
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.4K
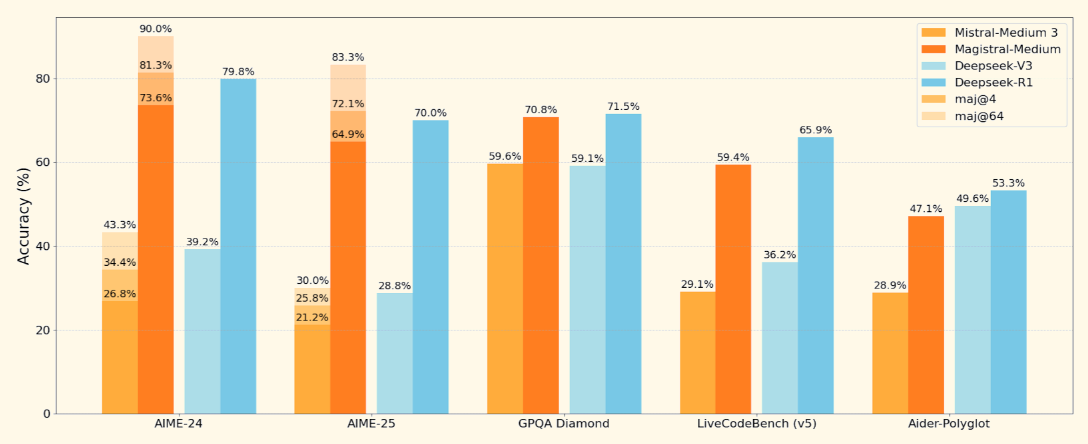
Mistral hat sein erstes Argumentationsmodell, Magistral, in zwei Varianten auf den Markt gebracht : Magistral Small (offenes Gewicht) und Magistral Medium (geschlossenes Modell).
In diesem Blog werde ich mich auf Magistral Smallkonzentrieren , ein offenes Argumentationsmodell, das für Aufgaben entwickelt wurde, die strukturierte Logik, mehrsprachiges Verständnis und die Fähigkeit, nachvollziehbare Erklärungen zu liefern, erfordern. In Kombination mit durchsatzstarken Inferenzmaschinen wie vLLM oder einfach zu bedienenden Tools wie Ollama wird es zu einem großartigen Werkzeug für die Fehlersuche bei fehlerhaften Logik- und Schlussfolgerungsaufgaben.
In diesem Tutorial erkläre ich dir Schritt für Schritt, wie du das machst:
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Magistral ist das erste dedizierte Argumentationsmodell von Mistral AI, das für schrittweise Logik, mehrsprachige Genauigkeit und nachvollziehbare Ergebnisse entwickelt wurde. Es ist ein Dual-Release-Modell, das es in zwei Varianten gibt:
Quelle: Mistral
Magistral Small, das offene Modell, auf das wir uns konzentrieren werden, unterstützt ein 128K-Kontextfenster (40K empfohlen für stabile Leistung). Es wird mithilfe von überwachter Feinabstimmung auf Magistral Medium Spuren und Verstärkungslernen.
In diesem Abschnitt werden wir mit Ollama lokal auf das Magistralmodell von Mistral schließen. Beachte, dass dieses Modell etwa 14 GB Speicherplatz benötigt und in eine einzelne RTX 4090 oder ein MacBook mit 32 GB RAM passt, sobald quantisiert. Ich habe diese Demo auf einem M3 MacBook Pro ausgeführt.
Lade Ollama für macOS, Windows oder Linux herunter unter: https://ollama.com/download.
Befolge die Anweisungen des Installationsprogramms und überprüfe nach der Installation, indem du dies im Terminal ausführst:
ollama --versionAls nächstes ziehst du das Magistralmodell, indem du den folgenden Code ausführst:
ollama pull magistral
Dadurch wird das Magistralmodell auf deinen lokalen Rechner gezogen. Hinweis: Es wird einige Zeit dauern, da das Modell etwa 14 GB groß ist.
Beginnen wir mit der Installation aller erforderlichen Abhängigkeiten.
pip install ollama
pip install requestsNachdem die Abhängigkeiten installiert sind, können wir die Inferenz ausführen.
Jetzt richten wir eine Prompt-Vorlagenstruktur ein (wie in der ursprünglichen Magistralschrift), die das Denken des Modells leitet.
import gradio as gr
import requests
import json
def build_prompt(flawed_logic):
return f"""<s>[SYSTEM_PROMPT]
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and detailed as needed until you're confident.
</think>
Do not mention that you're debugging — just present your thought process and conclusion naturally.
[/SYSTEM_PROMPT][INST]
Here is a flawed solution. Can you debug it and correct it step by step?
\"\"\"{flawed_logic}\"\"\"
[/INST]
"""Die obige Funktion gibt eine formatierte Eingabeaufforderung zurück, die Magistral anleitet:
Diese Struktur ist wichtig für Modelle wie Magistral, die mit toolunterstützten Prompts trainiert wurden. Die gleiche Struktur der Systemaufforderung kann auch für mathematische und kodierte Probleme verwendet werden.
