Python for Spreadsheet Users
BasicSkill Level
4 Hr
29.1K learners
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenpandas installeren is eenvoudig; gebruik gewoon het pip install-commando in je terminal.
pip install pandasJe kunt het ook via conda installeren:
conda install pandasNa het installeren van pandas is het goed om de geïnstalleerde versie te controleren om zeker te zijn dat alles werkt:
import pandas as pd
print(pd.__version__) # Prints the pandas versionDit bevestigt dat pandas correct is geïnstalleerd en laat je compatibiliteit met andere pakketten verifiëren.
Om met pandas te werken, importeer je het Python-pakket pandas zoals hieronder. De meest gebruikte alias voor pandas is pd.
import pandas as pdGebruik read_csv() met het pad naar het CSV-bestand om een comma-separated values-bestand te lezen (zie onze tutorial over data importeren met read_csv() voor meer details).
df = pd.read_csv("diabetes.csv")Deze leesbewerking laadt het CSV-bestand diabetes.csv en maakt een pandas DataFrame-object df. In deze tutorial zie je hoe je zulke DataFrame-objecten manipuleert.
Tekstbestanden lezen lijkt op CSV-bestanden. Het enige verschil is dat je een scheidingsteken moet opgeven met het argument sep, zoals hieronder. Het separator-argument verwijst naar het symbool dat wordt gebruikt om kolommen in een DataFrame te scheiden. Komma (sep = ","), witruimte (sep = "\s"), tab (sep = "\t") en dubbele punt (sep = ":") zijn de meestgebruikte scheidingstekens. Hier staat \s voor één witruimteteken.
df = pd.read_csv("diabetes.txt", sep="\s")Excel-bestanden importeren (enkel blad)
Excel-bestanden lezen (zowel XLS als XLSX) is net zo makkelijk met de functie
read_excel(), waarbij je het bestandspad meegeeft.df = pd.read_excel('diabetes.xlsx')Je kunt ook andere argumenten opgeven, zoals
headerom aan te geven welke rij de kop van het DataFrame wordt. De standaardwaarde is0, wat betekent dat de eerste rij de headers of kolomnamen zijn. Je kunt ook kolomnamen als lijst opgeven in het argumentnames. Het argumentindex_col(standaardNone) kan worden gebruikt als het bestand een rij-index bevat.Let op: In een pandas DataFrame of Series is de index een identificator die verwijst naar de locatie van een rij of kolom in een pandas DataFrame. Kort gezegd labelt de index de rij of kolom van een DataFrame en kun je een specifieke rij of kolom benaderen via de index (je ziet dit later). De rij-index van een DataFrame kan een bereik zijn (bijv. 0 tot 303), een tijdreeks (datums of tijdstempels), een unieke identificator (bijv.
employee_IDin eenemployees-tabel) of andere datatypes. Voor kolommen is het meestal een string (die de kolomnaam aangeeft).Excel-bestanden importeren (meerdere bladen)
Excel-bestanden met meerdere bladen lezen is niet heel anders. Je hoeft slechts één extra argument op te geven,
sheet_name, waarin je een string voor de bladnaam of een integer voor de bladpositie kunt meegeven (onthoud dat Python 0-indexering gebruikt, waarbij het eerste blad toegankelijk is metsheet_name = 0)# Extracting the second sheet since Python uses 0-indexing df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)JSON-bestand importeren
Vergelijkbaar met de functie
read_csv()kun jeread_json()gebruiken voor JSON-bestanden met de JSON-bestandsnaam als argument (lees voor meer details deze tutorial over JSON- en HTML-data importeren in pandas). Onderstaande code leest een JSON-bestand van schijf en maakt een DataFrame-objectdf.df = pd.read_json("diabetes.json")Wil je meer leren over data importeren met pandas, bekijk dan deze cheat sheet over het importeren van verschillende bestandstypen met Python.
Data importeren uit SQL-databases
Om data uit een relationele database te laden, gebruik je
pd.read_sql()samen met een databaseverbinding.import sqlite3 # Establish a connection to an SQLite database conn = sqlite3.connect("my_database.db") # Read data from a table df = pd.read_sql("SELECT * FROM my_table", conn)Voor grote datasets kun je SQLAlchemy gebruiken om queries te optimaliseren.
Data importeren van een API (JSON-formaat)
Als je data uit een web-API komt, kan pandas die direct lezen met
pd.read_json():df = pd.read_json("https://api.example.com/data.json")Als de API-respons gepagineerd is of in een genest JSON-formaat staat, heb je mogelijk extra verwerking nodig met
json_normalize()uitpandas.io.json.Data exporteren in pandas
Net zoals pandas data uit verschillende bestandstypen kan importeren, kun je ook naar diverse formaten exporteren. Dit is vooral handig wanneer data met pandas is getransformeerd en lokaal moet worden opgeslagen. Hieronder zie je hoe je pandas DataFrames naar verschillende formaten wegschrijft.
