Python for Spreadsheet Users
BasicSkill Level
4 h
29.1K learners
Esegui e modifica il codice da questo tutorial online
Esegui codiceInstallare pandas è semplice: usa il comando pip install nel tuo terminale.
pip install pandasIn alternativa, puoi installarlo tramite conda:
conda install pandasDopo aver installato pandas, è buona pratica controllare la versione installata per assicurarti che tutto funzioni correttamente:
import pandas as pd
print(pd.__version__) # Prints the pandas versionQuesto conferma che pandas è installato correttamente e ti permette di verificare la compatibilità con altri pacchetti.
Per iniziare a lavorare con pandas, importa il pacchetto Python come mostrato sotto. L’alias più comune per pandas è pd.
import pandas as pdUsa read_csv() con il percorso del file CSV per leggere un file comma-separated values (consulta il nostro tutorial sull’importazione dei dati con read_csv() per maggiori dettagli).
df = pd.read_csv("diabetes.csv")Questa operazione carica il file CSV diabetes.csv e genera un oggetto DataFrame di pandas df. Nel corso di questo tutorial vedrai come manipolare questi DataFrame.
La lettura di file di testo è simile ai CSV. L’unica differenza è che devi specificare un separatore con l’argomento sep, come mostrato sotto. Il separatore indica il simbolo usato per separare le righe in un DataFrame. Virgola (sep = ","), spazio bianco (sep = "\s"), tabulazione (sep = "\t") e due punti (sep = ":") sono i più comuni. Qui \s rappresenta un singolo carattere di spazio.
df = pd.read_csv("diabetes.txt", sep="\s")Leggere file Excel (sia XLS che XLSX) è semplice con la funzione read_excel(), passando il percorso del file come input.
df = pd.read_excel('diabetes.xlsx')Puoi anche specificare altri argomenti, come header per indicare quale riga diventa l’intestazione del DataFrame. Il valore predefinito è 0, che indica la prima riga come intestazioni o nomi di colonna. Puoi anche passare i nomi delle colonne come lista tramite l’argomento names. L’argomento index_col (predefinito None) può essere usato se il file contiene un indice di riga.
Nota: In un DataFrame o Series di pandas, l’indice è un identificatore che punta alla posizione di una riga o di una colonna. In sintesi, l’indice etichetta la riga o la colonna di un DataFrame e ti permette di accedere a una riga o colonna specifica tramite il suo indice (lo vedrai più avanti). L’indice delle righe di un DataFrame può essere un intervallo (es. da 0 a 303), una serie temporale (date o timestamp), un identificatore univoco (es. employee_ID in una tabella employees) o altri tipi di dati. Per le colonne, di solito è una stringa (che indica il nome della colonna).
La lettura di file Excel con più fogli non è molto diversa. Devi solo specificare un argomento aggiuntivo, sheet_name, a cui puoi passare una stringa con il nome del foglio o un intero per la posizione del foglio (nota che Python usa l’indicizzazione da 0, quindi il primo foglio è accessibile con sheet_name = 0)
# Estrazione del secondo foglio poiché Python usa l'indicizzazione da 0
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)In modo analogo a read_csv(), puoi usare read_json() per file JSON passando il nome del file come argomento (per maggiori dettagli leggi questo tutorial su come importare dati JSON e HTML in pandas). Il codice seguente legge un file JSON dal disco e crea un DataFrame df.
df = pd.read_json("diabetes.json")Se vuoi saperne di più sull’importazione dei dati con pandas, dai un’occhiata a questo cheat sheet sull’importazione di vari tipi di file con Python.
Per caricare dati da un database relazionale, usa pd.read_sql() insieme a una connessione al database.
import sqlite3
# Stabilisce una connessione a un database SQLite
conn = sqlite3.connect("my_database.db")
# Legge i dati da una tabella
df = pd.read_sql("SELECT * FROM my_table", conn)Per dataset di grandi dimensioni, valuta l’uso di SQLAlchemy per ottimizzare le query.
Se i tuoi dati provengono da una web API, pandas può leggerli direttamente usando pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Se la risposta dell’API è paginata o in formato JSON annidato, potresti aver bisogno di ulteriore elaborazione usando json_normalize() da pandas.io.json.
Così come pandas può importare dati da vari formati, ti permette anche di esportarli in diversi formati. Questo capita soprattutto quando i dati vengono trasformati con pandas e devono essere salvati in locale. Di seguito come esportare DataFrame in vari formati.
Un DataFrame di pandas (qui usiamo df) si salva come file CSV con il metodo .to_csv(). Gli argomenti includono il nome file con percorso e index – dove index = True implica scrivere l’indice del DataFrame.
df.to_csv("diabetes_out.csv", index=False)Esporta un DataFrame in un file JSON richiamando il metodo .to_json().
df.to_json("diabetes_out.json")Nota: Un file JSON memorizza un oggetto tabellare come un insieme di coppie chiave-valore. Perciò potresti osservare intestazioni di colonna ripetute in un file JSON.