In diesem Schritt streamen wir die Ausgabe des Magistralmodells in Echtzeit über die lokale API von Ollama. Da wir uns darauf konzentrieren, fehlerhafte Logik mit nachvollziehbarer, schrittweiser Argumentation zu debuggen, ist es wichtig, dass der Benutzer sehen kann, wie das Modell zu seinen Schlussfolgerungen kommt. Schließlich zeigen wir die Erklärung durch eine saubere Gradio Schnittstelle.
def call_ollama_stream(flawed_logic):
prompt = build_prompt(flawed_logic)
response_text = ""
with requests.post(
"http://localhost:11434/api/generate",
json={"model": "magistral", "prompt": prompt, "stream": True},
stream=True,
) as r:
for line in r.iter_lines():
if line:
content = json.loads(line).get("response", "")
response_text += content
return response_text
with gr.Blocks(theme=gr.themes.Base()) as demo:
gr.Markdown("## Chain-of-Logic Debugger (Magistral + Ollama)")
gr.Markdown("Paste a flawed logical argument or math proof, and Magistral will debug it with step-by-step reasoning.")
with gr.Row():
input_box = gr.Textbox(lines=8, label="Flawed Logic / Proof")
output_box = gr.Textbox(lines=15, label="Debugged Explanation")
debug_button = gr.Button("Run Debugger")
debug_button.click(fn=call_ollama_stream, inputs=input_box, outputs=output_box)
demo.launch(debug = True, share=True)Hier ist ein Überblick darüber, was hier passiert:
build_prompt() Funktion, um Benutzereingaben in eine strukturierte Eingabeaufforderung zu verpacken, die das Modell mit call_ollama_stream() die Eingabeaufforderung mit einer Streaming-POST-Anfrage an die HTTP-API von Ollama unter localhost:11434.requests.iter_lines(). Für jede empfangene Zeile extrahiert es das Antwortfeld aus der JSON-Nutzlast und hängt es an einen laufenden Textpuffer an.Hier ist die Eingabe, die ich versucht habe:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.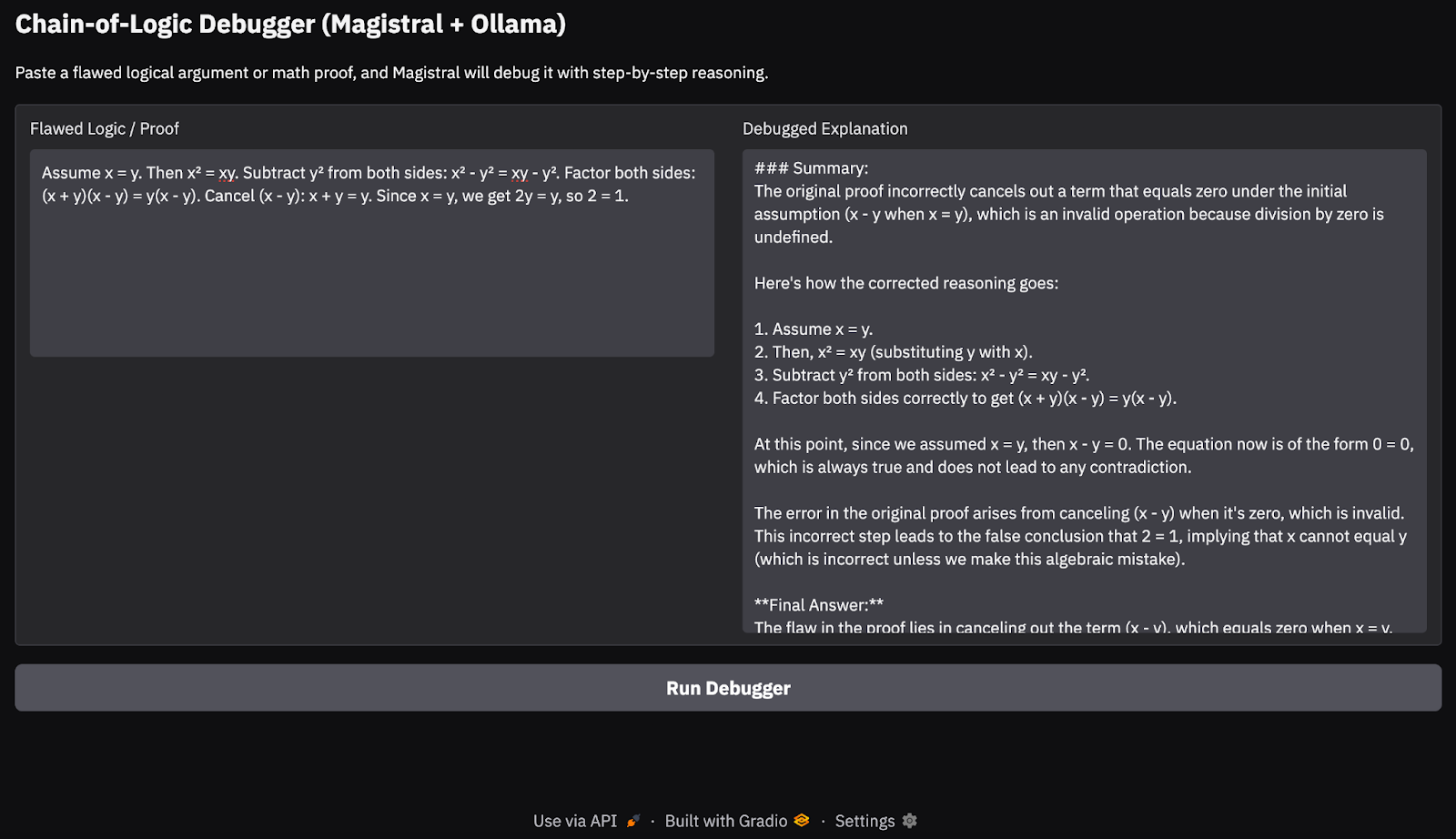
Bei meinen Tests auf einem M3 MacBook Pro kam das Modell mit einfachen logischen Ketten und mathematischen Beweisen ganz gut zurecht. Bei tieferen Denkaufgaben oder längeren Gedankenketten wurden jedoch gelegentlich Randfälle übersehen, was bei einem offenen 24B-Modell zu erwarten war. Dieser Ansatz ist ideal für leichtgewichtige Argumentationsdemos oder On-Device Chain-of-Thought-Anwendungen, ohne auf Cloud-APIs angewiesen zu sein.