Een DataFrame exporteren naar een CSV-bestand
Een pandas DataFrame (hier gebruiken we
df) sla je op als CSV-bestand met de methode.to_csv(). De argumenten omvatten de bestandsnaam met pad enindex– waarbijindex = Trueimpliceert dat de index van het DataFrame wordt weggeschreven.df.to_csv("diabetes_out.csv", index=False)Een DataFrame exporteren naar een JSON-bestand
Exporteer een DataFrame-object naar een JSON-bestand door de methode
.to_json()aan te roepen.df.to_json("diabetes_out.json")Let op: Een JSON-bestand slaat een tabelobject zoals een DataFrame op als key-valueparen. Daardoor zie je in een JSON-bestand herhaalde kolomkoppen.
Een DataFrame exporteren naar een tekstbestand
Zoals bij het schrijven van DataFrames naar CSV-bestanden kun je
.to_csv()aanroepen. De enige verschillen zijn dat het uitvoerformaat.txtis en dat je een scheidingsteken moet opgeven met het argumentsep.df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Een DataFrame exporteren naar een Excel-bestand
Roep
.to_excel()aan op het DataFrame-object om het op te slaan als een“.xls”- of“.xlsx”-bestand.df.to_excel("diabetes_out.xlsx", index=False)DataFrames bekijken en begrijpen met pandas
Nadat je tabeldata als DataFrame hebt ingelezen, wil je snel een indruk krijgen van de data. Je kunt ofwel een kleine steekproef bekijken, of een samenvatting in de vorm van beschrijvende statistieken.
Data bekijken met
.head()en.tail()Je kunt de eerste of laatste rijen van een DataFrame bekijken met respectievelijk de methoden
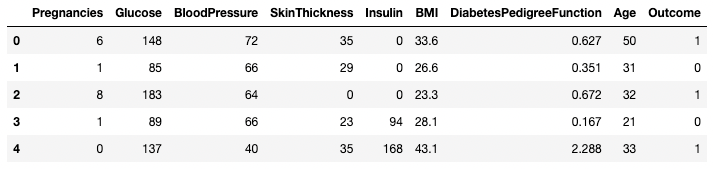
.head()of.tail(). Je kunt het aantal rijen opgeven via het argumentn(de standaardwaarde is 5).df.head()
Eerste vijf rijen van het DataFrame
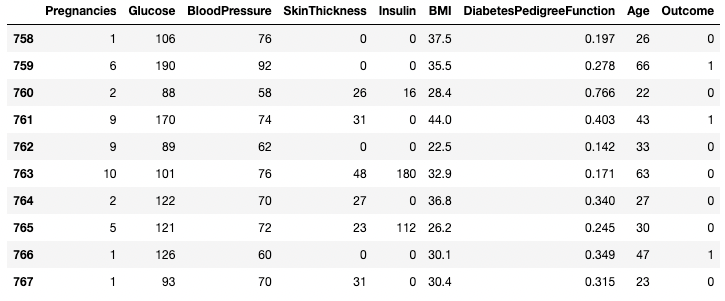
df.tail(n = 10)
Eerste 10 rijen van het DataFrame
Data begrijpen met
.describe()De methode
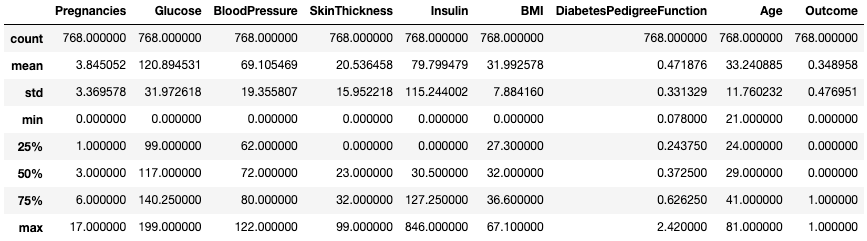
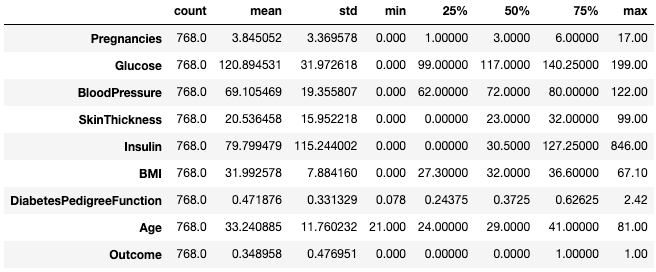
.describe()print de samenvattende statistieken van alle numerieke kolommen, zoals aantal, gemiddelde, standaarddeviatie, bereik en kwartielen van numerieke kolommen.df.describe()
Samenvattende statistieken ophalen met
.describe()Dit geeft snel inzicht in de schaal, scheefheid en het bereik van numerieke data.