Come per la scrittura di DataFrame in file CSV, puoi chiamare .to_csv(). Le uniche differenze sono che il formato di output è .txt e devi specificare un separatore tramite l’argomento sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Richiama .to_excel() dall’oggetto DataFrame per salvarlo come file “.xls” o “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Dopo aver letto i dati tabellari come DataFrame, avrai bisogno di un’anteprima. Puoi visualizzare un piccolo campione del dataset o un riepilogo dei dati sotto forma di statistiche descrittive.
.head() e .tail()Puoi vedere le prime o le ultime righe di un DataFrame usando rispettivamente i metodi .head() o .tail(). Puoi specificare il numero di righe con l’argomento n (il valore predefinito è 5).
df.head()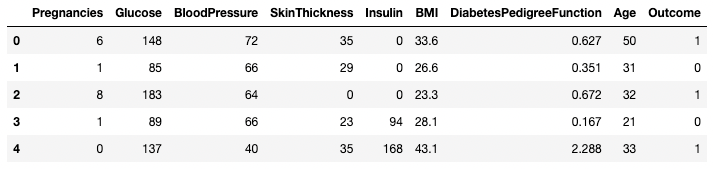
Prime cinque righe del DataFrame
df.tail(n = 10)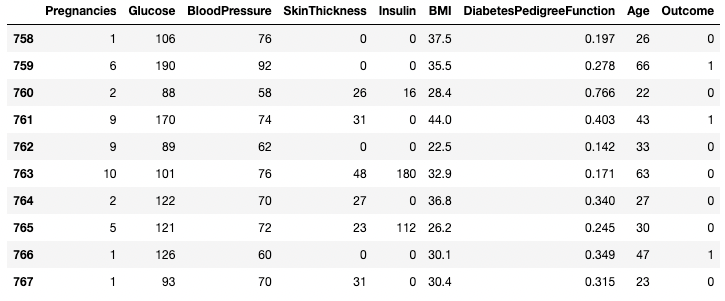
Prime 10 righe del DataFrame
.describe()Il metodo .describe() stampa le statistiche riassuntive di tutte le colonne numeriche, come conteggio, media, deviazione standard, range e quartili delle colonne numeriche.
df.describe()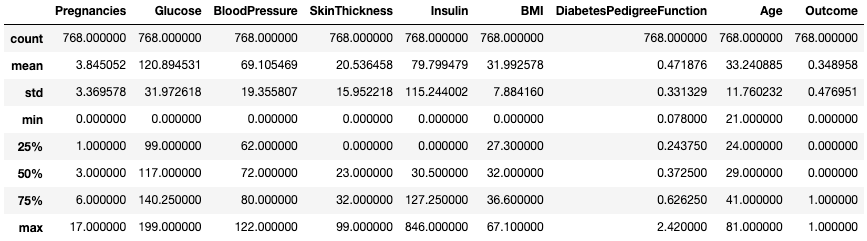
Ottieni statistiche descrittive con .describe()
Offre uno sguardo rapido alla scala, alla skewness e all’intervallo dei dati numerici.
Puoi anche modificare i quartili usando l’argomento percentiles. Qui, ad esempio, osserviamo i percentili 30%, 50% e 70% delle colonne numeriche nel DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])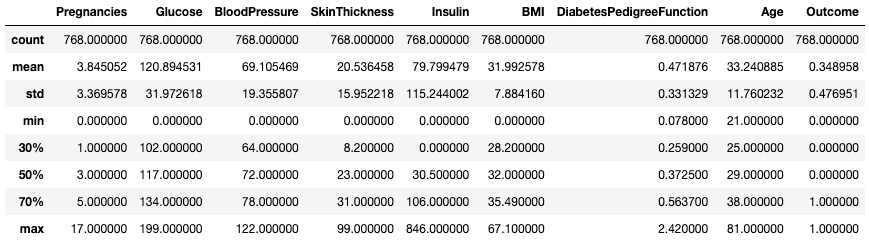
Ottieni statistiche descrittive con percentili specifici
Puoi anche isolare particolari tipi di dato nel riepilogo usando l’argomento include. Qui, ad esempio, stiamo riassumendo solo le colonne con tipo di dato integer.
df.describe(include=[int])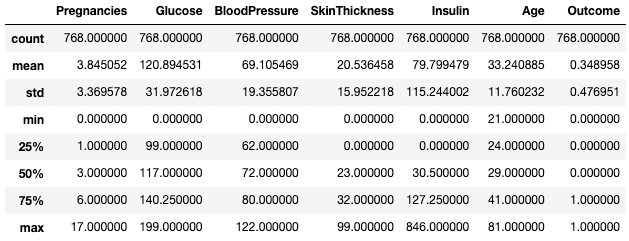
Ottieni statistiche descrittive solo per le colonne intere
Allo stesso modo, potresti voler escludere alcuni tipi di dato usando l’argomento exclude.
df.describe(exclude=[int])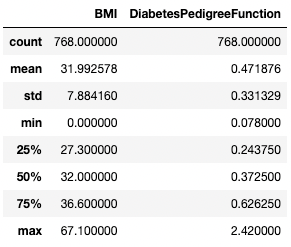
Ottieni statistiche descrittive solo per le colonne non intere
Spesso è più comodo visualizzare tali statistiche trasponendole con l’attributo .T.
df.describe().T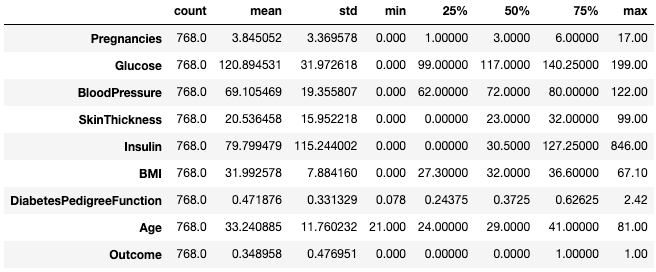
Trasponi le statistiche descrittive con .T
Per maggiori informazioni sulla descrizione dei DataFrame, consulta il seguente cheat sheet.
Il metodo .info() è un modo rapido per dare un’occhiata ai tipi di dato, ai valori mancanti e alla dimensione dei dati di un DataFrame. Qui impostiamo l’argomento show_counts su True, che mostra una vista del numero totale di valori non mancanti in ogni colonna. Impostiamo anche memory_usage su True, che mostra l’uso totale di memoria degli elementi del DataFrame. Quando verbose è impostato su True, stampa il riepilogo completo di .info().
df.info(show_counts=True, memory_usage=True, verbose=True)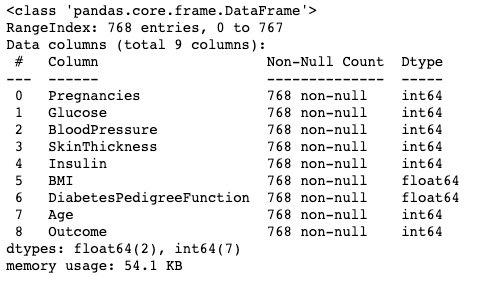
Il numero di righe e colonne di un DataFrame può essere identificato usando l’attributo .shape. Restituisce una tupla (righe, colonne) e può essere indicizzato per ottenere solo il numero di righe o solo il numero di colonne.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Richiamare l’attributo .columns di un DataFrame restituisce i nomi delle colonne sotto forma di oggetto Index. Ricorda: un indice di pandas è l’indirizzo/etichetta della riga o della colonna.
df.columns
Può essere convertito in una lista usando la funzione list().
list(df.columns)
Il DataFrame di esempio non ha valori mancanti. Aggiungiamone alcuni per rendere le cose più interessanti. Il metodo .copy() crea una copia del DataFrame originale. Questo serve a garantire che eventuali modifiche alla copia non si riflettano nel DataFrame originale. Usando .loc (ne parleremo più avanti), puoi impostare le righe dalla due alla cinque della colonna Pregnancies su valori NaN, che indicano valori mancanti.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)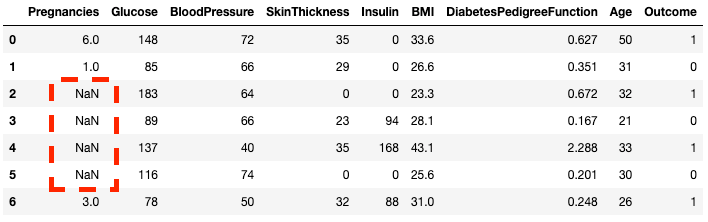
Come vedi, ora le righe da 2 a 5 sono NaN
Puoi verificare se ciascun elemento in un DataFrame è mancante usando il metodo .isnull().
df2.isnull().head(7)Dato che spesso è più utile sapere quanti valori mancanti hai, puoi combinare .isnull() con .sum() per contare il numero di null in ogni colonna.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Puoi anche fare una doppia somma per ottenere il numero totale di null nel DataFrame.
df2.isnull().sum().sum()4Il pacchetto pandas offre diversi modi per ordinare, suddividere, filtrare e isolare i dati nei tuoi DataFrame. Qui vedremo i modi più comuni.
Per ordinare un DataFrame in base a una colonna specifica:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderPuoi ordinare per più colonne:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Se filtri o ordini un DataFrame, l’indice potrebbe non essere più allineato. Usa .reset_index() per sistemarlo:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnPer estrarre dati in base a una condizione:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100Puoi isolare una singola colonna usando le parentesi quadre [ ] con il nome della colonna al loro interno. L’output è un oggetto Series di pandas. Una Series di pandas è un array monodimensionale che contiene dati di qualsiasi tipo, inclusi interi, float, stringhe, booleani, oggetti Python, ecc. Un DataFrame è composto da molte Series che fungono da colonne.
df['Outcome']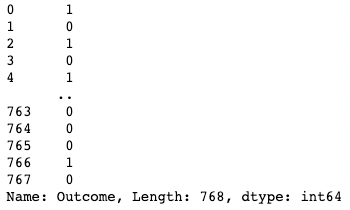
Isolare una colonna in pandas
Puoi anche fornire una lista di nomi di colonna all’interno delle parentesi quadre per recuperare più di una colonna. Qui le parentesi quadre sono usate in due modi diversi. Usiamo le parentesi esterne per indicare un sottoinsieme di un DataFrame e quelle interne per creare una lista.
df[['Pregnancies', 'Outcome']]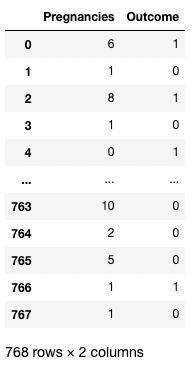
Isolare due colonne in pandas
Una singola riga può essere recuperata passando una Series booleana con un solo valore True. Nell’esempio sotto, viene restituita la seconda riga con index = 1. Qui .index restituisce le etichette delle righe del DataFrame e il confronto le trasforma in un array monodimensionale di booleani.
df[df.index==1]
Isolare una riga in pandas
Allo stesso modo, due o più righe possono essere restituite usando il metodo .isin() invece dell’operatore ==.
df[df.index.isin(range(2,10))]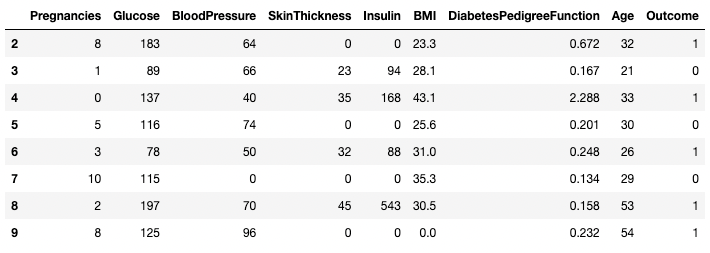
Isolare righe specifiche in pandas
Puoi recuperare righe specifiche tramite etichette o condizioni usando .loc[] e .iloc[] ("location" e "integer location"). .loc[] usa un’etichetta per puntare a una riga, colonna o cella, mentre .iloc[] usa la posizione numerica. Per capire la differenza tra i due, modifichiamo l’indice di df2 creato in precedenza.
df2.index = range(1,769)L’esempio sotto restituisce una Series di pandas invece di un DataFrame. Il 1 rappresenta l’indice (etichetta) della riga, mentre il 1 in .iloc[] è la posizione della riga (prima riga).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Puoi anche recuperare più righe fornendo un intervallo tra parentesi quadre.
df2.loc[100:110]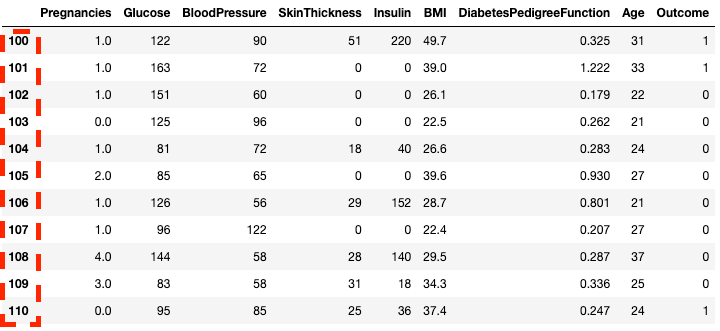
Isolare righe in pandas con .loc[]
df2.iloc[100:110]![Isolating rows in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Isolare righe in pandas con .iloc[]
Puoi anche fare subset con .loc[] e .iloc[] usando una lista invece di un intervallo.
df2.loc[[100, 200, 300]]![Isolating rows using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Isolare righe usando una lista con .loc[]
df2.iloc[[100, 200, 300]]
Isolare righe usando una lista con .iloc[]
Puoi anche selezionare colonne specifiche insieme alle righe. Qui .iloc[] differisce da .loc[]: richiede la posizione delle colonne e non le etichette.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Isolare colonne in pandas con .loc[]
df2.iloc[100:110, :3]![Isolating columns using in pandas with .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Isolare colonne con .iloc[]
Per flussi di lavoro più rapidi, puoi passare l’indice di partenza di una riga come intervallo.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Isolare colonne e righe in pandas con .loc[]
df2.iloc[760:, :3]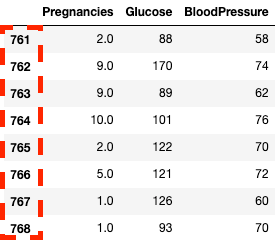
Isolare colonne e righe in pandas con .iloc[]
Puoi aggiornare/modificare determinati valori usando l’operatore di assegnazione =
df2.loc[df['Age']==81, ['Age']] = 80pandas ti permette di filtrare i dati in base a condizioni sui valori di righe/colonne. Ad esempio, il codice sotto seleziona la riga in cui la pressione sanguigna è esattamente 122. Qui stiamo isolando righe usando le parentesi [ ] come visto nelle sezioni precedenti. Tuttavia, invece di inserire indici di riga o nomi di colonna, inseriamo una condizione in cui la colonna BloodPressure è uguale a 122. Indichiamo questa condizione con df.BloodPressure == 122.
df[df.BloodPressure == 122]
Isolare righe in base a una condizione in pandas
L’esempio sottostante recupera tutte le righe in cui Outcome è 1. Qui df.Outcome seleziona quella colonna, df.Outcome == 1 restituisce una Series di valori booleani che determinano quali Outcome sono uguali a 1, quindi [] prende un sottoinsieme di df in cui quella Series booleana è True.
df[df.Outcome == 1]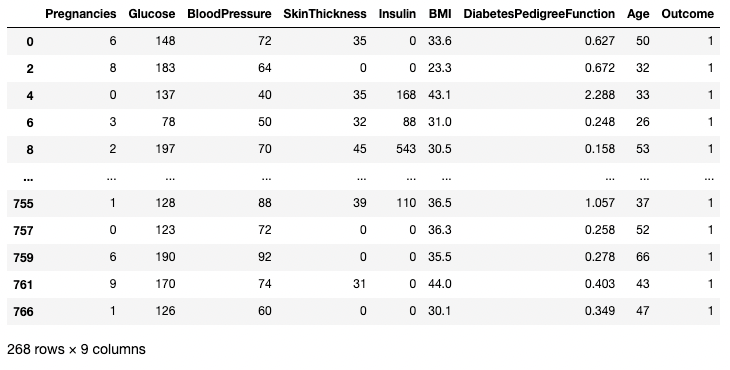
Isolare righe in base a una condizione in pandas
Puoi usare un operatore > per confronti. Il codice seguente recupera Pregnancies, Glucose e BloodPressure per tutti i record con BloodPressure maggiore di 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]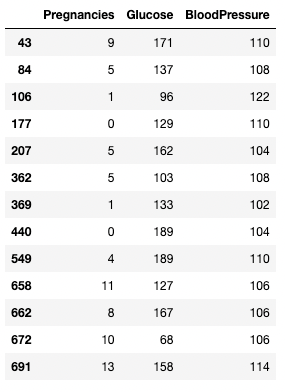
Isolare righe e colonne in base a una condizione in pandas
La pulizia dei dati è una delle attività più comuni in data science. pandas ti permette di preprocessare i dati per qualsiasi uso, incluso (ma non solo) l’addestramento di modelli di machine learning e deep learning. Usiamo il DataFrame df2 di prima, con quattro valori mancanti, per illustrare alcuni casi d’uso di pulizia dati. Come promemoria, ecco come vedere quanti valori mancanti ci sono in un DataFrame.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Un modo per gestire i dati mancanti è eliminarli. Questo è particolarmente utile quando hai molti dati e perdere una piccola porzione non influirà sull’analisi a valle. Puoi usare il metodo .dropna() come mostrato sotto. Qui salviamo i risultati di .dropna() in un DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2L’argomento axis ti permette di specificare se stai eliminando righe o colonne con valori mancanti. L’axis predefinito rimuove le righe contenenti NaN. Usa axis = 1 per rimuovere le colonne con uno o più valori NaN. Nota anche come usiamo l’argomento inplace=True, che ti permette di evitare di salvare l’output di .dropna() in un nuovo DataFrame.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()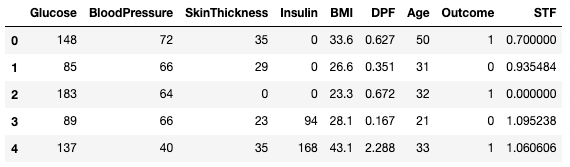
Eliminare dati mancanti in pandas
Puoi anche eliminare sia righe sia colonne con valori mancanti impostando l’argomento how su 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Invece di eliminare, sostituire i valori mancanti con una statistica riassuntiva o un valore specifico (a seconda del caso d’uso) può essere la scelta migliore. Ad esempio, se manca un valore nella colonna delle temperature che rappresenta le temperature durante i giorni della settimana, sostituire quel valore con la temperatura media della settimana può essere più efficace che eliminarlo del tutto. Puoi sostituire i dati mancanti con la media di riga o di colonna usando il codice seguente.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Aggiungiamo alcuni duplicati ai dati originali per imparare come eliminarli da un DataFrame. Qui usiamo il metodo .concat() per concatenare le righe di df2 a df2, aggiungendo duplicati perfetti di ogni riga in df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Puoi rimuovere tutte le righe duplicate (impostazione predefinita) dal DataFrame usando il metodo .drop_duplicates().