In diesem Abschnitt erkläre ich, wie man eine leistungsstarke GPU-Instanz auf RunPod bereitstellt, das Mistral-Modell mit vLLMund eine OpenAI-kompatible API für lokale und entfernte Inferenzen bereitstellt.
Bevor du das Modell startest, stelle sicher, dass dein RunPod-Konto eingerichtet ist:
Nun wollen wir einen Pod bereitstellen, der das Modell aufnehmen kann. Um einen Pod einzurichten, befolge diese Schritte:
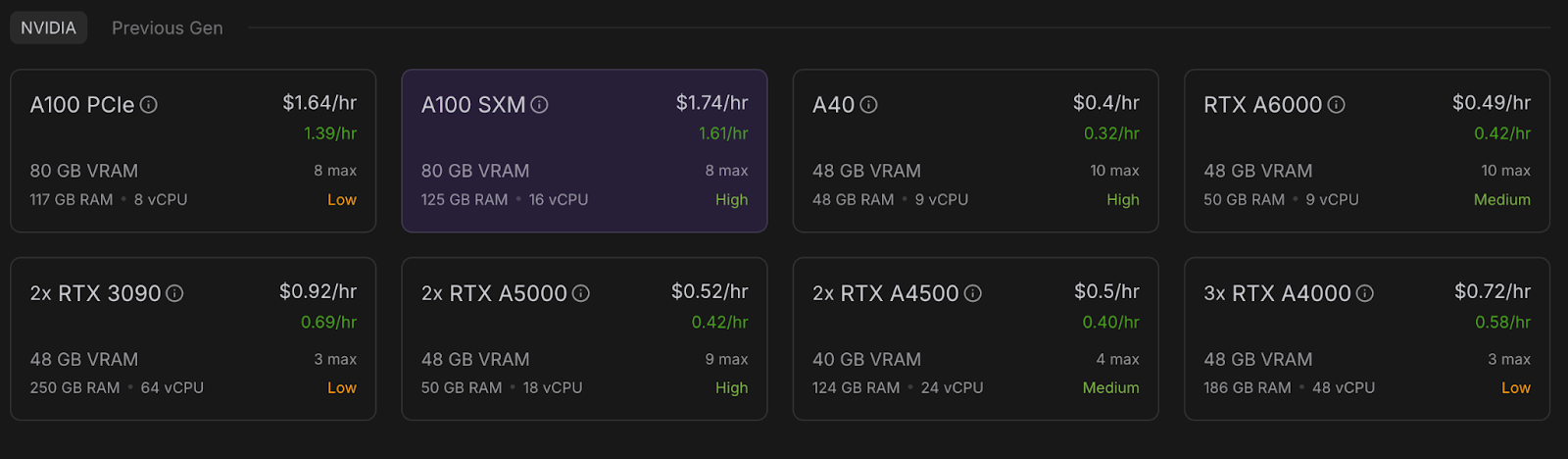
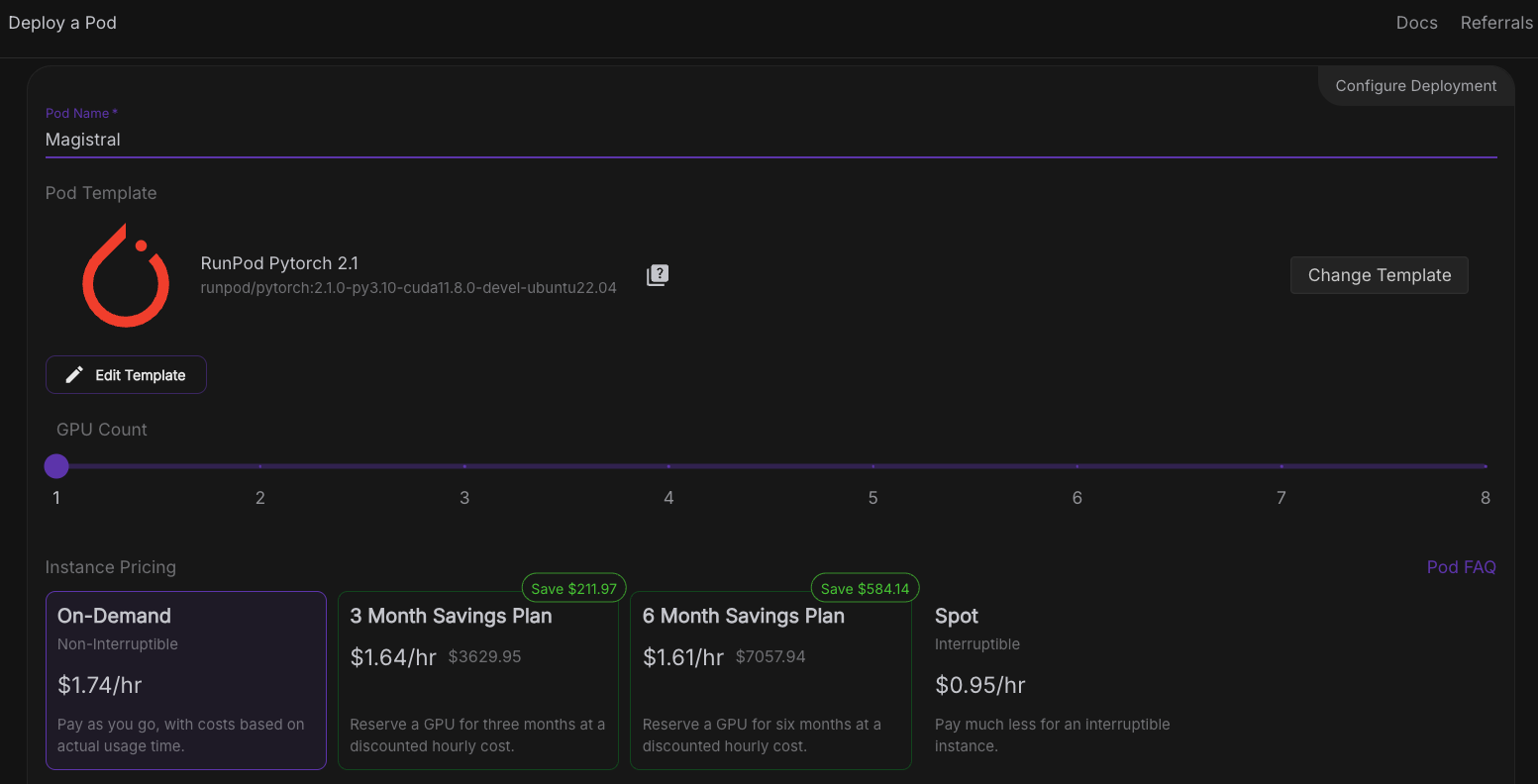
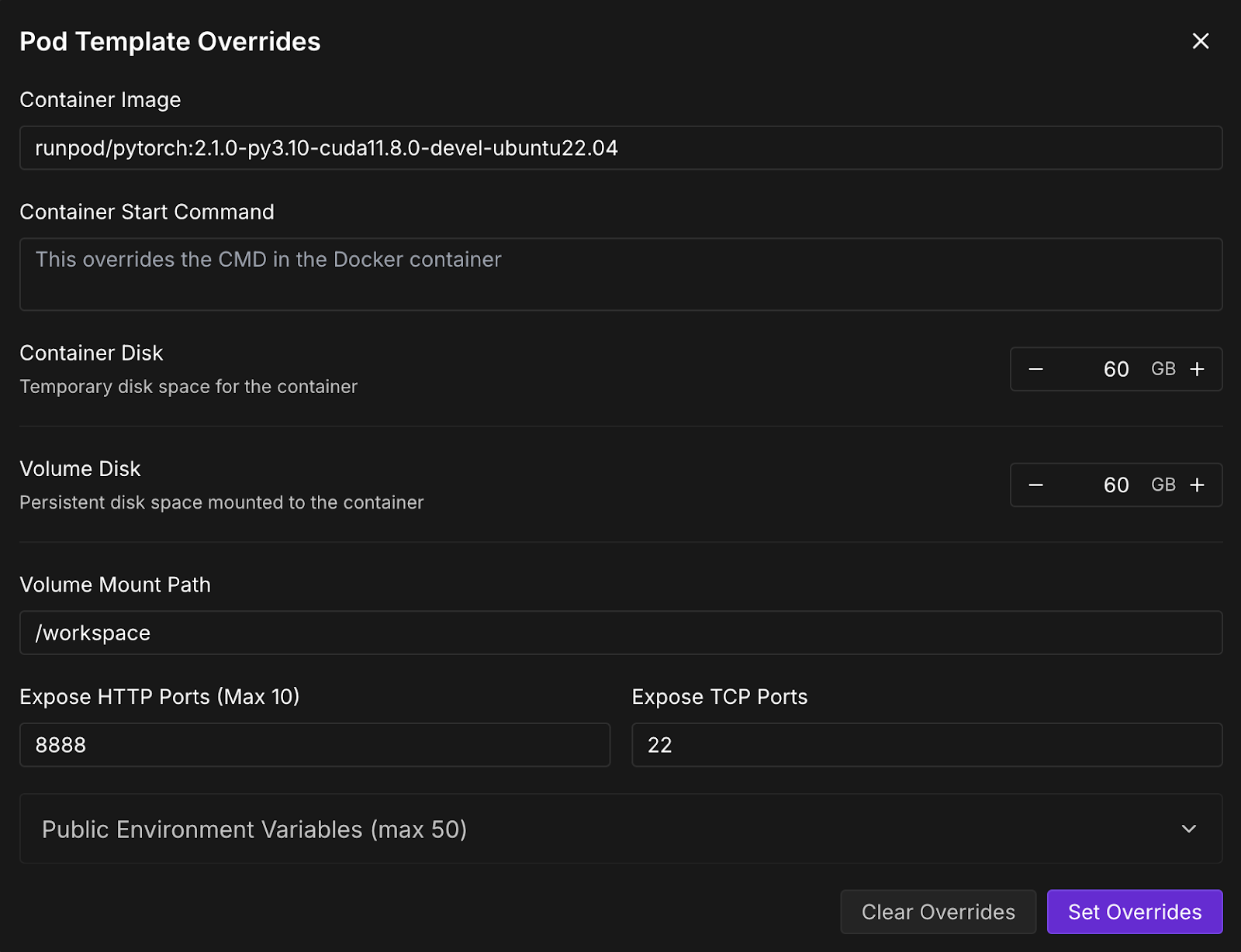
