Python for Spreadsheet Users
BasicSkill Level
4 Hr
29.1K learners
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeMenginstal pandas itu mudah; gunakan perintah pip install di terminal Anda.
pip install pandasSebagai alternatif, Anda dapat menginstalnya melalui conda:
conda install pandasSetelah menginstal pandas, sebaiknya periksa versi yang terpasang untuk memastikan semuanya berfungsi dengan benar:
import pandas as pd
print(pd.__version__) # Prints the pandas versionIni mengonfirmasi bahwa pandas terpasang dengan benar dan memungkinkan Anda memverifikasi kompatibilitas dengan paket lain.
Untuk mulai bekerja dengan pandas, impor paket Python pandas seperti di bawah ini. Saat mengimpor pandas, alias paling umum untuk pandas adalah pd.
import pandas as pdGunakan read_csv() dengan path ke file CSV untuk membaca file comma-separated values (lihat tutorial kami tentang mengimpor data dengan read_csv() untuk detail lebih lanjut).
df = pd.read_csv("diabetes.csv")Operasi baca ini memuat file CSV diabetes.csv untuk menghasilkan objek DataFrame pandas df. Sepanjang tutorial ini, Anda akan melihat cara memanipulasi objek DataFrame seperti itu.
Membaca file teks mirip dengan file CSV. Satu nuansanya adalah Anda perlu menentukan pemisah dengan argumen sep, seperti di bawah ini. Argumen pemisah merujuk pada simbol yang digunakan untuk memisahkan baris dalam DataFrame. Koma (sep = ","), whitespace(sep = "\s"), tab (sep = "\t"), dan titik dua(sep = ":") adalah pemisah yang umum digunakan. Di sini \s merepresentasikan satu karakter spasi.
df = pd.read_csv("diabetes.txt", sep="\s")Membaca file excel (baik XLS maupun XLSX) semudah fungsi read_excel(), menggunakan path file sebagai masukan.
df = pd.read_excel('diabetes.xlsx')Anda juga dapat menentukan argumen lain, seperti header untuk menentukan baris mana yang menjadi header DataFrame. Nilai defaultnya adalah 0, yang menandakan baris pertama sebagai header atau nama kolom. Anda juga dapat menentukan nama kolom sebagai list pada argumen names. Argumen index_col (default None) dapat digunakan jika file berisi indeks baris.
Catatan: Dalam DataFrame atau Series pandas, indeks adalah pengenal yang menunjuk ke lokasi baris atau kolom dalam DataFrame pandas. Singkatnya, indeks memberi label baris atau kolom dari DataFrame dan memungkinkan Anda mengakses baris atau kolom tertentu dengan menggunakan indeksnya (Anda akan melihat ini nanti). Indeks baris DataFrame bisa berupa rentang (mis., 0 hingga 303), deret waktu (tanggal atau timestamp), pengenal unik (mis., employee_ID dalam tabel employees), atau tipe data lainnya. Untuk kolom, biasanya berupa string (menunjukkan nama kolom).
Membaca file Excel dengan beberapa sheet tidak jauh berbeda. Anda hanya perlu menentukan satu argumen tambahan, sheet_name, di mana Anda dapat memberikan string untuk nama sheet atau integer untuk posisi sheet (perhatikan bahwa Python menggunakan penomoran berbasis 0, di mana sheet pertama dapat diakses dengan sheet_name = 0)
# Mengambil sheet kedua karena Python menggunakan penomoran berbasis 0
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)Mirip dengan fungsi read_csv(), Anda dapat menggunakan read_json() untuk tipe file JSON dengan nama file JSON sebagai argumen (untuk detail lebih lanjut baca tutorial ini tentang mengimpor data JSON dan HTML ke pandas). Kode di bawah membaca file JSON dari disk dan membuat objek DataFrame df.
df = pd.read_json("diabetes.json")Jika Anda ingin mempelajari lebih lanjut tentang mengimpor data dengan pandas, lihat lembar contekan ini tentang mengimpor berbagai tipe file dengan Python.
Untuk memuat data dari basis data relasional, gunakan pd.read_sql() bersama koneksi basis data.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Untuk dataset besar, pertimbangkan menggunakan SQLAlchemy untuk mengoptimalkan kueri.
Jika data Anda berasal dari web API, pandas dapat membacanya langsung menggunakan pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Jika respons API dipaginasi, atau dalam format JSON bertingkat, Anda mungkin memerlukan pemrosesan tambahan menggunakan json_normalize() dari pandas.io.json.
Sama seperti pandas dapat mengimpor data dari berbagai tipe file, pandas juga memungkinkan Anda mengekspor data ke berbagai format. Hal ini terutama terjadi saat data ditransformasikan menggunakan pandas dan perlu disimpan secara lokal di mesin Anda. Di bawah ini adalah cara mengekspor DataFrame pandas ke berbagai format.
DataFrame pandas (di sini kita menggunakan df) disimpan sebagai file CSV menggunakan metode .to_csv(). Argumennya mencakup nama file dengan path dan index – di mana index = True menyiratkan menulis indeks DataFrame.
df.to_csv("diabetes_out.csv", index=False)Ekspor objek DataFrame ke file JSON dengan memanggil metode .to_json().
df.to_json("diabetes_out.json")Catatan: File JSON menyimpan objek tabular seperti DataFrame sebagai pasangan key-value. Jadi Anda akan melihat header kolom yang berulang dalam file JSON.
Seperti saat menulis DataFrame ke file CSV, Anda dapat memanggil .to_csv(). Satu-satunya perbedaannya adalah format file output .txt, dan Anda perlu menentukan pemisah menggunakan argumen sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Panggil .to_excel() dari objek DataFrame untuk menyimpannya sebagai file “.xls” atau “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Setelah membaca data tabular sebagai DataFrame, Anda perlu sekilas melihat datanya. Anda dapat melihat sampel kecil dari dataset atau ringkasan data dalam bentuk statistik ringkasan.
.head() dan .tail()Anda dapat melihat beberapa baris pertama atau terakhir dari DataFrame menggunakan metode .head() atau .tail(). Anda dapat menentukan jumlah baris melalui argumen n (nilai default adalah 5).
df.head()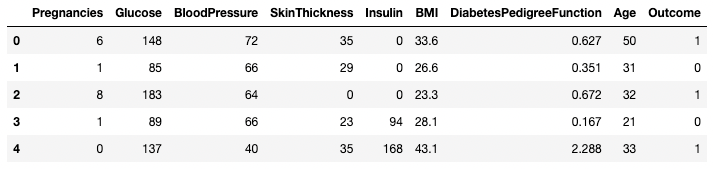
Lima baris pertama DataFrame
df.tail(n = 10)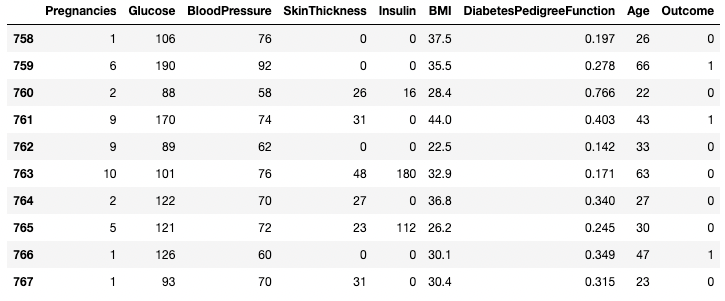
10 baris pertama DataFrame
.describe()Metode .describe() mencetak statistik ringkasan dari semua kolom numerik, seperti jumlah, mean, standar deviasi, rentang, dan kuartil kolom numerik.
df.describe()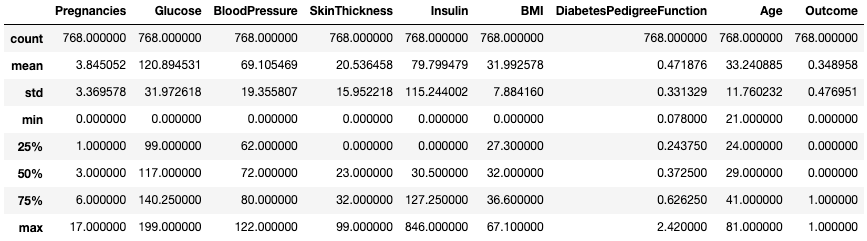
Dapatkan statistik ringkasan dengan .describe()
Ini memberikan gambaran cepat tentang skala, skew, dan rentang data numerik.
Anda juga dapat memodifikasi kuartil menggunakan argumen percentiles. Di sini, misalnya, kita melihat persentil 30%, 50%, dan 70% dari kolom numerik dalam DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])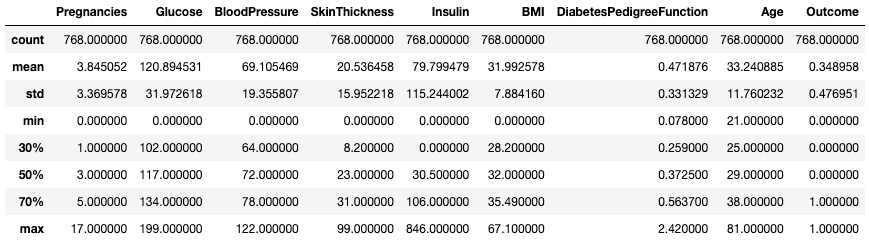
Dapatkan statistik ringkasan dengan persentil tertentu
Anda juga dapat mengisolasi tipe data tertentu dalam output ringkasan Anda dengan menggunakan argumen include. Di sini, misalnya, kita hanya merangkum kolom dengan tipe data integer.
df.describe(include=[int])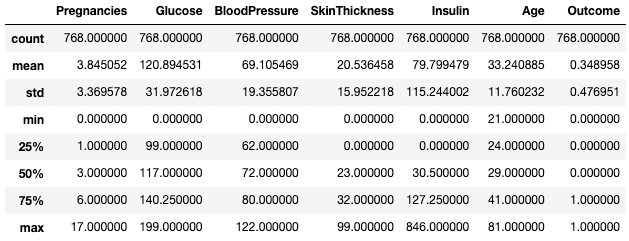
Dapatkan statistik ringkasan hanya untuk kolom integer
Demikian juga, Anda mungkin ingin mengecualikan tipe data tertentu menggunakan argumen exclude.
