
Cursus
Principes fondamentaux de l'IA
10 h
Qwen3 est l'une des suites de modèles ouverts les plus complètes publiées à ce jour.
Elle provient de l'équipe Qwen d'Alibaba et comprend des modèles qui atteignent des performances de niveau recherche ainsi que des versions plus petites qui peuvent être exécutées localement sur du matériel plus modeste.
Dans ce blog, je vous donnerai un aperçu rapide de la suite Qwen3 complète, j'expliquerai comment les modèles ont été développés, je vous présenterai les résultats de l'analyse comparative et je vous montrerai comment vous pouvez accéder à ces modèles et commencer à les utiliser.
Notre équipe travaille également sur des tutoriels qui montrent comment exécuter Qwen3 localement et comment affiner les modèles Qwen3. Je veillerai à mettre à jour cet article dès qu'elles seront prêtes. Si vous revenez ici au cours des deux ou trois prochains jours, vous trouverez des liens vers ces ressources ajoutées à cette introduction.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Qwen3 est la dernière famille de grands modèles linguistiques de l'équipe Qwen d'Alibaba. Tous les modèles de la gamme sont à pondération libre sous la licence Apache 2.0.
Ce qui a tout de suite attiré mon attention, c'est l'introduction d'un budget de réflexion que les utilisateurs peuvent contrôler directement dans l'application Qwen. Cela permet aux utilisateurs réguliers d'exercer un contrôle granulaire sur le processus de raisonnement, ce qui, auparavant, ne pouvait se faire que par programmation.
Comme le montrent les graphiques ci-dessous, l'augmentation des budgets de réflexion améliore considérablement les performances, en particulier pour les mathématiques, le codage et les sciences.
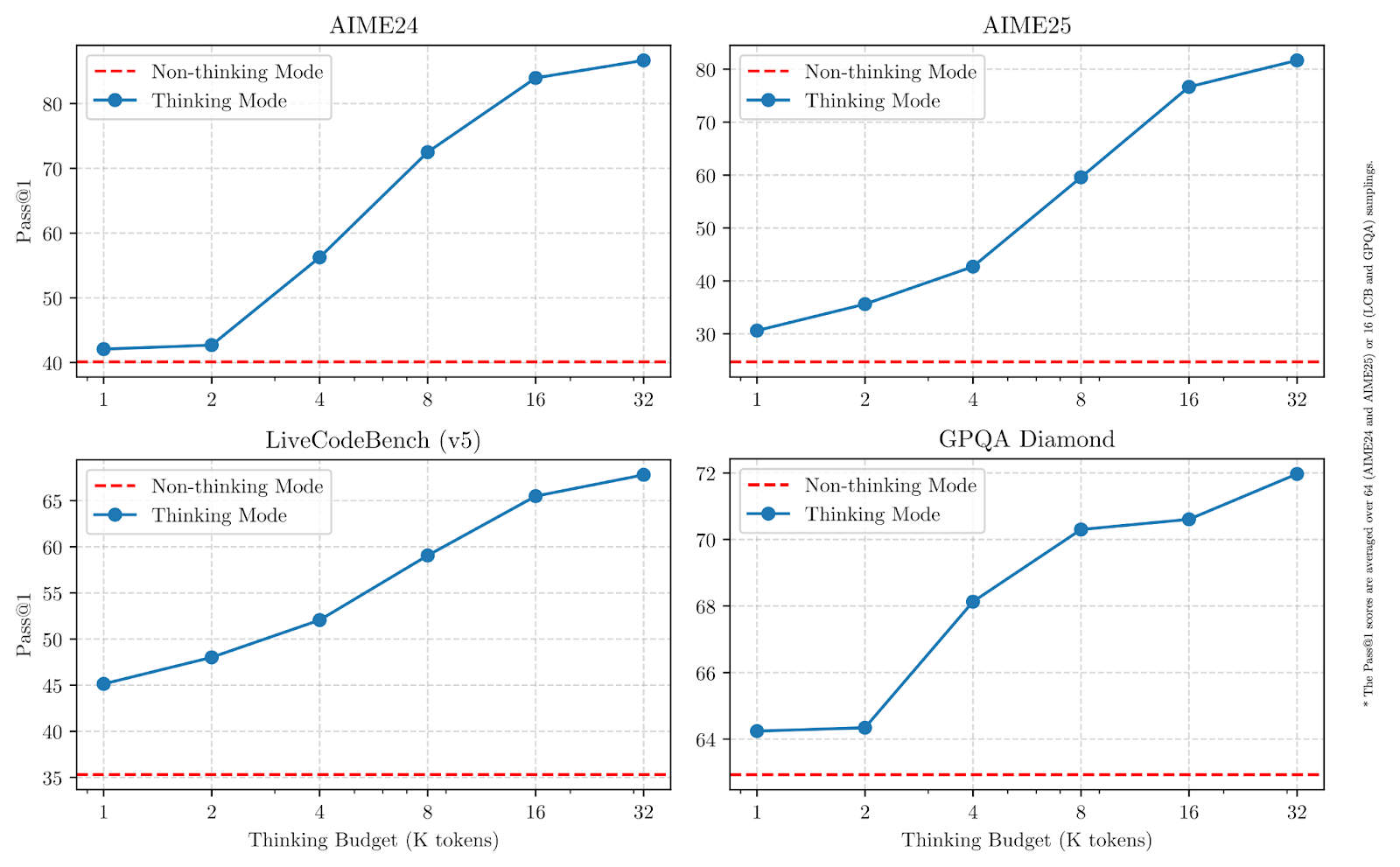
Source : Qwen
Dans les tests de référence, le modèle phare Qwen3-235B-A22B est compétitif par rapport à d'autres modèles de haut niveau et affiche des résultats supérieurs à ceux du modèle DeepSeek-R1 dans les domaines du codage, des mathématiques et du raisonnement général. Examinons rapidement chaque modèle et comprenons à quoi il est destiné.
Il s'agit du plus grand modèle de la gamme Qwen3. Il utilise un mélange d'experts (MoE) avec 235 milliards de paramètres totaux et 22 milliards de paramètres actifs par étape de génération.