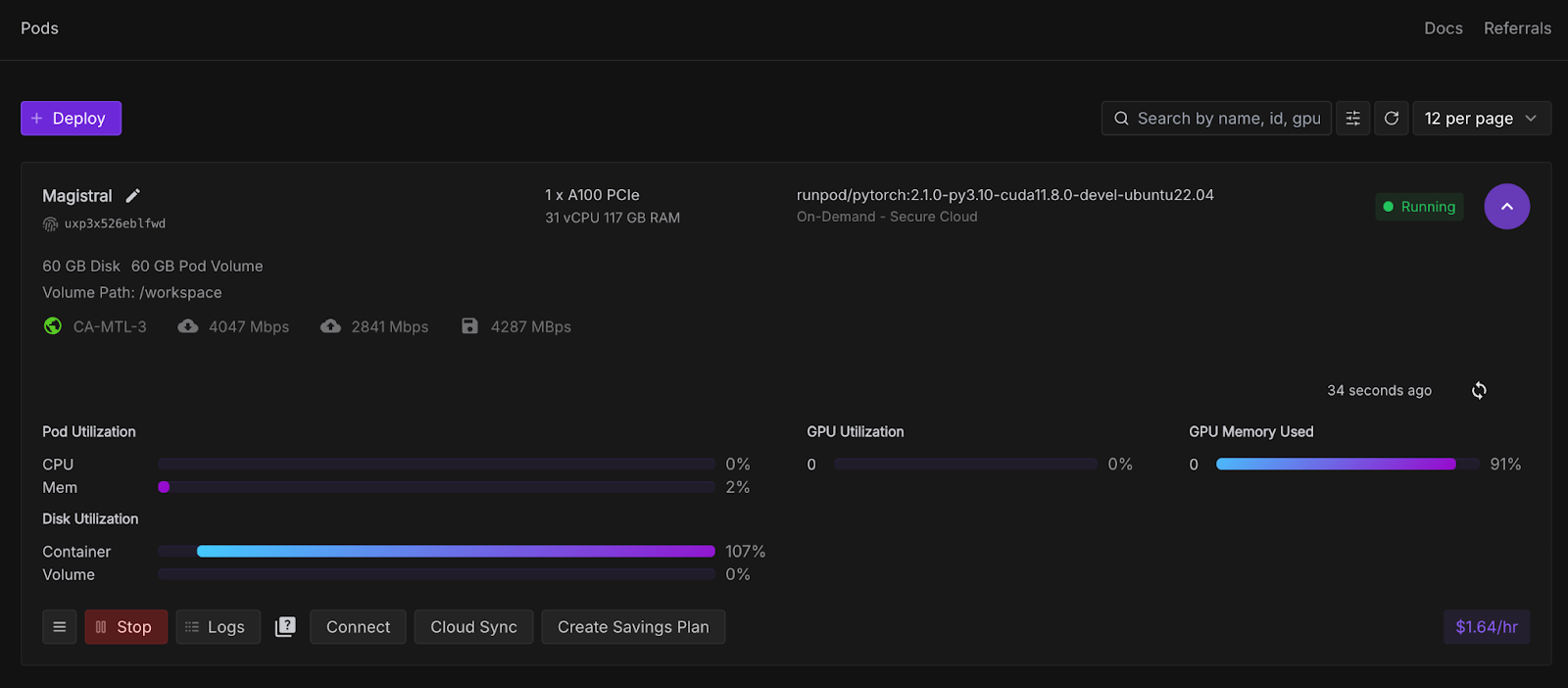
Sobald die SchaltflächeVerbinden anklickbar ist, klicke sie an. Du wirst mehrere Verbindungsoptionen sehen - du kannst entweder:
Hinweis: Warte, bis du einen grünen Punkt 🟢mit einem Bereitschaftszeichen unter Jupyter Lab siehst.
