
Corso
Prompt Engineering con l'API di OpenAI
4 h
49.9K
GPT-5.2 è un modello potente per generare workflow e pipeline multi-step che richiedono affidabilità, struttura e meno allucinazioni. OpenAI ha evidenziato miglioramenti nel lavoro su contesti lunghi e prestazioni ancora migliori su attività in stile foglio di calcolo.
In questo tutorial, costruiremo un'app Streamlit che si comporta come un junior analyst:
La chiave è che GPT-5.2 non “crea le slide” direttamente. Genera un piano rigoroso che il tuo codice esegue in modo deterministico.
Leggi anche le nostre guide sui modelli più recenti di OpenAI, GPT-5.5, GPT-5.4, GPT-5.3 Codex e GPT-5.3 Instant
GPT-5.2 è il nuovo modello della serie GPT-5 di OpenAI con miglioramenti per attività end-to-end come creare fogli di calcolo, costruire presentazioni, scrivere e fare debug del codice, comprendere contesti lunghi e usare strumenti.
Ecco le proprietà di GPT-5.2 più rilevanti per questo progetto:
In questa sezione, costruiremo un generatore di artifact strutturati (Excel e PowerPoint) usando il modello GPT 5.2 all’interno di un’app Streamlit. A grandi linee, l’app finale fa questo:
Legge un CSV e costruisce un workbook canonico
Poi chiama GPT-5.2 tramite OpenAI o OpenRouter con Structured Outputs (response_format: json_schema)
Convalida il piano restituito rispetto al nostro schema
Renderizza i grafici in Excel e li stilizza con la nostra palette di brand
Infine, genera un PowerPoint con grafici incorporati e citazioni
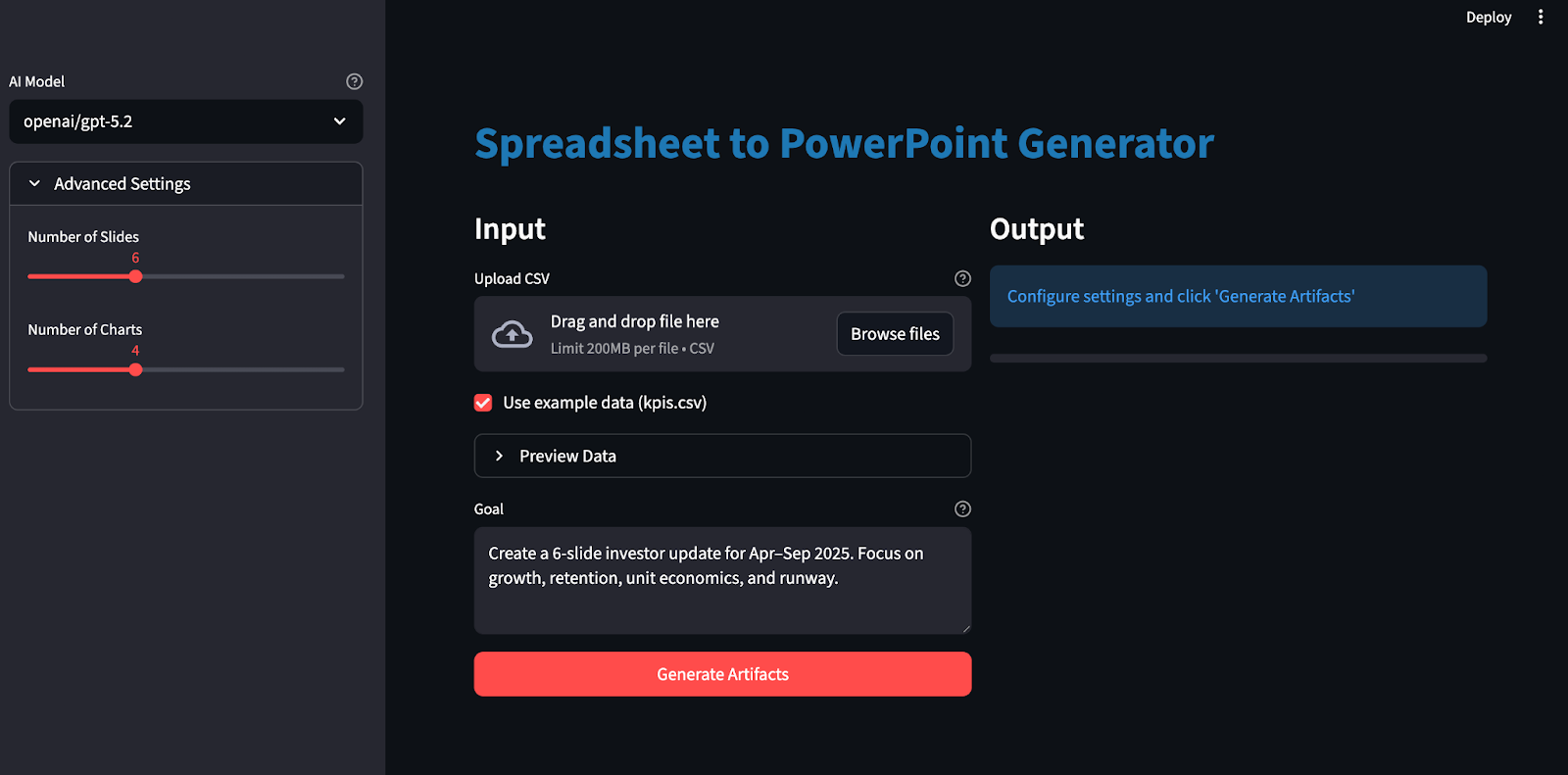
Costruiamolo passo dopo passo.
Prima di generare file Excel e presentazioni PowerPoint con GPT-5.2, dobbiamo configurare un ambiente locale. Partiremo installando le librerie core e impostando le chiavi API come variabili d’ambiente.
pip install streamlit pandas pydantic python-dotenv requests openpyxl python-pptxUseremo Streamlit per costruire l’interfaccia web interattiva, Pandas per caricare e preparare il CSV, Pydantic per convalidare il piano JSON con schema bloccato di GPT-5.2. Usiamo anche python-dotenv per caricare in sicurezza chiavi come OPENROUTER_API_KEY/OPENAI_API_KEY da un file .env. La libreria requests chiama l’endpoint compatibile OpenRouter/OpenAI, mentre openpyxl genera il file Excel e i grafici, e python-pptx crea la presentazione PowerPoint con grafici nativi (modificabili).