Dans un modèle MoE, seul un petit sous-ensemble de paramètres est activé à chaque étape, ce qui le rend plus rapide et moins coûteux à exécuter que les modèles denses (comme le GPT-4o), où tous les paramètres sont toujours utilisés.
Le modèle obtient de bons résultats en mathématiques, en raisonnement et en codage, et dans les comparaisons de référence, il surpasse des modèles tels que DeepSeek-R1.
Qwen3-30B-A3B est un modèle MoE plus petit avec 30 milliards de paramètres totaux et seulement 3 milliards actifs à chaque étape. Malgré le faible nombre d'actifs, ses performances sont comparables à celles de modèles beaucoup plus denses tels que le QwQ-32B. C'est un choix pratique pour les utilisateurs qui recherchent à la fois des capacités de raisonnement et des coûts d'inférence réduits. Comme le modèle 235B, il supporte une fenêtre contextuelle de 128K et est disponible sous Apache 2.0.
Les six modèles denses de la version Qwen3 suivent une architecture plus traditionnelle où tous les paramètres sont actifs à chaque étape. Ils couvrent un large éventail de cas d'utilisation :
Qwen3-32B, 14B, 8B prennent en charge 128K fenêtres contextuelles, tandis que Qwen3-4B, 1.7B, 0.6B prennent en charge 32K. Tous sont à pondération libre et sous licence Apache 2.0. Les petits modèles de ce groupe sont bien adaptés aux déploiements légers, tandis que les plus grands sont plus proches des LLM à usage général.
Qwen3 propose différents modèles en fonction de la profondeur de raisonnement, de la vitesse et du coût de calcul dont vous avez besoin. Voici un aperçu rapide du site :
|
Modèle |
Type |
Contexte Longueur |
Meilleur pour |
|
Qwen3-235B-A22B |
MdE |
128K |
Tâches de recherche, flux de travail des agents, longues chaînes de raisonnement |
|
Qwen3-30B-A3B |
MdE |
128K |
Un raisonnement équilibré pour un coût d'inférence moindre |
|
Qwen3-32B |
Dense |
128K |
Déploiements polyvalents haut de gamme |
|
Qwen3-14B |
Dense |
128K |
Applications de milieu de gamme nécessitant un raisonnement solide |
|
Qwen3-8B |
Dense |
128K |
Tâches de raisonnement légères |
|
Qwen3-4B |
Dense |
32K |
Des applications plus petites, une inférence plus rapide |
|
Qwen3-1.7B |
Dense |
32K |
Cas d'utilisation mobile et embarquée |
|
Qwen3-0.6B |
Dense |
32K |
Paramètres très légers ou limités |
Si vous travaillezsur des tâches nécessitant un raisonnement plus approfondi, l'utilisation d'outils d'agent ou la gestion de contextes longs, Qwen3-235B-A22B vous offrira la plus grande flexibilité.
Pour les cas où vous souhaitez que l'inférence soit plus rapide et moins coûteuse tout en gérant des tâches modérément complexes, Qwen3-30B-A3B est une option solide.
Les modèles denses offrent des déploiements plus simples et une latence prévisible, ce qui les rend plus adaptés aux applications à petite échelle.
Les modèles Qwen3 ont été construits grâce à une phase de pré-entraînement en trois étapes, suivie d'un pipeline de post-entraînement en quatre étapes.
Le préapprentissage est l'étape au cours de laquelle le modèle apprend des modèles généraux à partir de quantités massives de données (langage, logique, mathématiques, code) sans qu'on lui dise exactement ce qu'il doit faire. Le post-entraînement consiste à affiner le modèle pour qu'il se comporte de manière spécifique, par exemple en raisonnant avec prudence ou en suivant des instructions.
Je vais vous présenter les deux parties en termes simples, sans entrer dans les détails techniques.
Par rapport à Qwen2.5, l'ensemble de données de préformation pour Qwen3 a été considérablement élargi. Environ 36 000 milliards de jetons ont été utilisés, soit le double de la génération précédente. Les données comprenaient du contenu web, du texte extrait de documents, des mathématiques synthétiques et des exemples de code générés par les modèles Qwen2.5.
Le processus de formation préalable s'est déroulé en trois étapes :
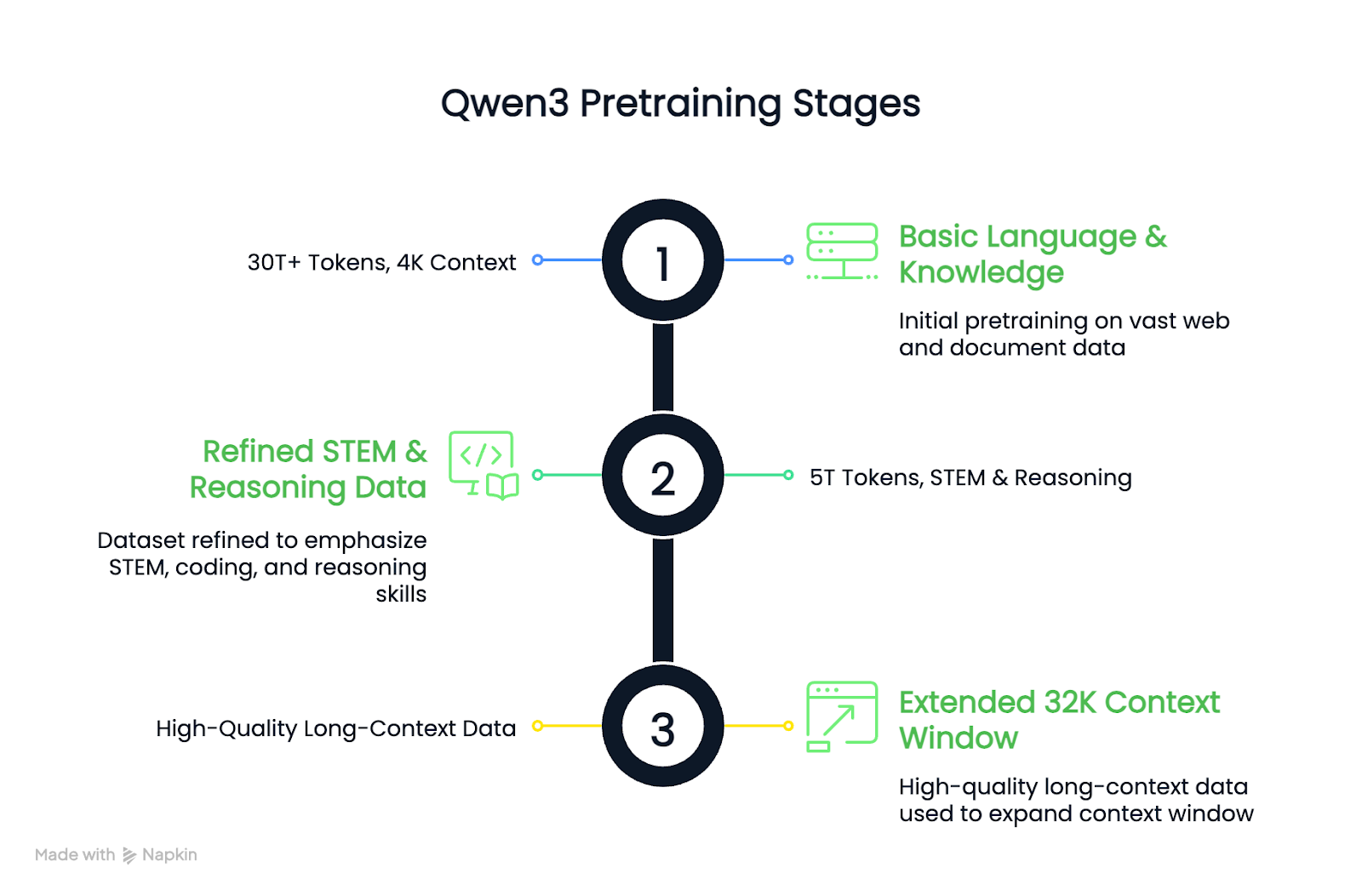
Il en résulte que les modèles de base denses de Qwen3 égalent ou dépassent les modèles de base plus grands de Qwen2.5 tout en utilisant moins de paramètres, en particulier dans les tâches de STIM et de raisonnement.
Le pipeline de post-formation de Qwen3 s'est concentré sur l'intégration de capacités de raisonnement approfondi et de réponse rapide dans un modèle unique. Voyons d'abord le schéma ci-dessous, puis je vous expliquerai pas à pas :
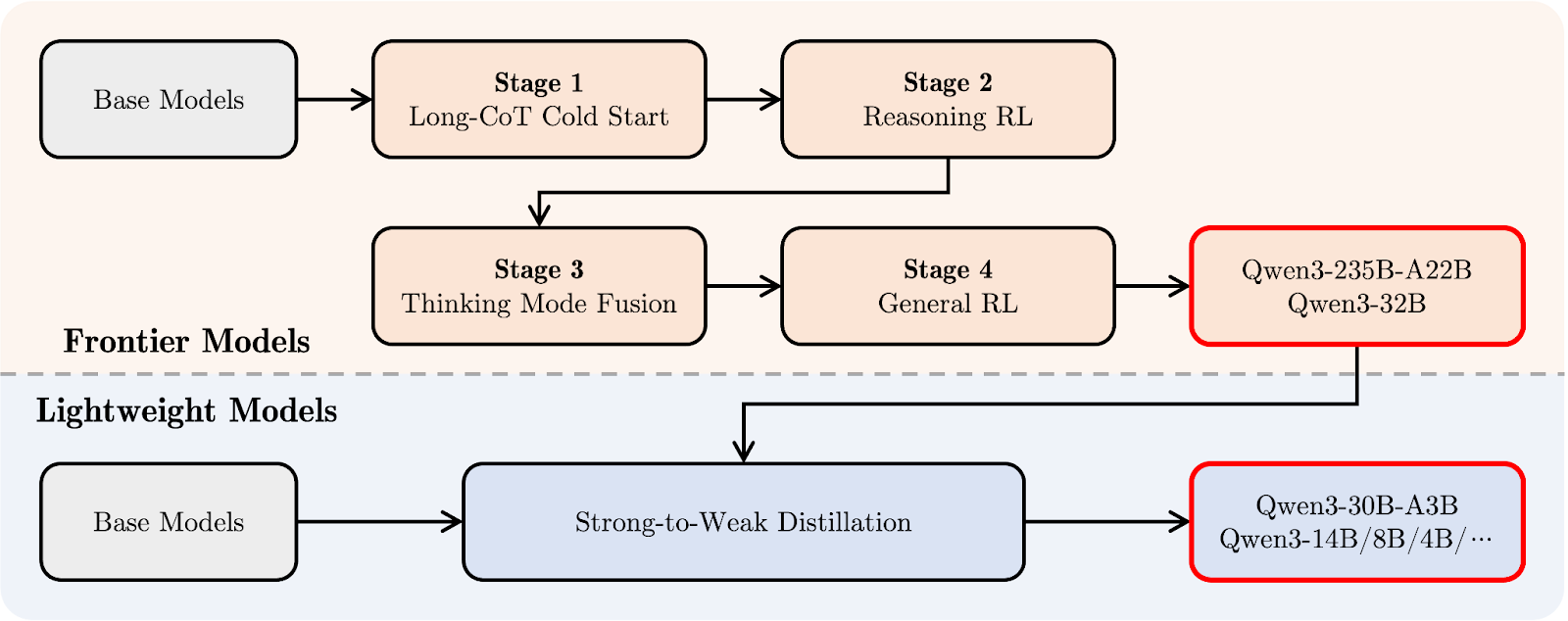
Pipeline post-formation Qwen 3. Source : Qwen
En haut (en orange), vous pouvez voir le chemin de développement des plus grands "modèles frontières", comme Qwen3-235B-A22B et Qwen3-32B. Tout commence par une Longue chaîne de pensée Démarrage à froid (étape 1), où le modèle apprend à raisonner étape par étape sur des tâches plus difficiles.