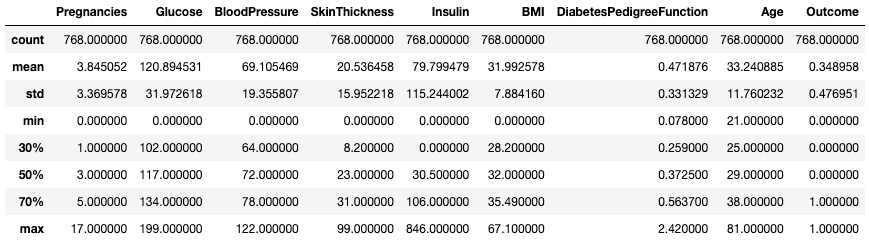
Je kunt de kwartielen ook aanpassen met het argument
percentiles. Hier kijken we bijvoorbeeld naar de 30%, 50% en 70% percentielen van de numerieke kolommen in DataFramedf.df.describe(percentiles=[0.3, 0.5, 0.7])
Samenvattende statistieken met specifieke percentielen
Je kunt ook specifieke datatypen isoleren in je samenvattingsoutput met het argument
include. Hier vatten we bijvoorbeeld alleen de kolommen met het datatypeintegersamen.df.describe(include=[int])
Samenvattende statistieken van alleen integerkolommen
Op dezelfde manier kun je bepaalde datatypen uitsluiten met het argument
exclude.df.describe(exclude=[int])
Samenvattende statistieken van alleen niet-integerkolommen
Vaak vinden practitioners het prettig om zulke statistieken te bekijken door ze te transponeren met het attribuut.T.df.describe().T
Samenvattende statistieken transponeren met
.T
Voor meer over het beschrijven van DataFrames, bekijk de volgende cheat sheet.
De methode .info() is een snelle manier om naar de datatypen, missende waarden en de grootte van een DataFrame te kijken. Hier zetten we het argument show_counts op True, wat een overzicht geeft van het totale aantal niet-missende waarden per kolom. We zetten ook memory_usage op True, wat het totale geheugengebruik van de DataFrame-elementen toont. Wanneer verbose op True staat, print het de volledige samenvatting van .info().
df.info(show_counts=True, memory_usage=True, verbose=True)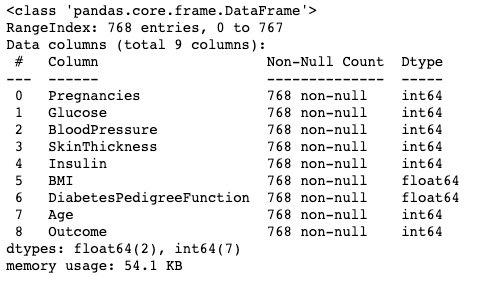
Het aantal rijen en kolommen van een DataFrame kun je achterhalen met het attribuut .shape van het DataFrame. Het retourneert een tuple (rijen, kolommen) en kan worden geïndexeerd om alleen het aantal rijen of alleen het aantal kolommen te krijgen.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Het aanroepen van het attribuut .columns van een DataFrame-object geeft de kolomnamen terug in de vorm van een Index-object. Ter herinnering: een pandas-index is het adres/label van de rij of kolom.
df.columns
Je kunt dit omzetten naar een lijst met de functie list().
list(df.columns)
Het voorbeeld-DataFrame heeft geen missende waarden. Laten we er een paar introduceren om het interessanter te maken. De methode .copy() maakt een kopie van het originele DataFrame. Dit doen we om te zorgen dat wijzigingen in de kopie niet in het origineel terechtkomen. Met .loc (later besproken) kun je rijen twee tot en met vijf van de kolom Pregnancies instellen op NaN-waarden, die missende waarden aanduiden.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)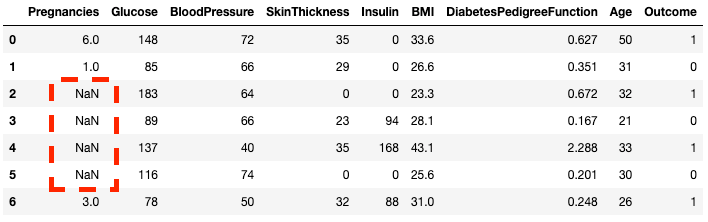
Je ziet dat rijen 2 t/m 5 nu NaN zijn
Je kunt met de methode .isnull() controleren of elk element in een DataFrame ontbreekt.
df2.isnull().head(7)Aangezien het vaak nuttiger is om te weten hoeveel missende data je hebt, kun je .isnull() combineren met .sum() om het aantal nulls per kolom te tellen.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Je kunt ook dubbel sommeren om het totale aantal nulls in het DataFrame te krijgen.
df2.isnull().sum().sum()4Het pandas-pakket biedt verschillende manieren om data in je DataFrames te sorteren, subsetten, filteren en isoleren. Hier behandelen we de meest gangbare manieren.
