
Cours
Introduction au data engineering
4 h
127.6K
De nombreuses entreprises modernes s'appuient sur des couches sémantiques pour combler le fossé entre les données brutes stockées dans des entrepôts de données tels que Snowflake et les informations contenues dans les tableaux de bord ou les rapports.
Une couche sémantique est une abstraction qui définit des métriques, des mesures et des dimensions cohérentes pour les analyses et les rapports.
Dans ce tutoriel, nous verrons comment mettre en place une couche sémantique en utilisant dbt (data build tool), un cadre populaire de transformation et de modélisation des données. Ce guide contient des exemples pratiques et des idées pour vous aider à maîtriser le concept.
Une couche sémantique traduit les données brutes en mesures et dimensions cohérentes et réutilisables, ce qui simplifie l'analyse des données. Il s'agit d'un outil permettant de maintenir l'uniformité entre les équipes et les outils.
Voyons ce qui fait de dbt l'outil idéal pour permettre aux ingénieurs en données et en analyse de construire une couche sémantique.
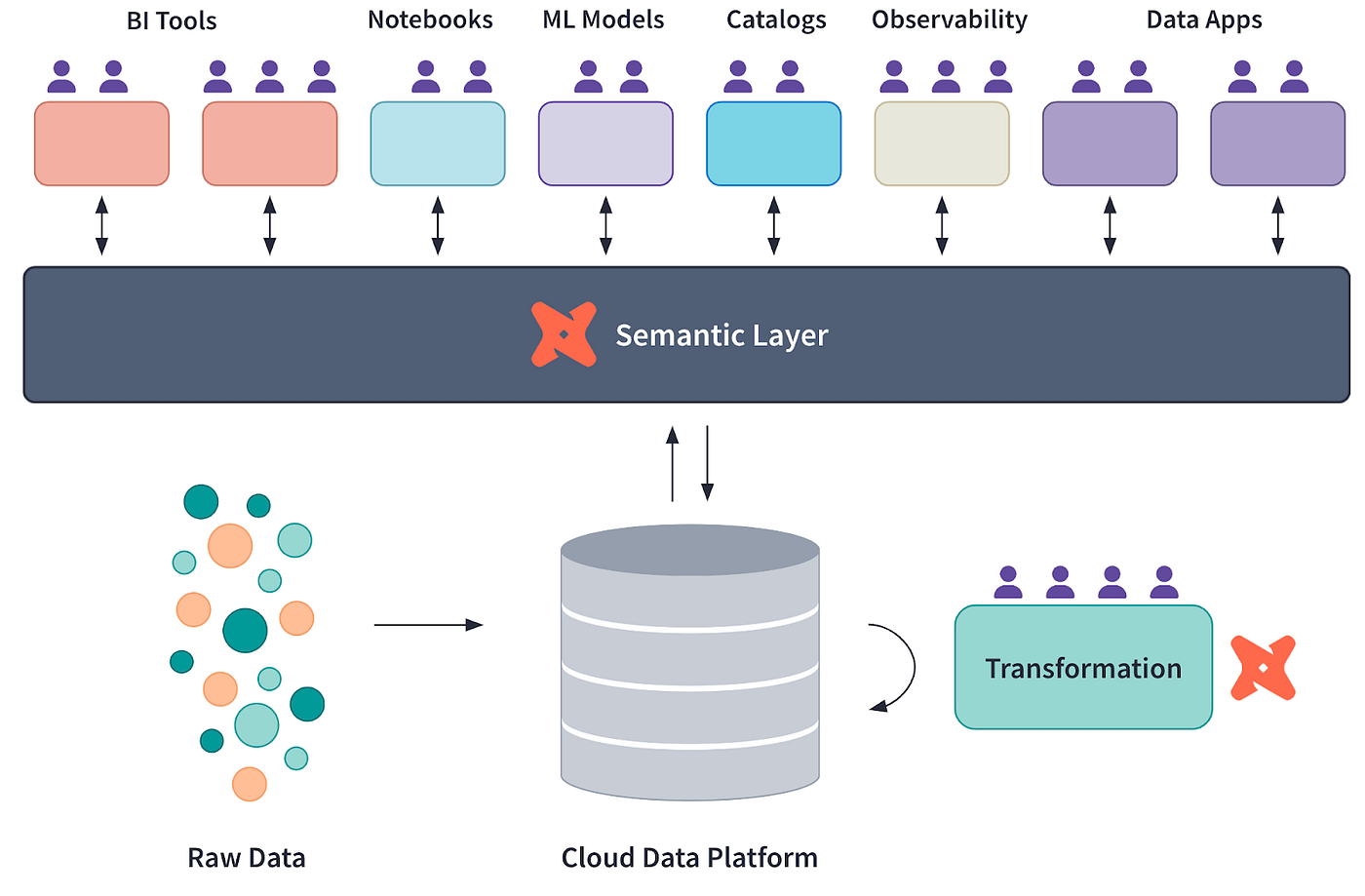
Diagramme conceptuel de la couche sémantique de dbt, courtesy of dbt Labs
dbt vous permet de décomposer des transformations de données complexes en modèles modulaires réutilisables. Ces modèles peuvent être hiérarchisés, les modèles de données fondamentaux alimentant des modèles analytiques de niveau supérieur.
Cette approche facilite la maintenance du pipeline et permet aux équipes de collaborer plus efficacement en isolant les changements apportés à des modèles spécifiques sans avoir d'impact sur l'ensemble du système.
Pour en savoir plus sur les concepts fondamentaux de dbt et les meilleures pratiques en matière de modélisation des données, consultez le didacticiel dbt : 7 Concepts incontournables pour les ingénieurs de données. Il offre des perspectives qui complètent les stratégies décrites ici.
Avec dbt, la logique d'entreprise et les mesures sont définies en un seul endroit, ce qui garantit la cohérence entre les différents outils d'analyse. En utilisant la fonction métrique de dbt, vous pouvez définir des indicateurs clés de performance (KPI) tels que les revenus, les taux de conversion ou le taux de désabonnement une fois pour toutes et les utiliser dans les tableaux de bord, les rapports et les analyses sans avoir à les redéfinir. Cela permet de réduire les divergences et de garantir l'intégrité des données.
L'intégration de dbtavec Git facilite un contrôle de version robuste, vous permettant de suivre et d'auditer les modifications au fil du temps. Associé à sa documentation auto-générée, dbt crée une référence vivante et accessible pour toutes les transformations de donnéesns et métriques. Cela favorise la transparence et permet aux nouveaux membres de l'équipe de s'intégrer rapidement en explorant le pipeline de données documenté.
dbt fonctionne avec des plateformes de BI telles que Looker, Tableau et Mode, ce qui permet d'intégrer la couche sémantique dans les outils de visualisation. En utilisant les expositions dbt, vous pouvez relier directement les modèles dbt aux tableaux de bord BI, garantissant ainsi que toute mise à jour des modèles de données est reflétée dans les analyses sans intervention manuelle.
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours