
Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.2K
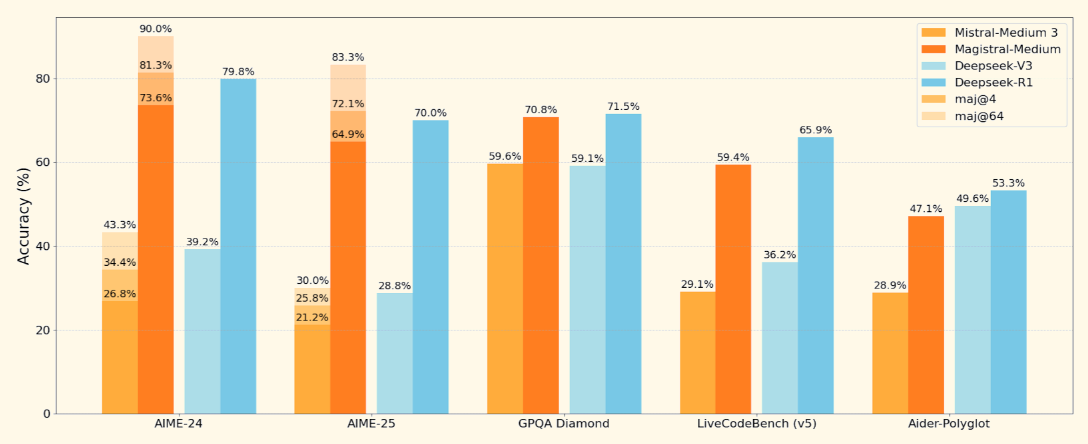
Mistral ha lanzado su primer modelo de razonamiento, Magistral, disponible en dos variantes: Magistral Pequeña (peso abierto) y Magistral Mediana (modelo cerrado).
En este blog me centraré en Magistral Small, un modelo de razonamiento de peso abierto diseñado para tareas que requieren lógica estructurada, comprensión multilingüe y la capacidad de proporcionar explicaciones rastreables. Cuando se combina con motores de inferencia de alto rendimiento como vLLM o con herramientas fáciles de usar como Ollama, se convierte en una gran herramienta para depurar tareas de lógica y razonamiento defectuosas.
En este tutorial, te explicaré paso a paso cómo hacerlo:
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Magistral es el primer modelo de razonamiento dedicado de Mistral AI, construido para una lógica paso a paso, precisión multilingüe y resultados rastreables. Es un modelo de doble liberación que se presenta en dos variantes:
Fuente: Mistral
Magistral Pequeño, el modelo abierto en el que nos centraremos, admite una ventana de contexto de 128K (se recomiendan 40K para un rendimiento estable). Se entrena utilizando ajuste fino supervisado sobre trazas Magistral Medium y aprendizaje por refuerzo.
En esta sección, vamos a realizar la inferencia sobre el modelo Magistral de Mistral localmente utilizando Ollama. Ten en cuenta que este modelo requiere aproximadamente 14 GB de espacio y puede caber en una sola RTX 4090 o en un MacBook de 32 GB de RAM una vez cuantificado. He ejecutado esta demostración en un MacBook Pro M3.
Descarga Ollama para macOS, Windows o Linux desde: https://ollama.com/download.
Sigue las instrucciones del instalador y, tras la instalación, compruébalo ejecutando esto en el terminal:
ollama --versionA continuación, extrae el modelo Magistral ejecutando el código siguiente:
ollama pull magistral
Esto arrastrará el modelo Magistral a tu máquina local. Nota: Llevará algún tiempo, ya que el modelo ocupa unos 14 GB.
Empecemos por instalar todas las dependencias necesarias.
pip install ollama
pip install requestsCon las dependencias instaladas, estamos listos para ejecutar la inferencia.
Ahora, configuramos una estructura de plantilla rápida (como se menciona en el original documento Magistral) que guía el pensamiento del modelo.
import gradio as gr
import requests
import json
def build_prompt(flawed_logic):
return f"""<s>[SYSTEM_PROMPT]
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and detailed as needed until you're confident.
</think>
Do not mention that you're debugging — just present your thought process and conclusion naturally.
[/SYSTEM_PROMPT][INST]
Here is a flawed solution. Can you debug it and correct it step by step?
\"\"\"{flawed_logic}\"\"\"
[/INST]
"""La función anterior devuelve un aviso formateado que guía a Magistral a:
Esta estructura es importante para modelos como Magistral, que se han entrenado con indicaciones aumentadas por herramientas. La misma estructura de indicaciones del sistema puede utilizarse tanto para problemas matemáticos como de codificación.
En este paso, transmitimos la salida del modelo Magistral en tiempo real utilizando la API local de Ollama. Puesto que nos centramos en depurar la lógica defectuosa con un razonamiento rastreable paso a paso, es importante que el usuario pueda ver cómo el modelo llega a sus conclusiones. Por último, mostramos la explicación mediante un Gradio limpia.
def call_ollama_stream(flawed_logic):
prompt = build_prompt(flawed_logic)
response_text = ""
with requests.post(
"http://localhost:11434/api/generate",
json={"model": "magistral", "prompt": prompt, "stream": True},
stream=True,
) as r:
for line in r.iter_lines():
if line:
content = json.loads(line).get("response", "")
response_text += content
return response_text
with gr.Blocks(theme=gr.themes.Base()) as demo:
gr.Markdown("## Chain-of-Logic Debugger (Magistral + Ollama)")
gr.Markdown("Paste a flawed logical argument or math proof, and Magistral will debug it with step-by-step reasoning.")
with gr.Row():
input_box = gr.Textbox(lines=8, label="Flawed Logic / Proof")
output_box = gr.Textbox(lines=15, label="Debugged Explanation")
debug_button = gr.Button("Run Debugger")
debug_button.click(fn=call_ollama_stream, inputs=input_box, outputs=output_box)
demo.launch(debug = True, share=True)He aquí un esquema de lo que ocurre aquí:
build_prompt() para envolver la entrada del usuario en una consulta estructurada que guía al modelo con etiquetas de razonamiento call_ollama_stream() envía la solicitud a la API HTTP de Ollama en localhost:11434 mediante una solicitud POST de flujo.requests.iter_lines(). Por cada línea recibida, extrae el campo de respuesta de la carga JSON y lo añade a un búfer de texto en ejecución.Esta es la entrada que he probado:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.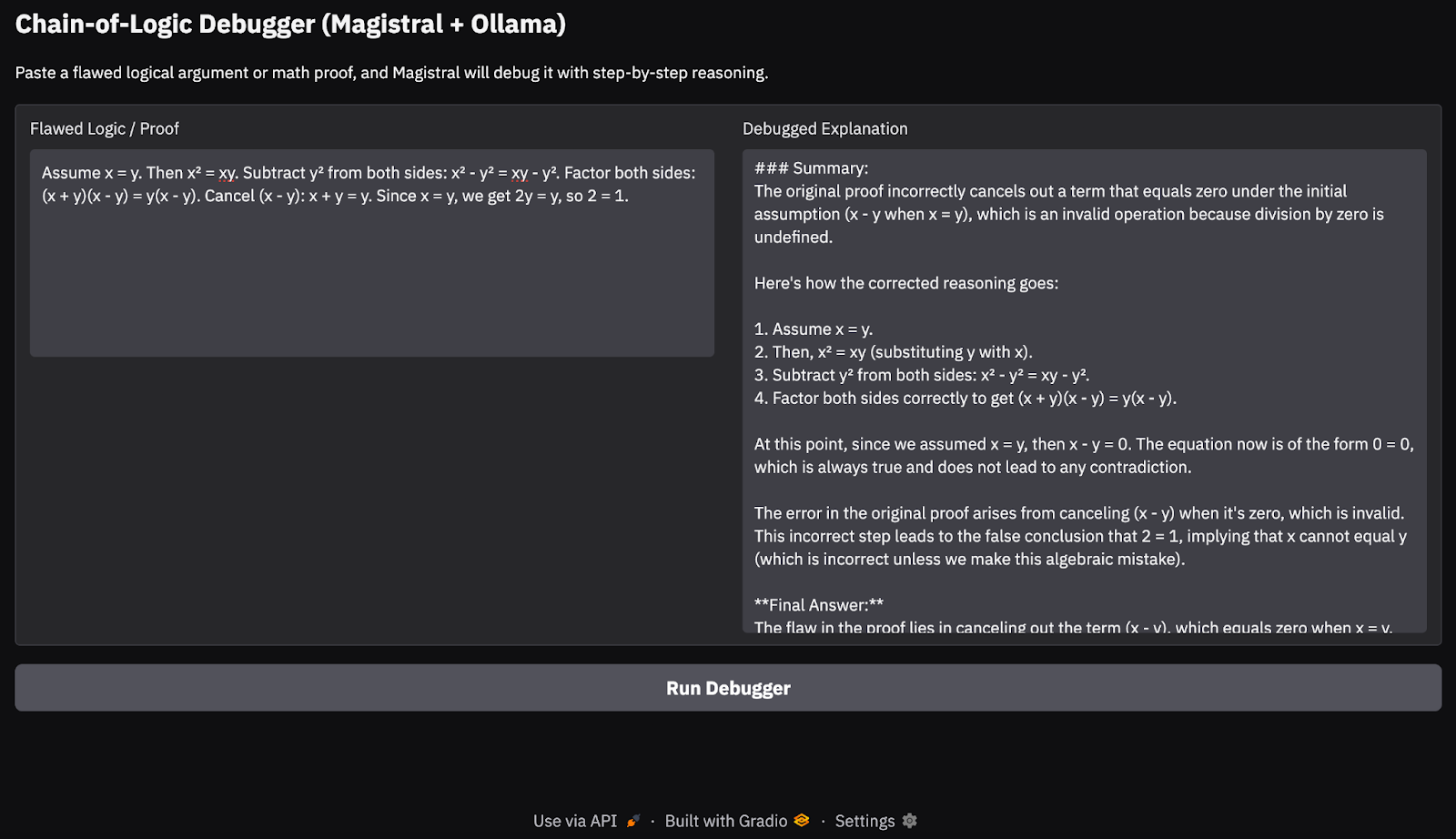
En mis pruebas en un MacBook Pro M3, el modelo manejó bastante bien las cadenas lógicas sencillas y las pruebas matemáticas. Sin embargo, para tareas de razonamiento más profundas o cadenas de pensamiento más largas, de vez en cuando se le escapaban casos límite, algo esperable de un modelo abierto de 24B. Este enfoque es ideal para demostraciones de razonamiento ligeras o en el dispositivo en el dispositivo, sin depender de las API de la nube.
En esta sección, explicaré cómo aprovisionar una potente instancia de GPU en RunPod, desplegar el modelo Magistral de Mistral utilizando vLLMy exponer una API compatible con OpenAI para la inferencia local y remota.
Antes de lanzar el modelo, asegúrate de que tu cuenta RunPod está configurada:
Ahora, vamos a aprovisionar un pod capaz de alojar el modelo. Para configurar un pod, sigue estos pasos:
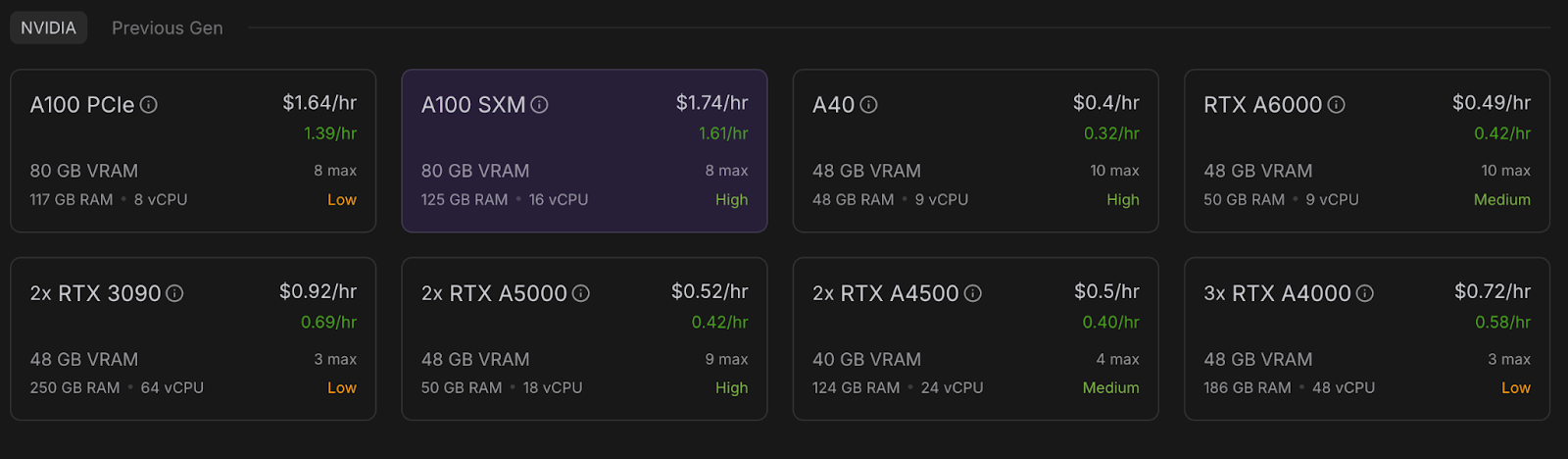
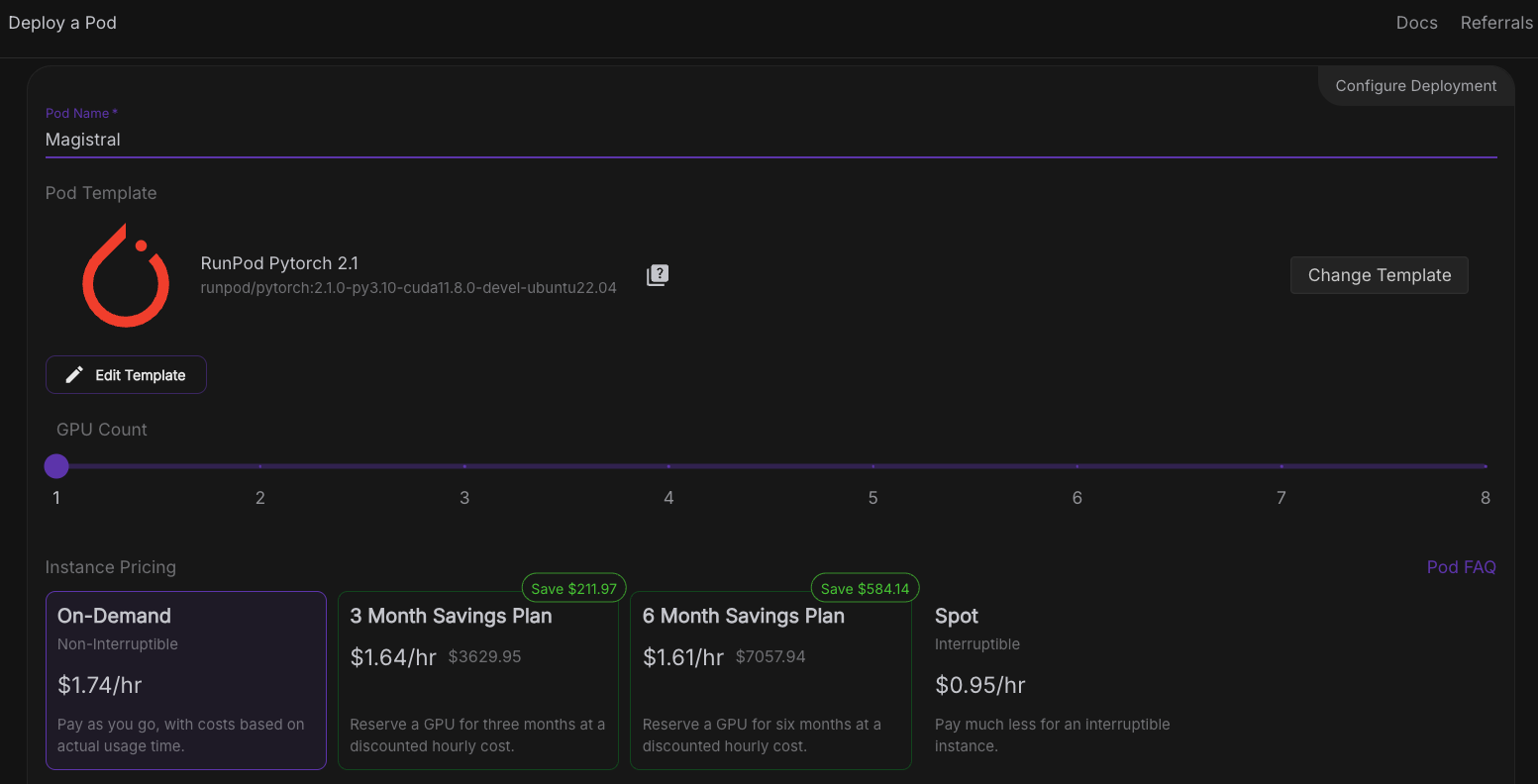
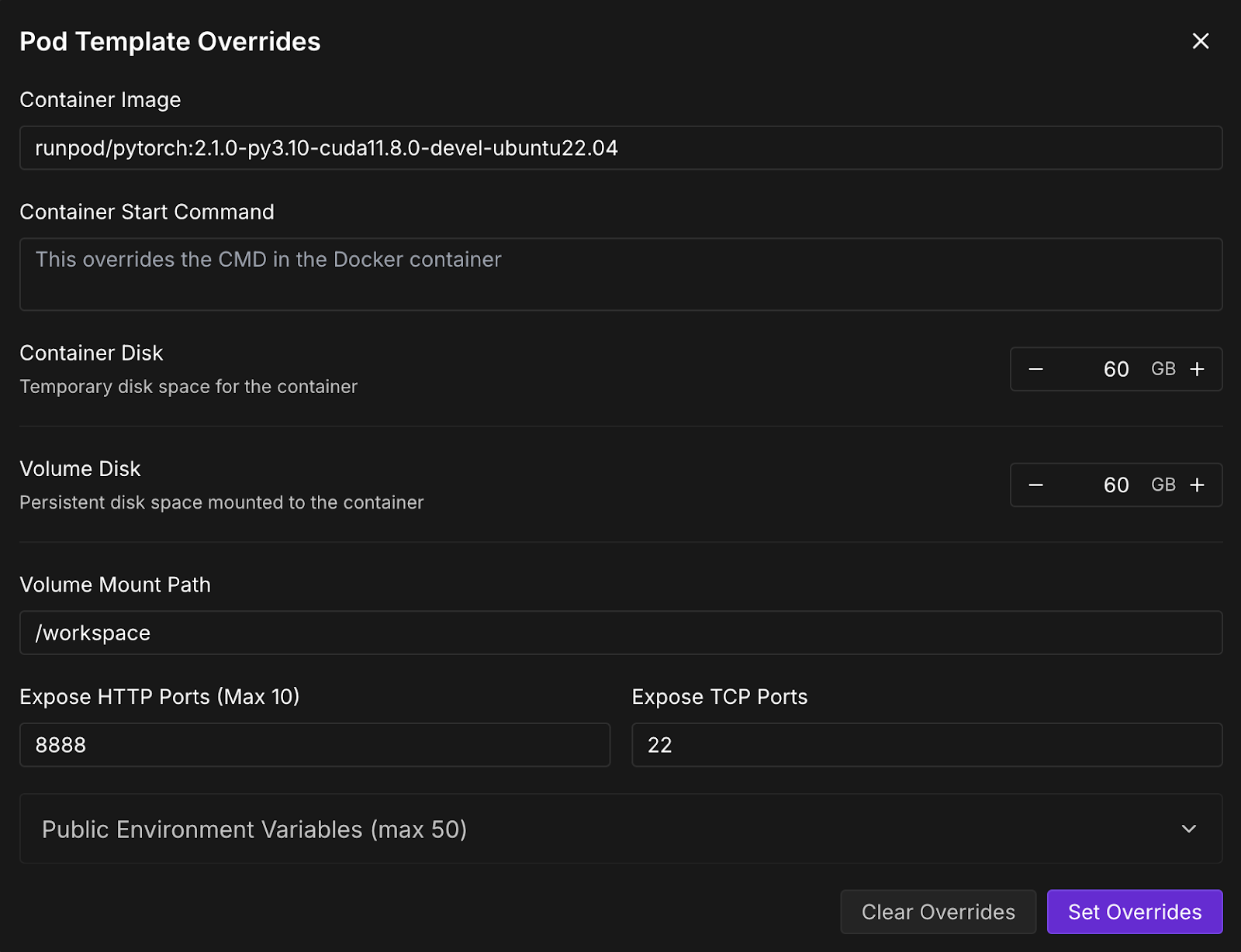
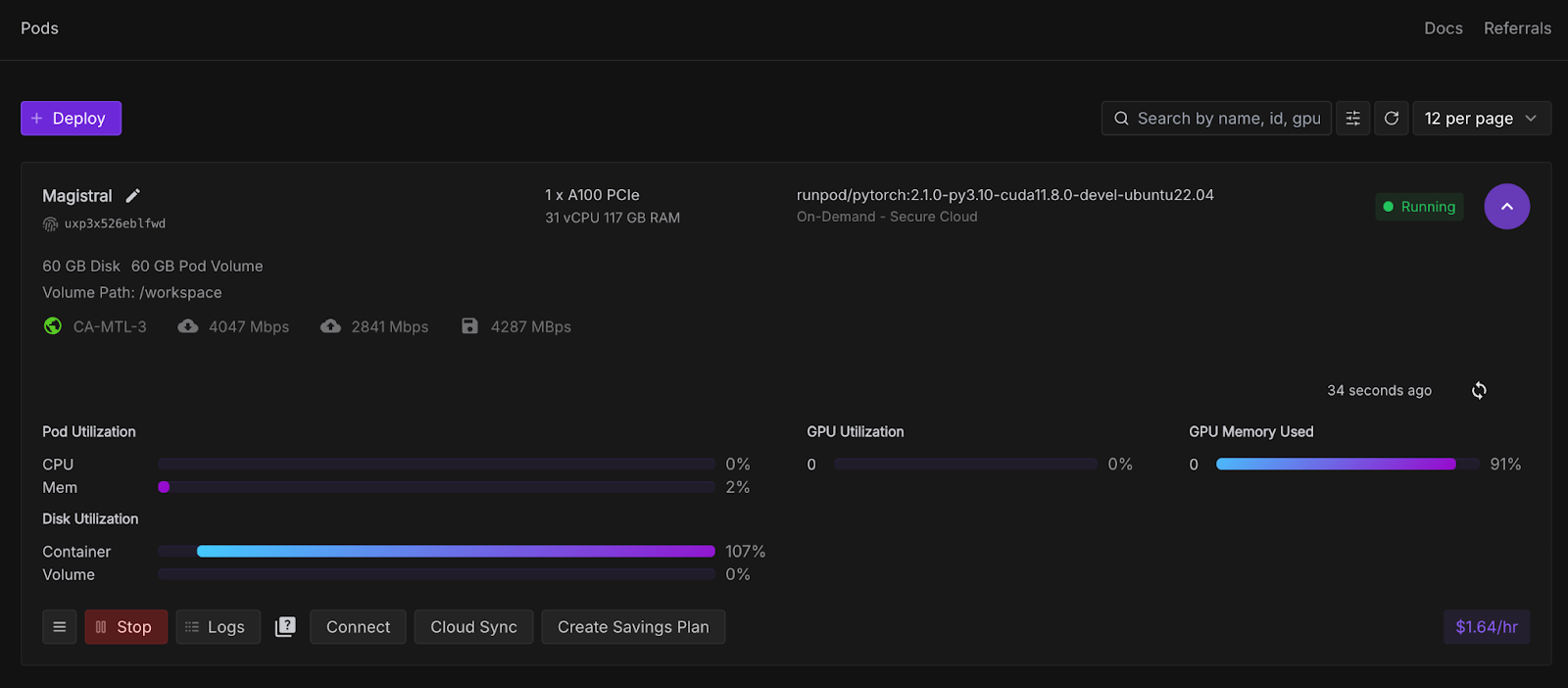
Una vez que el botónConectar se vuelva clicable, haz clic en él. Verás varias opciones de conexión: puedes:
Nota: Espera hasta que veas un punto verde 🟢con un signo Listo debajo de Jupyter Lab.
