Python dành cho người dùng bảng tính
BasicSkill Level
4 giờ
29.1K learners
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãCài đặt pandas rất đơn giản; chỉ cần dùng lệnh pip install trong terminal của bạn.
pip install pandasNgoài ra, bạn có thể cài đặt qua conda:
conda install pandasSau khi cài pandas, nên kiểm tra phiên bản đã cài để đảm bảo mọi thứ hoạt động đúng:
import pandas as pd
print(pd.__version__) # Prints the pandas versionĐiều này xác nhận pandas được cài đặt đúng và giúp bạn kiểm tra khả năng tương thích với các gói khác.
Để bắt đầu làm việc với pandas, hãy nhập gói Python pandas như dưới đây. Khi import, bí danh phổ biến nhất cho pandas là pd.
import pandas as pdDùng read_csv() với đường dẫn đến tệp CSV để đọc tệp giá trị phân tách bằng dấu phẩy (xem hướng dẫn nhập dữ liệu với read_csv() để biết chi tiết).
df = pd.read_csv("diabetes.csv")Thao tác đọc này tải tệp diabetes.csv để tạo một đối tượng DataFrame của pandas là df. Xuyên suốt hướng dẫn này, bạn sẽ thấy cách thao tác những đối tượng DataFrame như vậy.
Đọc tệp văn bản tương tự như tệp CSV. Khác biệt là bạn cần chỉ định ký tự phân tách bằng tham số sep như dưới đây. Tham số separator ám chỉ ký hiệu dùng để phân tách các trường trong DataFrame. Dấu phẩy (sep = ","), khoảng trắng (sep = "\s"), tab (sep = "\t") và dấu hai chấm (sep = ":") là những separator thường dùng. Ở đây \s đại diện cho một ký tự khoảng trắng đơn.
df = pd.read_csv("diabetes.txt", sep="\s")Đọc tệp Excel (cả XLS và XLSX) rất dễ với hàm read_excel(), dùng đường dẫn tệp làm đầu vào.
df = pd.read_excel('diabetes.xlsx')Bạn cũng có thể chỉ định các tham số khác, như header để xác định hàng nào là tiêu đề của DataFrame. Mặc định là 0, nghĩa là hàng đầu tiên là tiêu đề hoặc tên cột. Bạn cũng có thể chỉ định tên cột dưới dạng danh sách ở tham số names. Tham số index_col (mặc định None) dùng nếu tệp có chứa chỉ mục hàng.
Lưu ý: Trong một DataFrame hoặc Series của pandas, index là định danh trỏ tới vị trí của một hàng hoặc cột. Nói ngắn gọn, index gán nhãn cho hàng hoặc cột của DataFrame và cho phép bạn truy cập một hàng hoặc cột cụ thể bằng index của nó (bạn sẽ thấy ở phần sau). Chỉ mục hàng của DataFrame có thể là một dải (vd. 0 đến 303), chuỗi thời gian (ngày hoặc timestamp), định danh duy nhất (vd. employee_ID trong bảng employees), hoặc kiểu dữ liệu khác. Với cột, thường là chuỗi (biểu thị tên cột).
Đọc tệp Excel có nhiều sheet cũng tương tự. Bạn chỉ cần thêm tham số sheet_name, có thể truyền tên sheet dạng chuỗi hoặc vị trí sheet dạng số (lưu ý Python dùng đánh chỉ mục từ 0, sheet đầu tiên truy cập bằng sheet_name = 0)
# Trích sheet thứ hai vì Python dùng đánh chỉ mục từ 0
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)Tương tự hàm read_csv(), bạn có thể dùng read_json() cho tệp JSON với tên tệp JSON làm tham số (để biết thêm, đọc hướng dẫn này về nhập dữ liệu JSON và HTML vào pandas). Đoạn mã dưới đây đọc một tệp JSON từ đĩa và tạo đối tượng DataFrame df.
df = pd.read_json("diabetes.json")Nếu muốn tìm hiểu thêm về nhập dữ liệu với pandas, hãy xem cheat sheet này về nhập các loại tệp khác nhau với Python.
Để tải dữ liệu từ cơ sở dữ liệu quan hệ, dùng pd.read_sql() cùng với một kết nối cơ sở dữ liệu.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Với tập dữ liệu lớn, cân nhắc dùng SQLAlchemy để tối ưu truy vấn.
Nếu dữ liệu của bạn đến từ web API, pandas có thể đọc trực tiếp bằng pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Nếu phản hồi API được phân trang hoặc ở dạng JSON lồng nhau, bạn có thể cần xử lý thêm bằng json_normalize() từ pandas.io.json.
Cũng như có thể nhập dữ liệu từ nhiều loại tệp, pandas cho phép bạn xuất dữ liệu sang nhiều định dạng. Điều này đặc biệt hữu ích khi dữ liệu đã được biến đổi bằng pandas và cần lưu cục bộ trên máy. Dưới đây là cách xuất DataFrame của pandas sang các định dạng khác nhau.
Một DataFrame của pandas (ở đây là df) được lưu thành tệp CSV bằng phương thức .to_csv(). Các tham số gồm tên tệp kèm đường dẫn và index – trong đó index = True nghĩa là ghi cả chỉ mục của DataFrame.
df.to_csv("diabetes_out.csv", index=False)Xuất đối tượng DataFrame ra tệp JSON bằng cách gọi phương thức .to_json().
df.to_json("diabetes_out.json")Lưu ý: Tệp JSON lưu một đối tượng dạng bảng như DataFrame dưới dạng cặp khóa-giá trị. Do đó bạn sẽ thấy tiêu đề cột lặp lại trong tệp JSON.
Tương tự việc ghi DataFrame ra tệp CSV, bạn có thể gọi .to_csv(). Khác biệt là định dạng tệp đầu ra là .txt, và bạn cần chỉ định ký tự phân tách bằng tham số sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Gọi .to_excel() từ đối tượng DataFrame để lưu thành tệp “.xls” hoặc “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Sau khi đọc dữ liệu dạng bảng thành DataFrame, bạn sẽ cần lướt qua dữ liệu. Bạn có thể xem một mẫu nhỏ hoặc xem tóm tắt dữ liệu dưới dạng thống kê mô tả.
.head() và .tail()Bạn có thể xem vài hàng đầu hoặc vài hàng cuối của DataFrame bằng các phương thức .head() hoặc .tail(). Bạn có thể chỉ định số hàng qua tham số n (mặc định là 5).
df.head()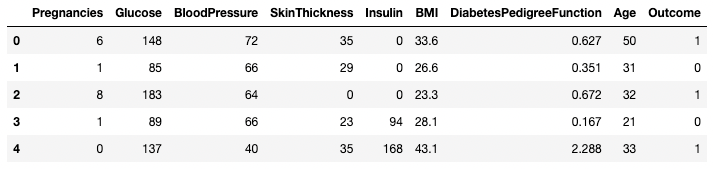
Năm hàng đầu tiên của DataFrame
df.tail(n = 10)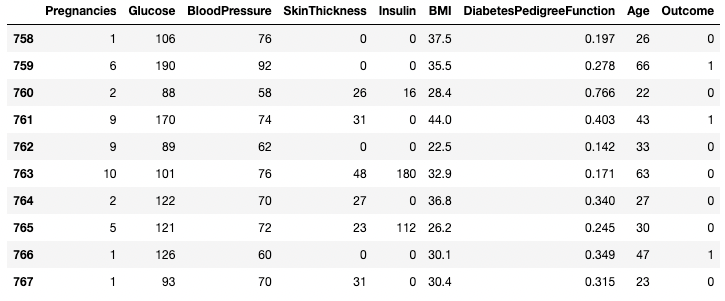
10 hàng đầu tiên của DataFrame
.describe()Phương thức .describe() in ra các thống kê tóm tắt của mọi cột số, như số lượng, trung bình, độ lệch chuẩn, khoảng và các tứ phân vị của các cột số.
df.describe()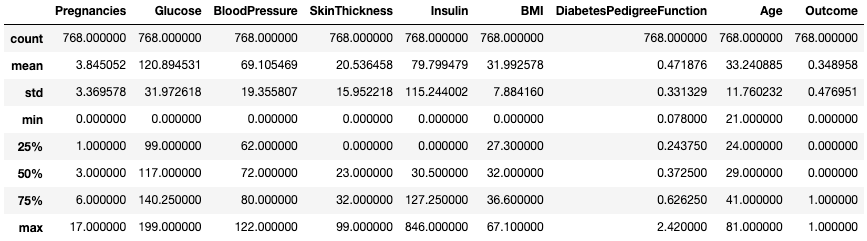
Lấy thống kê tóm tắt với .describe()
Nó cho cái nhìn nhanh về độ lớn, độ lệch và khoảng của dữ liệu số.
Bạn cũng có thể điều chỉnh các tứ phân vị bằng tham số percentiles. Ở đây, ví dụ, chúng ta xem các bách phân vị 30%, 50% và 70% của các cột số trong DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])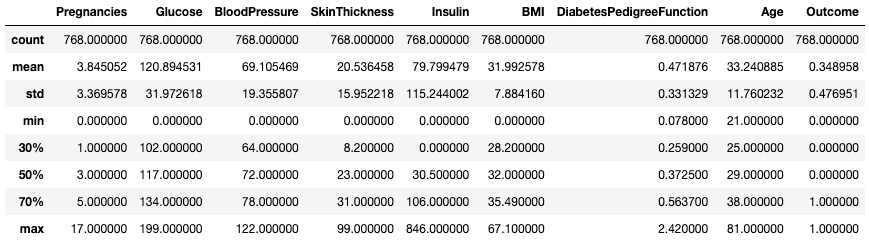
Lấy thống kê tóm tắt với các bách phân vị cụ thể
Bạn cũng có thể chỉ lấy các kiểu dữ liệu cụ thể trong đầu ra tóm tắt bằng tham số include. Ở đây, ví dụ, chúng ta chỉ tóm tắt các cột có kiểu dữ liệu integer.
df.describe(include=[int])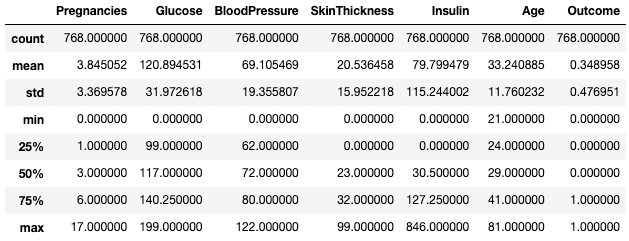
Lấy thống kê tóm tắt chỉ cho các cột số nguyên
Tương tự, bạn có thể loại trừ một số kiểu dữ liệu bằng tham số exclude.
df.describe(exclude=[int])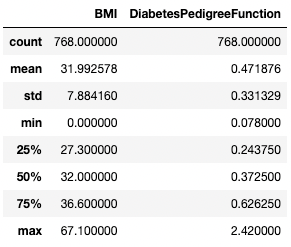
Lấy thống kê tóm tắt chỉ cho các cột không phải số nguyên
Thường thì người thực hành thấy dễ đọc hơn khi chuyển vị các thống kê này bằng thuộc tính .T.
df.describe().T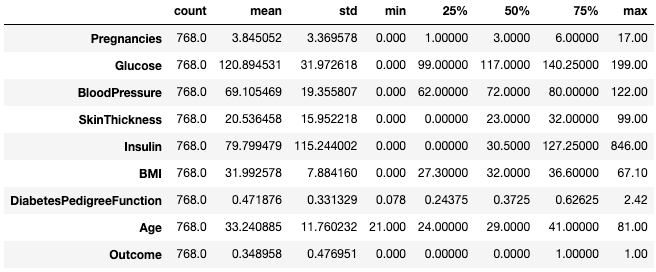
Chuyển vị thống kê tóm tắt với .T
Để biết thêm về mô tả DataFrame, hãy xem cheat sheet sau.
Phương thức .info() là cách nhanh để xem kiểu dữ liệu, giá trị thiếu và kích thước dữ liệu của một DataFrame. Ở đây, chúng ta đặt tham số show_counts là True, cho biết số lượng giá trị không thiếu ở mỗi cột. Chúng ta cũng đặt memory_usage là True, hiển thị tổng mức sử dụng bộ nhớ của các phần tử DataFrame. Khi verbose là True, nó in toàn bộ tóm tắt từ .info().
df.info(show_counts=True, memory_usage=True, verbose=True)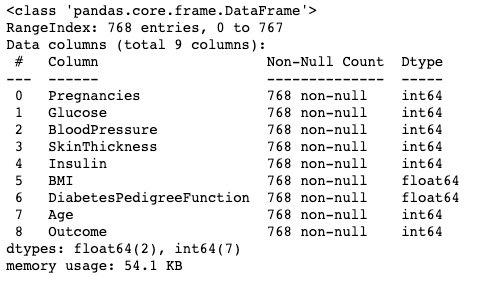
Số hàng và cột của một DataFrame có thể được xác định bằng thuộc tính .shape của DataFrame. Nó trả về một bộ giá trị (hàng, cột) và có thể đánh chỉ mục để chỉ lấy số hàng hoặc số cột.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Gọi thuộc tính .columns của một đối tượng DataFrame trả về tên cột dưới dạng đối tượng Index. Nhắc lại, index trong pandas là địa chỉ/nhãn của hàng hoặc cột.
df.columns
Có thể chuyển nó thành danh sách bằng hàm list().
list(df.columns)
DataFrame mẫu không có giá trị thiếu. Hãy thêm một vài giá trị thiếu để thú vị hơn. Phương thức .copy() tạo một bản sao của DataFrame gốc. Làm vậy để đảm bảo mọi thay đổi trên bản sao không ảnh hưởng đến DataFrame gốc. Dùng .loc (sẽ bàn sau), bạn có thể đặt các hàng từ hai đến năm của cột Pregnancies thành giá trị NaN, biểu thị giá trị thiếu.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)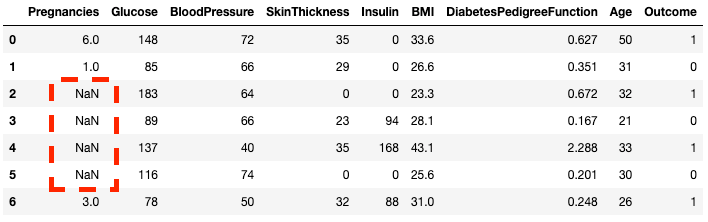
Như bạn thấy, giờ hàng 2 đến 5 là NaN
Bạn có thể kiểm tra từng phần tử trong DataFrame có bị thiếu không bằng phương thức .isnull().
df2.isnull().head(7)Vì thường hữu ích hơn khi biết có bao nhiêu dữ liệu thiếu, bạn có thể kết hợp .isnull() với .sum() để đếm số null ở mỗi cột.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Bạn cũng có thể cộng hai lần để lấy tổng số null trong toàn bộ DataFrame.
df2.isnull().sum().sum()4Gói pandas cung cấp nhiều cách để sắp xếp, lấy tập con, lọc và tách dữ liệu trong DataFrame. Ở đây, chúng ta sẽ xem những cách phổ biến nhất.
Để sắp xếp DataFrame theo một cột cụ thể:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderBạn có thể sắp xếp theo nhiều cột:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Nếu bạn lọc hoặc sắp xếp DataFrame, chỉ mục có thể bị lệch. Dùng .reset_index() để khắc phục:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnĐể trích dữ liệu dựa trên một điều kiện:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100Bạn có thể tách một cột bằng ngoặc vuông [ ] với tên cột bên trong. Kết quả là một đối tượng Series của pandas. Series là mảng một chiều chứa dữ liệu bất kỳ kiểu nào, gồm integer, float, string, boolean, đối tượng Python, v.v. DataFrame gồm nhiều Series đóng vai trò là các cột.
df['Outcome']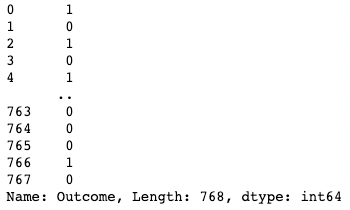
Tách một cột trong pandas
Bạn cũng có thể đưa vào danh sách tên cột bên trong ngoặc vuông để lấy nhiều cột. Ở đây, ngoặc vuông được dùng theo hai cách. Chúng ta dùng ngoặc vuông ngoài để chỉ tập con của DataFrame, và ngoặc vuông trong để tạo danh sách.
df[['Pregnancies', 'Outcome']]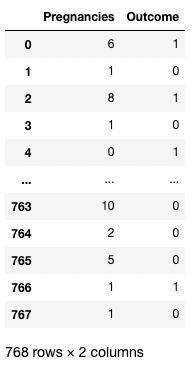
Tách hai cột trong pandas
Có thể lấy một hàng bằng cách truyền vào một Series boolean với một giá trị True. Ví dụ dưới đây trả về hàng thứ hai với index = 1. Ở đây, .index trả về nhãn hàng của DataFrame, và phép so sánh biến nó thành mảng một chiều Boolean.
df[df.index==1]
Tách một hàng trong pandas
Tương tự, có thể trả về hai hoặc nhiều hàng dùng phương thức .isin() thay vì toán tử ==.
df[df.index.isin(range(2,10))]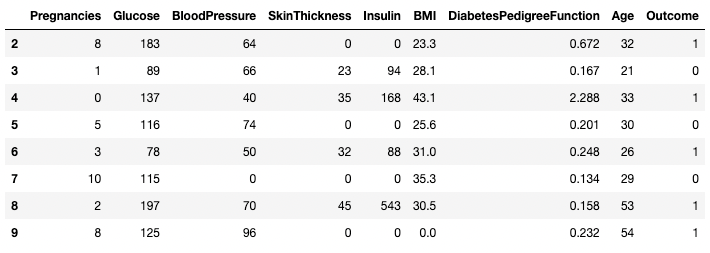
Tách các hàng cụ thể trong pandas
Bạn có thể lấy các hàng cụ thể theo nhãn hoặc theo điều kiện bằng .loc[] và .iloc[] ("location" và "integer location"). .loc[] dùng nhãn để trỏ tới một hàng, cột hoặc ô, trong khi .iloc[] dùng vị trí số. Để hiểu khác biệt, hãy sửa index của df2 đã tạo trước đó.
df2.index = range(1,769)Ví dụ dưới đây trả về một Series của pandas thay vì DataFrame. Số 1 đại diện cho index hàng (nhãn), trong khi 1 trong .iloc[] là vị trí hàng (hàng đầu tiên).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Bạn cũng có thể lấy nhiều hàng bằng cách cung cấp một khoảng trong ngoặc vuông.
df2.loc[100:110]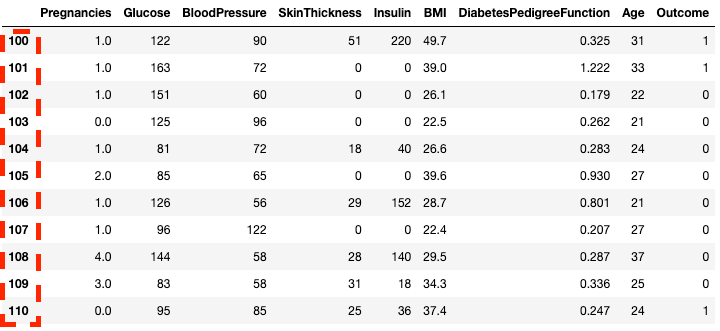
Tách hàng trong pandas với .loc[]
df2.iloc[100:110]![Isolating rows in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Tách hàng trong pandas với .iloc[]
Bạn cũng có thể lấy tập con với .loc[] và .iloc[] bằng cách dùng danh sách thay vì khoảng.
df2.loc[[100, 200, 300]]![Isolating rows using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Tách hàng bằng danh sách trong pandas với .loc[]
df2.iloc[[100, 200, 300]]
Tách hàng bằng danh sách trong pandas với .iloc[]
Bạn cũng có thể chọn các cột cụ thể cùng với hàng. Đây là điểm khác nhau giữa .iloc[] và .loc[] – .iloc[] yêu cầu vị trí cột chứ không phải nhãn cột.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Tách cột trong pandas với .loc[]
df2.iloc[100:110, :3]![Isolating columns using in pandas with .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Tách cột với .iloc[]
Để thao tác nhanh hơn, bạn có thể truyền vào chỉ mục bắt đầu của một hàng dưới dạng khoảng.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Tách cột và hàng trong pandas với .loc[]
df2.iloc[760:, :3]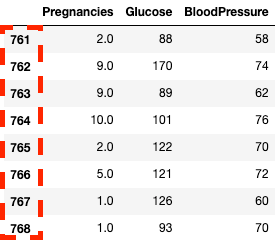
Tách cột và hàng trong pandas với .iloc[]
Bạn có thể cập nhật/sửa đổi một số giá trị bằng toán tử gán =
df2.loc[df['Age']==81, ['Age']] = 80pandas cho phép bạn lọc dữ liệu bằng các điều kiện trên giá trị hàng/cột. Ví dụ, đoạn mã dưới chọn hàng có Huyết áp (Blood Pressure) đúng bằng 122. Ở đây, chúng ta tách hàng bằng ngoặc [ ] như các phần trước. Tuy nhiên, thay vì đưa vào chỉ mục hàng hoặc tên cột, chúng ta đưa vào một điều kiện nơi cột BloodPressure bằng 122. Ta biểu diễn điều kiện này bằng df.BloodPressure == 122.
df[df.BloodPressure == 122]
Tách hàng dựa trên điều kiện trong pandas
Ví dụ dưới đây lấy tất cả hàng nơi Outcome là 1. Ở đây df.Outcome chọn cột đó, df.Outcome == 1 trả về một Series Boolean xác định Outcome nào bằng 1, sau đó [] lấy tập con của df nơi Series Boolean đó là True.
df[df.Outcome == 1]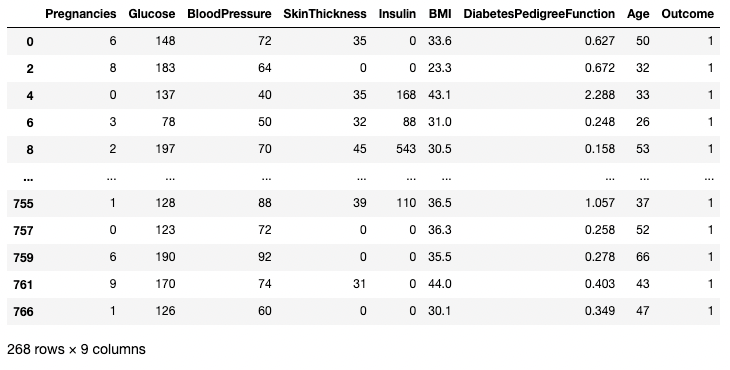
Tách hàng dựa trên điều kiện trong pandas
Bạn có thể dùng toán tử > để so sánh. Đoạn mã dưới đây lấy Pregnancies, Glucose và BloodPressure cho tất cả bản ghi có BloodPressure lớn hơn 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]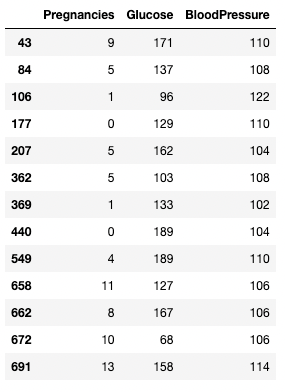
Tách hàng và cột dựa trên điều kiện trong pandas
Làm sạch dữ liệu là một trong những tác vụ phổ biến nhất trong khoa học dữ liệu. pandas cho phép bạn tiền xử lý dữ liệu cho mọi mục đích, bao gồm nhưng không giới hạn ở huấn luyện mô hình học máy và học sâu. Hãy dùng DataFrame df2 từ trước, có bốn giá trị thiếu, để minh họa vài trường hợp làm sạch dữ liệu. Nhắc lại, đây là cách xem có bao nhiêu giá trị thiếu trong DataFrame.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Một cách xử lý dữ liệu thiếu là loại bỏ chúng. Điều này hữu ích khi bạn có nhiều dữ liệu và việc mất đi một phần nhỏ không ảnh hưởng đến phân tích phía sau. Bạn có thể dùng phương thức .dropna() như dưới đây. Ở đây, chúng ta lưu kết quả từ .dropna() vào DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2Tham số axis cho phép bạn chỉ định đang loại bỏ hàng hay cột có giá trị thiếu. Mặc định axis loại bỏ các hàng chứa NaN. Dùng axis = 1 để loại bỏ các cột có một hoặc nhiều giá trị NaN. Cũng lưu ý cách chúng ta dùng tham số inplace=True giúp bạn không cần lưu đầu ra của .dropna() sang một DataFrame mới.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()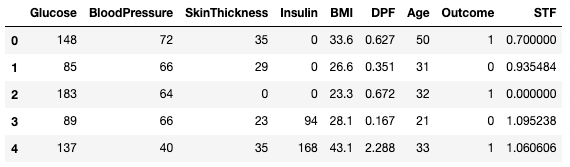
Loại bỏ dữ liệu thiếu trong pandas
Bạn cũng có thể loại bỏ cả hàng và cột có giá trị thiếu bằng cách đặt tham số how thành 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Thay vì loại bỏ, thay thế giá trị thiếu bằng một thống kê tóm tắt hoặc một giá trị cụ thể (tùy trường hợp sử dụng) có thể là cách tốt hơn. Ví dụ, nếu có một hàng thiếu ở cột nhiệt độ mô tả nhiệt độ trong các ngày trong tuần, thay giá trị thiếu đó bằng nhiệt độ trung bình của tuần đó có thể hiệu quả hơn là loại bỏ hoàn toàn. Bạn có thể thay dữ liệu thiếu bằng trung bình theo hàng hoặc theo cột như mã dưới đây.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Hãy thêm một số bản sao trùng lặp vào dữ liệu gốc để học cách loại bỏ trùng lặp trong DataFrame. Ở đây, chúng ta dùng phương thức .concat() để nối các hàng của DataFrame df2 với chính nó, thêm bản sao hoàn hảo của mọi hàng trong df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Bạn có thể loại bỏ tất cả các hàng trùng lặp (mặc định) khỏi DataFrame bằng phương thức .drop_duplicates().
