
Leerpad
Basisprincipes van machine learning in Python
16 Hr
Parameters schatten is een fundamentele stap in statistische analyse en machine learning. Van de vele beschikbare methoden is Maximum Likelihood Estimation (MLE) een van de meest gebruikte benaderingen dankzij de intuïtieve aard, wiskundige degelijkheid en brede toepasbaarheid op verschillende soorten data en modellen.
In dit artikel leer je wat MLE is, verken je de wiskundige basis met gedetailleerde afleidingen en voorbeelden, en ontdek je praktische computationele methoden om MLE effectief te implementeren.
Maximum likelihood estimation (MLE) is een belangrijke statistische methode om de parameters van een kansverdeling te schatten door de likelihood-functie te maximaliseren.
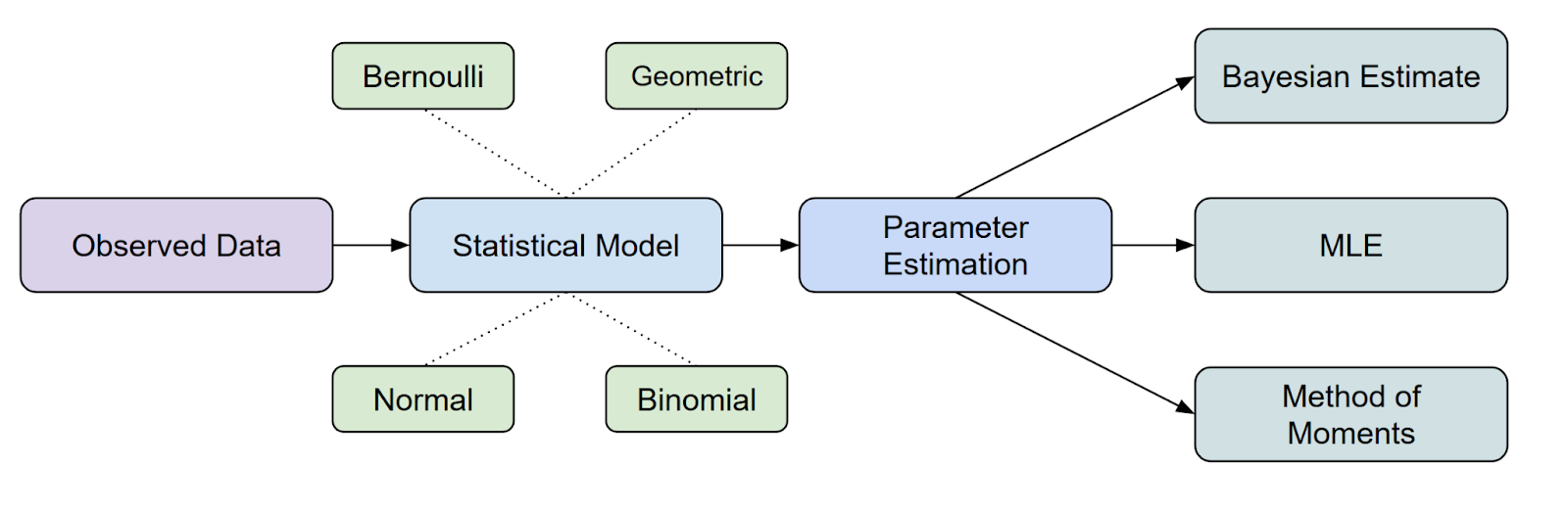
Als we kijken waar MLE past binnen de statistische inferentie, is het een van de meest gebruikelijke methoden om parameters te schatten.
Je zou hier echter nog een vraag kunnen hebben. Wat is een likelihood-functie? Laten we dat verder bespreken.
Je kunt de likelihood-functie zien als een manier om te meten hoe goed een bepaalde set parameters de data verklaart die je hebt geobserveerd.
Met andere woorden, het beantwoordt de vraag: “Gegeven deze parameterwaarden, hoe waarschijnlijk is het dat ik deze data zou zien?” Maar er is een veelvoorkomend misverstand tussen kans en likelihood:
Samengevat neemt de likelihood-functie de parameters van je model als invoer en geeft een getal dat weergeeft hoe plausibel die parameters zijn, gegeven je data.
Hoe hoger de waarde van de likelihood-functie, hoe beter die parameters je data verklaren.
Nog eenvoudiger gezegd: de likelihood-functie helpt ons verschillende parameterkeuzes te “scoren”, zodat we de waarden kunnen kiezen die onze geobserveerde data het meest waarschijnlijk maken.
Nu we het verschil tussen kans en likelihood, en het doel van MLE begrijpen, gaan we door naar de onderliggende wiskunde. 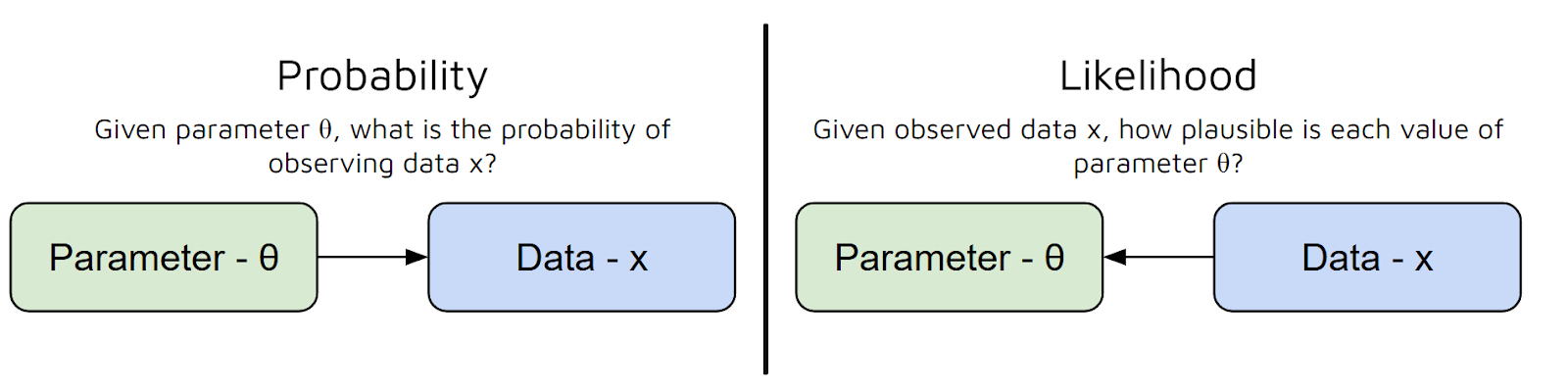
Voordat we specifieke voorbeelden induiken, bekijken we hoe de maximum likelihood-schatting (MLE) in het algemeen wordt afgeleid. We lopen elke stap door en lichten de redenering toe.
Stel dat we een dataset hebben: x₁, x₂, ..., xₙ. We nemen aan dat deze datapunten afkomstig zijn van een kansverdeling die afhangt van een onbekende parameter θ (theta). Ons hoofddoel is θ te schatten.
Als onze dataset bijvoorbeeld over muntworpen gaat, kan θ de kans op kop zijn. Als de dataset continu is, zoals de lengtes van studenten in de klas, kan θ het gemiddelde van een normale verdeling zijn.
De likelihood-functie meet hoe waarschijnlijk het is om je data te observeren voor verschillende waarden van θ. Ze is gedefinieerd als:
![]()
Intuïtief vragen we: gegeven dat de parameter θ een specifieke waarde heeft, wat is de kans om precies deze dataset te observeren?
Deze dataset wordt weergegeven als de gezamenlijke kans op het observeren van de individuele datapunten (x₁, x₂, ..., xₙ), ervan uitgaande dat ze zijn gegenereerd onder het model geparametriseerd door θ.
Met behulp van de kettingregel van de kansrekening kunnen we de bovenstaande vergelijking als volgt uitschrijven:
![]()
Dit is echter een vrij ingewikkelde vergelijking! Daarom nemen we aan dat de datapunten onafhankelijk zijn — meer specifiek, conditioneel onafhankelijk.