Poi impostiamo le nostre chiavi API:
export OPENAI_API_KEY="your_key"
export OPENROUTER_API_KEY="your_key"Nota che GPT 5.2 è accessibile tramite più servizi, inclusa l’API ufficiale di OpenAI oltre a servizi come OpenRouter e altri.
Si raccomanda di usare un file .env per archiviare localmente le chiavi API:
Nel file .env, salva quanto segue:
OPENROUTER_API_KEY="your_key"
OPENAI_API_KEY="your_key"Poi carica queste chiavi API usando la libreria load_dotenv:
from dotenv import load_dotenv
load_dotenv()A questo punto, il nostro ambiente è pronto per l’autenticazione con l’API di OpenAI.
Ora definiamo un artifact plan con schema bloccato, ovvero un rigoroso blueprint JSON che dice a GPT-5.2 esattamente quali grafici creare e come strutturare le slide, così l’output del modello può essere decodificato e convalidato usando Structured Outputs tramite response_format: { type: "json_schema", strict: true } invece di testo libero.
import os
import io
import re
import json
import math
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import Dict, List, Literal, Optional, Tuple
import requests
import pandas as pd
import numpy as np
import streamlit as st
import openpyxl
from dotenv import load_dotenv
from pydantic import BaseModel, Field, ValidationError
from openpyxl import Workbook, load_workbook
from openpyxl.styles import Font, Alignment, PatternFill
from openpyxl.utils import get_column_letter
from openpyxl.chart import LineChart, BarChart, Reference
from openpyxl.chart.series import SeriesLabel
from pptx import Presentation
from pptx.util import Inches, Pt
from pptx.chart.data import CategoryChartData
from pptx.enum.chart import XL_CHART_TYPE, XL_LEGEND_POSITION
ChartKind = Literal["line", "bar"]
def safe_float(x) -> float:
try:
if x is None:
return 0.0
if isinstance(x, (int, float)):
return float(x)
return float(str(x).replace(",", "").replace("$", ""))
except Exception:
return 0.0
def fmt_money(v: float) -> str:
sign = "-" if v < 0 else ""
v = abs(v)
if v >= 1_000_000:
return f"{sign}${v/1_000_000:.2f}M"
if v >= 1_000:
return f"{sign}${v/1_000:.1f}K"
return f"{sign}${v:.0f}"
def fmt_pct(v: float) -> str:
if v is None or (isinstance(v, float) and (math.isnan(v) or math.isinf(v))):
return "n/a"
return f"{v*100:.1f}%"
class ChartSeriesSpec(BaseModel):
name: str
metric: str
class ChartSpec(BaseModel):
id: str
kind: ChartKind
title: str
x_metric: str
series: List[ChartSeriesSpec]
anchor: str
class SlideBullet(BaseModel):
text: str
citations: List[str] = Field(min_length=1, max_length=4)
class SlideSpec(BaseModel):
title: str
chart_id: Optional[str] = None
bullets: List[SlideBullet] = Field(min_length=2, max_length=4)
class ArtifactPlan(BaseModel):
charts: List[ChartSpec] = Field(min_length=3, max_length=6)
slides: List[SlideSpec] = Field(min_length=4, max_length=10)Il codice sopra definisce il piano con modelli Pydantic, che fanno tre cose importanti:
Struttura del piano: ChartKind = Literal["line", "bar"] limita i tipi di grafico a un piccolo enum, ChartSpec cattura il contratto completo del grafico e SlideSpec definisce il layout della slide collegando opzionalmente una slide a un grafico tramite chart_id.
Garanzia di qualità automatica: I vincoli come Field() garantiscono che otteniamo sempre abbastanza grafici/slide, che ogni slide abbia abbastanza punti elenco e che ogni bullet includa citazioni.
Pianificazione e rendering: GPT-5.2 produce solo il blueprint, cioè grafici, slide e citazioni, come JSON strutturato, mentre il resto del codice gestisce l’esecuzione, la formattazione in Excel, il rendering dei grafici e il layout del deck.
Con questo schema in atto, GPT-5.2 diventa un planner che produce un blueprint JSON validato.
Definito lo schema del piano, la prossima mossa è chiamare GPT-5.2 in “schema mode”— così restituisce un blueprint JSON che puoi convalidare ed eseguire. Invece di sperare che il modello “si comporti”, diciamo all’API di decodificare direttamente nel tuo JSON Schema usando response_format: { type: "json_schema", ... strict: true }, che è esattamente lo scopo degli Structured Outputs.
def chat_json_schema(
model: str,
messages: list,
json_schema: dict,
api_key: str,
temperature: float = 0.2,
max_tokens: int = 6000,
timeout_s: int = 120,
api_provider: Optional[str] = None,
) -> dict:
if api_provider is None:
if "/" in model:
api_provider = "openrouter"
elif os.getenv("OPENAI_API_KEY") and api_key == os.getenv("OPENAI_API_KEY"):
api_provider = "openai"
elif os.getenv("OPENROUTER_API_KEY") and api_key == os.getenv("OPENROUTER_API_KEY"):
api_provider = "openrouter"
else:
api_provider = "openrouter"
if api_provider == "openai":
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
if "/" in model:
model = model.split("/", 1)[1]
else:
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
if os.getenv("OPENROUTER_SITE_URL"):
headers["HTTP-Referer"] = os.getenv("OPENROUTER_SITE_URL")
if os.getenv("OPENROUTER_APP_NAME"):
headers["X-Title"] = os.getenv("OPENROUTER_APP_NAME")
payload = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "artifact_plan",
"strict": True,
"schema": json_schema,
},
},
}
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=timeout_s)
r.raise_for_status()
data = r.json()
if "error" in data:
provider_name = "OpenAI" if api_provider == "openai" else "OpenRouter"
raise RuntimeError(f"{provider_name} error: {data['error']}")
finish_reason = data["choices"][0].get("finish_reason")
if finish_reason == "length":
raise RuntimeError("Model output truncated (max_tokens). Increase max_tokens or reduce schema size.")
content = data["choices"][0]["message"]["content"]
if isinstance(content, dict):
return content
try:
return json.loads(content)
except json.JSONDecodeError as e:
preview = (content or "")[:800]
raise RuntimeError(f"Failed to parse JSON. Preview:\n{preview}") from eLa funzione chat_json_schema() è l’unico gateway che trasforma i prompt in un piano validato:
Instradamento del provider (OpenRouter vs OpenAI): Se il nome del modello è namespaced (openai/gpt-5.2), per default usi OpenRouter perché è il formato che OpenRouter usa per il routing dei modelli. Se imposti esplicitamente api_provider="openai", invii lo stesso payload Chat Completions all’endpoint di OpenAI. Puoi anche ignorare completamente OpenRouter.
Impostazione degli endpoint: Per OpenAI, chiami l’endpoint https://api.openai.com/v1/chat/completions con autenticazione Bearer standard. Per OpenRouter, chiami l’endpoint https://openrouter.ai/api/v1/chat/completions e includi facoltativamente header di attribuzione come HTTP-Referer e X-Title, che OpenRouter documenta come metadati consigliati.
Decodifica tramite response_format: Il blocco chiave del payload è response_format: { type: "json_schema", json_schema: { strict: true, schema: ... } }, che istruisce il modello a produrre output limitato al nostro JSON Schema.
Poi convalidiamo il piano JSON del modello con Pydantic e, solo se supera i controlli, procediamo a renderizzare i grafici in Excel e a generare il deck PowerPoint.
Prima di renderizzare qualsiasi cosa, ci serve un piccolo livello che renda qualsiasi CSV caricato sicuro da analizzare e coerente da referenziare. Queste funzioni helper svolgono quattro compiti: caricare e pulire il CSV, creare una tabella modello derivata, calcolare un set compatto di fatti per il prompt e rendere l’output Excel leggibile con colonne auto-dimensionate.
GPT 5.2 non può pianificare in modo affidabile grafici e slide se la tabella di input è vuota o se i campi numerici sono memorizzati come stringhe. Questa funzione standardizza il dataset così i passaggi a valle non devono indovinare.
def load_and_validate_csv(csv_path: str) -> pd.DataFrame:
df = pd.read_csv(csv_path)
if len(df) == 0:
raise ValueError("CSV is empty")
if len(df.columns) == 0:
raise ValueError("CSV has no columns")
date_cols = [c for c in df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
if date_cols:
date_col = date_cols[0]
df[date_col] = df[date_col].astype(str)
for col in df.columns:
if col not in date_cols:
try:
df[col] = pd.to_numeric(df[col])
if df[col].dtype in ['float64', 'int64']:
df[col] = df[col].fillna(0)
except (ValueError, TypeError):
pass
return dfLa funzione sopra:
pd.read_csv.pd.to_numeric e riempie i valori mancanti con zero per evitare cascate di NaN più avanti. Alla fine di questo passaggio, hai un DataFrame non vuoto con colonne numeriche.
I CSV grezzi sono disordinati e incoerenti tra i domini. Il foglio modello funge da livello di normalizzazione in cui aggiungiamo metriche derivate utili per i grafici, senza richiedere all’utente di calcolarle manualmente.
def compute_model_df(raw_df: pd.DataFrame) -> pd.DataFrame:
df = raw_df.copy()
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
if "new_mrr" in df.columns and "churned_mrr" in df.columns:
df["net_new_mrr"] = df["new_mrr"] - df["churned_mrr"]
revenue_cols = [c for c in df.columns if any(x in c.lower() for x in ['revenue', 'mrr', 'income', 'sales'])]
cost_cols = [c for c in df.columns if any(x in c.lower() for x in ['cost', 'cogs', 'expense'])]
if revenue_cols and cost_cols:
revenue = df[revenue_cols[0]]
cost = df[cost_cols[0]]
df["gross_margin"] = ((revenue - cost) / revenue.replace(0, pd.NA)).fillna(0)
for col in numeric_cols[:5]:
if col not in df.columns:
continue
df[f"{col}_change"] = df[col].pct_change().fillna(0)
return dfLa funzione compute_model_df() fa due cose ampiamente utili:
Cerca una colonna di output primaria e una colonna di input secondaria e calcola un rapporto semplice per catturare quanta parte del segnale primario resta dopo aver considerato il segnale secondario.
Per un sottoinsieme di colonne numeriche, calcola pct_change(), che per impostazione predefinita restituisce la variazione fra una riga e la precedente, fornendo una base semplice per catturare il movimento in qualsiasi metrica di serie temporale.
Anche con gli Structured Outputs, vogliamo comunque dare a GPT-5.2 un riepilogo compatto di ciò che è cambiato nel periodo. Questi fatti funzionano anche come prompt che il modello può riutilizzare nei bullet delle slide.
def compute_facts(model_df: pd.DataFrame) -> Dict[str, str]:
def delta(a: float, b: float) -> float:
return 0.0 if a == 0 else (b - a) / a
if len(model_df) == 0:
return {"error": "No data"}
first = model_df.iloc[0]
last = model_df.iloc[-1]
date_cols = [c for c in model_df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
period_col = date_cols[0] if date_cols else model_df.columns[0]
facts = {
"period": f"{first[period_col]} → {last[period_col]}",
"row_count": len(model_df),
"column_count": len(model_df.columns),
}
numeric_cols = model_df.select_dtypes(include=[np.number]).columns.tolist()
for i, col in enumerate(numeric_cols[:5]):
if col in first.index and col in last.index:
start_val = safe_float(first[col])
end_val = safe_float(last[col])
avg_val = safe_float(model_df[col].mean())
facts[f"{col}_start"] = fmt_money(start_val) if start_val >= 100 else f"{start_val:.2f}"
facts[f"{col}_end"] = fmt_money(end_val) if end_val >= 100 else f"{end_val:.2f}"
facts[f"{col}_change_pct"] = fmt_pct(delta(start_val, end_val))
facts[f"{col}_avg"] = fmt_money(avg_val) if avg_val >= 100 else f"{avg_val:.2f}"
return factsPrima scegliamo la prima e l’ultima riga per definire la finestra del periodo. Poi selezioniamo una colonna (date, month, week, period) per un resoconto leggibile.
Per un piccolo set di colonne numeriche, calcoliamo un’istantanea di inizio, fine, media e variazione percentuale complessiva dall’inizio alla fine. Questo produce un dizionario leggero di segnali che aiuta il modello a scrivere i bullet delle slide.
Le larghezze predefinite delle colonne in Excel rendono i workbook generati grezzi. L’auto-dimensionamento è un semplice tocco di polish che migliora subito l’usabilità.
def autosize_columns(ws, max_width: int = 45):
for col in ws.columns:
max_len = 0
col_letter = get_column_letter(col[0].column)
for cell in col:
if cell.value is None:
continue
max_len = max(max_len, len(str(cell.value)))
ws.column_dimensions[col_letter].width = min(max_len + 2, max_width)La funzione autosize_columns() scansiona ogni colonna, trova la lunghezza massima della stringa e imposta ws.column_dimensions[col_letter].width. OpenPyXL espone column_dimensions e la relativa proprietà width per controllare la larghezza di visualizzazione in Excel.
Ora colleghiamo la tabella modello pulita e i fatti al prompt di pianificazione di GPT-5.2, convalidiamo il piano restituito e poi renderizziamo grafici e slide.