df3 = df3.drop_duplicates()
df3.shape(768, 9)Một tác vụ làm sạch dữ liệu phổ biến là đổi tên cột. Với phương thức .rename(), bạn có thể dùng tham số columns để đổi tên các cột cụ thể. Mã dưới đây là từ điển ánh xạ tên cũ và tên mới.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()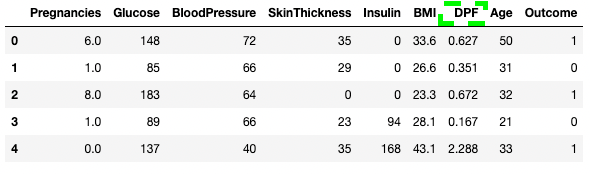
Đổi tên cột trong pandas
Bạn cũng có thể gán trực tiếp tên cột dưới dạng danh sách cho DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()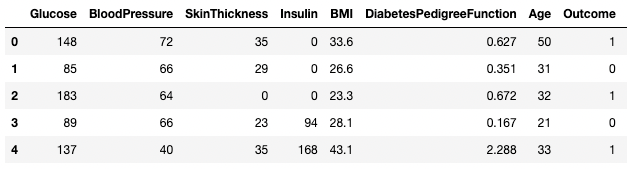
Đổi tên cột trong pandas
Để biết thêm về làm sạch dữ liệu và để có quy trình làm sạch dễ dàng, nhất quán hơn, hãy xem checklist sau, cung cấp một tập hợp toàn diện các tác vụ làm sạch dữ liệu phổ biến.
Giá trị cốt lõi của pandas nằm ở chức năng phân tích dữ liệu nhanh. Phần này sẽ tập trung vào một số kỹ thuật phân tích bạn có thể dùng trong pandas.
Như bạn đã thấy, bạn có thể lấy trung bình của mỗi cột bằng phương thức .mean().
df.mean()
In trung bình của các cột trong pandas
Giá trị mode có thể được tính tương tự bằng phương thức .mode().
df.mode()
In mode của các cột trong pandas
Tương tự, median của mỗi cột được tính bằng phương thức .median()
df.median()
In median của các cột trong pandas
pandas cho phép tính toán nhanh và hiệu quả bằng cách kết hợp hai hoặc nhiều cột như các biến vô hướng. Mã dưới đây chia mỗi giá trị trong cột Glucose cho giá trị tương ứng trong cột Insulin để tính cột mới Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Tạo cột mới từ các cột hiện có trong pandas
Thường bạn sẽ làm việc với giá trị phân loại và muốn đếm số quan sát mỗi hạng mục trong một cột. Các giá trị hạng mục có thể đếm bằng phương thức .value_counts(). Ở đây, ví dụ, chúng ta đếm số quan sát nơi Outcome là mắc tiểu đường (1) và số quan sát nơi Outcome không mắc (0).
df['Outcome'].value_counts()
Dùng .value_counts() trong pandas
Thêm tham số normalize sẽ trả về tỷ lệ thay vì số đếm tuyệt đối.
df['Outcome'].value_counts(normalize=True)
Dùng .value_counts() trong pandas với chuẩn hóa
Tắt sắp xếp tự động của kết quả bằng tham số sort (mặc định True). Mặc định sắp xếp dựa trên số đếm giảm dần.
df['Outcome'].value_counts(sort=False)
Dùng .value_counts() trong pandas với sắp xếp
Bạn cũng có thể áp dụng .value_counts() cho đối tượng DataFrame và các cột cụ thể trong đó thay vì chỉ một cột. Ở đây, ví dụ, chúng ta áp dụng value_counts() trên df với tham số subset, nhận vào danh sách các cột.
df.value_counts(subset=['Pregnancies', 'Outcome'])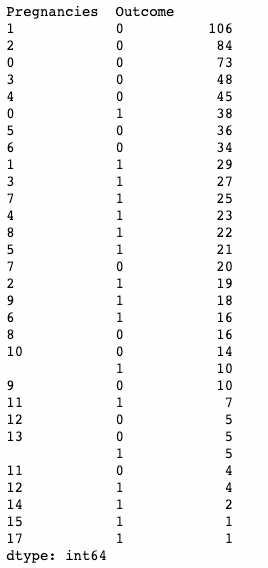
Dùng .value_counts() trong pandas khi lấy tập con cột
pandas cho phép bạn tổng hợp giá trị bằng cách nhóm theo các giá trị cột cụ thể. Bạn có thể làm điều đó bằng cách kết hợp phương thức .groupby() với một hàm tóm tắt tùy chọn. Đoạn mã dưới hiển thị trung bình của mỗi cột số theo nhóm Outcome.
df.groupby('Outcome').mean()
Tổng hợp dữ liệu theo một cột trong pandas
.groupby() cho phép nhóm theo nhiều hơn một cột bằng cách truyền vào danh sách tên cột, như dưới đây.
df.groupby(['Pregnancies', 'Outcome']).mean()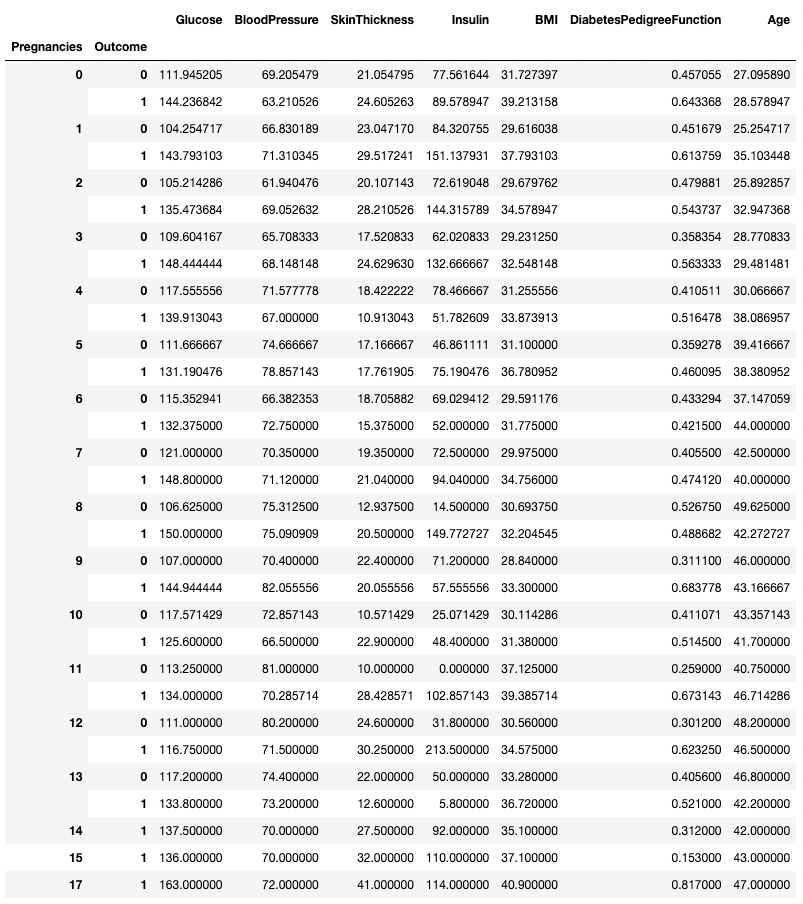
Tổng hợp dữ liệu theo hai cột trong pandas
Bất kỳ hàm tóm tắt nào cũng có thể dùng cùng .groupby(), bao gồm .min(), .max(), .mean(), .median(), .sum(), .mode(), và nhiều hơn nữa.
pandas cũng cho phép bạn tính các thống kê tóm tắt dưới dạng bảng pivot. Điều này giúp rút ra kết luận dựa trên tổ hợp biến. Đoạn mã dưới chọn hàng là các giá trị duy nhất của Pregnancies, cột là các giá trị duy nhất của Outcome, và ô chứa giá trị trung bình của BMI trong nhóm tương ứng.
Ví dụ, với Pregnancies = 5 và Outcome = 0, BMI trung bình là 31.1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc='mean')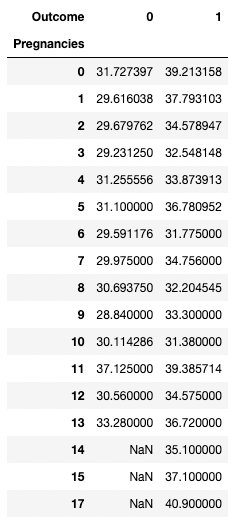
Tổng hợp dữ liệu bằng pivot với pandas
pandas cung cấp các wrapper tiện lợi cho các hàm vẽ của Matplotlib để việc trực quan hóa DataFrame trở nên dễ dàng. Dưới đây, bạn sẽ thấy cách thực hiện các trực quan hóa dữ liệu phổ biến bằng pandas.
pandas cho phép bạn vẽ mối quan hệ giữa các biến bằng biểu đồ đường. Dưới đây là biểu đồ đường của BMI và Glucose theo chỉ mục hàng.