df.describe(exclude=[int])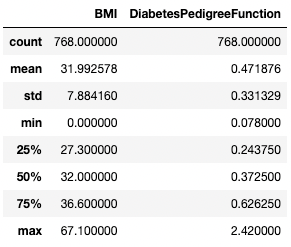
Dapatkan statistik ringkasan hanya untuk kolom non-integer
Sering kali, praktisi merasa lebih mudah melihat statistik seperti itu dengan mentransposenya menggunakan atribut .T.
df.describe().T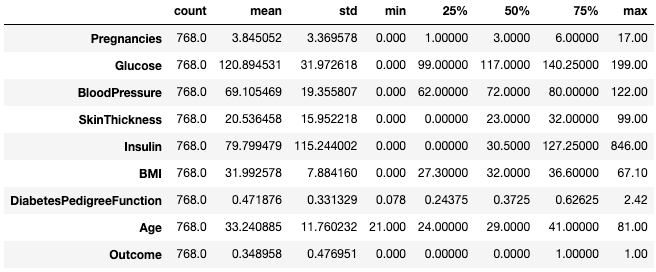
Transpose statistik ringkasan dengan .T
Untuk lebih lanjut tentang mendeskripsikan DataFrame, lihat lembar contekan berikut.
Metode .info() adalah cara cepat untuk melihat tipe data, nilai hilang, dan ukuran data dari sebuah DataFrame. Di sini, kami menetapkan argumen show_counts ke True, yang memberikan tinjauan atas total nilai non-hilang di setiap kolom. Kami juga menetapkan memory_usage ke True, yang menunjukkan total penggunaan memori elemen DataFrame. Saat verbose diatur ke True, ini mencetak ringkasan lengkap dari .info().
df.info(show_counts=True, memory_usage=True, verbose=True)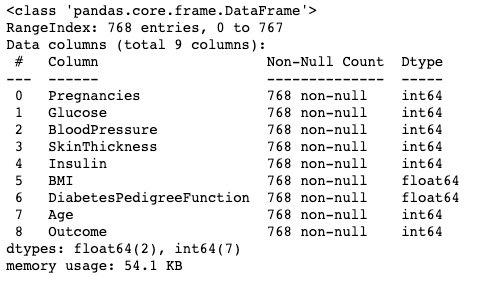
Jumlah baris dan kolom dari sebuah DataFrame dapat diidentifikasi menggunakan atribut .shape dari DataFrame. Ini mengembalikan tuple (baris, kolom) dan dapat diindeks untuk mendapatkan hanya jumlah baris, dan hanya jumlah kolom sebagai output.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Memanggil atribut .columns dari objek DataFrame mengembalikan nama kolom dalam bentuk objek Index. Sebagai pengingat, indeks pandas adalah alamat/label baris atau kolom.
df.columns
Ini dapat dikonversi menjadi list menggunakan fungsi list().
list(df.columns)
DataFrame sampel tidak memiliki nilai hilang. Mari kita tambahkan beberapa agar lebih menarik. Metode .copy() membuat salinan DataFrame asli. Ini dilakukan untuk memastikan bahwa perubahan pada salinan tidak tercermin di DataFrame asli. Menggunakan .loc (akan dibahas nanti), Anda dapat mengatur baris dua hingga lima dari kolom Pregnancies ke nilai NaN, yang menandakan nilai hilang.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)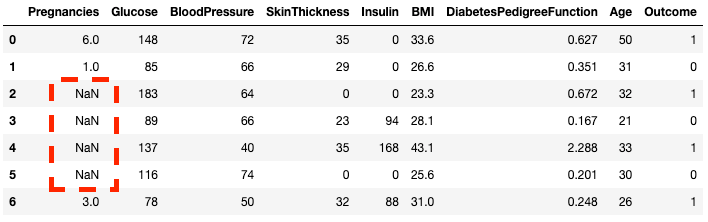
Anda dapat melihat, sekarang baris 2 hingga 5 adalah NaN
Anda dapat memeriksa apakah setiap elemen dalam DataFrame hilang menggunakan metode .isnull().
df2.isnull().head(7)Mengingat sering kali lebih berguna untuk mengetahui berapa banyak data yang hilang, Anda dapat menggabungkan .isnull() dengan .sum() untuk menghitung jumlah null di setiap kolom.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Anda juga dapat melakukan penjumlahan ganda untuk mendapatkan total jumlah null dalam DataFrame.
df2.isnull().sum().sum()4Paket pandas menawarkan beberapa cara untuk mengurutkan, membuat subset, memfilter, dan mengisolasi data dalam DataFrame Anda. Di sini, kita akan melihat cara-cara yang paling umum.
Untuk mengurutkan DataFrame berdasarkan kolom tertentu:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderAnda dapat mengurutkan berdasarkan beberapa kolom:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Jika Anda memfilter atau mengurutkan DataFrame, indeks Anda mungkin tidak selaras. Gunakan .reset_index() untuk memperbaikinya:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnUntuk mengekstrak data berdasarkan suatu kondisi:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100Anda dapat mengisolasi satu kolom menggunakan tanda kurung siku [ ] dengan nama kolom di dalamnya. Outputnya adalah objek Series pandas. Series pandas adalah array satu dimensi yang berisi data dengan tipe apa pun, termasuk integer, float, string, boolean, objek python, dll. DataFrame terdiri dari banyak series yang berfungsi sebagai kolom.
df['Outcome']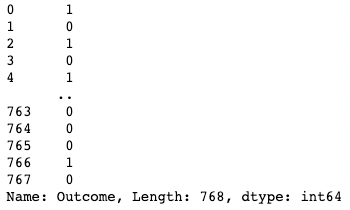
Mengisolasi satu kolom di pandas
Anda juga dapat memberikan list nama kolom di dalam tanda kurung siku untuk mengambil lebih dari satu kolom. Di sini, tanda kurung siku digunakan dalam dua cara berbeda. Kita menggunakan tanda kurung siku luar untuk menunjukkan subset dari DataFrame, dan tanda kurung siku dalam untuk membuat list.
df[['Pregnancies', 'Outcome']]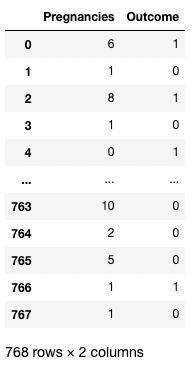
Mengisolasi dua kolom di pandas
Satu baris dapat diambil dengan memasukkan series boolean dengan satu nilai True. Pada contoh di bawah, baris kedua dengan index = 1 dikembalikan. Di sini, .index mengembalikan label baris DataFrame, dan perbandingan mengubahnya menjadi array satu dimensi bertipe boolean.
df[df.index==1]
Mengisolasi satu baris di pandas
Demikian pula, dua atau lebih baris dapat dikembalikan menggunakan metode .isin() alih-alih operator ==.
df[df.index.isin(range(2,10))]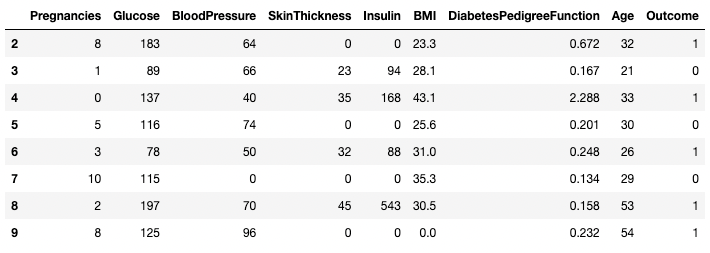
Mengisolasi baris tertentu di pandas
Anda dapat mengambil baris tertentu berdasarkan label atau kondisi menggunakan .loc[] dan .iloc[] ("location" dan "integer location"). .loc[] menggunakan label untuk menunjuk ke baris, kolom, atau sel, sedangkan .iloc[] menggunakan posisi numerik. Untuk memahami perbedaan keduanya, mari kita modifikasi indeks df2 yang dibuat sebelumnya.
df2.index = range(1,769)Contoh di bawah ini mengembalikan sebuah Series pandas, bukan DataFrame. Angka 1 merepresentasikan indeks baris (label), sedangkan 1 pada .iloc[] adalah posisi baris (baris pertama).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Anda juga dapat mengambil beberapa baris dengan memberikan rentang dalam tanda kurung siku.
df2.loc[100:110]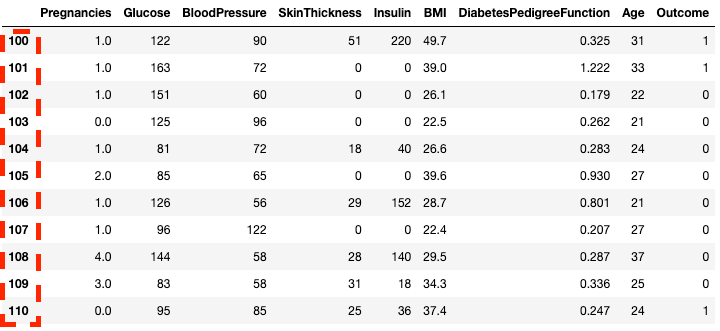
Mengisolasi baris di pandas dengan .loc[]
df2.iloc[100:110]![Isolating rows in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Mengisolasi baris di pandas dengan .iloc[]
Anda juga dapat membuat subset dengan .loc[] dan .iloc[] menggunakan list alih-alih rentang.
df2.loc[[100, 200, 300]]![Isolating rows using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Mengisolasi baris menggunakan list di pandas dengan .loc[]
df2.iloc[[100, 200, 300]]
Mengisolasi baris menggunakan list di pandas dengan .iloc[]
Anda juga dapat memilih kolom tertentu bersama baris. Di sinilah .iloc[] berbeda dari .loc[] – ia membutuhkan lokasi kolom, bukan label kolom.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Mengisolasi kolom di pandas dengan .loc[]
df2.iloc[100:110, :3]![Isolating columns using in pandas with .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Mengisolasi kolom dengan .iloc[]
Untuk alur kerja yang lebih cepat, Anda dapat memasukkan indeks awal suatu baris sebagai rentang.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Mengisolasi kolom dan baris di pandas dengan .loc[]
df2.iloc[760:, :3]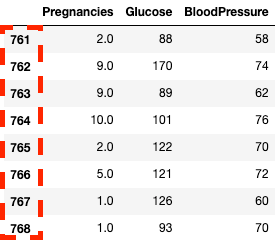
Mengisolasi kolom dan baris di pandas dengan .iloc[]
Anda dapat memperbarui/memodifikasi nilai tertentu dengan menggunakan operator penugasan =
df2.loc[df['Age']==81, ['Age']] = 80pandas memungkinkan Anda memfilter data berdasarkan kondisi pada nilai baris/kolom. Misalnya, kode di bawah memilih baris di mana Tekanan Darah tepat 122. Di sini, kita mengisolasi baris menggunakan tanda kurung [ ] seperti terlihat pada bagian sebelumnya. Namun, alih-alih memasukkan indeks baris atau nama kolom, kita memasukkan kondisi di mana kolom BloodPressure sama dengan 122. Kita menyatakan kondisi ini menggunakan df.BloodPressure == 122.
df[df.BloodPressure == 122]
Mengisolasi baris berdasarkan kondisi di pandas
Contoh di bawah mengambil semua baris di mana Outcome adalah 1. Di sini df.Outcome memilih kolom tersebut, df.Outcome == 1 mengembalikan Series nilai boolean yang menentukan Outcome mana yang sama dengan 1, lalu [] mengambil subset df di mana Series boolean tersebut bernilai True.
df[df.Outcome == 1]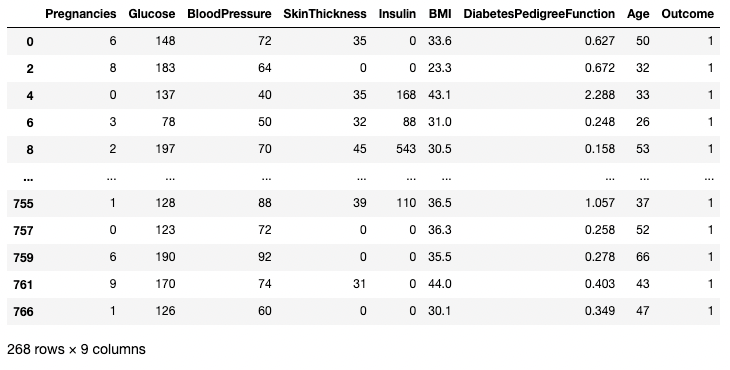
Mengisolasi baris berdasarkan kondisi di pandas
Anda dapat menggunakan operator > untuk membuat perbandingan. Kode di bawah mengambil Pregnancies, Glucose, dan BloodPressure untuk semua rekaman dengan BloodPressure lebih besar dari 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]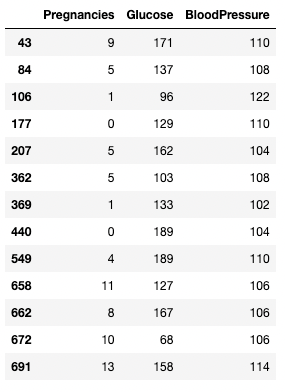
Mengisolasi baris dan kolom berdasarkan kondisi di pandas
Pembersihan data adalah salah satu tugas paling umum dalam data science. pandas memungkinkan Anda melakukan prapemrosesan data untuk berbagai penggunaan, termasuk namun tidak terbatas pada pelatihan model machine learning dan deep learning. Mari gunakan DataFrame df2 dari sebelumnya, yang memiliki empat nilai hilang, untuk menggambarkan beberapa kasus penggunaan pembersihan data. Sebagai pengingat, berikut cara melihat berapa banyak nilai hilang dalam DataFrame.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Salah satu cara menangani data hilang adalah dengan menghapusnya. Ini sangat berguna dalam kasus di mana Anda memiliki banyak data dan kehilangan sebagian kecil tidak akan berdampak pada analisis selanjutnya. Anda dapat menggunakan metode .dropna() seperti di bawah ini. Di sini, kami menyimpan hasil dari .dropna() ke dalam DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2Argumen axis memungkinkan Anda menentukan apakah Anda menghapus baris, atau kolom, dengan nilai hilang. Default axis menghapus baris yang berisi NaN. Gunakan axis = 1 untuk menghapus kolom dengan satu atau lebih nilai NaN. Perhatikan juga bagaimana kami menggunakan argumen inplace=True yang memungkinkan Anda melewatkan penyimpanan output .dropna() ke DataFrame baru.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()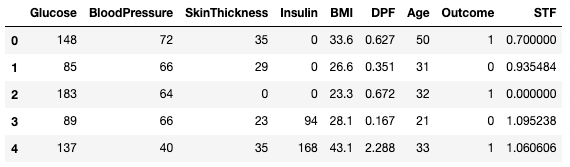
Menghapus data hilang di pandas
Anda juga dapat menghapus baik baris maupun kolom dengan nilai hilang dengan menyetel argumen how ke 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Alih-alih menghapus, mengganti nilai hilang dengan statistik ringkasan atau nilai tertentu (tergantung kasus penggunaan) mungkin cara terbaik. Misalnya, jika ada satu baris yang hilang dari kolom suhu yang menunjukkan suhu sepanjang hari dalam seminggu, mengganti nilai hilang tersebut dengan suhu rata-rata minggu itu mungkin lebih efektif daripada menghapus nilai sepenuhnya. Anda dapat mengganti data hilang dengan mean baris, atau kolom menggunakan kode di bawah ini.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Mari tambahkan beberapa duplikat ke data asli untuk mempelajari cara menghilangkan duplikat dalam DataFrame. Di sini, kami menggunakan metode .concat() untuk menggabungkan baris DataFrame df2 ke DataFrame df2, menambahkan duplikat sempurna dari setiap baris di df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Anda dapat menghapus semua baris duplikat (default) dari DataFrame menggunakan metode .drop_duplicates().
