
Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
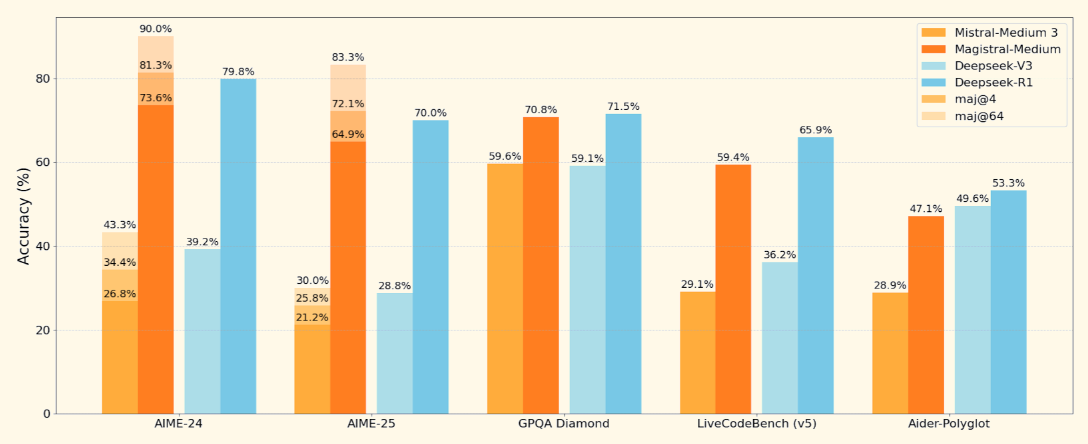
Mistral a lancé son premier modèle de raisonnement, Magistral, disponible en deux variantes : Magistral Small (poids ouvert) et Magistral Medium (modèle fermé).
Dans ce blog, je me concentrerai sur Magistral Small, un modèle de raisonnement ouvert conçu pour les tâches nécessitant une logique structurée, une compréhension multilingue et la capacité de fournir des explications traçables. Associé à des moteurs d'inférence à haut rendement comme vLLM ou à des outils faciles à utiliser comme Ollama, il devient un excellent outil pour déboguer les tâches de logique et de raisonnement défectueuses.
Dans ce tutoriel, je vous expliquerai pas à pas comment faire :
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Magistral est le premier modèle de raisonnement dédié de Mistral AI, conçu pour une logique étape par étape, une précision multilingue et des résultats traçables. Il s'agit d'un modèle à double libération qui se décline en deux variantes :
Source : Mistral
Magistral Small, le modèle ouvert sur lequel nous allons nous concentrer, supporte une fenêtre de contexte de 128K (40K recommandé pour des performances stables). Il est formé à l'aide d'une méthode supervisée supervisé sur des traces moyennes de Magistral et l'apprentissage par renforcement.
Dans cette section, nous allons effectuer l'inférence sur le modèle Magistral de Mistral localement en utilisant Ollama. Notez que ce modèle nécessite environ 14 Go d'espace et peut être installé dans une seule RTX 4090 ou un MacBook avec 32 Go de RAM une fois. quantifié. J'ai exécuté cette démo sur un MacBook Pro M3.
Téléchargez Ollama pour macOS, Windows ou Linux à partir de : https://ollama.com/download.
Suivez les instructions de l'installateur, et après l'installation, vérifiez en lançant ceci dans le terminal :
ollama --versionEnsuite, tirez le modèle Magistral en exécutant le code suivant :
ollama pull magistral
Cette opération permet de télécharger le modèle Magistral sur votre machine locale. Note : Cela prendra un certain temps, car le modèle pèse environ 14 Go.
Commençons par installer toutes les dépendances nécessaires.
pip install ollama
pip install requestsUne fois les dépendances installées, nous sommes prêts à lancer l'inférence.
Maintenant, nous mettons en place une structure de modèle d'invite (comme mentionné dans le document original de article de Magistral) qui guide la réflexion du modèle.
import gradio as gr
import requests
import json
def build_prompt(flawed_logic):
return f"""<s>[SYSTEM_PROMPT]
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and detailed as needed until you're confident.
</think>
Do not mention that you're debugging — just present your thought process and conclusion naturally.
[/SYSTEM_PROMPT][INST]
Here is a flawed solution. Can you debug it and correct it step by step?
\"\"\"{flawed_logic}\"\"\"
[/INST]
"""La fonction ci-dessus renvoie une invite formatée qui guide Magistral vers :
Cette structure est importante pour les modèles tels que Magistral, qui ont été formés à l'aide d'invites complétées par des outils. La même structure d'invite peut également être utilisée pour les problèmes mathématiques et de codage.