df[['BMI', 'Glucose']].plot.line()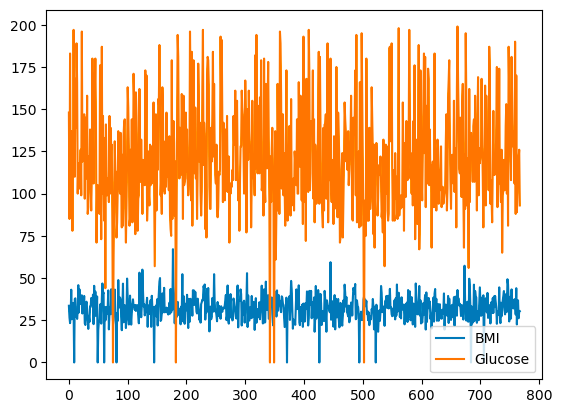
Biểu đồ đường cơ bản với pandas
Bạn có thể chọn màu bằng tham số color.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})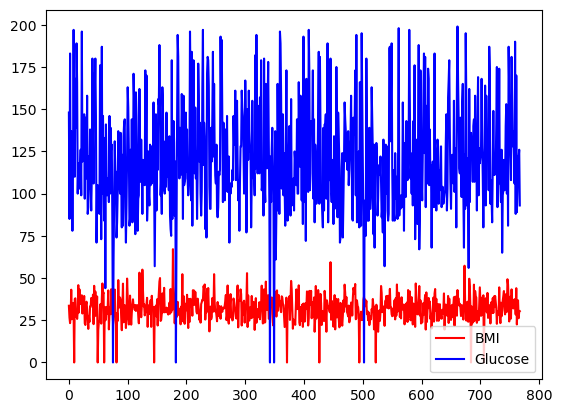
Biểu đồ đường cơ bản với pandas, với màu tùy chỉnh
Tất cả các cột của df cũng có thể được vẽ trên các thang và trục khác nhau bằng tham số subplots.
df.plot.line(subplots=True)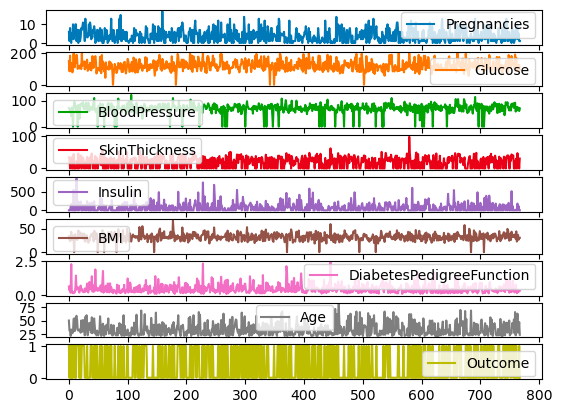
Biểu đồ con (subplots) cho biểu đồ đường với pandas
Với các cột rời rạc, bạn có thể dùng biểu đồ cột trên số lượng hạng mục để trực quan hóa phân phối. Biến Outcome với giá trị nhị phân được minh họa dưới đây.
df['Outcome'].value_counts().plot.bar()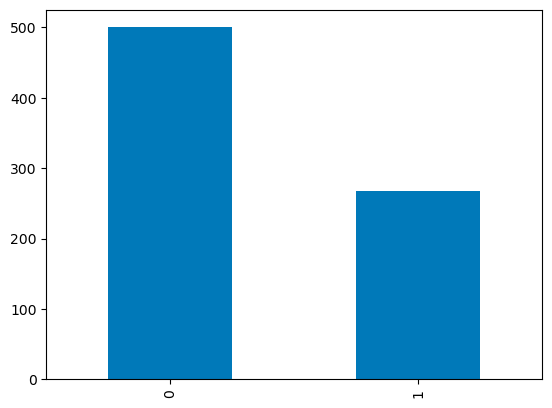
Biểu đồ cột trong pandas
Phân phối theo tứ phân vị của các biến liên tục có thể được trực quan hóa bằng boxplot. Đoạn mã dưới giúp bạn tạo boxplot với pandas.
df.boxplot(column=['BMI'], by='Outcome')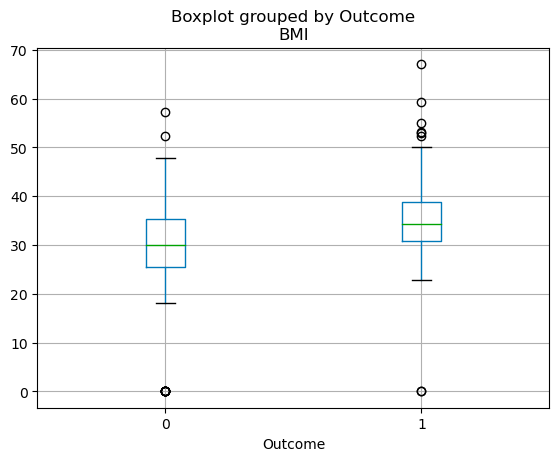
Biểu đồ hộp trong pandas
Hướng dẫn trên chỉ mới chạm vào bề mặt những gì có thể làm với pandas. Dù là phân tích dữ liệu, trực quan hóa, lọc hay tổng hợp, pandas cung cấp bộ tính năng vô cùng phong phú giúp bạn tăng tốc mọi quy trình dữ liệu. Hơn nữa, bằng cách kết hợp pandas với các gói khoa học dữ liệu khác, bạn có thể tạo dashboard tương tác, xây dựng mô hình dự đoán bằng học máy, tự động hóa quy trình dữ liệu và nhiều hơn nữa. Hãy xem các tài nguyên dưới đây để tăng tốc hành trình học pandas của bạn:
Nhiều khóa học về pandas hơn
Courses
Courses
Courses