Vient ensuite le raisonnement Apprentissage par renforcement (RL) (étape 2) pour encourager de meilleures stratégies de résolution de problèmes. Au stade 3, appelé Thinking Mode Fusion, Qwen3 apprend à équilibrer un raisonnement lent et prudent avec des réponses plus rapides. Enfin, une étapeRL générale améliore son comportement dans un large éventail de tâches, comme le suivi d'instructions et les cas d'utilisation agentique.
En dessous (en bleu clair), vous verrez le chemin pour les "modèles légers", comme Qwen3-30B-A3B et les modèles denses plus petits. Ces modèles sont formés à l'aide d'une distillationun processus au cours duquel les connaissances des grands modèles sont comprimées dans des modèles plus petits et plus rapides, sans perdre trop de capacité de raisonnement.
En termes simples, les grands modèles ont été formés en premier, puis les modèles légers ont été distillés à partir de ces modèles. Ainsi, toute la famille Qwen3 partage un style de pensée similaire, même pour des modèles de tailles très différentes.
Les modèles Qwen3 ont été évalués sur une série de critères de raisonnement, de codage et de connaissances générales. Les résultats montrent que le modèle Qwen3-235B-A22B est le plus performant dans la plupart des tâches, mais les modèles plus petits Qwen3-30B-A3B et Qwen3-4B offrent également de bonnes performances.