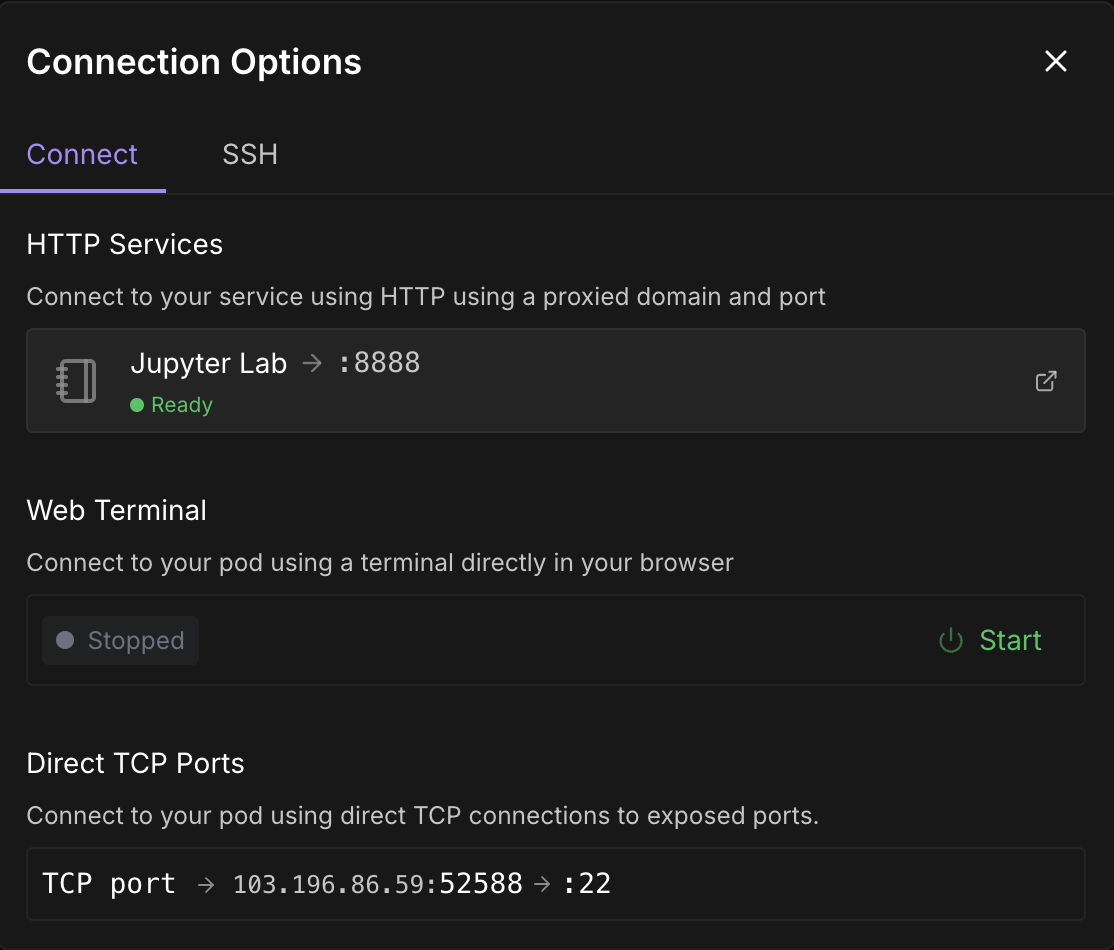
Klicke auf Jupyter Lab- es öffnet sich ein weiteres Fenster mit Optionen zum Erstellen eines neuen Jupyter-Notizbuchs. Öffne ein neues Terminal oder richte eine neue Python-Datei ein.
Installiere vLLM und seine Abhängigkeiten entweder im Terminal oder im Jupyter Notebook innerhalb deines Pods.
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install gradioStelle außerdem sicher, dass du mistral_common >= 1.6.0 ausführst:
python -c "import mistral_common; print(mistral_common.__version__)"Jetzt lass uns das Modell servieren. Klicke auf das "+"-Zeichen in der linken oberen Ecke und wähle in den Optionen "Terminal" aus und führe dann den folgenden Befehl aus:
vllm serve mistralai/Magistral-Small-2506 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tool-call-parser mistral \
--enable-auto-tool-choiceLass dieses Terminal laufen, denn dieser Befehl startet das Magistral Small Modell mit vLLM und macht es über einen schnellen, OpenAI-kompatiblen API-Endpunkt verfügbar (http://localhost:8000/v1). Hier ist eine Aufschlüsselung von für jede Flagge:
|
Flagge |
Beschreibung |
|
|
Es handelt sich um eine Hugging Face-Modellkennung. vLLM lädt dieses Modell automatisch herunter, wenn es noch nicht vorhanden ist. |
|
|
Damit wird sichergestellt, dass der Tokenizer mit der Mistral-spezifischen Logik interpretiert wird |
|
|
Es zeigt an, dass die Modellkonfiguration im benutzerdefinierten Format von Mistral und nicht im Standardformat von Hugging Face vorliegt. |
|
|
Dadurch werden die Modellgewichte mit dem erwarteten Layout von Mistral geladen (wichtig für die Kompatibilität). |
|
|
Es ermöglicht ein Parsing-Tool, das die Syntax entsprechend der Struktur von Mistral aufruft. |
|
|
Wählt automatisch das beste Werkzeug anhand der Eingabe aus, wenn der Werkzeugaufruf verwendet wird. Dies ist optional, aber nützlich für Modelle, die mit Tool Reasoning trainiert wurden. |
Wir werden jetzt eine Demo erstellen, in der Magistral einen fehlerhaften logischen oder mathematischen Beweis debuggen soll. Das Modell gibt einen detaillierten inneren Monolog aus, der in <think> Tags und eine abschließende Zusammenfassung verpackt ist.