Dans cette étape, nous diffusons en temps réel les résultats du modèle Magistral en utilisant l'API locale d'Ollama. Puisque nous nous concentrons sur le débogage d'une logique défectueuse à l'aide d'un raisonnement traçable, étape par étape, il est important que l'utilisateur puisse voir comment le modèle arrive à ses conclusions. Enfin, nous affichons l'explication à l'aide d'un Gradio propre.
def call_ollama_stream(flawed_logic):
prompt = build_prompt(flawed_logic)
response_text = ""
with requests.post(
"http://localhost:11434/api/generate",
json={"model": "magistral", "prompt": prompt, "stream": True},
stream=True,
) as r:
for line in r.iter_lines():
if line:
content = json.loads(line).get("response", "")
response_text += content
return response_text
with gr.Blocks(theme=gr.themes.Base()) as demo:
gr.Markdown("## Chain-of-Logic Debugger (Magistral + Ollama)")
gr.Markdown("Paste a flawed logical argument or math proof, and Magistral will debug it with step-by-step reasoning.")
with gr.Row():
input_box = gr.Textbox(lines=8, label="Flawed Logic / Proof")
output_box = gr.Textbox(lines=15, label="Debugged Explanation")
debug_button = gr.Button("Run Debugger")
debug_button.click(fn=call_ollama_stream, inputs=input_box, outputs=output_box)
demo.launch(debug = True, share=True)Voici un aperçu de ce qui se passe ici :
build_prompt() pour envelopper les données de l'utilisateur dans une invite structurée qui guide le modèle à l'aide de balises de raisonnement call_ollama_stream() envoie l'invite à l'API HTTP d'Ollama à l'adresse localhost:11434 à l'aide d'une requête POST en continu.requests.iter_lines(). Pour chaque ligne reçue, il extrait le champ de réponse de la charge utile JSON et l'ajoute à un tampon de texte en cours d'exécution.Voici l'entrée que j'ai essayée :
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.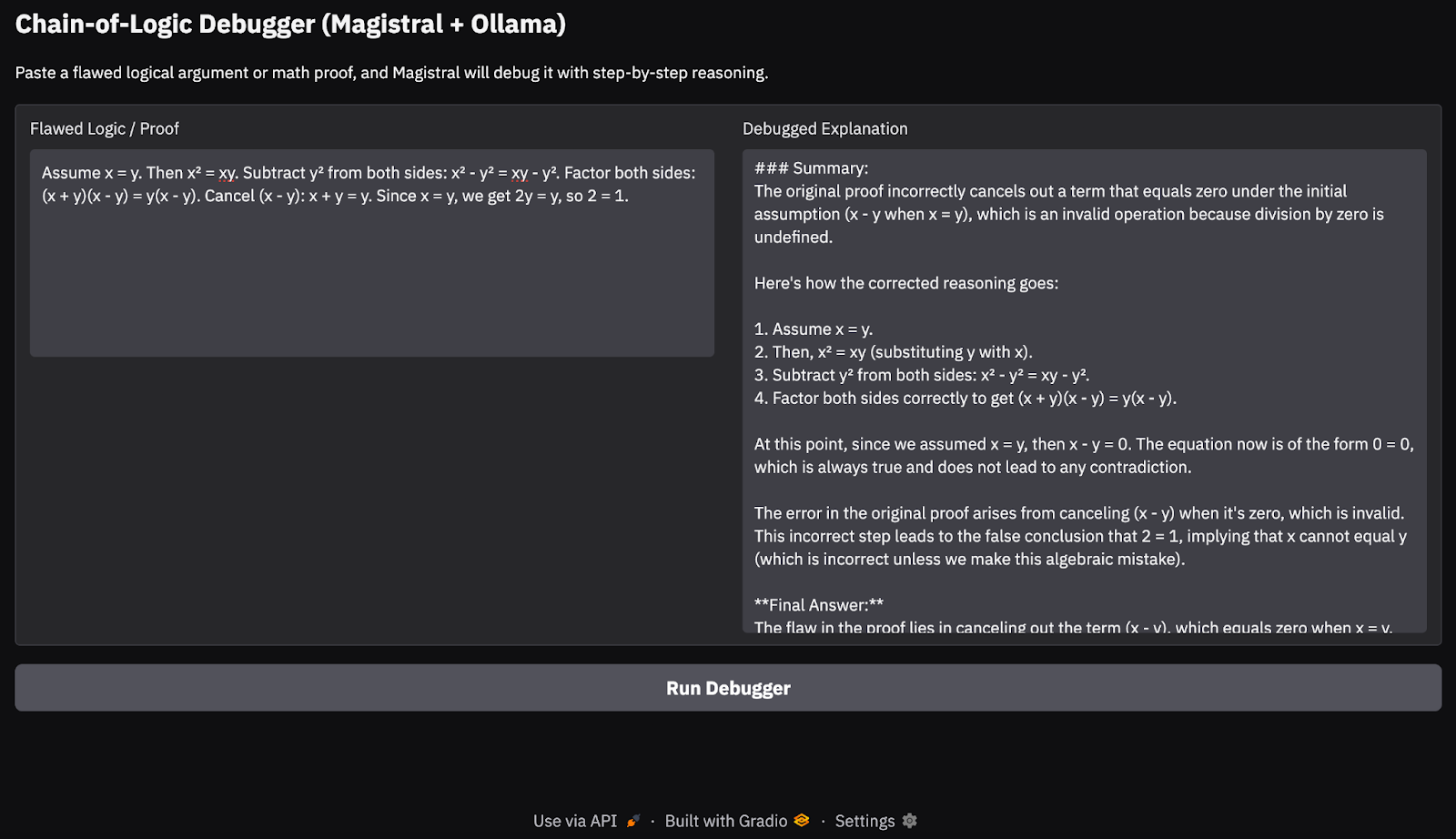
Lors de mes tests sur un MacBook Pro M3, le modèle a assez bien géré les chaînes logiques simples et les preuves mathématiques. Cependant, pour les tâches de raisonnement plus approfondies ou les chaînes de pensée plus longues, il a parfois manqué des cas limites, ce qui est normal pour un modèle ouvert 24B. Cette approche est idéale pour les démonstrations de raisonnement légères ou les applications sur l'appareil de l'appareil, sans s'appuyer sur les API du cloud.
Dans cette section, je vais vous expliquer comment provisionner une instance GPU puissante sur RunPod, déployer le modèle Magistral de Mistral à l'aide de vLLMet exposer une API compatible avec OpenAI pour l'inférence locale et distante.
Avant de lancer le modèle, assurez-vous que votre compte RunPod est configuré :
Maintenant, provisionnons un pod capable d'héberger le modèle. Pour configurer un pod, suivez les étapes suivantes :
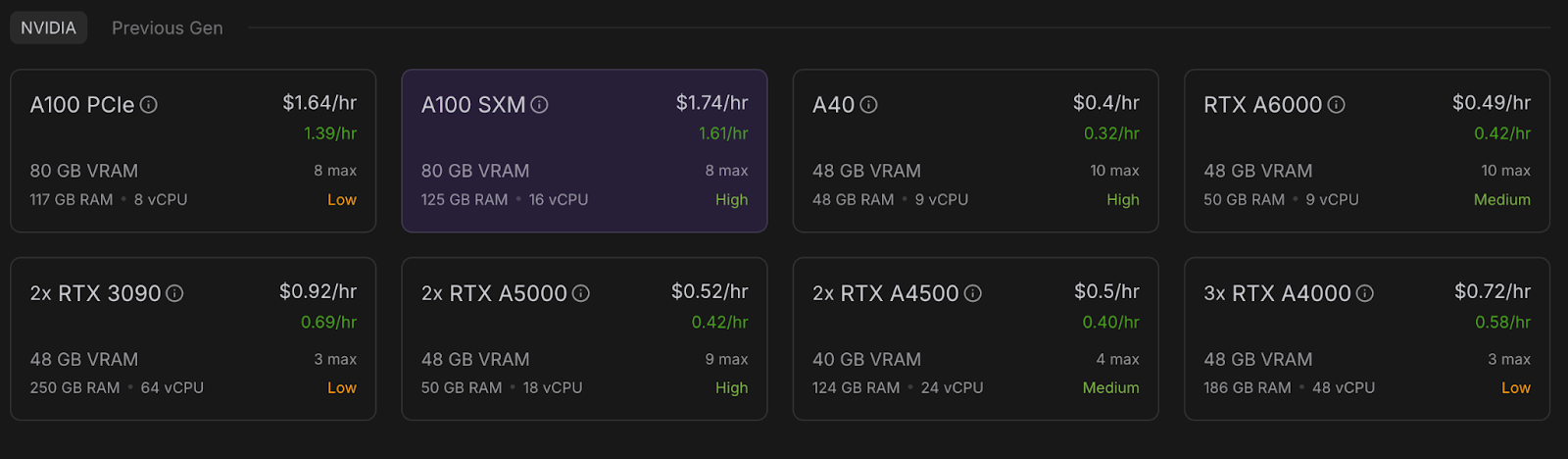
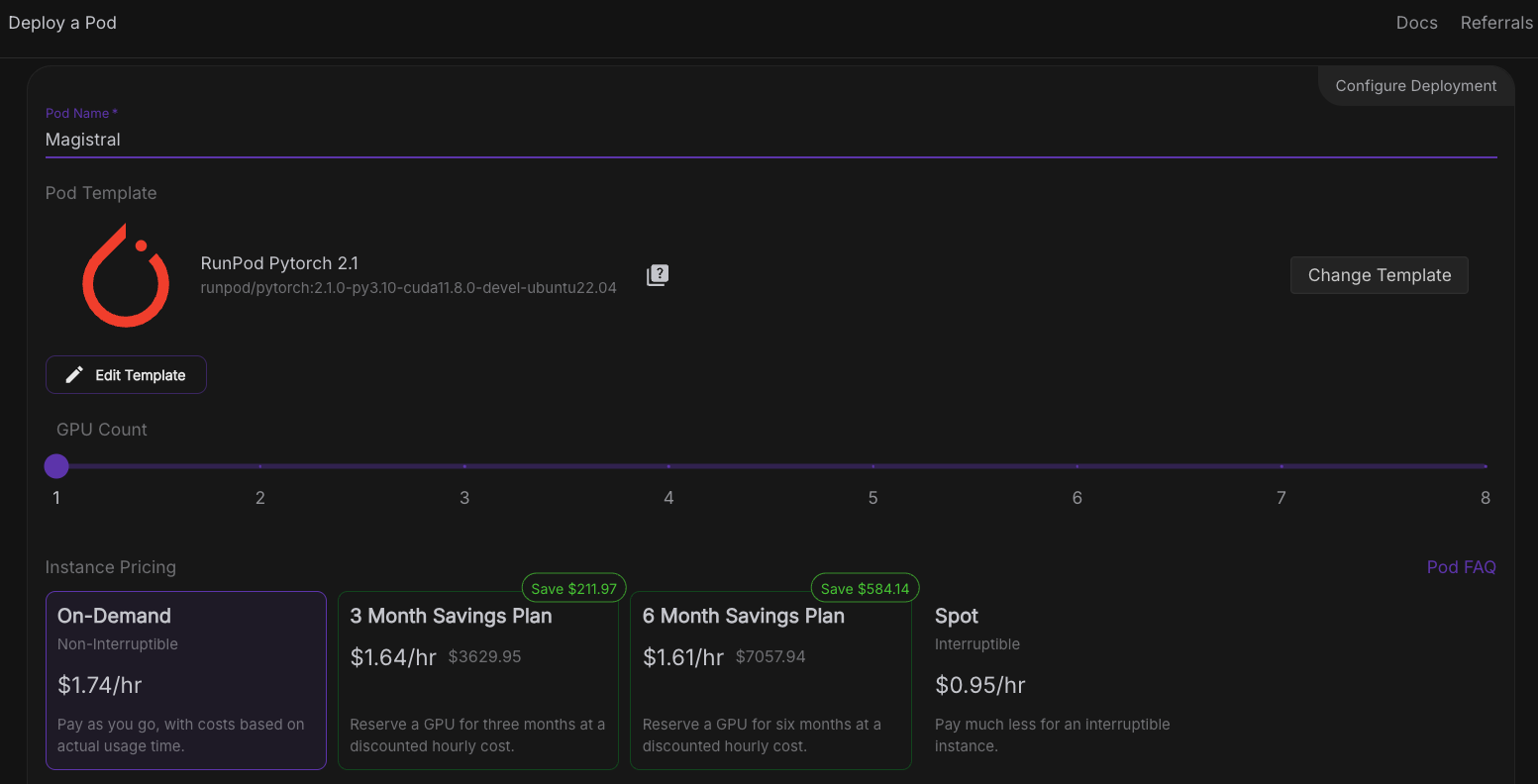