df3 = df3.drop_duplicates()
df3.shape(768, 9)Un’attività di pulizia dati comune è rinominare le colonne. Con il metodo .rename() puoi usare columns come argomento per rinominare colonne specifiche. Il codice seguente mostra il dizionario per mappare vecchi e nuovi nomi.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()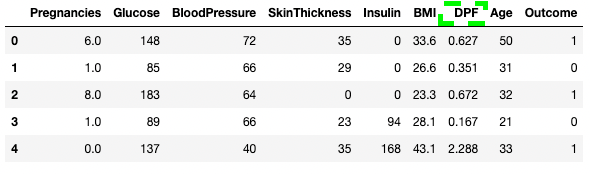
Rinominare colonne in pandas
Puoi anche assegnare direttamente i nomi delle colonne come lista al DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()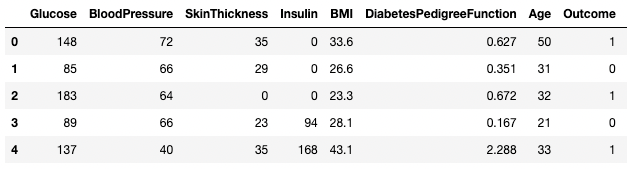
Rinominare colonne in pandas
Per approfondire la pulizia dei dati, e per flussi di lavoro più semplici e prevedibili, consulta la seguente checklist, che fornisce un set completo di comuni attività di data cleaning.
Il principale valore aggiunto di pandas risiede nelle sue funzionalità per un’analisi rapida dei dati. In questa sezione ci concentreremo su un insieme di tecniche di analisi utilizzabili in pandas.
Come hai visto in precedenza, puoi ottenere la media di ciascuna colonna con il metodo .mean().
df.mean()
Stampa della media delle colonne in pandas
La moda può essere calcolata in modo analogo con il metodo .mode().
df.mode()
Stampa della moda delle colonne in pandas
Allo stesso modo, la mediana di ciascuna colonna si calcola con il metodo .median()
df.median()
Stampa della mediana delle colonne in pandas
pandas fornisce calcoli veloci ed efficienti combinando due o più colonne come variabili scalari. Il codice seguente divide ciascun valore nella colonna Glucose per il corrispondente valore nella colonna Insulin per calcolare una nuova colonna chiamata Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Creare una nuova colonna da colonne esistenti in pandas
Spesso lavorerai con valori categorici e vorrai contare il numero di osservazioni che ogni categoria ha in una colonna. I valori di categoria possono essere contati con il metodo .value_counts(). Qui, ad esempio, contiamo il numero di osservazioni in cui l’Outcome è diabetico (1) e il numero di osservazioni in cui l’Outcome è non diabetico (0).
df['Outcome'].value_counts()
Usare .value_counts() in pandas
Aggiungendo l’argomento normalize ottieni proporzioni invece di conteggi assoluti.
df['Outcome'].value_counts(normalize=True)
Usare .value_counts() in pandas con normalizzazione
Disattiva l’ordinamento automatico dei risultati usando l’argomento sort (predefinito True). L’ordinamento predefinito è basato sui conteggi in ordine decrescente.
df['Outcome'].value_counts(sort=False)
Usare .value_counts() in pandas con ordinamento
Puoi anche applicare .value_counts() a un oggetto DataFrame e a colonne specifiche al suo interno, non solo a una singola colonna. Qui, ad esempio, applichiamo value_counts() a df con l’argomento subset, che accetta una lista di colonne.
df.value_counts(subset=['Pregnancies', 'Outcome'])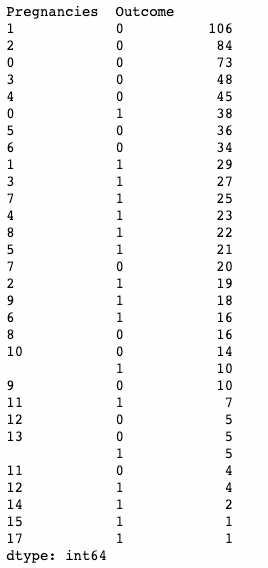
Usare .value_counts() in pandas mentre si fa subset delle colonne
pandas ti permette di aggregare i valori raggruppandoli per valori specifici di colonna. Puoi farlo combinando il metodo .groupby() con un metodo riassuntivo a tua scelta. Il codice sotto mostra la media di ciascuna delle colonne numeriche raggruppate per Outcome.