Wir beginnen damit, die Importe einzurichten und den OpenAI-Client in Jupyter Notebook zu initialisieren. Dann haben wir die Systemaufforderung der Magistrale so eingerichtet, wie es in der ursprünglichen Magistralarbeit vorgeschlagen wurde.
import gradio as gr
from openai import OpenAI
import re
import time
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
SYSTEM_PROMPT = """<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
<think>
Your thoughts or draft, like working through an exercise on scratch paper.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user.
Problem:
[/SYSTEM_PROMPT]"""Die SYSTEM_PROMPT definiert das strukturierte Format, in dem das Modell antworten soll:
Als Nächstes kümmern wir uns um das Streaming der Modellausgabe, indem wir die erforderlichen temperature, top_p und max_tokens setzen, wie im Magistral-Blog vorgeschlagen.
# Streaming logic with stop control
def debug_faulty_logic_stream(faulty_proof, stop_signal):
stop_signal["stop"] = False
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Here is a flawed logic or math proof. Can you debug it step-by-step?\n\n{faulty_proof}"}
]
try:
response = client.chat.completions.create(
model="mistralai/Magistral-Small-2506",
messages=messages,
stream=True,
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
buffer = ""
for chunk in response:
if stop_signal.get("stop"):
break
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
buffer += delta.content
filtered = re.sub(r"<think>.*?</think>", "", buffer, flags=re.DOTALL).strip()
yield filtered
time.sleep(0.02)
except Exception as e:
yield f"Error: {str(e)}"
# Set stop flag when stop button is clicked
def stop_streaming(stop_signal):
stop_signal["stop"] = True
return gr.Textbox.update(value="Stopped.")Das obige Codeschnipsel verarbeitet das Live-Streaming der Token-Ausgabe des Modells. stop_signal ermöglicht es den Nutzern, das Streaming zu unterbrechen, indem sie auf die Schaltfläche "Stop" klicken.
Während der Puffer den gesamten Inhalt sammelt, aber nur die Zusammenfassung (ohne den <think> Tag) mit Hilfe eines regulären Ausdrucks ausgibt . Wenn ein Fehler auftritt (z. B. ein Netzwerkproblem), wird eine Fehlermeldung ausgegeben.
Bringen wir dies mit einer einfachen Gradio-App zusammen, die es den Nutzern ermöglicht, ihre fehlerhafte Logik oder ihren Beweis einzubringen und sie dem Modell zur Prüfung vorzulegen.
with gr.Blocks() as demo:
gr.Markdown("## Chain-of-Logic Debugger (Streaming via Magistral + vLLM)")
input_box = gr.Textbox(
label="Paste Your Faulty Logic or Proof",
lines=8,
placeholder="e.g., Assume x = y, then x² = xy..."
)
output_box = gr.Textbox(label="Corrected Reasoning (Streaming Output)")
submit_btn = gr.Button("Submit")
stop_btn = gr.Button("Stop")
stop_flag = gr.State({"stop": False})
submit_btn.click(
fn=debug_faulty_logic_stream,
inputs=[input_box, stop_flag],