df3 = df3.drop_duplicates()
df3.shape(768, 9)Tugas pembersihan data yang umum adalah mengganti nama kolom. Dengan metode .rename(), Anda dapat menggunakan columns sebagai argumen untuk mengganti nama kolom tertentu. Kode di bawah ini menunjukkan kamus untuk memetakan nama kolom lama dan baru.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()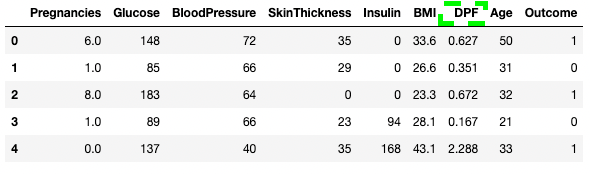
Mengganti nama kolom di pandas
Anda juga dapat langsung menetapkan nama kolom sebagai list ke DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()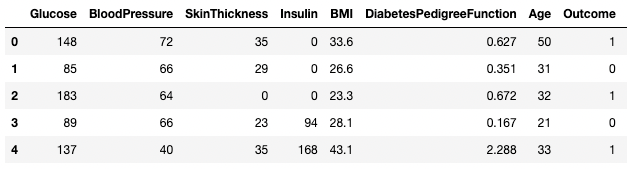
Mengganti nama kolom di pandas
Untuk lebih lanjut tentang pembersihan data, dan untuk alur kerja pembersihan data yang lebih mudah dan dapat diprediksi, lihat daftar periksa berikut, yang menyediakan serangkaian lengkap tugas pembersihan data umum.
Nilai utama pandas terletak pada fungsionalitas analisis data yang cepat. Pada bagian ini, kita akan fokus pada serangkaian teknik analisis yang dapat Anda gunakan di pandas.
Seperti yang Anda lihat sebelumnya, Anda dapat memperoleh mean dari setiap nilai kolom menggunakan metode .mean().
df.mean()
Mencetak mean kolom di pandas
Modus dapat dihitung serupa menggunakan metode .mode().
df.mode()
Mencetak modus kolom di pandas
Demikian pula, median setiap kolom dihitung dengan metode .median()
df.median()
Mencetak median kolom di pandas
pandas menyediakan komputasi yang cepat dan efisien dengan menggabungkan dua atau lebih kolom seperti variabel skalar. Kode di bawah ini membagi setiap nilai pada kolom Glucose dengan nilai yang sesuai pada kolom Insulin untuk menghitung kolom baru bernama Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Buat kolom baru dari kolom yang ada di pandas
Sering kali Anda akan bekerja dengan nilai kategorikal, dan Anda ingin menghitung jumlah observasi yang dimiliki setiap kategori dalam suatu kolom. Nilai kategori dapat dihitung menggunakan metode .value_counts(). Di sini, misalnya, kita menghitung jumlah observasi di mana Outcome adalah diabetes (1) dan jumlah observasi di mana Outcome non-diabetes (0).
df['Outcome'].value_counts()
Menggunakan .value_counts() di pandas
Menambahkan argumen normalize mengembalikan proporsi alih-alih jumlah absolut.
df['Outcome'].value_counts(normalize=True)
Menggunakan .value_counts() di pandas dengan normalisasi
Nonaktifkan pengurutan otomatis hasil menggunakan argumen sort (True secara default). Pengurutan default didasarkan pada jumlah dalam urutan menurun.
df['Outcome'].value_counts(sort=False)
Menggunakan .value_counts() di pandas dengan pengurutan
Anda juga dapat menerapkan .value_counts() pada objek DataFrame dan kolom tertentu di dalamnya, bukan hanya sebuah kolom. Di sini, misalnya, kita menerapkan value_counts() pada df dengan argumen subset, yang menerima list kolom.
df.value_counts(subset=['Pregnancies', 'Outcome'])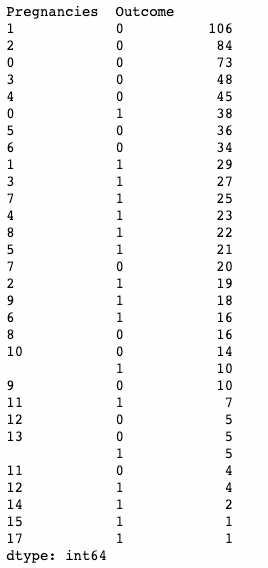
Menggunakan .value_counts() di pandas saat membuat subset kolom
pandas memungkinkan Anda mengagregasi nilai dengan mengelompokkannya berdasarkan nilai kolom tertentu. Anda dapat melakukannya dengan menggabungkan metode .groupby() dengan metode ringkasan pilihan Anda. Kode di bawah menampilkan mean dari masing-masing kolom numerik yang dikelompokkan berdasarkan Outcome.
df.groupby('Outcome').mean()
Mengagregasi data berdasarkan satu kolom di pandas
.groupby() memungkinkan pengelompokan berdasarkan lebih dari satu kolom dengan memberikan list nama kolom, seperti ditunjukkan di bawah.
df.groupby(['Pregnancies', 'Outcome']).mean()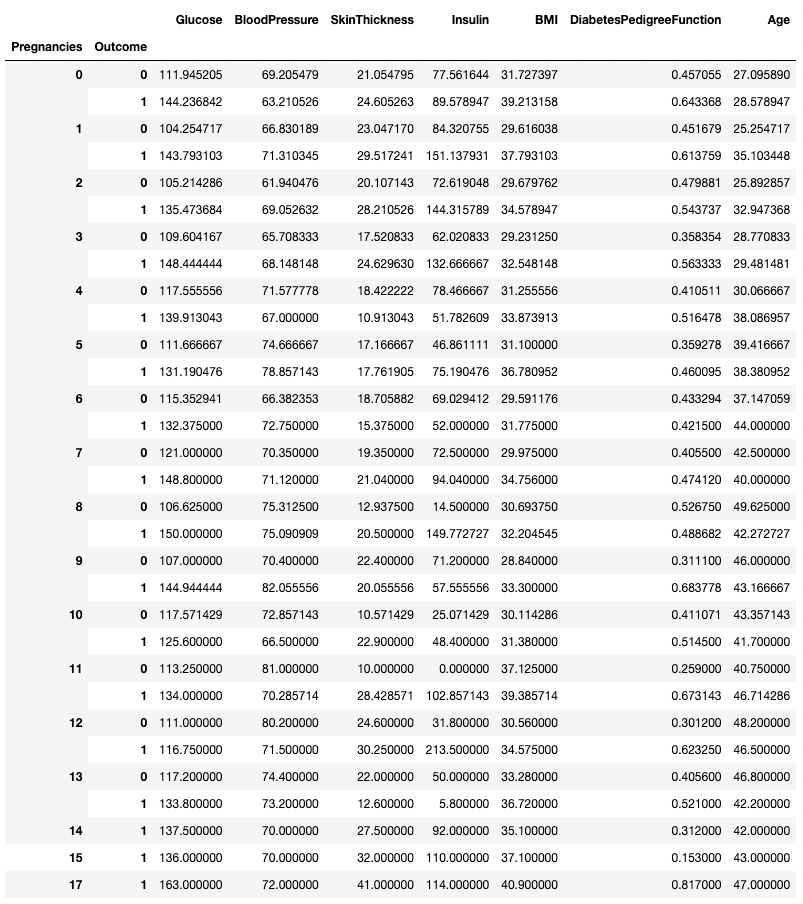
Mengagregasi data berdasarkan dua kolom di pandas
Metode ringkasan apa pun dapat digunakan bersama .groupby(), termasuk .min(), .max(), .mean(), .median(), .sum(), .mode(), dan lainnya.
pandas juga memungkinkan Anda menghitung statistik ringkasan sebagai tabel pivot. Ini memudahkan untuk menarik kesimpulan berdasarkan kombinasi variabel. Kode di bawah memilih baris sebagai nilai unik dari Pregnancies, nilai kolom adalah nilai unik dari Outcome, dan sel berisi nilai rata-rata BMI dalam grup yang sesuai.
Misalnya, untuk Pregnancies = 5 dan Outcome = 0, rata-rata BMI adalah 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc='mean')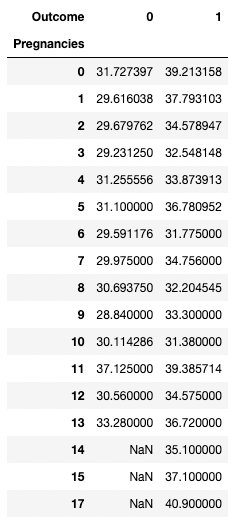
Mengagregasi data dengan pivot di pandas
pandas menyediakan pembungkus praktis untuk fungsi plotting Matplotlib agar memudahkan visualisasi DataFrame Anda. Di bawah ini, Anda akan melihat cara melakukan visualisasi data umum menggunakan pandas.
pandas memungkinkan Anda memetakan hubungan antar variabel menggunakan line plot. Di bawah ini adalah line plot dari BMI dan Glucose terhadap indeks baris.
df[['BMI', 'Glucose']].plot.line()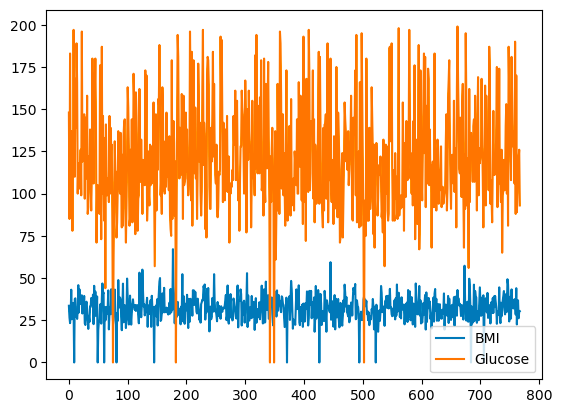
Line plot dasar dengan pandas
Anda dapat memilih warna dengan menggunakan argumen color.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})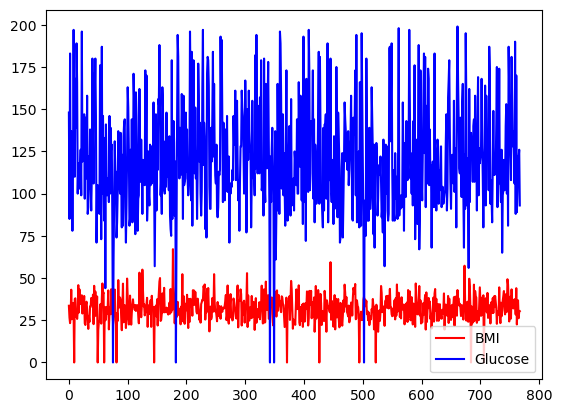
Line plot dasar dengan pandas, dengan warna kustom
Semua kolom df juga dapat diplot pada skala dan sumbu yang berbeda dengan menggunakan argumen subplots.
df.plot.line(subplots=True)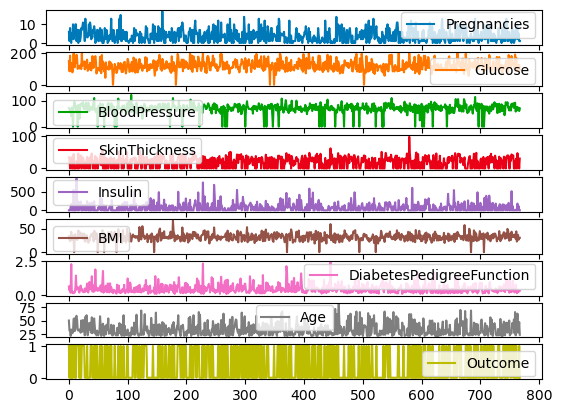
Subplot untuk line plot dengan pandas
Untuk kolom diskrit, Anda dapat menggunakan bar plot atas jumlah kategori untuk memvisualisasikan distribusinya. Variabel Outcome dengan nilai biner divisualisasikan di bawah.
df['Outcome'].value_counts().plot.bar()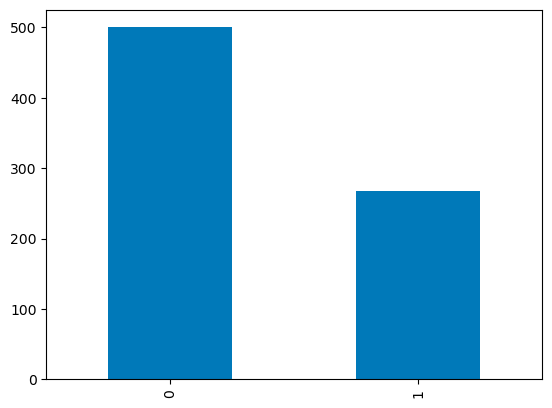
Bar plot di pandas
Distribusi kuartil variabel kontinu dapat divisualisasikan menggunakan boxplot. Kode di bawah memungkinkan Anda membuat boxplot dengan pandas.
df.boxplot(column=['BMI'], by='Outcome')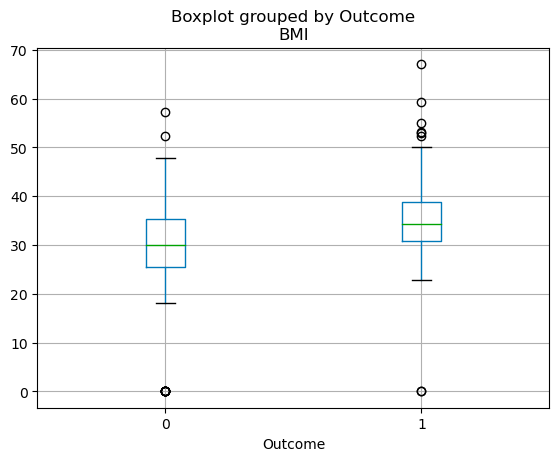
Box plot di pandas
Tutorial di atas hanya menggores permukaan dari apa yang mungkin dilakukan dengan pandas. Baik menganalisis data, memvisualisasikannya, memfilter, atau mengagregasinya, pandas menyediakan seperangkat fitur yang sangat kaya yang memungkinkan Anda mempercepat alur kerja data apa pun. Selain itu, dengan menggabungkan pandas dengan paket data science lainnya, Anda akan dapat membuat dasbor interaktif, membuat model prediktif menggunakan machine learning, mengotomatisasi alur kerja data, dan banyak lagi. Lihat sumber daya di bawah untuk mempercepat perjalanan belajar pandas Anda:
Lebih banyak kursus pandas
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt

