS, AWS SQS est votre meilleur choix. Il simplifie la gestion des files d'attente et s'adapte sans effort, ce qui le rend idéal pour de nombreuses applications standard.
Par ailleurs, si votre projet exige un débit élevé, une faible latence et la possibilité d'ajuster votre système, Apache Kafka offre une grande souplesse pour la diffusion et le traitement de données en temps réel.
Le choix de l'outil adéquat dépend des besoins spécifiques de votre projet, notamment de facteurs tels que la facilité d'utilisation, les performances, l'évolutivité et l'intégration. Kafka et SQS ont tous deux leurs points forts, et leur compréhension vous aidera à tirer parti de la meilleure plateforme pour votre prochain projet axé sur les données !
Pour continuer à vous informer sur ces sujets, consultez les ressources suivantes :
Apprenez-en plus sur l'infrastructure et la gestion des données de streaming grâce à ces cours !
Cours
Cours
Cours