Usando la tabella modello pulita e i fatti di riepilogo del passaggio precedente, ora generiamo un workbook Excel deterministico con openpyxl.
def build_workbook_base(raw_df: pd.DataFrame, model_df: pd.DataFrame, out_xlsx: str) -> Tuple[str, int]:
wb = Workbook()
wb.remove(wb.active)
header_fill = PatternFill("solid", fgColor="F2F2F2")
header_font = Font(bold=True)
ws_raw = wb.create_sheet("Raw")
for j, col in enumerate(raw_df.columns, start=1):
c = ws_raw.cell(row=1, column=j, value=col)
c.font = header_font
c.fill = header_fill
c.alignment = Alignment(horizontal="center", vertical="center")
for i, row in enumerate(raw_df.itertuples(index=False), start=2):
for j, val in enumerate(row, start=1):
ws_raw.cell(row=i, column=j, value=val)
ws_raw.freeze_panes = "A2"
autosize_columns(ws_raw)
row_end = 1 + len(raw_df)
ws_model = wb.create_sheet("Model")
for j, col in enumerate(model_df.columns, start=1):
c = ws_model.cell(row=1, column=j, value=col)
c.font = header_font
c.fill = header_fill
c.alignment = Alignment(horizontal="center", vertical="center")
for i, row in enumerate(model_df.itertuples(index=False), start=2):
for j, val in enumerate(row, start=1):
ws_model.cell(row=i, column=j, value=val)
ws_model.freeze_panes = "A2"
autosize_columns(ws_model)
col_index = {name: idx + 1 for idx, name in enumerate(model_df.columns)}
money_keywords = ['mrr', 'revenue', 'income', 'sales', 'cost', 'expense', 'cash', 'balance', 'burn', 'price', 'amount', 'fee']
pct_keywords = ['margin', 'rate', 'ratio', 'pct', 'percent', 'change', 'growth']
for col_name, col_idx in col_index.items():
col_lower = col_name.lower()
is_money = any(kw in col_lower for kw in money_keywords)
is_pct = any(kw in col_lower for kw in pct_keywords) or 'margin' in col_lower
is_large_number = False
if col_name in model_df.columns:
sample_vals = model_df[col_name].dropna()
if len(sample_vals) > 0 and pd.api.types.is_numeric_dtype(sample_vals):
max_val = abs(sample_vals.max())
is_large_number = max_val > 1000
for r in range(2, row_end + 1):
if is_money or is_large_number:
ws_model.cell(row=r, column=col_idx).number_format = "$#,##0"
elif is_pct:
ws_model.cell(row=r, column=col_idx).number_format = "0.0%"
elif pd.api.types.is_numeric_dtype(model_df[col_name]):
ws_model.cell(row=r, column=col_idx).number_format = "0.0"
ws_charts = wb.create_sheet("Charts")
ws_charts["A1"] = "Charts"
ws_charts["A1"].font = Font(bold=True)
wb.save(out_xlsx)
return out_xlsx, row_endEcco cosa fa questo builder del workbook:
Crea lo scheletro del workbook: Workbook() istanzia un nuovo oggetto workbook, poi wb.remove(wb.active) rimuove il foglio predefinito così controlliamo completamente l’ordine. I nuovi fogli vengono aggiunti esplicitamente con wb.create_sheet("Raw"), wb.create_sheet("Model") e wb.create_sheet("Charts").
Scrive il foglio Raw: Scriviamo una riga di intestazione usando Font, PatternFill e Alignment, poi aggiungiamo ogni riga da raw_df. La funzione autosize_columns(ws_raw) migliora la leggibilità senza ridimensionamenti manuali.
Calcola i limiti: Usiamo row_end = 1 + len(raw_df), che ci dà un’ultima riga stabile per generare intervalli come A2:A{row_end} per categorie dei grafici e citazioni.
Applica euristiche di formattazione numerica: Poi impostiamo il cell.number_format in base alle parole chiave nel nome colonna e al dtype, così Excel mostra valori come valuta, percentuali o numeri semplici.
Crea un foglio Charts: La creazione di wb.create_sheet("Charts") ci dà una tela stabile per gli anchor dei grafici. Questo si allinea al workflow di openpyxl: creiamo un LineChart o BarChart, colleghiamo gli intervalli tramite Reference, impostiamo le categorie con set_categories e poi lo posizioniamo con ws.add_chart().
Dopo questo passaggio, hai un file Excel coerente che la fase successiva può referenziare in sicurezza con intervalli di celle esatti.
Passo 6: Renderizza i grafici
Ora che la struttura del workbook è fissa, possiamo renderizzare i grafici nel foglio Charts e applicare un look coerente con il brand. Ho applicato la palette colori di DataCamp con:
def add_charts_to_workbook(xlsx_path: str, charts: List[ChartSpec], metric_to_range: Dict[str, str]):
wb = load_workbook(xlsx_path)
ws_model = wb["Model"]
ws_charts = wb["Charts"]
header_map = {ws_model.cell(1, c).value: c for c in range(1, ws_model.max_column + 1)}
def ref_from_metric(metric: str, row_start: int, row_end: int) -> Reference:
if metric not in header_map:
raise ValueError(f"Unknown metric in Model sheet: {metric}")
col = header_map[metric]
return Reference(ws_model, min_col=col, min_row=row_start, max_col=col, max_row=row_end)
for ch in charts:
chart = LineChart() if ch.kind == "line" else BarChart()
chart.title = ch.title
x_metric = ch.x_metric
if x_metric not in header_map:
date_keywords = ['date', 'time', 'month', 'year', 'period', 'week']
date_cols = [col for col in header_map.keys() if col and any(kw in str(col).lower() for kw in date_keywords)]
if date_cols:
x_metric = date_cols[0]
else:
x_metric = list(header_map.keys())[0] if header_map else "month"
x_ref = ref_from_metric(x_metric, 2, ws_model.max_row)
chart.set_categories(x_ref)
chart_colors = ["01EF63", "203147"]
for i, s in enumerate(ch.series):
y_ref = ref_from_metric(s.metric, 2, ws_model.max_row)
chart.add_data(y_ref, titles_from_data=False)
chart.series[-1].title = SeriesLabel(v=s.name)
series = chart.series[-1]
color_hex = chart_colors[i % len(chart_colors)]
try:
if ch.kind == "line":
series.graphicalProperties.line.solidFill = color_hex
series.graphicalProperties.line.width = 30000
else:
series.graphicalProperties.solidFill = color_hex
except AttributeError:
pass
anchor = ch.anchor.strip()
if "!" in anchor:
anchor = anchor.split("!")[-1]
if anchor and anchor.isalpha():
anchor = f"{anchor}2"
if not re.match(r'^[A-Z]+[0-9]+La funzione add_charts_to_workbook() è il motore di rendering dei grafici che trasforma il nostro schema in visual Excel brandizzati.
Carica il workbook: iniziamo aprendo il file Excel generato con load_workbook(xlsx_path). Poi costruiamo una header_map dalla prima riga, mappando ogni nome colonna al suo indice di colonna Excel.
Crea i riferimenti agli intervalli: la funzione Reference() definisce l’intervallo esatto da tracciare e chart.set_categories(x_ref) collega le categorie dell’asse X. Il pattern standard è creare gli oggetti di riferimento, aggiungere i dati e poi impostare le categorie.
Istanzia il tipo di grafico: per ogni specifica, creiamo un LineChart() o un BarChart(), e impostiamo il chart.title.
Aggiungi la palette del brand: per ogni serie nella specifica, colleghiamo l’intervallo Y con chart.add_data(), poi impostiamo l’etichetta di visualizzazione usando SeriesLabel().
Infine, la funzione ws_charts.add_chart() posiziona ogni grafico a una cella specifica in alto a sinistra.
Qui il piano diventa un vero deck di slide. Creiamo un PowerPoint, disponiamo titoli e bullet, incorporiamo grafici costruiti dalla stessa tabella usata per Excel e aggiungiamo un footer che preserva le citazioni degli intervalli di celle del piano.
def build_pptx(out_pptx: str, model_df: pd.DataFrame, plan: ArtifactPlan):
prs = Presentation()
blank = prs.slide_layouts[6]
chart_by_id = {c.id: c for c in plan.charts}
def add_title(slide, title: str):
box = slide.shapes.add_textbox(Inches(0.5), Inches(0.2), Inches(9.0), Inches(0.6))
tf = box.text_frame
tf.clear()
p = tf.paragraphs[0]
p.text = title
p.font.size = Pt(32)
p.font.bold = True
def add_bullets(slide, bullets: List[SlideBullet], left, top, width, height):
box = slide.shapes.add_textbox(left, top, width, height)
tf = box.text_frame
tf.word_wrap = True
tf.clear()
for i, b in enumerate(bullets):
p = tf.paragraphs[0] if i == 0 else tf.add_paragraph()
p.text = b.text
p.font.size = Pt(18)
p.level = 0
p.space_before = Pt(4)
p.space_after = Pt(8)
def add_sources_footer(slide, bullets: List[SlideBullet]):
sources = []
seen = set()
for b in bullets:
for c in b.citations:
if c not in seen:
seen.add(c)
sources.append(c)
if not sources:
return
text = "Sources: " + "; ".join(sources)
box = slide.shapes.add_textbox(Inches(0.5), Inches(6.8), Inches(9.0), Inches(0.4))
tf = box.text_frame
tf.clear()
p = tf.paragraphs[0]
p.text = text
p.font.size = Pt(9)
p.font.italic = True
def add_chart(slide, chart_spec: ChartSpec, left, top, width, height):
date_cols = [c for c in model_df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
x_col = date_cols[0] if date_cols else model_df.columns[0]
categories = model_df[x_col].astype(str).tolist()
chart_data = CategoryChartData()
chart_data.categories = categories
chart_colors = ["01EF63", "203147"]
for i, s in enumerate(chart_spec.series):
values = model_df[s.metric].apply(safe_float).tolist()
chart_data.add_series(s.name, values)
chart_type = XL_CHART_TYPE.LINE if chart_spec.kind == "line" else XL_CHART_TYPE.COLUMN_CLUSTERED
graphic_frame = slide.shapes.add_chart(chart_type, left, top, width, height, chart_data)
chart = graphic_frame.chart
chart.has_title = True
chart.chart_title.text_frame.text = chart_spec.title
chart.has_legend = True
chart.legend.position = XL_LEGEND_POSITION.BOTTOM
chart.legend.include_in_layout = False
from pptx.dml.color import RGBColor
for i, series in enumerate(chart.series):
color_hex = chart_colors[i % len(chart_colors)]
color_rgb = RGBColor(
int(color_hex[0:2], 16),
int(color_hex[2:4], 16),
int(color_hex[4:6], 16)
)
fill = series.format.fill
fill.solid()
fill.fore_color.rgb = color_rgb
if chart_spec.kind == "line":
line = series.format.line
line.color.rgb = color_rgb
line.width = Pt(3)
for s in plan.slides:
slide = prs.slides.add_slide(blank)
add_title(slide, s.title)
has_chart = bool(s.chart_id and s.chart_id in chart_by_id)
if has_chart:
add_bullets(
slide,
s.bullets,
left=Inches(0.5),
top=Inches(1.0),
width=Inches(4.5),
height=Inches(5.5),
)
add_chart(
slide,
chart_by_id[s.chart_id],
left=Inches(5.2),
top=Inches(1.0),
width=Inches(4.5),
height=Inches(5.5),
)
else:
add_bullets(
slide,
s.bullets,
left=Inches(0.5),
top=Inches(1.0),
width=Inches(9.0),
height=Inches(5.5),
)
add_sources_footer(slide, s.bullets)
prs.save(out_pptx)
def build_allowed_ranges(model_df: pd.DataFrame, row_end: int) -> Dict[str, str]:
ranges = {}
for i, col in enumerate(model_df.columns, start=1):
col_letter = get_column_letter(i)
ranges[col] = f"Model!{col_letter}2:{col_letter}{row_end}"
return ranges
def validate_plan(plan: ArtifactPlan, allowed_ranges: Dict[str, str]) -> None:
allowed_set = set(allowed_ranges.values())
chart_ids = {c.id for c in plan.charts}
if len(chart_ids) != len(plan.charts):
raise ValueError("Duplicate chart ids in plan.")
for s in plan.slides:
if s.chart_id and s.chart_id not in chart_ids:
raise ValueError(f"Slide references unknown chart_id: {s.chart_id}")
for s in plan.slides:
for b in s.bullets:
for c in b.citations:
if c not in allowed_set:
raise ValueError(f"Citation not in allowed set: {c}")
allowed_metrics = set(allowed_ranges.keys())
for c in plan.charts:
if c.x_metric not in allowed_metrics:
pass
for s in c.series:
if s.metric not in allowed_metrics:
raise ValueError(f"Unknown series metric: {s.metric}")Capiremo il codice qui sopra passo dopo passo:
Crea il deck e indicizza i grafici: prs = Presentation() avvia un nuovo PPTX, mentre blank = prs.slide_layouts[6] fornisce una tela vuota per un posizionamento preciso.
Titoli e bullet: la funzione add_title() scrive in una textbox text_frame, e add_bullets() aggiunge un paragrafo per bullet controllando dimensione del font e spaziatura tramite la formattazione del paragrafo.
Footer delle citazioni: la funzione add_sources_footer() deduplica le citazioni tra i bullet e rende una riga compatta Sources: in fondo, così la tracciabilità resta intatta senza appesantire la slide.
Incorpora i grafici: add_chart() costruisce un oggetto CategoryChartData() usando una colonna X di tipo temporale e i valori delle serie pianificati, poi lo inserisce con slide.shapes.add_chart(), che restituisce un GraphicFrame.
Stile del brand: infine convertiamo l’hex in RGBColor e lo applichiamo per serie.
Regole di layout e guardrail: se una slide ha un chart_id valido, usiamo un layout a due colonne, altrimenti bullet a tutta larghezza. La funzione build_allowed_ranges() crea la allow-list degli intervalli citabili, e validate_plan() impone ID grafici unici, riferimenti validi, citazioni ammesse e metriche valide così il modello non può inventare campi.
A questo punto, abbiamo dati tabellari puliti, che trasformeremo in un piano di build con schema (grafici, slide e citazioni) che il renderer può eseguire.
def generate_plan_with_llm(
api_key: str,
model: str,
goal: str,
allowed_ranges: Dict[str, str],
facts: Dict[str, str],
num_slides: int = 6,
num_charts: int = 4,
) -> ArtifactPlan:
plan_schema = {
"type": "object",
"properties": {
"charts": {
"type": "array",
"minItems": 3,
"maxItems": 6,
"items": {
"type": "object",
"properties": {
"id": {"type": "string"},
"kind": {"type": "string", "enum": ["line", "bar"]},
"title": {"type": "string"},
"x_metric": {"type": "string"},
"series": {
"type": "array",
"minItems": 1,
"maxItems": 3,
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"metric": {"type": "string"},
},
"required": ["name", "metric"],
"additionalProperties": False,
},
},
"anchor": {"type": "string"},
},
"required": ["id", "kind", "title", "x_metric", "series", "anchor"],
"additionalProperties": False,
},
},
"slides": {
"type": "array",
"minItems": 4,
"maxItems": 10,
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"chart_id": {"type": ["string", "null"]},
"bullets": {
"type": "array",
"minItems": 2,
"maxItems": 4,
"items": {
"type": "object",
"properties": {
"text": {"type": "string"},
"citations": {
"type": "array",
"minItems": 1,
"maxItems": 4,
"items": {"type": "string"},
},
},
"required": ["text", "citations"],
"additionalProperties": False,
},
},
},
"required": ["title", "chart_id", "bullets"],
"additionalProperties": False,
},
},
},
"required": ["charts", "slides"],
"additionalProperties": False,
}
system = (
"You produce investor-grade slides with traceability.\n"
"Output MUST match the JSON schema exactly.\n"
"Rules:\n"
"1) Use ONLY the allowed citation ranges (exact strings).\n"
"2) No generic filler. Every bullet must contain at least ONE number (e.g., $X, X%, X mo).\n"
"3) Keep bullets short: <= 12 words.\n"
"4) Prefer trends (start→end) or averages; avoid speculation.\n"
"5) Provide exactly the requested number of charts and slides.\n"
"6) Use chart_id to attach the correct chart to each slide.\n"
"7) Chart anchors: Use cell references ONLY (e.g., 'A2', 'A20', 'A38'). Do NOT include sheet name like 'CHARTS!A'.\n"
)
user = (
f"Goal: {goal}\n"
f"Requested: {num_charts} charts and {num_slides} slides.\n\n"
f"Facts (use these; do not invent):\n{json.dumps(facts, indent=2)}\n\n"
f"Allowed citation ranges (use exact values only):\n{json.dumps(list(allowed_ranges.values()), indent=2)}\n\n"
"Metric keys available for charts:\n"
f"{json.dumps(list(allowed_ranges.keys()), indent=2)}\n\n"
"Chart requirements:\n"
"- x_metric: Use a date/time column (e.g., 'month', 'date', 'period', 'week') for the X-axis.\n"
" If no date column exists, use the first column from the available metrics.\n"
"- Create meaningful charts based on available metrics in the data.\n"
"- Focus on trends, comparisons, and key business metrics.\n"
"- Chart colors: Use these specific shades for all chart series:\n"
" * Primary color: #01ef63 (bright green)\n"
" * Secondary color: #203147 (dark blue/navy)\n"
" * Alternate between these two colors for multiple series in the same chart.\n"
"Slide requirements:\n"
"- Create slides that tell a story with the available data.\n"
"- Suggested structure: Overview, Key Metrics, Trends, Analysis, Summary, Next Steps.\n"
"- Adapt slide titles and content to match the data domain (e.g., sales, marketing, operations, finance).\n"
)
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
plan_json = chat_json_schema(
model=model,
messages=messages,
json_schema=plan_schema,
api_key=api_key,
temperature=0.2,
max_tokens=6000,
)
try:
plan = ArtifactPlan.model_validate(plan_json)
validate_plan(plan, allowed_ranges)
if len(plan.slides) != num_slides:
raise ValueError(f"Expected {num_slides} slides, got {len(plan.slides)}")
if len(plan.charts) != num_charts:
raise ValueError(f"Expected {num_charts} charts, got {len(plan.charts)}")
return plan
except (ValidationError, ValueError) as e:
repair = messages + [
{"role": "assistant", "content": json.dumps(plan_json)},
{"role": "user", "content": f"Fix JSON to satisfy schema + rules. Error:\n{str(e)}"},
]
plan_json = chat_json_schema(
model=model,
messages=repair,
json_schema=plan_schema,
api_key=api_key,
temperature=0.0,
max_tokens=6000,
)
plan = ArtifactPlan.model_validate(plan_json)
validate_plan(plan, allowed_ranges)
if len(plan.slides) != num_slides or len(plan.charts) != num_charts:
raise RuntimeError("Plan repaired but counts still wrong. Tighten prompt or increase max_tokens.")
return planLa funzione generate_plan_with_llm() è il cervello di questa demo. Ecco come la aggiungiamo alla pipeline:
JSON Schema esplicito: plan_schema definisce l’unica forma di risposta che il modello può produrre, charts[] e slides[], con campi obbligatori ed enum.
Guardrail nel prompt di sistema: imponiamo vincoli non negoziabili per garantire che il piano resti renderizzabile e verificabile. Limitiamo anche il posizionamento dei grafici a semplici celle, così il layout resta deterministico invece che improvvisato dal modello. Questo tipo di controllo multi-step è esattamente ciò per cui GPT-5.2 è progettato.
Messaggio utente: il messaggio utente fornisce l’obiettivo, i conteggi richiesti, i fatti calcolati e le chiavi metriche ammesse. Poiché il modello non vede altro, ha molte meno possibilità di inventare colonne, intervalli o affermazioni non supportate.
Decodifica aderente allo schema: chiamiamo chat_json_schema() con response_format impostato a json_schema e strict: true, che impone l’aderenza allo schema durante la decodifica.
Convalida su due livelli: prima ArtifactPlan.model_validate(plan_json) conferma che la risposta rispetta i modelli Pydantic. Poi validate_plan() impone vincoli di dominio.
Infine, colleghiamo il caricamento del CSV, la generazione dell’Excel, la pianificazione LLM, il rendering dei grafici e l’export finale in PPTX, quindi restituiamo i percorsi di output.
@dataclass
class RunOutputs:
xlsx_path: str
pptx_path: str
plan_path: str
logs: str
def run_pipeline(csv_path: str, goal: str, outdir: str, model: str, num_slides: int, num_charts: int) -> RunOutputs:
load_dotenv()
openai_key = os.getenv("OPENAI_API_KEY")
openrouter_key = os.getenv("OPENROUTER_API_KEY")
if "/" in model or openrouter_key:
api_key = openrouter_key
if not api_key:
raise RuntimeError("Missing OPENROUTER_API_KEY (required for OpenRouter models)")
elif openai_key:
api_key = openai_key
else:
raise RuntimeError("Missing API key. Set either OPENAI_API_KEY or OPENROUTER_API_KEY")
out = Path(outdir)
out.mkdir(parents=True, exist_ok=True)
xlsx_path = str(out / "investor_update.xlsx")
pptx_path = str(out / "investor_update.pptx")
plan_path = str(out / "plan.json")
raw_df = load_and_validate_csv(csv_path)
model_df = compute_model_df(raw_df)
xlsx_path, row_end = build_workbook_base(raw_df, model_df, xlsx_path)
allowed_ranges = build_allowed_ranges(model_df, row_end)
facts = compute_facts(model_df)
plan = generate_plan_with_llm(
api_key=api_key,
model=model,
goal=goal,
allowed_ranges=allowed_ranges,
facts=facts,
num_slides=num_slides,
num_charts=num_charts,
)
with open(plan_path, "w", encoding="utf-8") as f:
json.dump(plan.model_dump(), f, indent=2)
add_charts_to_workbook(xlsx_path, plan.charts, allowed_ranges)
build_pptx(pptx_path, model_df, plan)
logs = (
f"CSV rows: {len(raw_df)}\n"
f"Excel: {xlsx_path}\n"
f"PPTX: {pptx_path}\n"
f"Plan: {plan_path}\n"
f"Facts used: {facts}\n"
)
return RunOutputs(xlsx_path=xlsx_path, pptx_path=pptx_path, plan_path=plan_path, logs=logs)Uniamo tutti i componenti della nostra pipeline passo dopo passo:
@dataclass crea un contenitore leggero per xlsx_path, pptx_path, plan_path e logs, così la UI Streamlit può trattare il risultato come un unico valore strutturato invece di gestire tuple o globali.load_dotenv() carica il nostro file .env nelle variabili d’ambiente così OPENAI_API_KEY e OPENROUTER_API_KEY possono essere letti via os.getenv(). Poi scegliamo la chiave del provider con una regola semplice: se esiste OPENROUTER_API_KEY, usa OpenRouter; altrimenti, ripiega su OpenAI se disponibile.build_workbook_base(). La funzione generate_plan_with_llm() restituisce quindi un ArtifactPlan che viene salvato come JSON con json.dump() così è facile da ispezionare e fare debug.build_pptx() costruisce il deck delle slide dal piano e dalla tabella.Dopo questo passaggio, la nostra app Streamlit può chiamare run_pipeline(), mostrare i logs ed esporre tre output deterministici per il download, incluso il workbook Excel, il deck PPTX e il piano JSON.
Ora che la pipeline core è pronta, l’ultimo passo è incapsularla in un’app Streamlit così chiunque può caricare un file, impostare un obiettivo, scegliere un modello e scaricare gli artifact generati.
load_dotenv()
st.set_page_config(
page_title="GPT-5.2 PPT and Excel Generator",
page_icon="",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-size: 2.5rem;
font-weight: 700;
color: #1f77b4;
margin-bottom: 1rem;
}
.sub-header {
font-size: 1.2rem;
color: #666;
margin-bottom: 2rem;
}
.success-box {
padding: 1rem;
background-color: #d4edda;
border-left: 4px solid #28a745;
margin: 1rem 0;
}
.error-box {
padding: 1rem;
background-color: #f8d7da;
border-left: 4px solid #dc3545;
margin: 1rem 0;
}
.info-box {
padding: 1rem;
background-color: #d1ecf1;
border-left: 4px solid #17a2b8;
margin: 1rem 0;
}
.slide-preview {
border: 2px solid #ddd;
border-radius: 8px;
padding: 10px;
margin: 10px 0;
background: white;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
</style>
""", unsafe_allow_html=True)
def main():
try:
if 'outputs' not in st.session_state:
st.session_state.outputs = None
if 'generated' not in st.session_state:
st.session_state.generated = False
st.markdown('<div class="main-header">Spreadsheet to PowerPoint Generator</div>', unsafe_allow_html=True)
with st.sidebar:
# API Provider selection
api_provider = st.selectbox(
"API Provider",
["OpenAI", "OpenRouter"],
help="Select which API to use. Make sure the corresponding API key is set in your .env file"
)
# Model selection based on provider
if api_provider == "OpenAI":
model = st.selectbox(
"AI Model",
[
"gpt-4o",
"gpt-4-turbo",
"gpt-4",
"gpt-3.5-turbo",
],
help="OpenAI models. Requires OPENAI_API_KEY in .env file"
)
else: # OpenRouter
model = st.selectbox(
"AI Model",
[
"openai/gpt-5.2",
"openai/gpt-4-turbo",
"openai/gpt-4o",
"anthropic/claude-3-opus",
"anthropic/claude-3-sonnet",
],
help="OpenRouter models. Requires OPENROUTER_API_KEY in .env file"
)
with st.expander("Advanced Settings"):
num_slides = st.slider("Number of Slides", 4, 10, 6)
num_charts = st.slider("Number of Charts", 3, 6, 4)
col1, col2 = st.columns([1, 1])
with col1:
st.markdown("### Input")
uploaded_file = st.file_uploader(
"Upload CSV",
type=['csv'],
help="Upload any CSV file. The app will automatically detect columns and create appropriate charts and slides."
)
use_example = st.checkbox("Use example data (kpis.csv)", value=True if not uploaded_file else False)
if uploaded_file or use_example:
if use_example:
csv_path = "kpis.csv"
df = pd.read_csv(csv_path)
else:
df = pd.read_csv(uploaded_file)
with tempfile.NamedTemporaryFile(delete=False, suffix='.csv', mode='w') as f:
df.to_csv(f, index=False)
csv_path = f.name
with st.expander(" Preview Data", expanded=False):
try:
st.dataframe(df, width='stretch')
except Exception as e:
st.write("**Data Preview:**")
st.table(df.head(20))
if len(df) > 20:
st.caption(f"Showing first 20 of {len(df)} rows")
st.caption(f"Rows: {len(df)} | Columns: {len(df.columns)}")
else:
csv_path = None
st.info("Upload a CSV or use example data to continue")
goal = st.text_area(
"Goal",
value="Create a 6-slide investor update for Apr–Sep 2025. Focus on growth, retention, unit economics, and runway.",
height=100,
help="Describe what you want the AI to create"
)
generate_btn = st.button("Generate Artifacts", type="primary", use_container_width=True)
with col2:
st.markdown("### Output")
status_container = st.empty()
progress_bar = st.progress(0)
if not generate_btn:
status_container.info("Configure settings and click 'Generate Artifacts'")
if generate_btn:
if not csv_path:
st.error("Please upload a CSV or select 'Use example data'")
st.stop()
try:
status_container.info("Processing... This may take 30-60 seconds")
progress_bar.progress(10)
output_dir = Path("out")
output_dir.mkdir(exist_ok=True)
progress_bar.progress(20)
with st.spinner("Generating artifacts..."):
outputs: RunOutputs = run_pipeline(
csv_path=csv_path,
goal=goal,
outdir=str(output_dir),
model=model,
num_slides=num_slides,
num_charts=num_charts
)
st.session_state.outputs = outputs
st.session_state.generated = True
progress_bar.progress(100)
except Exception as e:
status_container.markdown(
f'<div class="error-box"> <b>Error:</b> {str(e)}</div>',
unsafe_allow_html=True
)
st.exception(e)
st.session_state.generated = False
if st.session_state.generated and st.session_state.outputs:
outputs = st.session_state.outputs
try:
if "Error" not in outputs.logs:
status_container.markdown(
'<div class="success-box"><b>Success!</b> Artifacts generated successfully</div>',
unsafe_allow_html=True
)
tab1, tab2, tab3, tab4 = st.tabs(["PowerPoint", "Excel", "JSON Plan", "Logs"])
with tab1:
st.markdown("### PowerPoint Slides")
pptx_path = Path(outputs.pptx_path)
if pptx_path.exists():
try:
prs = Presentation(str(pptx_path))
slide_count = len(prs.slides)
except:
slide_count = "unknown"
with open(pptx_path, "rb") as f:
st.download_button(
label="Download PowerPoint",
data=f.read(),
file_name="investor_update.pptx",
mime="application/vnd.openxmlformats-officedocument.presentationml.presentation",
width='stretch',
key="pptx_download"
)
st.markdown("---")
col_info1, col_info2 = st.columns(2)
with col_info1:
st.metric("Slides", slide_count)
with col_info2:
file_size = pptx_path.stat().st_size / 1024 # KB
st.metric("File Size", f"{file_size:.1f} KB")
else:
st.error("PowerPoint file not found")
with tab2:
st.markdown("### Excel Workbook")
xlsx_path = Path(outputs.xlsx_path)
if xlsx_path.exists():
with open(xlsx_path, "rb") as f:
st.download_button(
label="Download Excel",
data=f.read(),
file_name="investor_update.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
width='stretch',
key="xlsx_download"
)
wb = openpyxl.load_workbook(xlsx_path)
st.markdown("#### Data Preview")
ws = wb["Model"]
data = []
headers = [cell.value for cell in ws[1]]
for row in ws.iter_rows(min_row=2, values_only=True):
data.append(row)
df_preview = pd.DataFrame(data, columns=headers)
try:
st.dataframe(df_preview.head(10), width='stretch')
except Exception:
st.table(df_preview.head(10))
if len(df_preview) > 10:
st.caption(f"Showing first 10 of {len(df_preview)} rows")
else:
st.error("Excel file not found")
with tab3:
st.markdown("### Schema-Locked JSON Plan")
plan_path = Path(outputs.plan_path)
if plan_path.exists():
with open(plan_path, "r") as f:
plan_data = json.load(f)
st.download_button(
label="Download JSON",
data=json.dumps(plan_data, indent=2),
file_name="plan.json",
mime="application/json",
key="json_download"
)
st.markdown("---")
st.json(plan_data)
col_a, col_b = st.columns(2)
with col_a:
st.metric("Charts Generated", len(plan_data.get("charts", [])))
with col_b:
st.metric("Slides Generated", len(plan_data.get("slides", [])))
else:
st.error("JSON plan not found")
with tab4:
st.markdown("### Generation Logs")
st.code(outputs.logs, language="text")
else:
status_container.markdown(
f'<div class="error-box"> <b>Error occurred</b><br>{outputs.logs}</div>',
unsafe_allow_html=True
)
except Exception as e:
st.error(f"Error displaying results: {str(e)}")
st.exception(e)
except Exception as e:
st.error(f"Fatal Error: {str(e)}")
st.exception(e)
st.info("Try installing dependencies: pip install -r requirements.txt")
if __name__ == "__main__":
try:
main()
except Exception as e:
import sys
print(f"Fatal error: {e}", file=sys.stderr)
import traceback
traceback.print_exc()Nel livello Streamlit, impostiamo il frame dell’app con st.set_page_config( layout="wide"), poi dividiamo lo schermo usando st.columns() così a sinistra raccogliamo gli input mentre a destra mostriamo controlli di esecuzione e output. La pipeline gira solo quando l’utente clicca st.button(), dove prima controlliamo la presenza dei caricamenti, avvolgiamo in st.spinner() così la UI non sembra bloccata, poi restituiamo gli artifact all’utente con st.download_button() per Excel, PowerPoint e il file del piano.
Completato questo passaggio, salviamo tutto come app.py e lanciamo l’esperienza completa con:
streamlit run app.pyImpara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

