Python for Spreadsheet Users
BasicSkill Level
4 sa
29.1K learners
Bu eğitimdeki kodu çevrimiçi olarak çalıştırın ve düzenleyin
Kodu çalıştırpandas'ı kurmak son derece basittir; terminalinizde pip install komutunu kullanmanız yeterlidir.
pip install pandasAlternatif olarak, conda ile de kurabilirsiniz:
conda install pandaspandas'ı kurduktan sonra, her şeyin doğru çalıştığından emin olmak için yüklü sürümü kontrol etmek iyi bir uygulamadır:
import pandas as pd
print(pd.__version__) # Prints the pandas versionBu, pandas'ın doğru kurulduğunu doğrular ve diğer paketlerle uyumluluğu kontrol etmenizi sağlar.
pandas ile çalışmaya başlamak için, aşağıda gösterildiği gibi pandas Python paketini içe aktarın. pandas içe aktarılırken en yaygın takma ad pd'dir.
import pandas as pdVirgülle ayrılmış değerli bir dosyayı okumak için dosya yolunu belirterek read_csv() kullanın (daha fazla ayrıntı için read_csv() ile veri içe aktarma eğitimimize bakın).
df = pd.read_csv("diabetes.csv")Bu okuma işlemi, diabetes.csv dosyasını yükleyerek bir pandas DataFrame nesnesi df oluşturur. Bu eğitim boyunca, bu tür DataFrame nesnelerini nasıl işleyeceğinizi göreceksiniz.
Metin dosyalarını okumak CSV dosyalarına benzerdir. Tek fark, aşağıda gösterildiği gibi sep bağımsız değişkeniyle bir ayırıcı belirtmeniz gerektiğidir. Ayırıcı bağımsız değişkeni, bir DataFrame'de satırları ayırmak için kullanılan simgeyi ifade eder. Virgül (sep = ","), boşluk (sep = "\s"), sekme (sep = "\t") ve iki nokta (sep = ":") en sık kullanılan ayırıcılardır. Burada \s tek bir boşluk karakterini temsil eder.
df = pd.read_csv("diabetes.txt", sep="\s")Excel dosyalarını (hem XLS hem XLSX) okumak, dosya yolunu giriş olarak kullanan read_excel() işlevi kadar kolaydır.
df = pd.read_excel('diabetes.xlsx')Ayrıca, DataFrame'in başlığının hangi satır olacağını belirlemek için header gibi başka bağımsız değişkenler de belirtebilirsiniz. Varsayılan değeri 0'dır; bu da ilk satırın başlıklar veya sütun adları olduğunu belirtir. names bağımsız değişkeninde bir liste olarak sütun adlarını da belirtebilirsiniz. Dosya bir satır indeksi içeriyorsa index_col (varsayılan None) bağımsız değişkeni kullanılabilir.
Not: Bir pandas DataFrame veya Series'te indeks, bir pandas DataFrame'deki bir satırın veya sütunun konumunu işaret eden tanımlayıcıdır. Kısaca, indeks DataFrame'in satırını veya sütununu etiketler ve indeksini kullanarak belirli bir satıra veya sütuna erişmenizi sağlar (bunu ileride göreceksiniz). Bir DataFrame’in satır indeksi bir aralık (ör. 0'dan 303'e), bir zaman serisi (tarihler veya zaman damgaları), benzersiz bir tanımlayıcı (ör. bir employees tablosundaki employee_ID) veya başka türden veriler olabilir. Sütunlar için genellikle bir dizedir (sütun adını belirtir).
Birden çok sayfası olan Excel dosyalarını okumak pek farklı değildir. Sadece bir ek bağımsız değişken belirtmeniz gerekir: sheet_name. Buraya sayfa adını bir dize olarak ya da sayfa konumunu bir tamsayı olarak verebilirsiniz (Python'un 0 tabanlı indeksleme kullandığını ve ilk sayfaya sheet_name = 0 ile erişildiğini unutmayın).
# Python 0-indeksleme kullandığı için ikinci sayfayı çıkarma
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)read_csv() işlevine benzer şekilde, read_json() işlevini JSON dosyaları için, JSON dosya adını bağımsız değişken olarak vererek kullanabilirsiniz (daha fazla ayrıntı için pandas'a JSON ve HTML veri içe aktarma eğitimini okuyun). Aşağıdaki kod, diskten bir JSON dosyası okur ve df adlı bir DataFrame nesnesi oluşturur.
df = pd.read_json("diabetes.json")pandas ile veri içe aktarma hakkında daha fazla bilgi edinmek isterseniz, Python ile çeşitli dosya türlerini içe aktarma konusunda bu özet kılavuza göz atın.
İlişkisel bir veritabanından veri yüklemek için bir veritabanı bağlantısıyla birlikte pd.read_sql() kullanın.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Büyük veri kümeleri için sorguları iyileştirmek amacıyla SQLAlchemy kullanmayı düşünün.
Verileriniz bir web API'sinden geliyorsa, pandas bunu doğrudan pd.read_json() kullanarak okuyabilir:
df = pd.read_json("https://api.example.com/data.json")API yanıtı sayfalanmışsa veya iç içe geçmiş bir JSON biçimindeyse, pandas.io.json içindeki json_normalize() ile ek işlem yapmanız gerekebilir.
pandas çeşitli dosya türlerinden veri içe aktarabildiği gibi verileri çeşitli biçimlere dışa aktarmanıza da olanak tanır. Bu özellikle, veriler pandas kullanılarak dönüştürüldüğünde ve makinenize yerel olarak kaydedilmesi gerektiğinde kullanışlıdır. Aşağıda pandas DataFrame'lerini çeşitli biçimlere nasıl aktarıp kaydedeceğiniz yer alıyor.
Bir pandas DataFrame'i (burada df kullanıyoruz) .to_csv() yöntemiyle CSV dosyası olarak kaydedilir. Bağımsız değişkenler arasında dosya adı/yolu ve index bulunur – index = True, DataFrame'in indeksinin yazılacağı anlamına gelir.
df.to_csv("diabetes_out.csv", index=False)DataFrame nesnesini .to_json() yöntemini çağırarak bir JSON dosyasına dışa aktarın.
df.to_json("diabetes_out.json")Not: Bir JSON dosyası, DataFrame gibi tabular bir nesneyi anahtar-değer çifti olarak depolar. Bu nedenle bir JSON dosyasında tekrarlayan sütun başlıkları görürsünüz.
DataFrame'leri CSV dosyalarına yazmaya benzer şekilde, .to_csv() çağrısı yapabilirsiniz. Tek fark, çıktı dosya biçiminin .txt olması ve sep bağımsız değişkeniyle bir ayırıcı belirtmeniz gerektiğidir.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ').to_excel() yöntemini DataFrame nesnesinden çağırarak “.xls” veya “.xlsx” dosyası olarak kaydedin.
df.to_excel("diabetes_out.xlsx", index=False)Tabular veriyi bir DataFrame olarak okuduktan sonra, veriye hızlıca göz atmanız gerekir. Veri kümesinin küçük bir örneğini ya da özet istatistikler biçiminde bir özetini görüntüleyebilirsiniz.
.head() ve .tail() ile verileri nasıl görüntülersinizBir DataFrame'in ilk birkaç veya son birkaç satırını sırasıyla .head() veya .tail() yöntemleriyle görüntüleyebilirsiniz. n bağımsız değişkeniyle satır sayısını belirtebilirsiniz (varsayılan değer 5'tir).
df.head()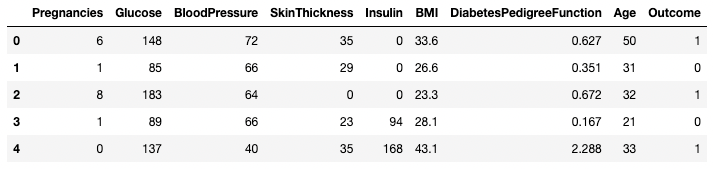
DataFrame'in ilk beş satırı
df.tail(n = 10)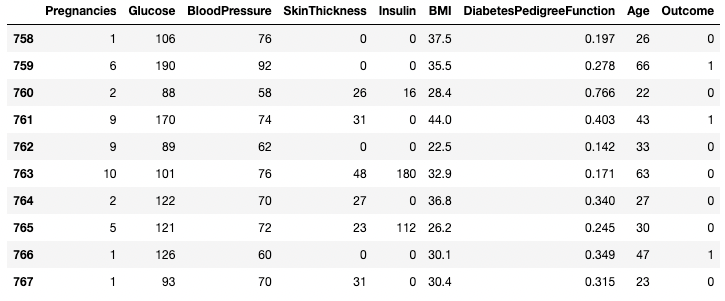
DataFrame'in son 10 satırı
.describe() ile verileri anlama.describe() yöntemi; tüm sayısal sütunların özet istatistiklerini, örneğin adet, ortalama, standart sapma, aralık ve çeyreklikleri yazdırır.
df.describe()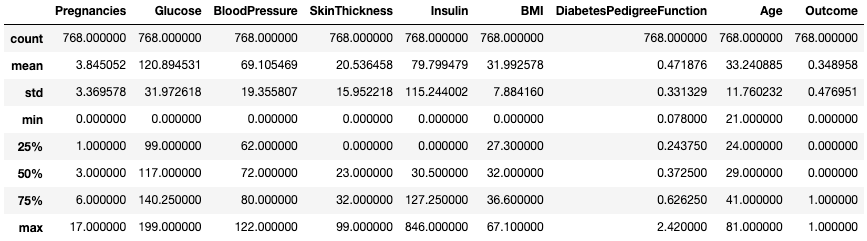
.describe() ile özet istatistikleri alın
Bu, sayısal verinin ölçeğine, çarpıklığına ve aralığına hızlı bir bakış sağlar.
percentiles bağımsız değişkenini kullanarak çeyreklikleri de değiştirebilirsiniz. Burada örneğin, DataFrame df içindeki sayısal sütunların yüzde 30, 50 ve 70'lik dilimlerine bakıyoruz.
df.describe(percentiles=[0.3, 0.5, 0.7])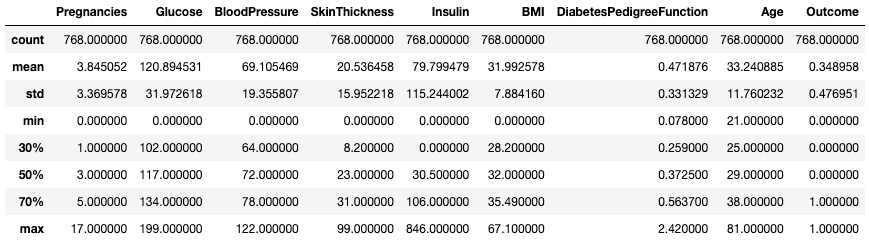
Belirli yüzdeliklerle özet istatistikleri alın
Ayrıca, include bağımsız değişkenini kullanarak özet çıktınızda belirli veri türlerini izole edebilirsiniz. Burada örneğin, yalnızca integer veri türüne sahip sütunları özetliyoruz.
df.describe(include=[int])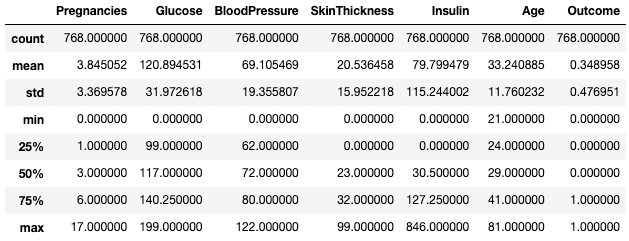
Yalnızca tamsayı sütunlarının özet istatistiklerini alın
Benzer şekilde, exclude bağımsız değişkenini kullanarak belirli veri türlerini hariç tutmak isteyebilirsiniz.
df.describe(exclude=[int])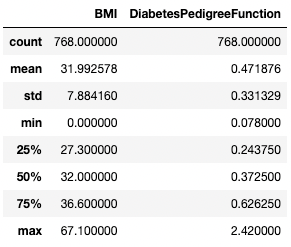
Yalnızca tamsayı olmayan sütunların özet istatistiklerini alın
Uygulayıcılar, bu tür istatistikleri .T özniteliğiyle transpoze ederek görüntülemeyi genellikle daha kolay bulur.
df.describe().T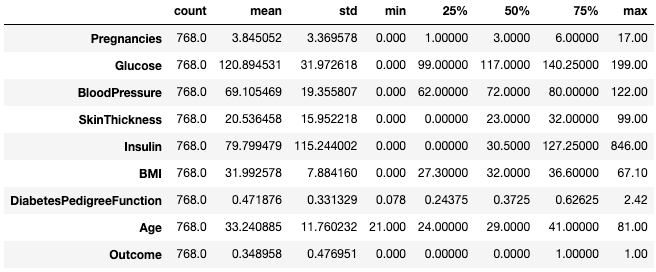
Özet istatistikleri .T ile transpoze edin
DataFrame'leri betimleme hakkında daha fazlası için şu özet kılavuza göz atın.
.info() yöntemi, bir DataFrame'in veri türlerine, eksik değerlere ve veri boyutuna hızlıca bakmanın bir yoludur. Burada, her sütundaki toplam eksik olmayan değerlerin bir görünümünü veren show_counts bağımsız değişkenini True olarak ayarlıyoruz. Ayrıca, DataFrame öğelerinin toplam bellek kullanımını gösteren memory_usage'ı True olarak ayarlıyoruz. verbose True olarak ayarlandığında, .info()'dan tam özeti yazdırır.
df.info(show_counts=True, memory_usage=True, verbose=True)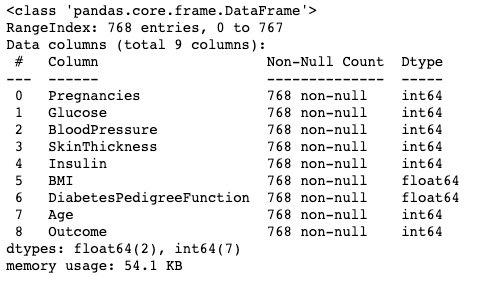
Bir DataFrame'in satır ve sütun sayısı, DataFrame'in .shape özniteliği kullanılarak belirlenebilir. Bu, bir demet (satır, sütun) döndürür ve çıktıda yalnızca satır sayısını veya yalnızca sütun sayısını almak için indekslenebilir.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Bir DataFrame nesnesinin .columns özniteliğini çağırmak, sütun adlarını bir Index nesnesi biçiminde döndürür. Hatırlatma olarak, bir pandas indeksi satırın veya sütunun adresi/etiketidir.
df.columns
list() işlevi kullanılarak bir listeye dönüştürülebilir.
list(df.columns)
Örnek DataFrame'imizde eksik değer yok. İşleri biraz ilginçleştirmek için birkaç tane ekleyelim. .copy() yöntemi, orijinal DataFrame'in bir kopyasını oluşturur. Bu, kopyadaki değişikliklerin orijinal DataFrame'de yansımamasını sağlamak için yapılır. .loc'u kullanarak (ileride ele alınacak), Pregnancies sütununun iki ile beşinci satırlarını eksik değerleri ifade eden NaN olarak ayarlayabilirsiniz.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)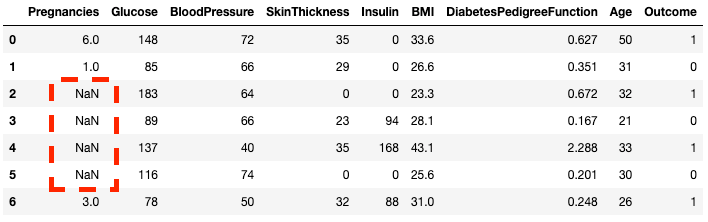
Gördüğünüz gibi, artık 2 ile 5. satırlar NaN
Bir DataFrame'deki her öğenin eksik olup olmadığını .isnull() yöntemiyle kontrol edebilirsiniz.
df2.isnull().head(7)Genellikle ne kadar eksik veri olduğunun bilinmesi daha faydalı olduğundan, her sütundaki boş değerleri saymak için .isnull() ile .sum()'ı birleştirebilirsiniz.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64DataFrame'deki toplam boş değer sayısını almak için çift toplam da yapabilirsiniz.
df2.isnull().sum().sum()4pandas paketi, DataFrame'lerinizde verileri sıralamak, alt kümelere ayırmak, filtrelemek ve izole etmek için çeşitli yollar sunar. Burada en yaygın yolları göreceğiz.
Bir DataFrame'i belirli bir sütuna göre sıralamak için:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderBirden çok sütuna göre sıralayabilirsiniz:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Bir DataFrame'i filtreler veya sıralarsanız, indeksiniz hizadan çıkabilir. Bunu düzeltmek için .reset_index() kullanın:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnBir koşula göre veri çıkarmak için:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100Köşeli parantez [ ] içine bir sütun adı yazarak tek bir sütunu izole edebilirsiniz. Çıktı bir pandas Series nesnesidir. Bir pandas Series, tamsayı, kayan nokta, dize, boolean, Python nesneleri vb. dahil olmak üzere herhangi bir türde veriyi içeren tek boyutlu bir dizidir. Bir DataFrame, sütun görevi gören birçok seriden oluşur.
df['Outcome']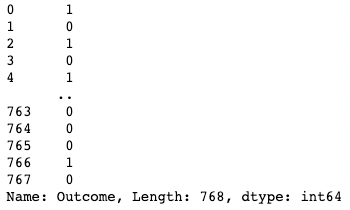
pandas'ta tek bir sütunu izole etme
Birden fazla sütunu getirmek için köşeli parantez içine bir sütun adları listesi de verebilirsiniz. Burada köşeli parantezler iki farklı şekilde kullanılır. Dış köşeli parantezleri bir DataFrame'in alt kümesini belirtmek için, iç köşeli parantezleri ise bir liste oluşturmak için kullanırız.
df[['Pregnancies', 'Outcome']]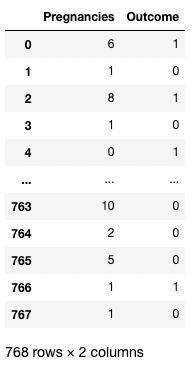
pandas'ta iki sütunu izole etme
Tek bir satır, içinde bir adet True değeri olan bir boolean seri geçirilerek alınabilir. Aşağıdaki örnekte, index = 1 olan ikinci satır döndürülür. Burada .index, DataFrame'in satır etiketlerini döndürür ve karşılaştırma bunu bir Boolean tek boyutlu diziye dönüştürür.
df[df.index==1]
pandas'ta tek bir satırı izole etme
Benzer şekilde, == operatörü yerine .isin() yöntemi kullanılarak iki veya daha fazla satır döndürülebilir.
df[df.index.isin(range(2,10))]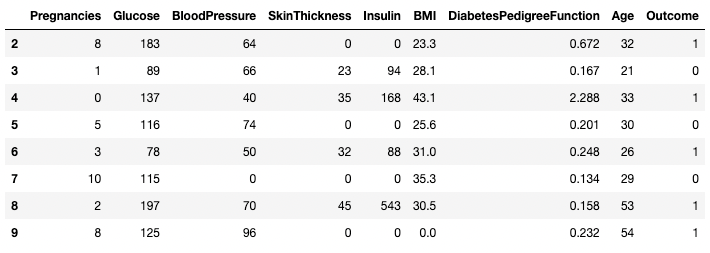
pandas'ta belirli satırları izole etme
Belirli satırları etiketlerle veya koşullarla .loc[] ve .iloc[] ("konum" ve "tamsayı konumu") kullanarak getirebilirsiniz. .loc[] bir satıra, sütuna veya hücreye işaret etmek için etiketi kullanırken, .iloc[] sayısal konumu kullanır. İkisi arasındaki farkı anlamak için daha önce oluşturulan df2'nin indeksini değiştirelim.
df2.index = range(1,769)Aşağıdaki örnek bir DataFrame yerine bir pandas Series döndürür. 1 satır indeksini (etiketini) temsil ederken, .iloc[] içindeki 1 satır konumunu (ilk satır) ifade eder.
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Köşeli parantez içinde bir aralık vererek birden çok satırı da getirebilirsiniz.
df2.loc[100:110]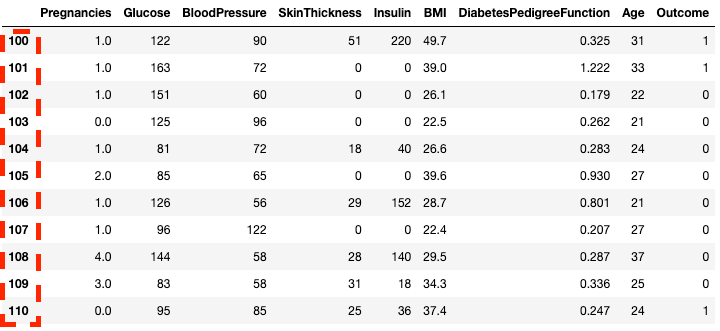
.loc[] ile pandas'ta satırları izole etme
df2.iloc[100:110]![Isolating rows in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
.iloc[] ile pandas'ta satırları izole etme
Aralık yerine bir liste kullanarak da .loc[] ve .iloc[] ile alt küme alabilirsiniz.
df2.loc[[100, 200, 300]]![Isolating rows using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
pandas'ta bir liste kullanarak .loc[] ile satırları izole etme
df2.iloc[[100, 200, 300]]
pandas'ta bir liste kullanarak .iloc[] ile satırları izole etme
Satırlarla birlikte belirli sütunları da seçebilirsiniz. .iloc[]’un .loc[]’dan farkı burada ortaya çıkar – sütun etiketlerini değil, sütun konumunu gerektirir.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
.loc[] ile pandas'ta sütunları izole etme
df2.iloc[100:110, :3]![Isolating columns using in pandas with .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
.iloc[] ile sütunları izole etme
Daha hızlı iş akışları için, bir satırın başlangıç indeksini bir aralık olarak geçebilirsiniz.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
.loc[] ile pandas'ta satır ve sütunları izole etme
df2.iloc[760:, :3]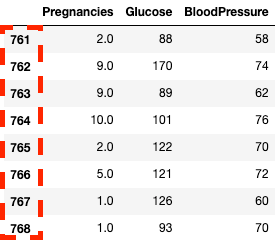
.iloc[] ile pandas'ta satır ve sütunları izole etme
Atama operatörü = kullanarak belirli değerleri güncelleyebilir/değiştirebilirsiniz
df2.loc[df['Age']==81, ['Age']] = 80pandas, satır/sütun değerleri üzerindeki koşullara göre veri filtrelemenize olanak tanır. Örneğin, aşağıdaki kod Kan Basıncı'nın tam olarak 122 olduğu satırı seçer. Burada, önceki bölümlerde görüldüğü gibi köşeli parantez [ ] kullanarak satırları izole ediyoruz. Ancak satır indeksleri veya sütun adları girmek yerine, BloodPressure sütununun 122'ye eşit olduğu bir koşul giriyoruz. Bu koşulu df.BloodPressure == 122 ifadesiyle belirtiriz.
df[df.BloodPressure == 122]
pandas'ta bir koşula göre satırları izole etme
Aşağıdaki örnek, Outcome'ın 1 olduğu tüm satırları getirir. Burada df.Outcome o sütunu seçer, df.Outcome == 1 1'e eşit olan Outcome değerlerini belirleyen bir Boolean seri döndürür, ardından [] bu Boolean serisinin True olduğu df'in bir alt kümesini alır.
df[df.Outcome == 1]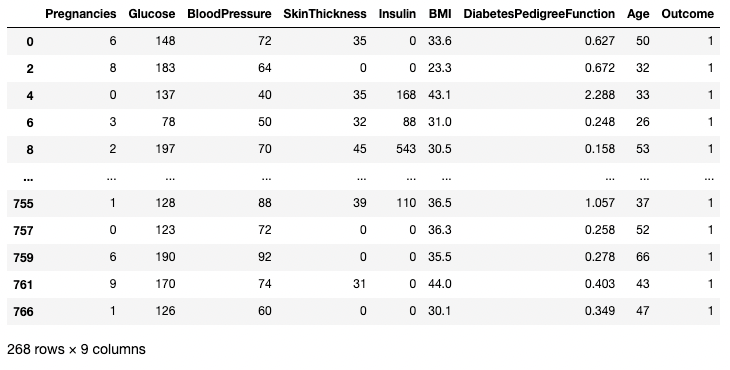
pandas'ta bir koşula göre satırları izole etme
> operatörünü kullanarak karşılaştırmalar yapabilirsiniz. Aşağıdaki kod, BloodPressure değeri 100'den büyük olan tüm kayıtlar için Pregnancies, Glucose ve BloodPressure sütunlarını getirir.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]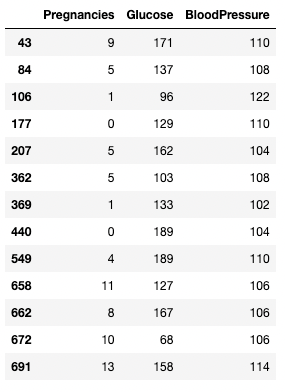
pandas'ta bir koşula göre satır ve sütunları izole etme
Veri temizleme, veri bilimindeki en yaygın görevlerden biridir. pandas, makine öğrenimi ve derin öğrenme modellerini eğitmek dahil her türlü kullanım için veriyi ön işleme imkânı verir. Daha önce dört eksik değere sahip df2 DataFrame'ini birkaç veri temizleme kullanım örneğini göstermek için kullanalım. Hatırlatma olarak, bir DataFrame'de kaç eksik değer olduğunu şu şekilde görebilirsiniz.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Eksik verilerle başa çıkmanın bir yolu onları atmaktır. Bu, çok fazla veriye sahip olduğunuz ve küçük bir kısmını kaybetmenin aşağı akış analizini etkilemeyeceği durumlarda özellikle kullanışlıdır. Aşağıda gösterildiği gibi .dropna() yöntemini kullanabilirsiniz. Burada, .dropna() sonuçlarını df3 adlı bir DataFrame'e kaydediyoruz.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2axis bağımsız değişkeni, eksik değer içeren satırları mı yoksa sütunları mı attığınızı belirtmenizi sağlar. Varsayılan axis, NaN içeren satırları kaldırır. Bir veya daha fazla NaN değeri içeren sütunları kaldırmak için axis = 1 kullanın. Ayrıca, .dropna() çıktısını yeni bir DataFrame'e kaydetmeyi atlamanızı sağlayan inplace=True bağımsız değişkenini nasıl kullandığımıza dikkat edin.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()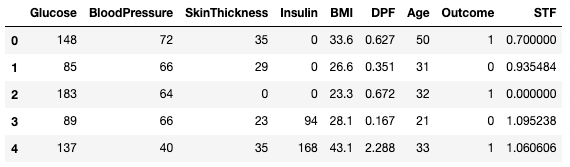
pandas'ta eksik verileri atma
how bağımsız değişkenini 'all' olarak ayarlayarak eksik değer içeren hem satırları hem de sütunları atabilirsiniz
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Atmak yerine, eksik değerleri bir özet istatistikle veya belirli bir değerle (kullanım durumuna bağlı olarak) değiştirmek en iyi yol olabilir. Örneğin, haftanın günleri boyunca sıcaklıkları gösteren bir sütunda bir satır eksikse, o eksik değeri o haftanın ortalama sıcaklığıyla değiştirmek, değerleri tamamen atmaktan daha etkili olabilir. Aşağıdaki kodu kullanarak eksik verileri satır veya sütun ortalamasıyla değiştirebilirsiniz.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Bir DataFrame'deki yinelenenleri nasıl ortadan kaldıracağınızı öğrenmek için orijinal veriye bazı kopyalar ekleyelim. Burada .concat() yöntemini kullanarak df2 DataFrame'inin satırlarını yine df2 ile birleştiriyor, böylece df2'deki her satırın birebir kopyalarını ekliyoruz.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9).drop_duplicates() yöntemini kullanarak DataFrame'den tüm yinelenen satırları (varsayılan) kaldırabilirsiniz.
df3 = df3.drop_duplicates()
df3.shape(768, 9)Yaygın bir veri temizleme görevi sütunları yeniden adlandırmaktır. .rename() yöntemiyle belirli sütunları yeniden adlandırmak için columns bağımsız değişkenini kullanabilirsiniz. Aşağıdaki kod, eski ve yeni sütun adlarının eşlemesine ilişkin sözlüğü gösterir.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()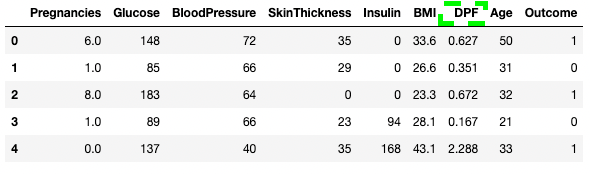
pandas'ta sütunları yeniden adlandırma
Sütun adlarını bir liste olarak doğrudan DataFrame'e de atayabilirsiniz.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()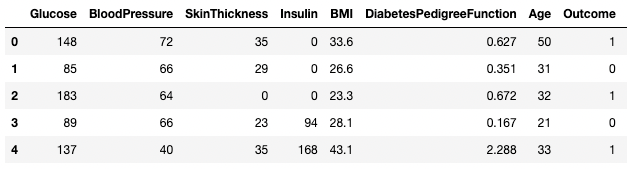
pandas'ta sütunları yeniden adlandırma
Daha kolay, daha öngörülebilir veri temizleme iş akışları ve veri temizleme hakkında daha fazlası için, yaygın veri temizleme görevlerinin kapsamlı bir listesini sunan aşağıdaki kontrol listesini inceleyin.
pandas'ın ana değer önerisi, hızlı veri analizi işlevselliğinde yatar. Bu bölümde, pandas'ta kullanabileceğiniz bir dizi analiz tekniğine odaklanacağız.
Daha önce gördüğünüz gibi, .mean() yöntemiyle her sütun değerinin ortalamasını alabilirsiniz.
df.mean()
pandas'ta sütunların ortalamasını yazdırma
Tepe değer (mod) benzer şekilde .mode() yöntemiyle hesaplanabilir.
df.mode()
pandas'ta sütunların tepe değerini yazdırma
Benzer şekilde, her sütunun medyanı .median() yöntemiyle hesaplanır
df.median()
pandas'ta sütunların medyanını yazdırma
pandas, iki veya daha fazla sütunu skaler değişkenler gibi birleştirerek hızlı ve verimli hesaplama sağlar. Aşağıdaki kod, Glucose sütunundaki her değeri Insulin sütunundaki karşılık gelen değerle bölerek Glucose_Insulin_Ratio adlı yeni bir sütun hesaplar.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
pandas'ta mevcut sütunlardan yeni bir sütun oluşturma
Çoğu zaman kategorik değerlerle çalışırsınız ve bir sütunda her kategorinin kaç gözleme sahip olduğunu saymak istersiniz. Kategori değerleri, .value_counts() yöntemleri kullanılarak sayılabilir. Burada örneğin, Outcome'ın diyabetik (1) olduğu ve Outcome'ın diyabetik olmadığı (0) gözlemlerin sayısını sayıyoruz.
df['Outcome'].value_counts()
pandas'ta .value_counts() kullanma
normalize bağımsız değişkenini eklemek, mutlak sayımlar yerine oranları döndürür.
df['Outcome'].value_counts(normalize=True)
pandas'ta normalleştirme ile .value_counts() kullanma
Sonuçların otomatik sıralamasını sort bağımsız değişkeniyle kapatın (varsayılan olarak True). Varsayılan sıralama, azalan düzende sayımlara göredir.
df['Outcome'].value_counts(sort=False)
Sıralama ile .value_counts() kullanma
.value_counts()’ı yalnızca bir sütuna değil, bir DataFrame nesnesine ve içindeki belirli sütunlara da uygulayabilirsiniz. Burada örneğin, subset bağımsız değişkeniyle, bir sütun listesini alan df üzerinde value_counts() uyguluyoruz.
df.value_counts(subset=['Pregnancies', 'Outcome'])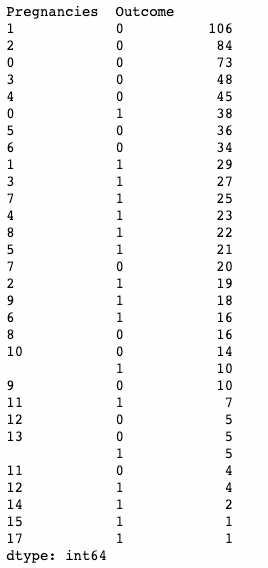
Sütunları alt kümelere ayırırken pandas'ta .value_counts() kullanma
pandas, belirli sütun değerlerine göre gruplandırarak değerleri bir araya getirmenize olanak tanır. Bunu, .groupby() yöntemini seçtiğiniz bir özet yöntemiyle birleştirerek yapabilirsiniz. Aşağıdaki kod, Outcome'a göre gruplandırılmış her bir sayısal sütunun ortalamasını gösterir.
df.groupby('Outcome').mean()
pandas'ta tek bir sütuna göre verileri bir araya getirme
.groupby(), aşağıda gösterildiği gibi bir sütun adları listesi geçirerek birden fazla sütuna göre gruplandırmayı mümkün kılar.
df.groupby(['Pregnancies', 'Outcome']).mean()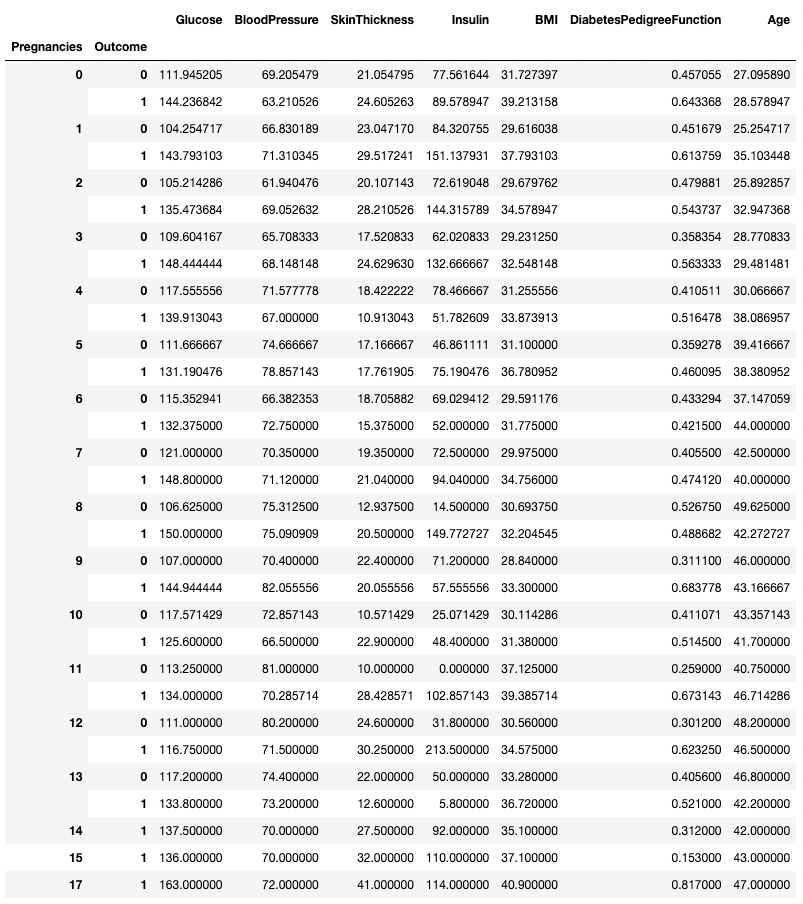
pandas'ta iki sütuna göre verileri bir araya getirme
.groupby() ile birlikte .min(), .max(), .mean(), .median(), .sum(), .mode() ve daha fazlası dahil olmak üzere herhangi bir özet yöntemi kullanılabilir.
pandas, özet istatistikleri pivot tablolar olarak da hesaplamanıza olanak tanır. Bu, değişken kombinasyonlarına dayalı çıkarımlar yapmayı kolaylaştırır. Aşağıdaki kod, satırlar olarak Pregnancies'in benzersiz değerlerini, sütun değerleri olarak Outcome'ın benzersiz değerlerini seçer ve hücreler ilgili gruptaki BMI'nın ortalama değerini içerir.
Örneğin, Pregnancies = 5 ve Outcome = 0 için, ortalama BMI 31.1 çıkmaktadır.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc='mean')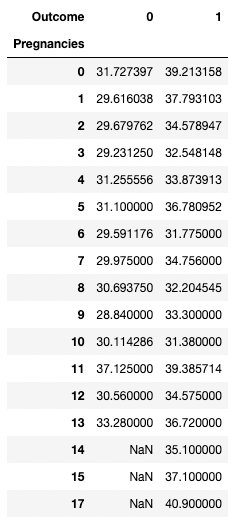
pandas ile pivotlama yaparak verileri bir araya getirme
pandas, DataFrame'lerinizi kolayca görselleştirmeniz için Matplotlib çizim işlevlerine kolaylık sağlayan sarmalayıcılar sunar. Aşağıda pandas kullanarak yaygın veri görselleştirmelerinin nasıl yapılacağını göreceksiniz.
pandas, çizgi grafikleri kullanarak değişkenler arasındaki ilişkileri çizmenizi sağlar. Aşağıda, BMI ve Glucose'un satır indeksine karşı çizgi grafiği bulunmaktadır.
df[['BMI', 'Glucose']].plot.line()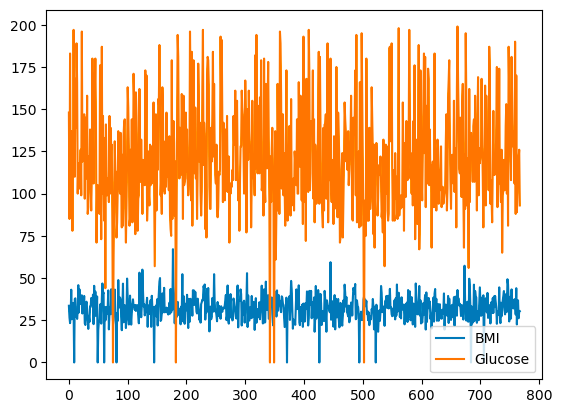
pandas ile temel çizgi grafiği
Renk seçimini color bağımsız değişkenini kullanarak belirleyebilirsiniz.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})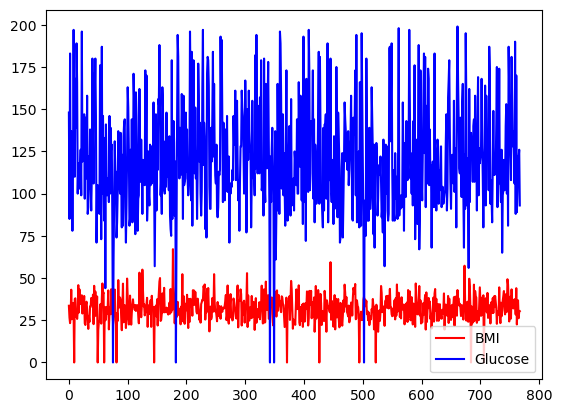
pandas ile özel renklerle temel çizgi grafiği
df'in tüm sütunları subplots bağımsız değişkeni kullanılarak farklı ölçeklerde ve eksenlerde de çizdirilebilir.
df.plot.line(subplots=True)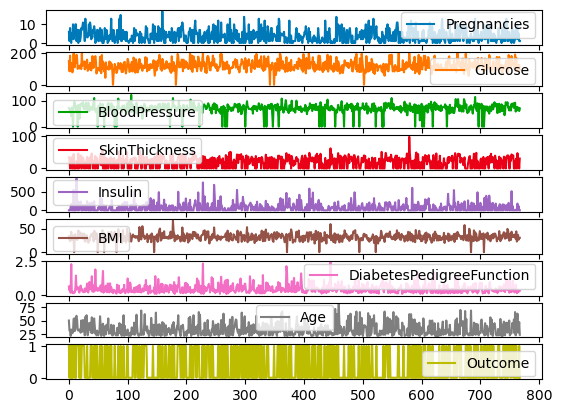
pandas ile çizgi grafikler için alt grafikler
Kesikli sütunlar için, dağılımlarını görselleştirmek amacıyla kategori sayımları üzerinden bir çubuk grafik kullanabilirsiniz. İkili değerlere sahip Outcome değişkeni aşağıda görselleştirilmiştir.
df['Outcome'].value_counts().plot.bar()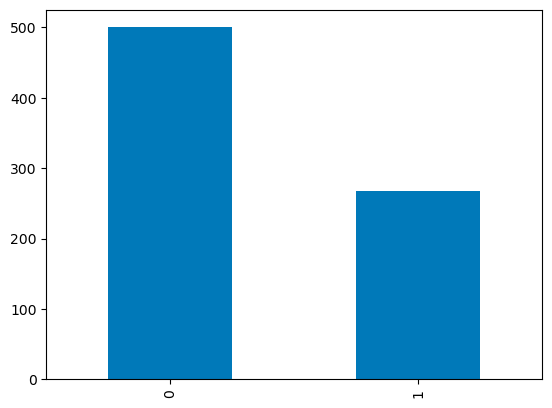
pandas'ta çubuk grafikler
Sürekli değişkenlerin çeyreklik dağılımı bir kutu grafiği ile görselleştirilebilir. Aşağıdaki kod, pandas ile bir kutu grafiği oluşturmanıza olanak tanır.
df.boxplot(column=['BMI'], by='Outcome')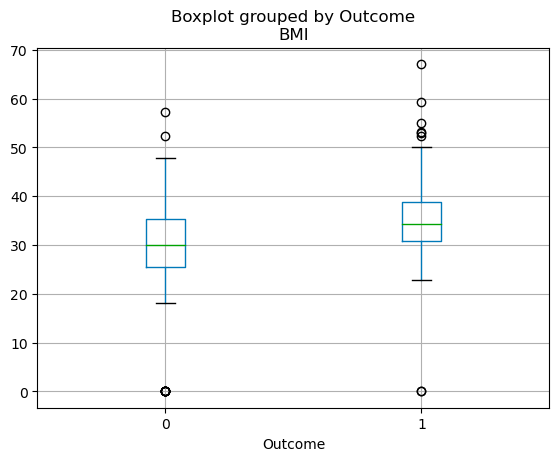
pandas'ta kutu grafikleri
Yukarıdaki eğitim, pandas ile yapılabileceklerin yüzeyine dokunuyor. İster veriyi analiz edin, ister görselleştirin, filtreleyin veya bir araya getirin; pandas, herhangi bir veri iş akışını hızlandırmanızı sağlayan son derece zengin bir özellik seti sunar. Dahası, pandas'ı diğer veri bilimi paketleriyle birleştirerek etkileşimli panolar oluşturabilir, makine öğrenimi kullanarak tahmine dayalı modeller geliştirebilir, veri iş akışlarını otomatikleştirebilir ve daha fazlasını yapabilirsiniz. pandas öğrenme yolculuğunuzu hızlandırmak için aşağıdaki kaynaklara göz atın:
Daha fazla pandas kursu
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes