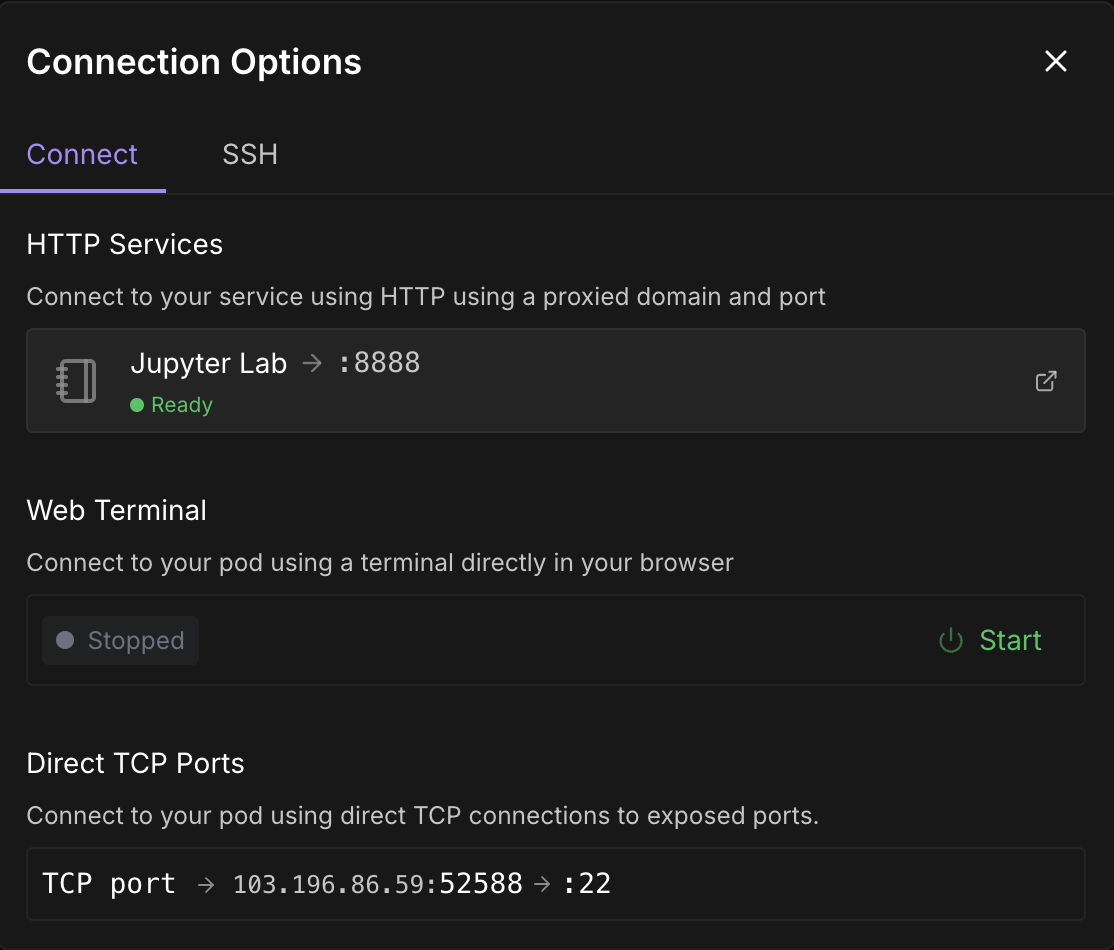
Haz clic en Jupyter Lab-te llevará a otra ventana con opciones para crear un nuevo cuaderno Jupyter. Abre un nuevo terminal o crea un nuevo archivo Python.
Ya sea en el terminal o en Jupyter Notebook dentro de tu pod, instala vLLM y sus dependencias.
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install gradioAdemás, asegúrate de que estás ejecutando mistral_common >= 1.6.0 ejecutando:
python -c "import mistral_common; print(mistral_common.__version__)"Ahora, vamos a servir el modelo. Haz clic en el signo "+" de la esquina superior izquierda y selecciona terminal en las opciones, luego ejecuta el siguiente comando:
vllm serve mistralai/Magistral-Small-2506 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tool-call-parser mistral \
--enable-auto-tool-choiceMantén este terminal en ejecución, ya que este comando lanza elmodeloMagistral Small utilizando vLLM y lo pone a disposición en un punto final de API rápido y compatible con OpenAI (http://localhost:8000/v1). Aquí tienes un desglose de cada bandera:
|
Flag |
Descripción |
|
|
Es un identificador de modelo de Hugging Face. vLLM descarga automáticamente este modelo si no está ya presente. |
|
|
Esto garantiza que el tokenizador se interpreta utilizando la lógica específica de Mistral |
|
|
Indica que la configuración del modelo está en el formato personalizado de Mistral, no en el predeterminado de Hugging Face. |
|
|
Esto carga los pesos del modelo utilizando la disposición esperada de Mistral (importante para la compatibilidad). |
|
|
Habilita una herramienta de análisis sintáctico según la estructura de Mistral. |
|
|
Selecciona automáticamente la mejor herramienta en función de la entrada si se utiliza la llamada a la herramienta. Esto es opcional, pero útil para los modelos entrenados con herramientas de razonamiento. |
Ahora construiremos una demostración en la que se pida a Magistral que depure una prueba lógica o matemática defectuosa. El modelo emitirá un monólogo interior detallado envuelto en etiquetas<think> de y un resumen final.
Empezaremos configurando las importaciones e inicializando el cliente OpenAI en Jupyter Notebook. A continuación, configuramos el indicador del sistema de Magistral como se sugiere en el documento original de Magistral.
import gradio as gr
from openai import OpenAI
import re
import time
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
SYSTEM_PROMPT = """<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
<think>
Your thoughts or draft, like working through an exercise on scratch paper.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user.
Problem:
[/SYSTEM_PROMPT]"""En SYSTEM_PROMPT se define el formato estructurado de cómo debe responder el modelo:
A continuación, nos ocupamos del flujo de salida del modelo configurando las direcciones temperature, top_p, y max_tokens necesarias, tal y como se sugiere en el blog original de Magistral.
# Streaming logic with stop control
def debug_faulty_logic_stream(faulty_proof, stop_signal):
stop_signal["stop"] = False
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Here is a flawed logic or math proof. Can you debug it step-by-step?\n\n{faulty_proof}"}
]
try:
response = client.chat.completions.create(
model="mistralai/Magistral-Small-2506",
messages=messages,
stream=True,
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
buffer = ""
for chunk in response:
if stop_signal.get("stop"):
break
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
buffer += delta.content
filtered = re.sub(r"<think>.*?</think>", "", buffer, flags=re.DOTALL).strip()
yield filtered
time.sleep(0.02)
except Exception as e:
yield f"Error: {str(e)}"
# Set stop flag when stop button is clicked
def stop_streaming(stop_signal):
stop_signal["stop"] = True
return gr.Textbox.update(value="Stopped.")El fragmento de código anterior gestiona la transmisión en directo de la salida token a token desde el modelo. stop_signal permite a los usuarios interrumpir la transmisión pulsando un botón "Detener".
Mientras que el buffer acumula todo el contenido, pero sólo devuelve el resumen (excluyendo la etiqueta<think> ) utilizando una expresión regular. Si se produce algún error (por ejemplo, un problema de red), devuelve el mensaje de error.
Unamos todo esto con una sencilla aplicación de Gradio que permita a los usuarios añadir su lógica o prueba errónea y presentarla al modelo para que la razone.
with gr.Blocks() as demo:
gr.Markdown("## Chain-of-Logic Debugger (Streaming via Magistral + vLLM)")
input_box = gr.Textbox(
label="Paste Your Faulty Logic or Proof",
lines=8,
placeholder="e.g., Assume x = y, then x² = xy..."
)
output_box = gr.Textbox(label="Corrected Reasoning (Streaming Output)")
submit_btn = gr.Button("Submit")
stop_btn = gr.Button("Stop")
stop_flag = gr.State({"stop": False})
submit_btn.click(
fn=debug_faulty_logic_stream,
inputs=[input_box, stop_flag],
outputs=output_box
)
stop_btn.click(
fn=stop_streaming,
inputs=stop_flag,
outputs=output_box
)
if __name__ == "__main__":
demo.launch(share=True, inbrowser=True, debug=True)El código anterior crea una sencilla interfaz Gradio con:
Utiliza gr.State para saber si el usuario quiere interrumpir el proceso de transmisión. A continuación, el método launch() ejecuta la aplicación localmente y la abre en tu navegador. Esta es la entrada que he probado:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.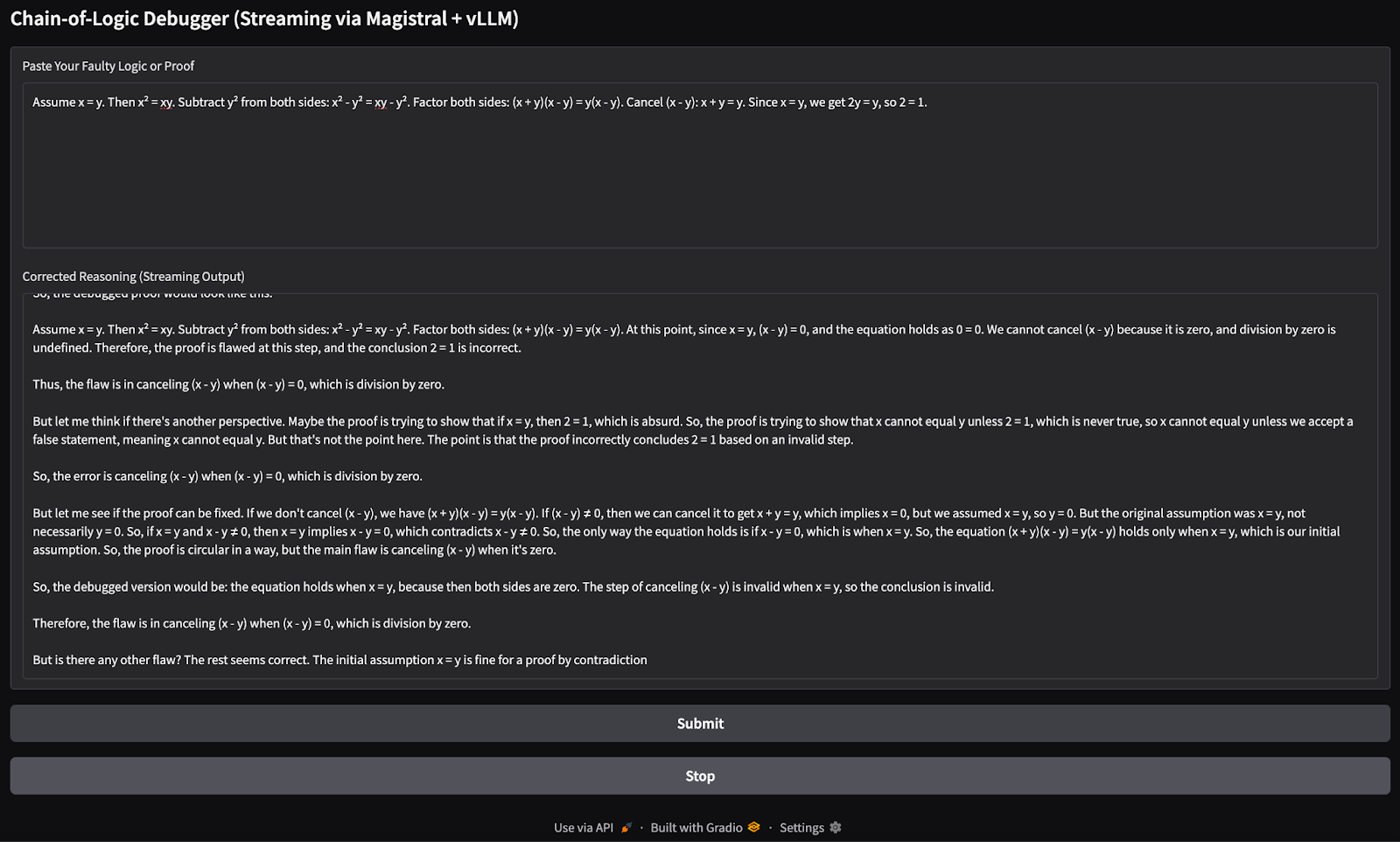
Puedes cambiar al terminal ya en ejecución donde está sirviendo vLLM para comprobar los registros del uso de la caché KV, así como la tasa de aciertos que sube cuando el modelo devuelve alguna salida.

Comparado con Ollama, vLLM fue notablemente más rápido y estable durante la inferencia. La transmisión se sintió fluida, y las salidas estaban en su mayoría bien estructuradas. Dicho esto, el modelo a veces repetía pensamientos dentro de las secciones<think> de , probablemente debido a la naturaleza de la descodificación autorregresiva sin penalizaciones de muestreo.
Mientras que Ollama admite una versión cuantificada de 4 bits del modelo para una inferencia eficiente en el dispositivo, vLLM requiere aceleración en la GPU, lo que hace que sea ligeramente más caro de ejecutar (unos 5 $ para este proyecto). El modelo Magistral cuantizado a 4 bits requiere aproximadamente 14 GB de memoria, que pueden alojarse en una sola GPU RTX 4090 o incluso en un MacBook con 32 GB de RAM. Sin embargo, la inferencia puede ser lenta, de hasta 4 minutos por respuesta, debido a la limitación del cálculo.
En cambio, vLLM ofrece una inferencia significativamente más rápida (aproximadamente menos de un minuto por respuesta) cuando se despliega en GPU de alto rendimiento como la A100 SXM, lo que la hace más adecuada para aplicaciones con capacidad de respuesta o despliegues a escala.
Si sólo estás experimentando y tienes recursos locales, Ollama es ideal por su bajo coste de instalación. Pero para un rendimiento de nivel de producción o cargas de trabajo mayores, vLLM es la opción recomendada. Ten en cuenta que, aunque vLLM puede ejecutarse localmente, sigue necesitando una GPU capaz.
En este tutorial, utilizamos Magistral Small -un LLM de razonamiento de Mistral- para construir un depurador lógico paso a paso. Desplegamos el modelo localmente utilizando tanto Ollama para pruebas rápidas en el dispositivo como vLLM para la inferencia de alto rendimiento en la GPU con API compatibles con OpenAI. También probamos las capacidades de razonamiento del modelo con una aplicación Gradio. Tanto si estás depurando una lógica defectuosa como construyendo herramientas de IA de razonamiento, Magistral Small puede ser una buena solución.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
