
Cursus
Développer des LLM
16 h
La nouvelle famille de modèles à code source ouvert de Google, Gemma 3, gagne rapidement en popularité grâce à ses performances impressionnantes, comparables à celles de certains des derniers modèles propriétaires. Gemma 3 introduit des fonctionnalités multimodales, des capacités de raisonnement améliorées et prend en charge plus de 140 langues.
Dans ce tutoriel, nous allons explorer les capacités de Gemma 3 et apprendre à l'affiner sur un ensemble de données de questions-réponses de raisonnement financier. Ce processus de mise au point améliorera considérablement la précision du modèle dans la compréhension de questions financières complexes et lui permettra de fournir des réponses précises et adaptées au contexte.
Vous êtes novice en matière d'affinage des MLD ? Ne vous inquiétez pas, nous vous couvrons ! Suivez notre tutoriel facile à comprendre, Fine-Tuning LLMs : Un guide avec des exemples, pour apprendre comment fonctionne le réglage fin.
Vous pouvez également suivre le cours Introduction aux LLM en Python pour en savoir plus sur le fonctionnement des LLM, sur la manière de les affiner et sur l'évaluation de leurs performances.

Image par l'auteur
La famille de modèles ouverts Gemma représente une avancée significative pour rendre la technologie de pointe de l'IA accessible à tous. Construit à partir de la recherche et de la technologie des modèles Gemini 2.0, Gemma 3 offre des performances de pointe tout en restant léger et efficace.
Avec des tailles allant de 1 milliard à 27 milliards de paramètres, Gemma 3 offre une grande flexibilité en termes de matériel et de performances, ce qui facilite plus que jamais l'intégration de l'IA avancée dans les applications du monde réel.
Gemma 3 établit une nouvelle référence en matière de performances dans sa catégorie, surpassant des concurrents tels que Llama3-405B, DeepSeek-V3et o3-mini dans les évaluations des préférences humaines sur le tableau de classement LMArena. Sa conception légère ne fait aucun compromis sur la puissance, ce qui permet aux développeurs d'obtenir des résultats de premier ordre tout en conservant leur efficacité.
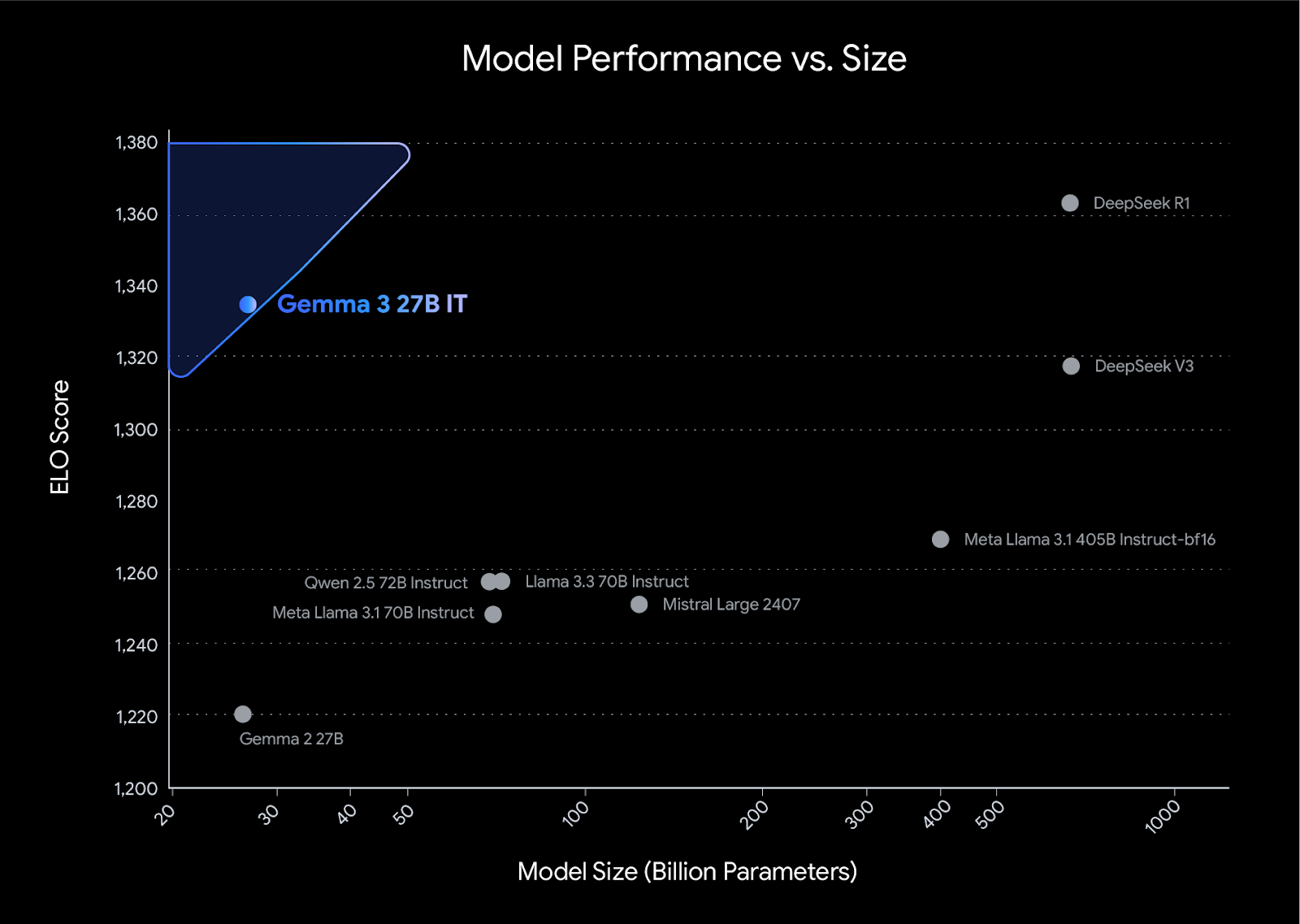
Source : Présentation de Gemma 3