Om een DataFrame op een specifieke kolom te sorteren:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderJe kunt ook op meerdere kolommen sorteren:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Als je een DataFrame filtert of sorteert, kan je index niet meer oplopen. Gebruik .reset_index() om dit te herstellen:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnOm data op basis van een voorwaarde te extraheren:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100Je kunt één enkele kolom isoleren met een vierkante haak [ ] met daarin een kolomnaam. De output is een pandas-Series-object. Een pandas Series is een eendimensionale array met data van elk type, inclusief integer, float, string, boolean, Python-objecten, enz. Een DataFrame bestaat uit meerdere series die als kolommen fungeren.
df['Outcome']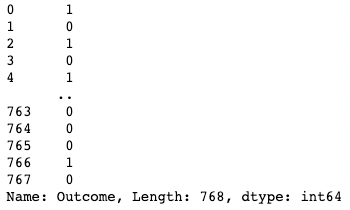
Eén kolom isoleren in pandas
Je kunt ook een lijst met kolomnamen opgeven binnen de vierkante haken om meer dan één kolom op te halen. Hier worden de vierkante haken op twee manieren gebruikt. We gebruiken de buitenste vierkante haken om een subset van een DataFrame aan te geven en de binnenste vierkante haken om een lijst te maken.
df[['Pregnancies', 'Outcome']]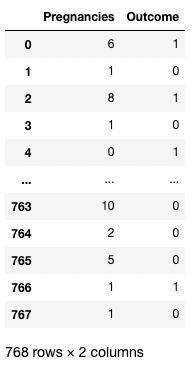
Twee kolommen isoleren in pandas
Een enkele rij kan worden opgehaald door een booleaanse Series met één True-waarde door te geven. In het onderstaande voorbeeld wordt de tweede rij met index = 1 geretourneerd. Hier geeft .index de rijlables van het DataFrame terug en zet de vergelijking dit om in een booleaanse eendimensionale array.
df[df.index==1]
Eén rij isoleren in pandas
Op dezelfde manier kunnen twee of meer rijen worden geretourneerd met de methode .isin() in plaats van een ==-operator.
df[df.index.isin(range(2,10))]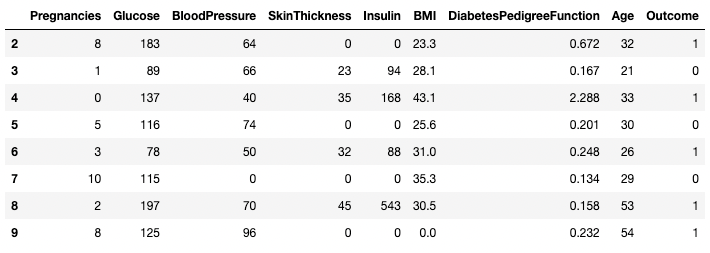
Specifieke rijen isoleren in pandas
Je kunt specifieke rijen ophalen op basis van labels of voorwaarden met .loc[] en .iloc[] ("location" en "integer location"). .loc[] gebruikt een label om naar een rij, kolom of cel te verwijzen, terwijl .iloc[] de numerieke positie gebruikt. Om het verschil tussen beide te begrijpen, passen we de index van het eerder gemaakte df2 aan.
df2.index = range(1,769)Het onderstaande voorbeeld retourneert een pandas-Series in plaats van een DataFrame. De 1 staat voor de rijindex (label), terwijl de 1 in .iloc[] de rijpositie is (eerste rij).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Je kunt ook meerdere rijen ophalen door een bereik in vierkante haken op te geven.
df2.loc[100:110]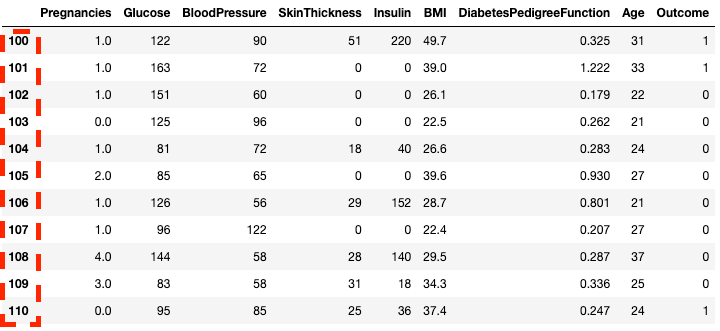
Rijen isoleren in pandas met .loc[]
df2.iloc[100:110]![Isolating rows in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Rijen isoleren in pandas met .iloc[]
Je kunt ook subsetten met .loc[] en .iloc[] met een lijst in plaats van een bereik.
df2.loc[[100, 200, 300]]![Isolating rows using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Rijen isoleren met een lijst in pandas met .loc[]
df2.iloc[[100, 200, 300]]
Rijen isoleren met een lijst in pandas met .iloc[]
Je kunt ook specifieke kolommen selecteren samen met rijen. Hierin verschilt .iloc[] van .loc[] – het vereist kolomlocaties in plaats van kolomlabels.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using a list in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Kolommen isoleren in pandas met .loc[]
df2.iloc[100:110, :3]![Isolating columns using in pandas with .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Kolommen isoleren met .iloc[]
Voor snellere workflows kun je het startindex van een rij als bereik doorgeven.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolating columns using in pandas with .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Kolommen en rijen isoleren in pandas met .loc[]
df2.iloc[760:, :3]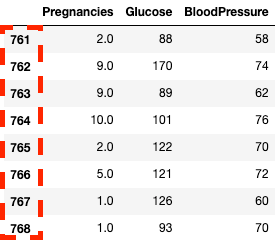
Kolommen en rijen isoleren in pandas met .iloc[]
Je kunt bepaalde waarden bijwerken/wijzigen met de toewijzingsoperator =
df2.loc[df['Age']==81, ['Age']] = 80pandas laat je data filteren op voorwaarden over rij-/kolomwaarden. Zo selecteert de onderstaande code de rij waar de bloeddruk precies 122 is. Hier isoleren we rijen met de haken [ ] zoals in eerdere secties. In plaats van rij-indexen of kolomnamen te gebruiken, geven we echter een voorwaarde mee waarbij de kolom BloodPressure gelijk is aan 122. We geven deze voorwaarde aan met df.BloodPressure == 122.
df[df.BloodPressure == 122]
Rijen isoleren op basis van een voorwaarde in pandas
Het onderstaande voorbeeld haalt alle rijen op waar Outcome 1 is. Hier selecteert df.Outcome die kolom, df.Outcome == 1 retourneert een Series met booleaanse waarden die bepalen welke Outcomes gelijk zijn aan 1, en vervolgens neemt [] een subset van df waar die booleaanse Series True is.
df[df.Outcome == 1]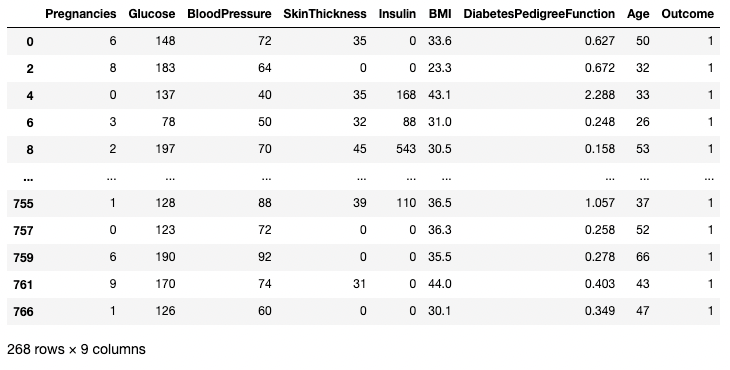
Rijen isoleren op basis van een voorwaarde in pandas
Je kunt een >-operator gebruiken om vergelijkingen te maken. De onderstaande code haalt Pregnancies, Glucose en BloodPressure op voor alle records met BloodPressure groter dan 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]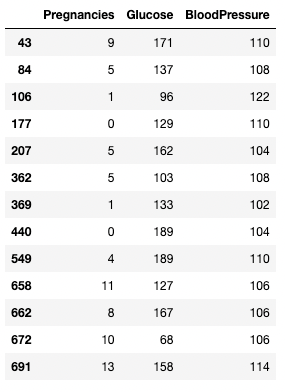
Rijen en kolommen isoleren op basis van een voorwaarde in pandas
Data opschonen is een van de meest voorkomende taken in data science. Met pandas kun je data preprocessen voor elk gebruik, waaronder maar niet beperkt tot het trainen van machine learning- en deep learning-modellen. Laten we het DataFrame df2 van eerder gebruiken, met vier missende waarden, om een paar use cases van data opschonen te illustreren. Ter herinnering: zo zie je hoeveel missende waarden er in een DataFrame staan.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Een manier om met missende data om te gaan is deze te droppen. Dit is vooral nuttig wanneer je veel data hebt en het verlies van een klein deel de vervolganalyse niet beïnvloedt. Je kunt de methode .dropna() gebruiken zoals hieronder. Hier slaan we de resultaten van .dropna() op in een DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2Met het argument axis kun je aangeven of je rijen of kolommen met missende waarden dropt. De standaard axis verwijdert de rijen met NaN's. Gebruik axis = 1 om de kolommen met één of meer NaN-waarden te verwijderen. Merk ook op dat we het argument inplace=True gebruiken, waarmee je kunt overslaan om de output van .dropna() in een nieuw DataFrame op te slaan.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()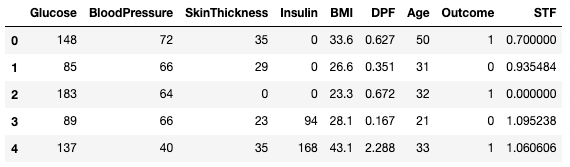
Missende data droppen in pandas
Je kunt ook zowel rijen als kolommen met missende waarden droppen door het argument how op 'all' te zetten
df3 = df2.copy()
df3.dropna(inplace=True, how='all')In plaats van te droppen, kan het vervangen van missende waarden door een samenvattende statistiek of een specifieke waarde (afhankelijk van de use case) de beste aanpak zijn. Als er bijvoorbeeld één missende rij is in een kolom met temperaturen door de week, kan het effectiever zijn om die missende waarde te vervangen door de gemiddelde temperatuur van die week dan om waarden volledig te droppen. Je kunt de missende data vervangen door het rij- of kolomgemiddelde met onderstaande code.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Laten we wat duplicaten toevoegen aan de originele data om te leren hoe je duplicaten verwijdert in een DataFrame. Hier gebruiken we de methode .concat() om de rijen van DataFrame df2 te concatenaten met DataFrame df2, waardoor perfecte duplicaten van elke rij in df2 worden toegevoegd.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Je kunt alle dubbele rijen (standaard) uit het DataFrame verwijderen met de methode .drop_duplicates().
df3 = df3.drop_duplicates()
df3.shape(768, 9)Een veelvoorkomende opschonentaak is het hernoemen van kolommen. Met de methode .rename() kun je columns als argument gebruiken om specifieke kolommen te hernoemen. De onderstaande code toont de dictionary voor het mappen van oude en nieuwe kolomnamen.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()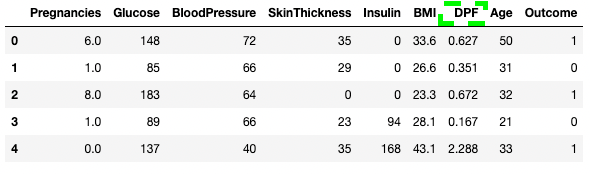
Kolommen hernoemen in pandas
Je kunt ook kolomnamen direct als lijst toewijzen aan het DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()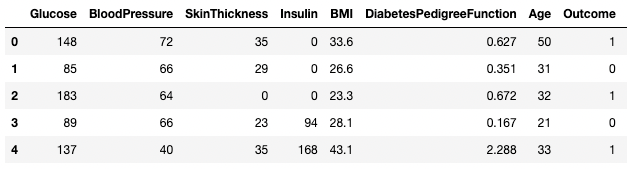
Kolommen hernoemen in pandas
Voor meer over data opschonen en voor eenvoudiger, voorspelbaardere opschoningsworkflows bekijk je de volgende checklist, die je een uitgebreide set veelvoorkomende opschoningtaken biedt.
De belangrijkste waardepropositie van pandas ligt in de snelle data-analysemogelijkheden. In deze sectie focussen we op een set analysetechnieken die je in pandas kunt gebruiken.
Zoals je eerder zag, kun je het gemiddelde van elke kolomwaarde krijgen met de methode .mean().
df.mean()
Het gemiddelde van kolommen printen in pandas
De modus kan op vergelijkbare wijze worden berekend met de methode .mode().
df.mode()
De modus van kolommen printen in pandas
Evenzo wordt de mediaan van elke kolom berekend met de methode .median()
df.median()
De mediaan van kolommen printen in pandas
pandas biedt snelle en efficiënte berekeningen door twee of meer kolommen te combineren zoals scalairen. De onderstaande code deelt elke waarde in de kolom Glucose door de corresponderende waarde in de kolom Insulin om een nieuwe kolom Glucose_Insulin_Ratio te berekenen.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Een nieuwe kolom maken op basis van bestaande kolommen in pandas
Vaak werk je met categorische waarden en wil je het aantal observaties per categorie in een kolom tellen. Categoriewaarden kunnen worden geteld met de methode .value_counts(). Hier tellen we bijvoorbeeld het aantal observaties waar Outcome diabetisch (1) is en het aantal observaties waar Outcome niet-diabetisch (0) is.
df['Outcome'].value_counts()
.value_counts() gebruiken in pandas
Met het argument normalize krijg je verhoudingen in plaats van absolute aantallen.
df['Outcome'].value_counts(normalize=True)
.value_counts() gebruiken in pandas met normalisatie
Schakel het automatisch sorteren van resultaten uit met het argument sort (True standaard). De standaard sortering is op de aantallen in aflopende volgorde.
df['Outcome'].value_counts(sort=False)
.value_counts() gebruiken in pandas met sorteren
Je kunt .value_counts() ook toepassen op een DataFrame-object en specifieke kolommen daarin in plaats van slechts op één kolom. Hier passen we bijvoorbeeld value_counts() toe op df met het subset-argument, dat een lijst met kolommen verwacht.
df.value_counts(subset=['Pregnancies', 'Outcome'])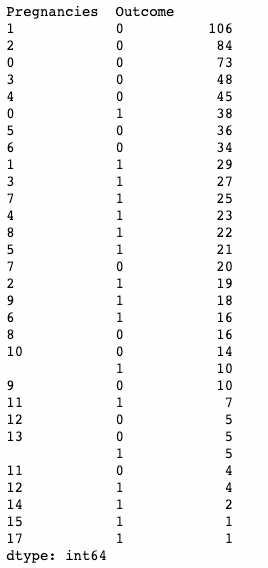
.value_counts() gebruiken in pandas terwijl je kolommen subset
pandas laat je waarden aggregeren door ze te groeperen op specifieke kolomwaarden. Dat doe je door de methode .groupby() te combineren met een samenvattingsmethode naar keuze. De onderstaande code toont het gemiddelde van elk van de numerieke kolommen, gegroepeerd op Outcome.
df.groupby('Outcome').mean()
Data aggregeren op één kolom in pandas
.groupby() maakt groeperen op meer dan één kolom mogelijk door een lijst met kolomnamen door te geven, zoals hieronder.
df.groupby(['Pregnancies', 'Outcome']).mean()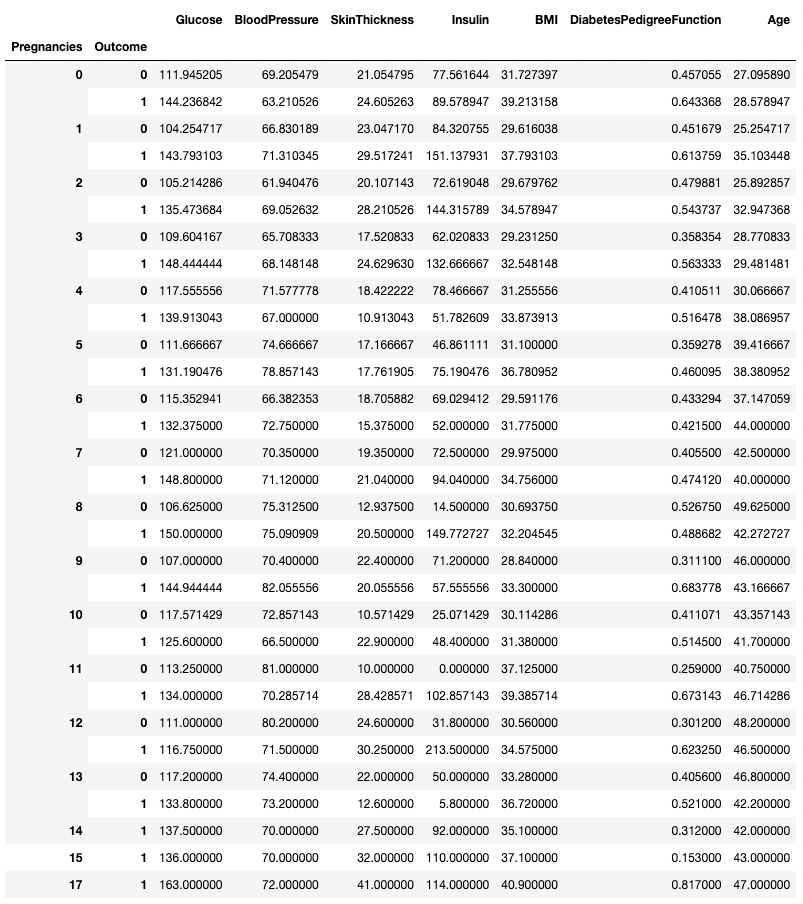
Data aggregeren op twee kolommen in pandas
Elke samenvattingsmethode kan naast .groupby() worden gebruikt, waaronder .min(), .max(), .mean(), .median(), .sum(), .mode() en meer.
pandas stelt je ook in staat om samenvattende statistieken als draaitabellen te berekenen. Dit maakt het eenvoudig om conclusies te trekken op basis van een combinatie van variabelen. De onderstaande code kiest de rijen als unieke waarden van Pregnancies, de kolommen als de unieke waarden van Outcome en de cellen bevatten de gemiddelde waarde van BMI in de overeenkomstige groep.
Voorbeeld: voor Pregnancies = 5 en Outcome = 0 blijkt de gemiddelde BMI 31,1 te zijn.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc='mean')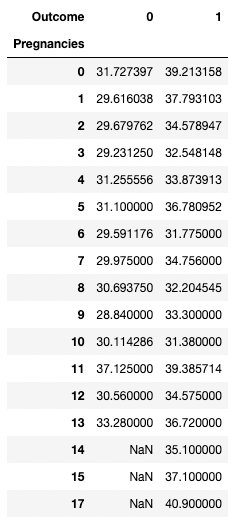
Data aggregeren door te pivotten met pandas
pandas biedt handige wrappers rond Matplotlib-plotfuncties om het eenvoudig te maken je DataFrames te visualiseren. Hieronder zie je hoe je veelvoorkomende visualisaties maakt met pandas.
pandas stelt je in staat relaties tussen variabelen te plotten met lijngrafieken. Hieronder staat een lijngrafiek van BMI en Glucose ten opzichte van de rij-index.
df[['BMI', 'Glucose']].plot.line()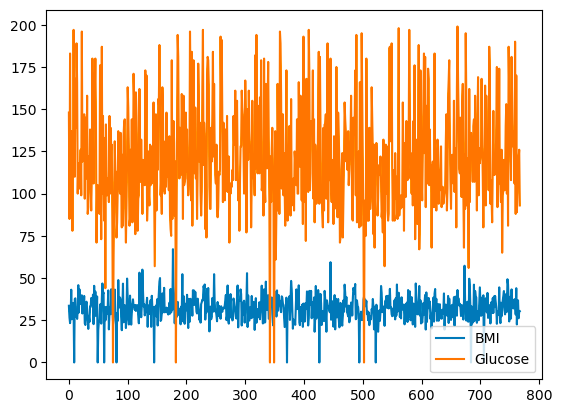
Eenvoudige lijngrafiek met pandas
Je kunt de kleurkeuze instellen met het argument color.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})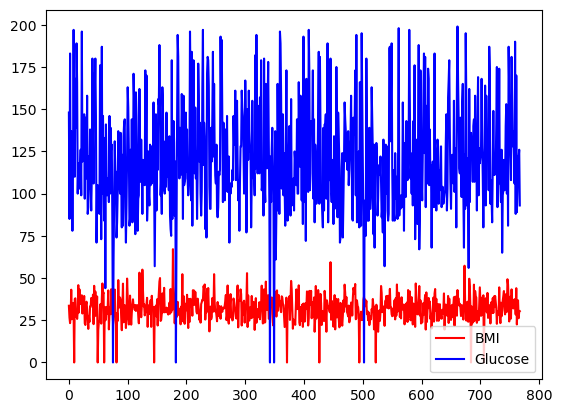
Eenvoudige lijngrafiek met pandas, met aangepaste kleuren
Alle kolommen van df kunnen ook op verschillende schalen en assen worden geplot met het argument subplots.
df.plot.line(subplots=True)
Subplots voor lijngrafieken met pandas
Voor discrete kolommen kun je een staafdiagram gebruiken over de categorieaantallen om hun verdeling te visualiseren. De variabele Outcome met binaire waarden is hieronder gevisualiseerd.
df['Outcome'].value_counts().plot.bar()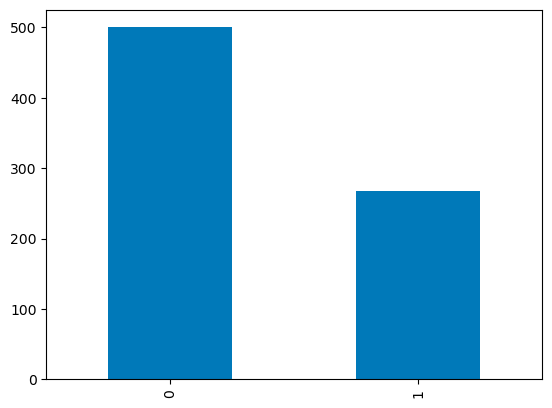
Staafdiagrammen in pandas
De kwartielverdeling van continue variabelen kun je visualiseren met een boxplot. De onderstaande code laat zien hoe je met pandas een boxplot maakt.
df.boxplot(column=['BMI'], by='Outcome')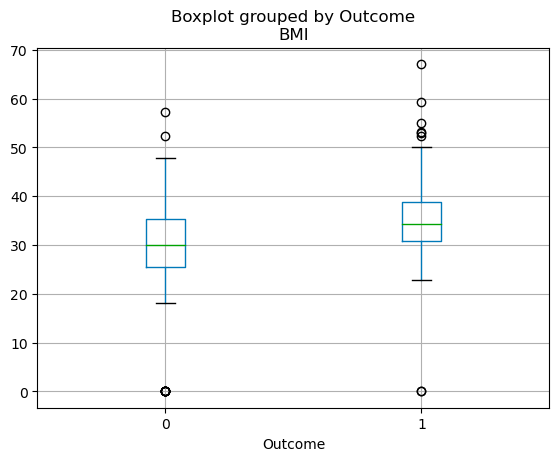
Boxplots in pandas
De bovenstaande tutorial raakt slechts de oppervlakte van wat mogelijk is met pandas. Of je nu data analyseert, visualiseert, filtert of aggregeert, pandas biedt een ongelooflijk rijke feature set waarmee je elke dataworkflow kunt versnellen. Bovendien kun je door pandas te combineren met andere datawetenschapspakketten interactieve dashboards maken, voorspellende modellen bouwen met machine learning, dataworkflows automatiseren en meer. Bekijk de onderstaande bronnen om je pandas-leertraject te versnellen:
Meer pandas-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min