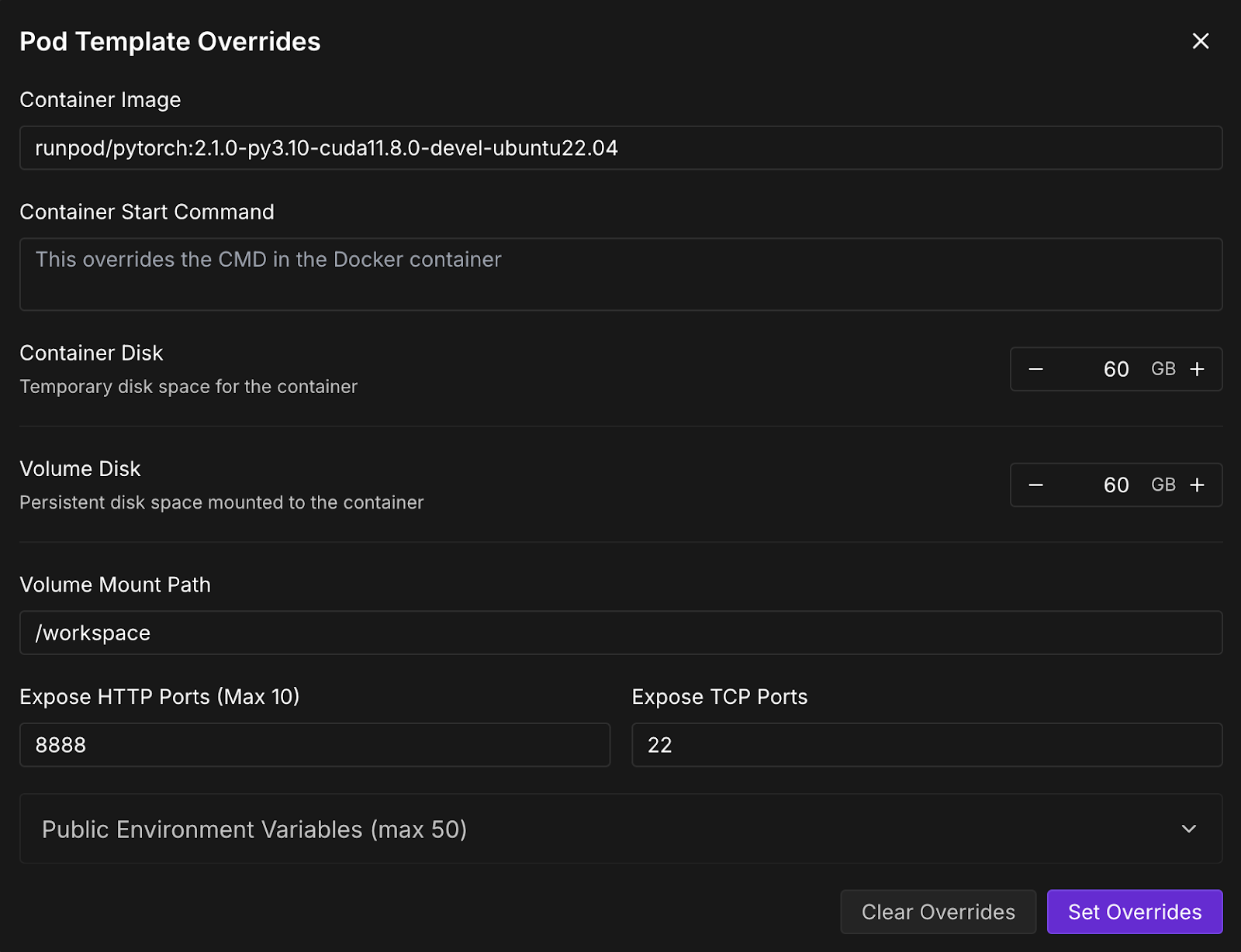
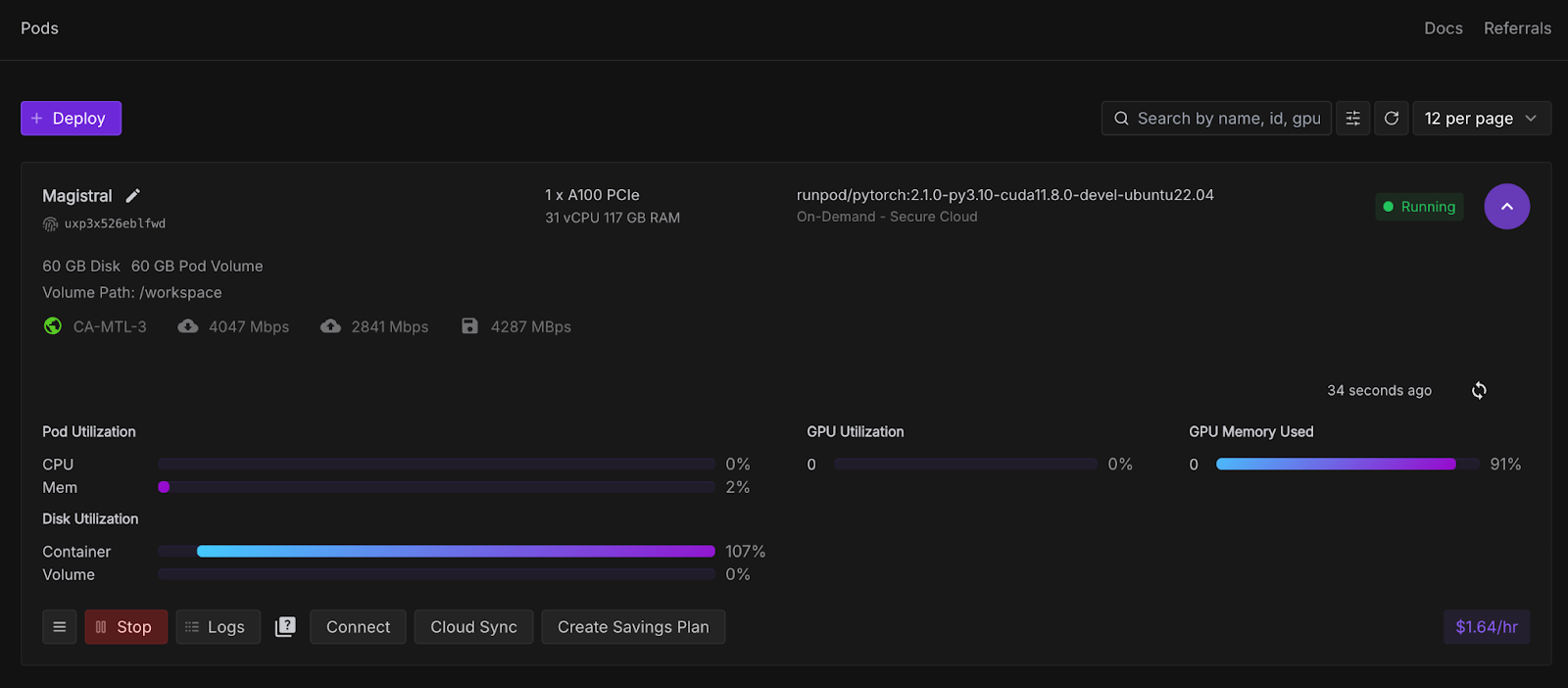
Une fois que le boutonConnect devient cliquable, cliquez dessus. Plusieurs options de connexion s'offrent à vous :
Note : Attendez de voir un point vert 🟢 avec un Ready sous Jupyter Lab.