Dans ce projet, nous allons charger le Gemma 3 depuis Kaggle et récupérer les données de Hugging Face. Ensuite, nous utiliserons les bibliothèques Transformers et TRL pour affiner notre modèle. À des fins de comparaison, nous produirons la réponse avant et après le réglage fin.
Si vous souhaitez apprendre à utiliser la bibliothèque Unsloth pour affiner votre modèle sur des données de raisonnement, consultez le document suivant Ajustement de DeepSeek R1 (Modèle de raisonnement) guide.
Installez toutes les bibliothèques Python nécessaires, en veillant à mettre à jour la bibliothèque transformer bibliothèque.
%%capture
!pip install -U datasets
!pip install -U accelerate
!pip install -U peft
!pip install -U trl
!pip install -U bitsandbytes
!pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3Connectez-vous au client Hugging Face à l'aide de votre clé API. La clé API est stockée en toute sécurité dans les secrets Kaggle, et nous allons l'extraire et l'appliquer au client Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Ajoutez le modèle informatique Gemma 3 4B au carnet Kaggle de la même manière que vous ajoutez l'ensemble de données en cliquant sur le bouton "+ Add Input".
Chargez le modèle et le tokenizer à l'aide de la bibliothèque transformers. Assurez-vous que le modèle est réglé sur device_map="auto" pour utiliser efficacement une configuration à double GPU.
from transformers import AutoTokenizer, Gemma3ForConditionalGeneration
import torch
GEMMA_PATH = "/kaggle/input/gemma-3/transformers/gemma-3-4b-it/1"
model = Gemma3ForConditionalGeneration.from_pretrained(
GEMMA_PATH, device_map="auto",attn_implementation='eager'
).eval()
tokenizer = AutoTokenizer.from_pretrained(GEMMA_PATH)Avant de charger l'ensemble de données, nous allons créer le style de l'invite de formation et fournir trois espaces réservés que nous remplirons avec les colonnes de l'ensemble de données. Ce style d'invite nous aidera à générer un texte de raisonnement.
train_prompt_style="""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
</think>
{}
"""Ensuite, nous allons créer la fonction de formatage qui utilise les colonnes de l'ensemble de données et les applique au style de l'invite de formation pour créer la colonne "texte". Assurez-vous d'ajouter le jeton EOS à la fin de la réponse.