df.groupby('Outcome').mean()
Aggregare i dati per una colonna in pandas
.groupby() consente il raggruppamento per più di una colonna passando una lista di nomi di colonna, come mostrato sotto.
df.groupby(['Pregnancies', 'Outcome']).mean()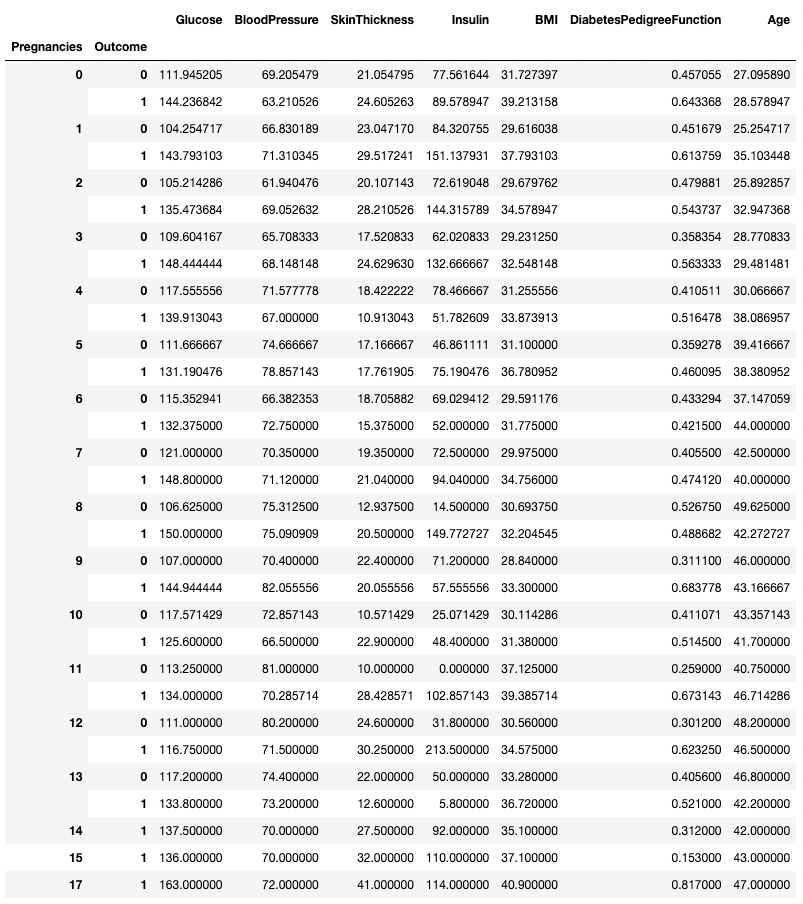
Aggregare i dati per due colonne in pandas
Qualsiasi metodo riassuntivo può essere usato insieme a .groupby(), tra cui .min(), .max(), .mean(), .median(), .sum(), .mode() e altri.
pandas consente anche di calcolare statistiche riassuntive come tabelle pivot. Questo rende più facile trarre conclusioni sulla base di una combinazione di variabili. Il codice seguente imposta le righe come valori unici di Pregnancies, le colonne come valori unici di Outcome e le celle come valore medio di BMI nel gruppo corrispondente.
Ad esempio, per Pregnancies = 5 e Outcome = 0, il BMI medio risulta 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc='mean')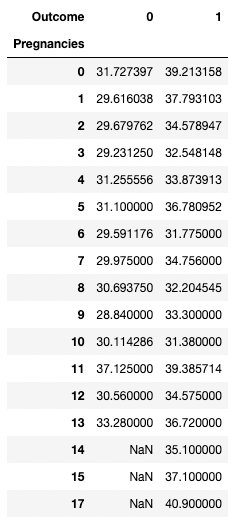
Aggregare i dati con il pivoting in pandas
pandas fornisce dei wrapper di comodo alle funzioni di plotting di Matplotlib per facilitare la visualizzazione dei tuoi DataFrame. Di seguito vedrai come realizzare le visualizzazioni più comuni con pandas.
pandas ti permette di tracciare le relazioni tra variabili usando i grafici a linee. Di seguito un line plot di BMI e Glucose rispetto all’indice di riga.
df[['BMI', 'Glucose']].plot.line()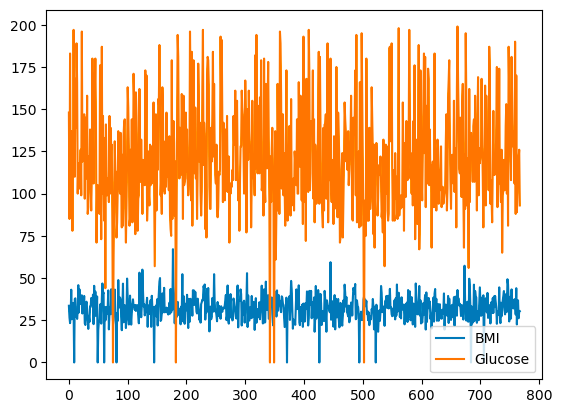
Line plot di base con pandas
Puoi scegliere i colori usando l’argomento color.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})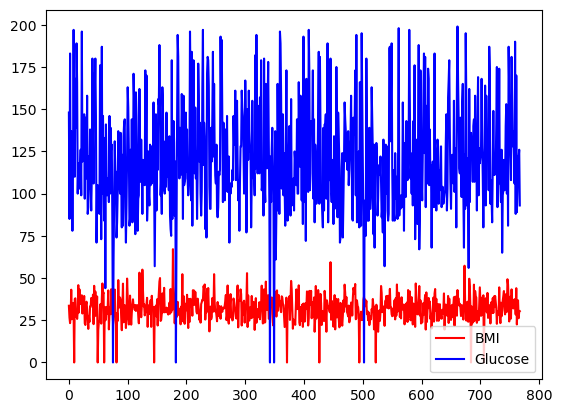
Line plot di base con pandas, con colori personalizzati
Tutte le colonne di df possono anche essere tracciate su scale e assi diversi usando l’argomento subplots.
df.plot.line(subplots=True)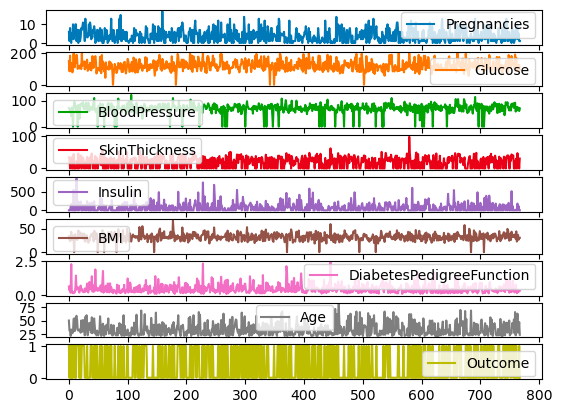
Sottotrame per line plot con pandas
Per colonne discrete, puoi usare un grafico a barre sui conteggi delle categorie per visualizzarne la distribuzione. La variabile Outcome con valori binari è visualizzata sotto.
df['Outcome'].value_counts().plot.bar()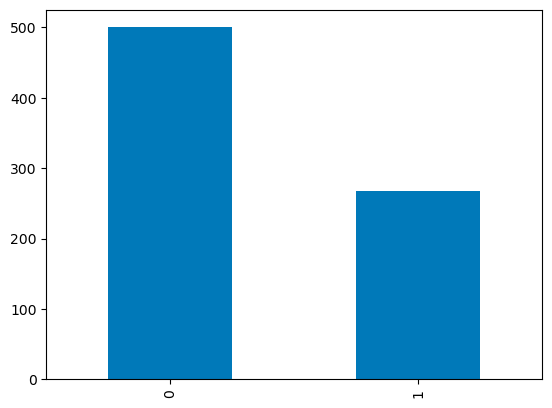
Bar plot in pandas
La distribuzione in quartili delle variabili continue può essere visualizzata con un box plot. Il codice seguente ti permette di creare un box plot con pandas.
df.boxplot(column=['BMI'], by='Outcome')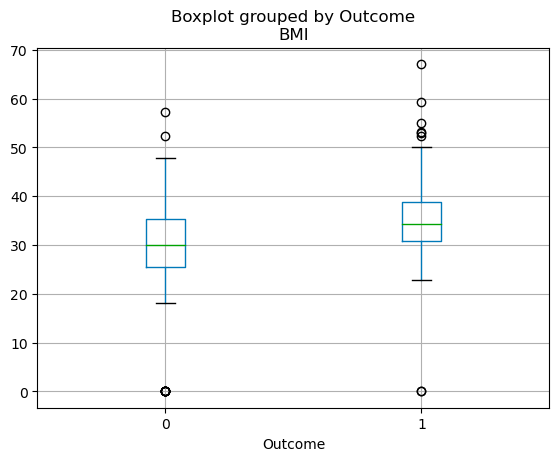
Box plot in pandas
Il tutorial sopra tocca solo la superficie di ciò che è possibile con pandas. Che si tratti di analizzare, visualizzare, filtrare o aggregare dati, pandas offre un set di funzionalità incredibilmente ricco che accelera qualsiasi flusso di lavoro sui dati. Inoltre, combinando pandas con altri pacchetti di data science, potrai creare dashboard interattive, modelli predittivi con il machine learning, automatizzare flussi di lavoro sui dati e altro ancora. Dai un’occhiata alle risorse qui sotto per accelerare il tuo percorso di apprendimento su pandas:
Altri corsi su pandas
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min