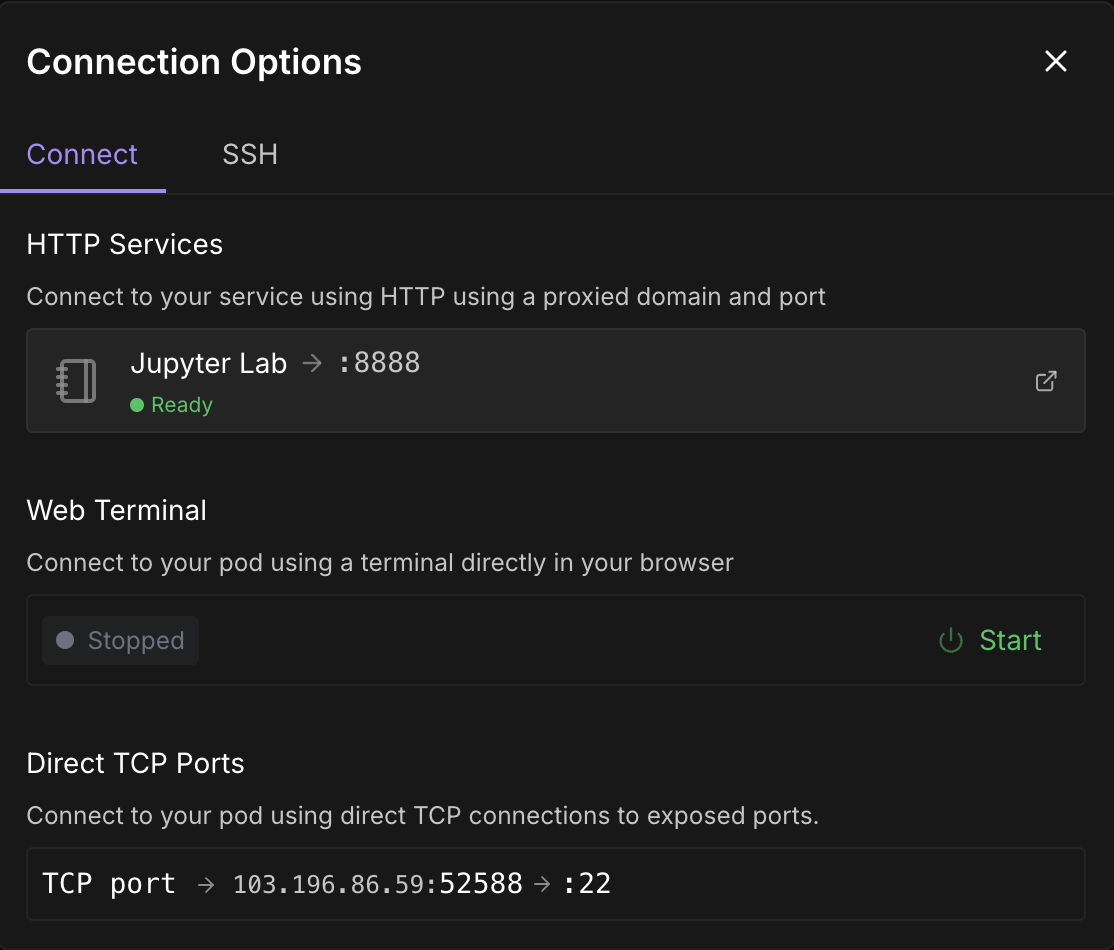
Cliquez sur Jupyter Lab- cela vous mènera à une autre fenêtre avec des options pour créer un nouveau carnet Jupyter. Ouvrez un nouveau terminal ou créez un nouveau fichier Python.
Soit dans le terminal, soit dans le Jupyter Notebook à l'intérieur de votre pod, installez vLLM et ses dépendances.
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install gradioAssurez-vous également que vous exécutez mistral_common >= 1.6.0 en exécutant :
python -c "import mistral_common; print(mistral_common.__version__)"Maintenant, servons le modèle. Cliquez sur le signe "+" dans le coin supérieur gauche et sélectionnez terminal dans les options, puis exécutez la commande suivante :
vllm serve mistralai/Magistral-Small-2506 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tool-call-parser mistral \
--enable-auto-tool-choiceGardez ce terminal en marche car cette commande lance lemodèleMagistral Small en utilisant vLLM et le rend disponible à un point de terminaison API rapide et compatible avec OpenAI (http://localhost:8000/v1). Voici un aperçu de pour chaque drapeau :
|
Flag |
Description |
|
|
Il s'agit d'un identifiant de modèle Hugging Face. vLLM télécharge automatiquement ce modèle s'il n'existe pas déjà. |
|
|
Cela permet de s'assurer que le tokenizer est interprété selon la logique propre à Mistral |
|
|
Cela indique que la configuration du modèle est dans le format personnalisé de Mistral, et non dans le format par défaut de Hugging Face. |
|
|
Cela permet de charger les poids du modèle en utilisant la disposition prévue par Mistral (important pour la compatibilité). |
|
|
Il permet à un outil d'analyse syntaxique d'appeler la syntaxe selon la structure de Mistral. |
|
|
Sélectionne automatiquement le meilleur outil en fonction de l'entrée si l'appel d'outil est utilisé. Cette option est facultative mais utile pour les modèles formés à l'aide d'outils de raisonnement. |
Nous allons maintenant construire une démo dans laquelle Magistral est invité à déboguer une preuve logique ou mathématique erronée. Le modèle produira un monologue intérieur détaillé enveloppé dans balises<think> et un résumé final.
Nous commençons par mettre en place les importations et initialiser le client OpenAI dans Jupyter Notebook. Nous avons ensuite mis en place l'invite du système du Magistral, comme suggéré dans le document original du Magistral.
import gradio as gr
from openai import OpenAI
import re
import time
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
SYSTEM_PROMPT = """<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
<think>
Your thoughts or draft, like working through an exercise on scratch paper.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user.
Problem:
[/SYSTEM_PROMPT]"""Le site SYSTEM_PROMPT définit le format structuré de la réponse du modèle :
Ensuite, nous gérons le flux de sortie du modèle en définissant les paramètres requis temperature, top_p, et max_tokens comme suggéré dans le blog original de Magistral.
# Streaming logic with stop control
def debug_faulty_logic_stream(faulty_proof, stop_signal):
stop_signal["stop"] = False
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Here is a flawed logic or math proof. Can you debug it step-by-step?\n\n{faulty_proof}"}
]
try:
response = client.chat.completions.create(
model="mistralai/Magistral-Small-2506",
messages=messages,
stream=True,
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
buffer = ""
for chunk in response:
if stop_signal.get("stop"):
break
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
buffer += delta.content
filtered = re.sub(r"<think>.*?</think>", "", buffer, flags=re.DOTALL).strip()
yield filtered
time.sleep(0.02)
except Exception as e:
yield f"Error: {str(e)}"
# Set stop flag when stop button is clicked
def stop_streaming(stop_signal):
stop_signal["stop"] = True
return gr.Textbox.update(value="Stopped.")L'extrait de code ci-dessus gère le flux de sortie en direct, jeton par jeton, du modèle. stop_signal permet aux utilisateurs d'interrompre le flux en cliquant sur un bouton "Stop".
Tandis que le tampon accumule tout le contenu, mais ne produit que le résumé (à l'exclusion de la balise<think> ) à l'aide d'une expression régulière. En cas d'erreur (par exemple, problème de réseau), il renvoie le message d'erreur.
Rassemblons tout cela avec une simple application Gradio qui permet aux utilisateurs d'ajouter leur logique ou leur preuve défectueuse et de la soumettre au modèle pour qu'il la raisonne.
with gr.Blocks() as demo:
gr.Markdown("## Chain-of-Logic Debugger (Streaming via Magistral + vLLM)")
input_box = gr.Textbox(
label="Paste Your Faulty Logic or Proof",
lines=8,
placeholder="e.g., Assume x = y, then x² = xy..."
)
output_box = gr.Textbox(label="Corrected Reasoning (Streaming Output)")
submit_btn = gr.Button("Submit")
stop_btn = gr.Button("Stop")
stop_flag = gr.State({"stop": False})
submit_btn.click(
fn=debug_faulty_logic_stream,
inputs=[input_box, stop_flag],
outputs=output_box
)
stop_btn.click(
fn=stop_streaming,
inputs=stop_flag,
outputs=output_box
)
if __name__ == "__main__":
demo.launch(share=True, inbrowser=True, debug=True)Le code ci-dessus crée une interface Gradio simple avec :
Il utilise le site gr.State pour savoir si l'utilisateur souhaite interrompre le processus de diffusion en continu. Ensuite, la méthode launch() exécute l'application localement et l'ouvre dans votre navigateur. Voici l'entrée que j'ai essayée :
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.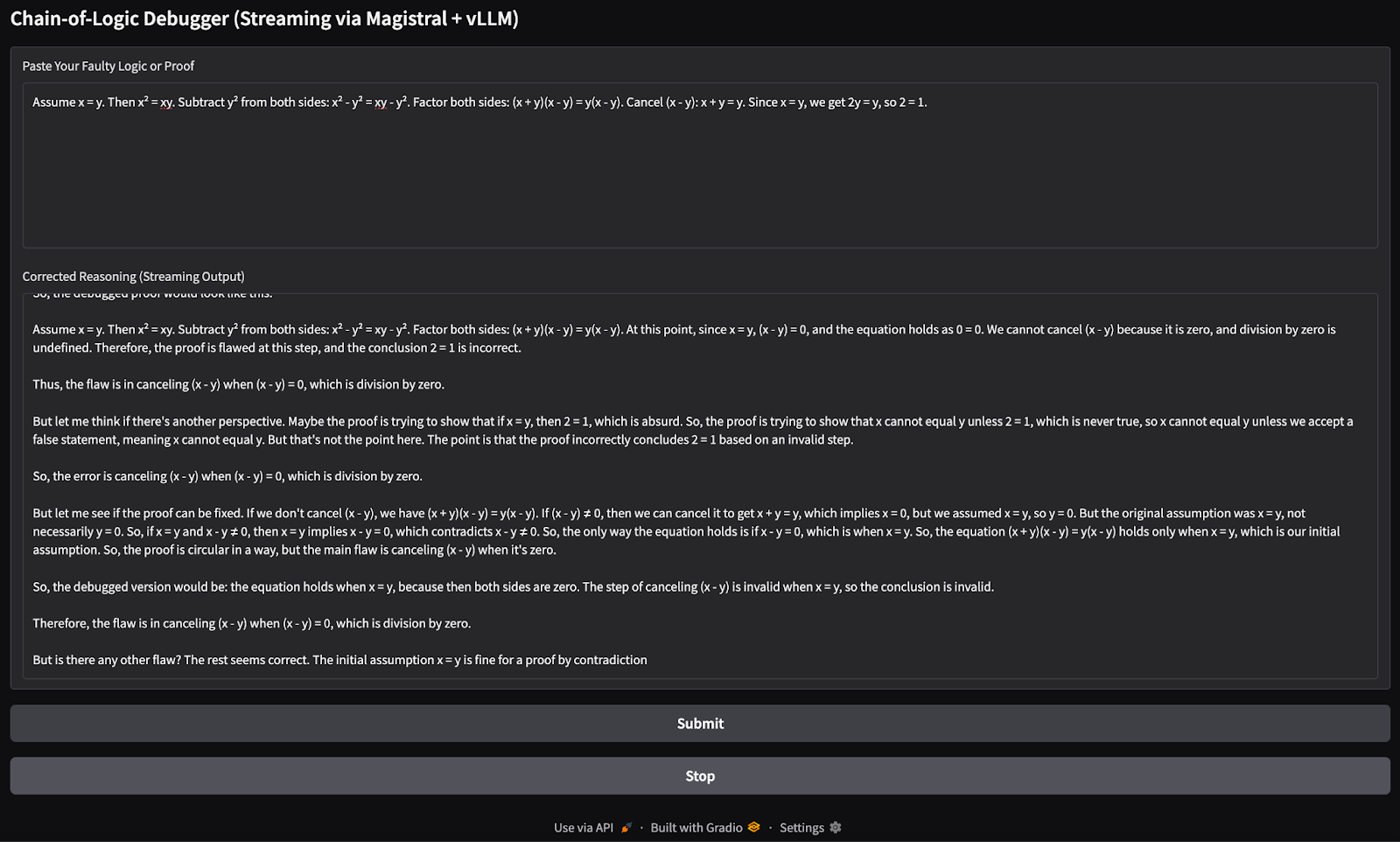
Vous pouvez basculer vers le terminal déjà en cours d'exécution où vLLM est utilisé pour vérifier les journaux d'utilisation du cache KV, ainsi que le taux de réussite qui augmente lorsque le modèle renvoie des résultats.

Comparé à Ollama, vLLM était sensiblement plus rapide et plus stable pendant l'inférence. Le flux est fluide et les résultats sont généralement bien structurés. Cela dit, le modèle a parfois répété des pensées dans les sections <think >, probablement en raison de la nature du décodage autorégressif sans pénalités d'échantillonnage.
Alors qu'Ollama prend en charge une version quantifiée à 4 bits du modèle pour une inférence efficace sur l'appareil, vLLM nécessite une accélération GPU, ce qui rend son exécution légèrement plus coûteuse (environ 5 $ pour ce projet). Le modèle Magistral quantifié sur 4 bits nécessite environ 14 Go de mémoire, ce qui peut être hébergé sur un seul GPU RTX 4090 ou même un MacBook avec 32 Go de RAM. Cependant, l'inférence peut être lente, jusqu'à 4 minutes par réponse, en raison d'une capacité de calcul limitée.
En revanche, vLLM offre une inférence beaucoup plus rapide (environ moins d'une minute par réponse) lorsqu'il est déployé sur des GPU haute performance comme l'A100 SXM, ce qui le rend plus adapté aux applications réactives ou aux déploiements à grande échelle.
Si vous n'en êtes qu'au stade de l'expérimentation et que vous disposez de ressources locales, Ollama est la solution idéale en raison de son faible coût d'installation. Mais pour des performances de niveau production ou des charges de travail plus importantes, vLLM est le choix recommandé. Gardez à l'esprit que si vLLM peut être exécuté localement, il nécessite tout de même un GPU performant.
Dans ce tutoriel, nous avons utilisé Magistral Small - un LLM de raisonnement de Mistral - pour construire un débogueur logique étape par étape. Nous avons déployé le modèle localement en utilisant à la fois Ollama pour des tests rapides sur l'appareil et vLLM pour une inférence GPU à haut débit avec des API compatibles avec OpenAI. Nous avons également testé les capacités de raisonnement du modèle avec une application Gradio. Que vous déboguiez une logique défectueuse ou que vous construisiez des outils d'intelligence artificielle, Magistral Small peut être une bonne solution.
Apprenez l'IA avec ces cours !
Cours
Cours
Cours