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Nous allons maintenant charger le fichier L'ensemble de données TheFinAI/Fino1_Reasoning_Path_FinQA qui est un ensemble de données de raisonnement financier basé sur FinQA, enrichi de chemins de raisonnement générés par GPT-4o pour répondre à des questions financières structurées. Ensuite, nous appliquerons la fonction de formatage à l'ensemble de données et créerons la nouvelle colonne de texte façonnée par le style d'invite.
from datasets import load_dataset
dataset = load_dataset("TheFinAI/Fino1_Reasoning_Path_FinQA", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]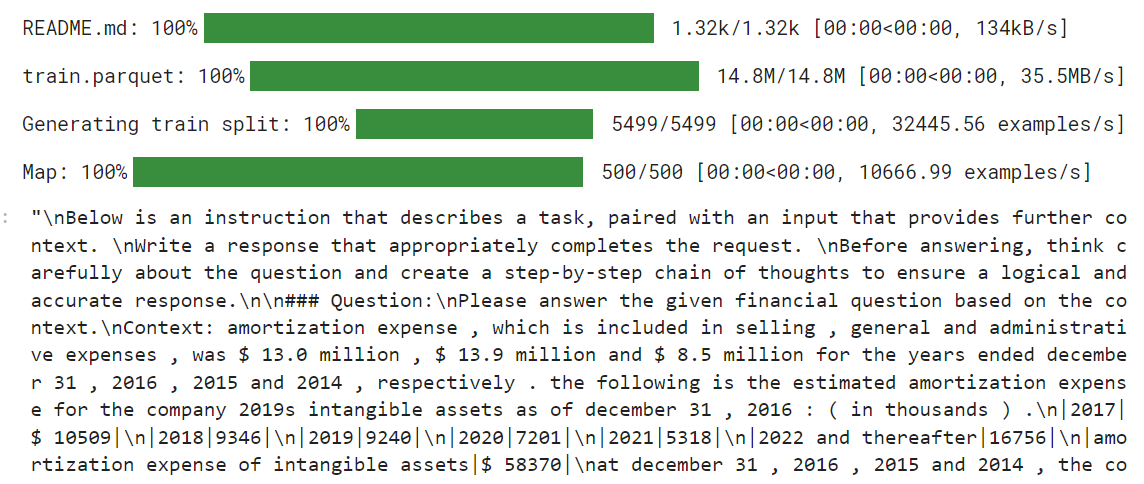
Le nouveau formateur STF n'accepte pas les tokenizers, nous devons donc créer notre collection de données en utilisant le tokenizer et la fournir au formateur plus tard.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # we're doing causal LM, not masked LM
)Avant de commencer à affiner le modèle, nous allons tester notre modèle original pour voir s'il est efficace pour générer des réponses. Nous allons créer le style d'invite avec deux espaces réservés au lieu de trois.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
"""Ensuite, nous appliquerons le style d'invite à la question, la convertirons en jetons et la fournirons au modèle. Ensuite, nous allons générer la réponse et reconvertir les jetons en texte.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La réponse est brève et loin d'être exacte.
<think>
The question asks for the portion of the estimated amortization expense that will be recognized in 2017.
The provided table shows the estimated amortization expense for intangible assets for the years 2017, 2018, 2019, 2020, 2021, and 2022 and thereafter.
The amortization expense for 2017 is $10,509.
</think>
$10,509Voici la réponse de l'ensemble de données. La réponse doit être un ratio et non un montant.
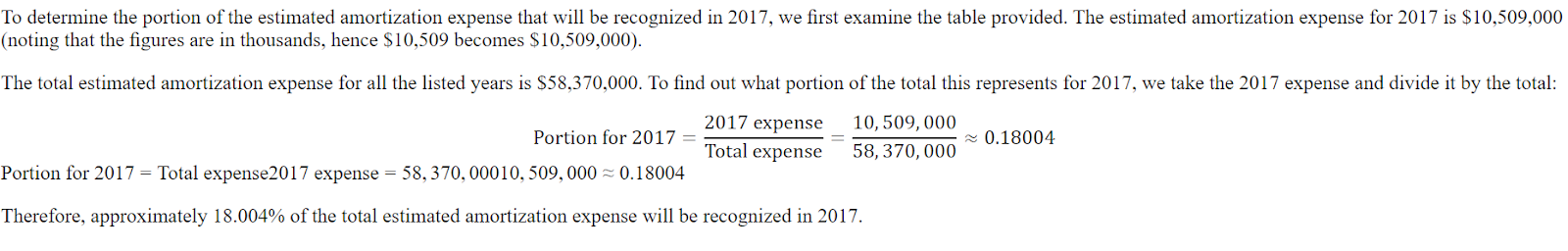
Même le ChatGPT s'est trompé, et nous avons dû lui demander de corriger l'erreur. Ensuite, il a compris qu'il avait commis une erreur et l'a corrigée.

Nous allons maintenant fournir le jeu de données, le modèle, la collecte de données, les arguments d'entraînement et la configuration de LoRA au SFTTrainer.
from trl import SFTTrainer
from transformers import TrainingArguments
from peft import LoraConfig
# LoRA Configuration
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Videz le cache CUDA avant d'entamer le processus de filtrage.
torch.cuda.empty_cache()
trainer_stats = trainer.train()Il a fallu près d'une heure et 20 minutes pour compléter une époque. Comme on peut le constater, la perte s'est progressivement réduite.
Maintenant, testons notre modèle affiné en fournissant un exemple de question comme nous l'avons fait précédemment.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La partie "raisonnement" est maintenant détaillée et correcte. La réponse est également exacte.
<think>
Alright, let's figure out what portion of the estimated amortization expense will be recognized in 2017. First, I need to see what the total estimated amortization expense is for the years 2017 through 2022. Looking at the numbers, it's $58,370.
Now, I need to find out how much of that is specifically for 2017. The table shows that the estimated amortization expense for 2017 is $10,509.
So, to find out what portion of the total expense is for 2017, I'll divide the 2017 expense by the total expense. That's $10,509 divided by $58,370.
Let's do the math: $10,509 divided by $58,370 gives me approximately 0.1805.
Now, to express this as a percentage, I'll multiply by 100. So, 0.1805 times 100 gives me 18.05%.
Therefore, about 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.
</think>
About 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.Posons une autre question.
question = dataset[10]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Comme nous pouvons le constater, nous avons réussi à affiner le modèle sur le nouvel ensemble de données. Il est maintenant précis et suit le raisonnement et le style de réponse.
<think>
Alright, let's figure out the total purchase price of Impella Cardiosystems. First, we know the purchase price was $45.1 million, but there's a contingent payment of $5.6 million that could be earned. So, we need to see if we can figure out how much of that $5.6 million is actually likely to be paid.
Now, the question mentions that the contingent payment is triggered by FDA approvals. Since we're dealing with a medical device, getting FDA clearance is pretty important. Let's assume that the FDA approval for the Impella 2.5 is a good sign that the contingent payments will be made.
Okay, so if we assume all the contingent payments are earned, we just need to add the $5.6 million to the original $45.1 million. Let's do the math: $45.1 million plus $5.6 million equals $50.7 million.
Hmm, let's double-check our work. We're adding $45.1 million to $5.6 million, which gives us $50.7 million. Yep, that seems right.
So, if we assume all the contingent payments are earned, the total purchase price of Impella Cardiosystems would be $50.7 million.
</think>
The total purchase price of Impella Cardiosystems, assuming all contingent consideration is earned, would be $50.7 million.La mise au point d'un modèle nécessite de l'expertise, de l'argent et du temps. Dans certains cas, vous pouvez simplement avoir besoin d'un meilleur pipeline RAG pour répondre à vos besoins. Veuillez lire le guide RAG vs Fine-Tuning : Un tutoriel complet avec des exemples pratiques pour comprendre vos besoins.
Tout d'abord, nous allons enregistrer le modèle et le tokenizer localement.
new_model_online = "kingabzpro/Gemma-3-4B-Fin-QA-Reasoning"
new_model_local = "Gemma-3-4B-Fin-QA-Reasoning"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local)Ensuite, nous pousserons le modèle vers le Hugging Face Hub.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online savingCe processus crée d'abord le référentiel de modèles, puis transfère tous les champs du modèle, du tokenizer et de la configuration vers le serveur distant.
Source : kingabzpro/Gemma-3-4B-Fin-QA-Reasoning - Hugging Face
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, nous avons créé un carnet Kaggle pour que chacun puisse le cloner et l'exécuter de son côté afin de mieux comprendre le processus.
La mise au point du modèle Gemma 3 ne va pas sans difficultés : vous pouvez rencontrer des problèmes de matériel, de bibliothèque, de fragmentation de la mémoire, etc. Ce guide propose une mise en œuvre plus simple de la manière dont vous pouvez convertir n'importe quel modèle en un modèle de raisonnement et éviter de faire face à des problèmes futurs liés au logiciel et au matériel.
Dans ce tutoriel, nous avons abordé les caractéristiques du modèle Gemma 3 et la manière dont nous pouvons facilement l'adapter à l'ensemble de données de raisonnement en utilisant les ressources GPU gratuites disponibles sur Kaggle.
Prenez le Réglage fin avec le lama 3 pour vous attaquer à des tâches de réglage fin à l'aide de TorchTune et apprendre des techniques de réglage fin efficaces telles que la quantification.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nisha Arya Ahmed
15 min