Dans la plupart des tests de référence, le Qwen3-235B-A22B figure parmi les modèles les plus performants, mais il n'est pas toujours en tête.
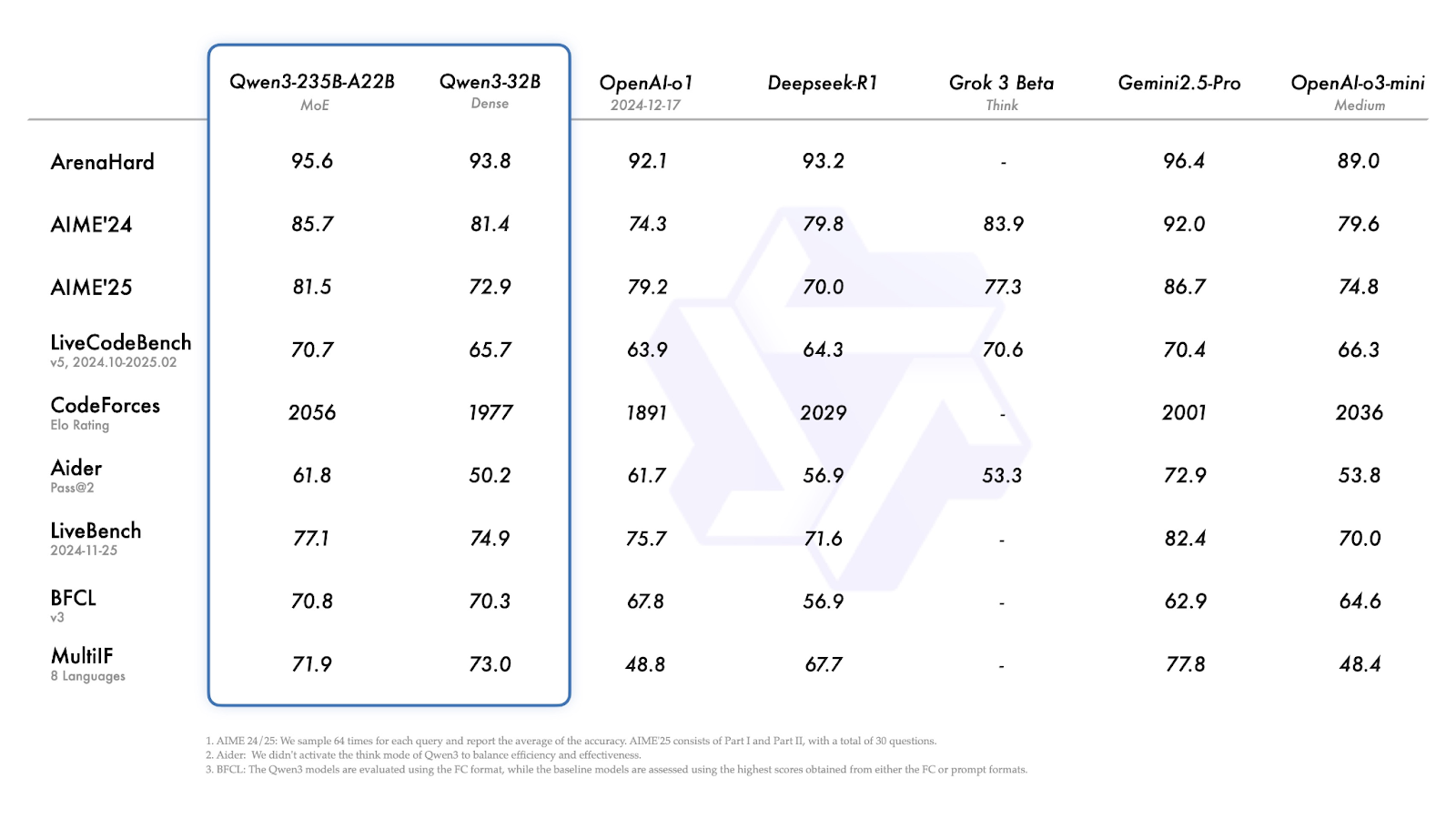
Source : Qwen
Examinons rapidement les résultats ci-dessus :
Qwen3-30B-A3B (le plus petit modèle MoE) obtient de bons résultats dans presque tous les points de référence, égalant ou surpassant systématiquement les modèles denses de taille similaire.
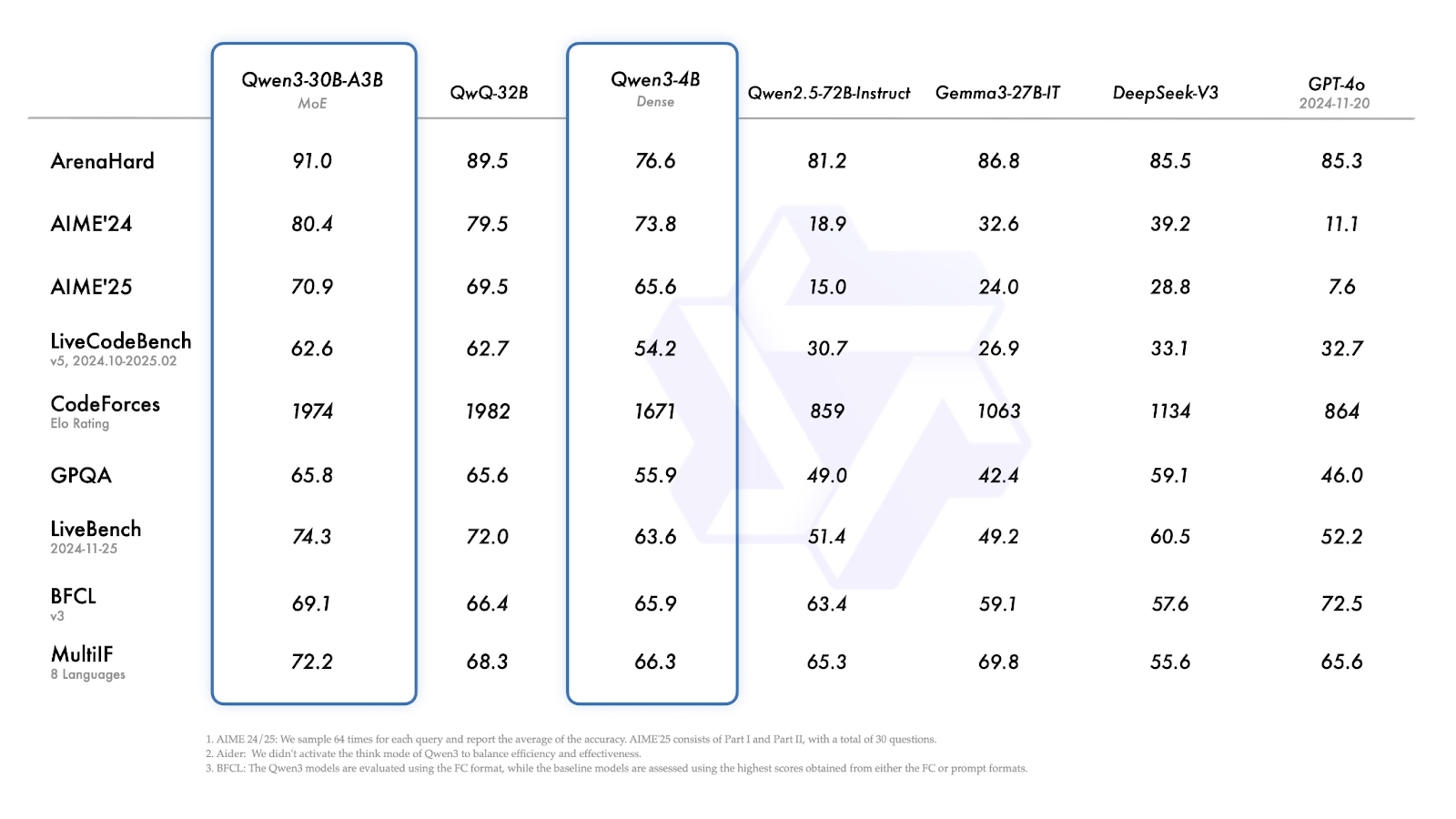
Source : Qwen
Qwen3-4B affiche des performances solides pour sa taille :
Les modèles Qwen3 sont accessibles au public et peuvent être utilisés sur l'application de chat, via l'API, téléchargés pour un déploiement local ou intégrés dans des configurations personnalisées.
Vous pouvez essayer Qwen3 directement à l'adresse suivante chat.qwen.ai.
Vous n'aurez accès qu'à trois modèles de la famille Qwen 3 dans l'application de chat : Qwen3-235B, Qwen3-30B et Qwen3-32B :
Qwen3 fonctionne avec des formats d'API compatibles avec OpenAI par le biais de fournisseurs tels que ModelScope ou DashScope. Des outils comme vLLM et SGLang offrent un service efficace pour un déploiement local ou autonome. Le blog officiel de Qwen 3 contient plus de détails à ce sujet.
Tous les modèles Qwen3, qu'ils soient MoE ou denses, sont publiés sous la licence Apache 2.0. Ils sont disponibles sur :
Vous pouvez également exécuter Qwen3 localement en utilisant :
Qwen3 est l'une des suites de modèles ouverts les plus complètes publiées à ce jour.
Le modèle phare 235B MoE est performant dans les tâches de raisonnement, de mathématiques et de codage, tandis que les versions 30B et 4B offrent des alternatives pratiques pour les déploiements à plus petite échelle ou à budget limité. La possibilité d'ajuster le budget de réflexion du modèle ajoute une couche supplémentaire de flexibilité pour les utilisateurs réguliers.
En l'état, Qwen3 est une version bien équilibrée qui couvre un large éventail de cas d'utilisation et qui est prête à être utilisée dans des contextes de recherche et de production.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus
blog
Kurtis Pykes
15 min
blog
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Samuel Shaibu