outputs=output_box
)
stop_btn.click(
fn=stop_streaming,
inputs=stop_flag,
outputs=output_box
)
if __name__ == "__main__":
demo.launch(share=True, inbrowser=True, debug=True)Der obige Code erstellt eine einfache Gradio-Schnittstelle mit:
Es verwendet gr.State, um zu verfolgen, ob der/die Nutzer/in den Streaming-Prozess unterbrechen möchte. Dann führt die Methode launch() die App lokal aus und öffnet sie in deinem Browser. Hier ist die Eingabe, die ich versucht habe:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.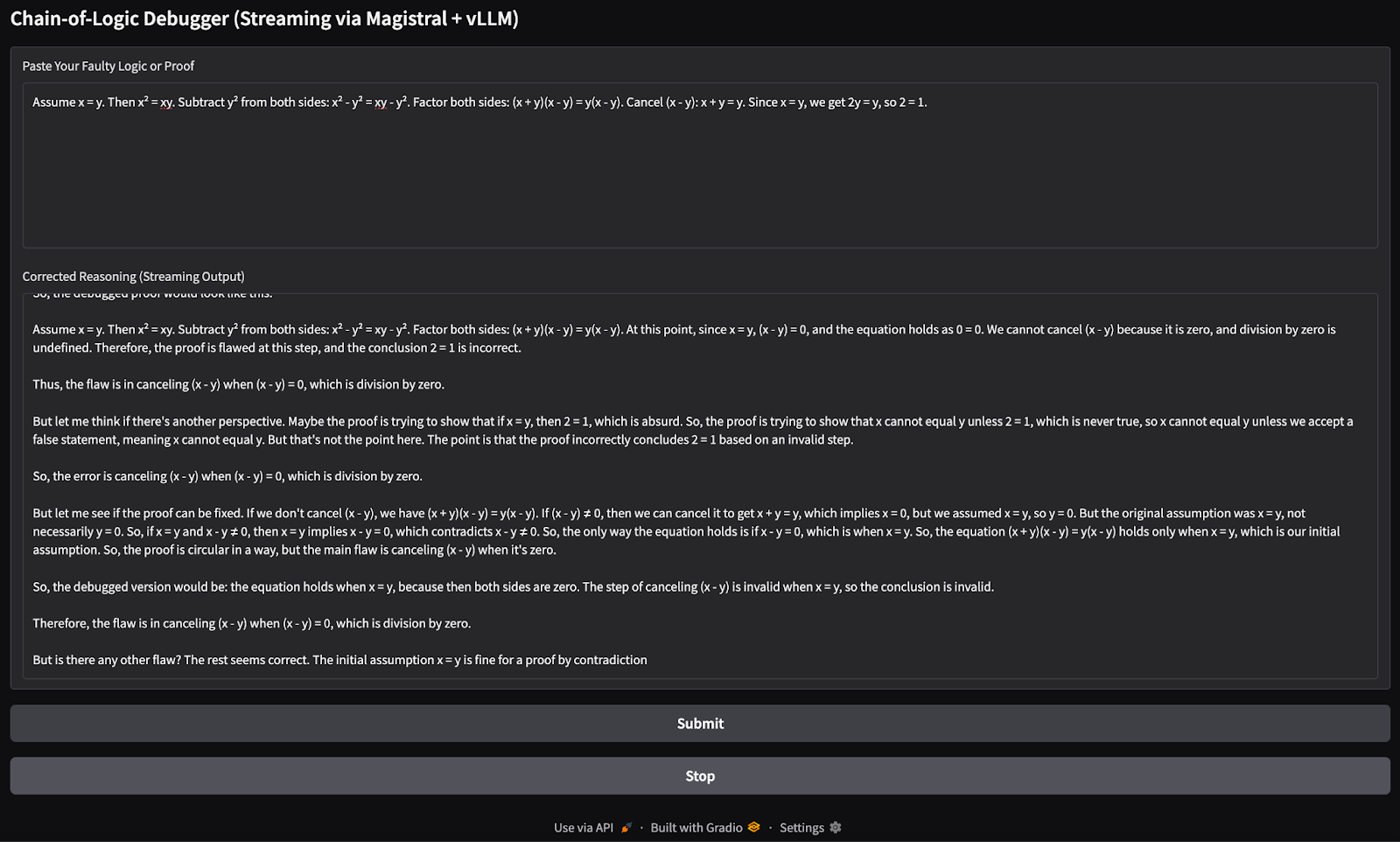
Du kannst zu dem bereits laufenden Terminal wechseln, in dem vLLM läuft, um die Protokolle der KV-Cache-Nutzung zu prüfen und zu sehen, wie die Trefferquote ansteigt, wenn das Modell eine Ausgabe liefert.

Im Vergleich zu Ollama war vLLM während der Inferenz deutlich schneller und stabiler. Das Streaming verlief reibungslos und die Ausgaben waren meist gut strukturiert. Allerdings wiederholte das Modell manchmal Gedanken innerhalb der <think> Abschnitte, was wahrscheinlich auf die Natur der autoregressiven Dekodierung ohne Stichprobenstrafen zurückzuführen ist.
Während Ollama eine quantisierte 4-Bit-Version des Modells für eine effiziente Inferenz auf dem Gerät unterstützt, erfordert vLLM eine GPU-Beschleunigung, was den Betrieb etwas teurer macht (etwa $5 für dieses Projekt). Das 4-Bit-quantisierte Magistralmodell benötigt ca. 14 GB Speicher, der auf einer einzelnen RTX 4090 GPU oder sogar auf einem MacBook mit 32 GB RAM untergebracht werden kann. Allerdings können die Schlussfolgerungen aufgrund der begrenzten Rechenleistung langsam sein und bis zu 4 Minuten pro Antwort dauern.
Im Gegensatz dazu bietet vLLM eine deutlich schnellere Inferenz (etwa weniger als eine Minute pro Antwort), wenn es auf Hochleistungs-GPUs wie dem A100 SXM eingesetzt wird, wodurch es sich besser für reaktionsschnelle Anwendungen oder skalierte Einsätze eignet.
Wenn du nur experimentieren willst und über lokale Ressourcen verfügst, ist Ollama aufgrund seiner geringen Einrichtungskosten ideal. Aber für produktionsgerechte Leistung oder größere Arbeitslasten ist vLLM die empfohlene Wahl. Denke daran, dass vLLM zwar lokal ausgeführt werden kann, aber trotzdem einen leistungsfähigen Grafikprozessor benötigt.
In diesem Tutorium haben wir Magistral Small - einen schlussfolgernden LLM von Mistral - verwendet, um einen Schritt-für-Schritt-Logik-Debugger zu erstellen. Wir haben das Modell sowohl mit Ollama für schnelle Tests auf dem Gerät als auch mit vLLM für GPU-Inferenzen mit hohem Durchsatz und OpenAI-kompatiblen APIs lokal eingesetzt. Außerdem haben wir die Argumentationsfähigkeit des Modells mit einer Gradio-Anwendung getestet. Egal, ob du fehlerhafte Logik debuggen oder logische KI-Tools entwickeln willst, Magistral Small kann eine gute Lösung sein.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