Hierdoor kunnen we de gezamenlijke kans schrijven als het product van individuele kansen:
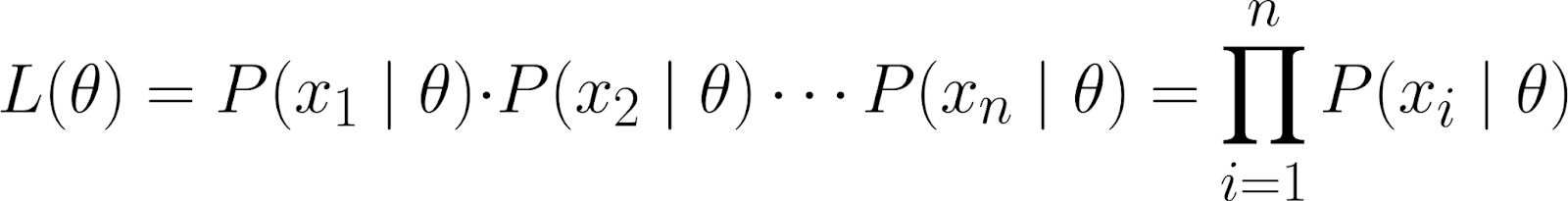
Aangezien onze geobserveerde datapunten conditioneel onafhankelijk zijn gegeven θ, weten we dat de volgende vergelijking geldt:
![]()
Dit komt doordat we aannemen dat, zodra we de waarde van θ kennen, de datapunten x₁ en x₂ conditioneel onafhankelijk zijn.
We zijn nu op het punt dat we de waarden van θ moeten vinden die de likelihood-functie maximaliseren (m.a.w. die de geobserveerde data het meest waarschijnlijk maken):
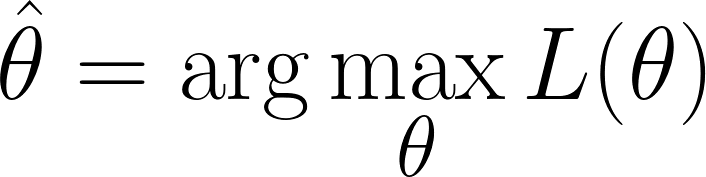
Onthoud echter dat onze likelihood-functie een product bevat. Werken met producten kan lastig worden, vooral bij veel datapunten. Om te vereenvoudigen nemen we het logaritme van de likelihood-functie, omdat dit het product omzet in een som.
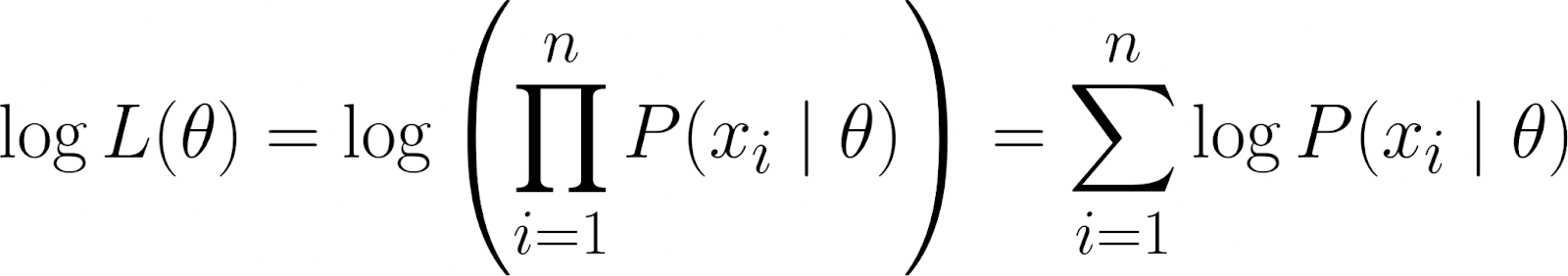
Dit levert de log-likelihood op, die enkele gunstige eigenschappen heeft:
We zijn nu op het punt dat we kunnen differentiëren, maar in machine learning willen we verliesfuncties meestal minimaliseren. Gelukkig is dat makkelijk op te lossen.
Door een minteken toe te voegen (d.w.z. vermenigvuldigen met -1) aan het begin van onze functie, moeten we nu onze verliesfunctie minimaliseren, die nu de Negative Log-Likelihood Loss Function wordt genoemd.
Nu kunnen we calculus gebruiken om de waarde van θ te verkrijgen. We nemen de afgeleide van de log-likelihood naar θ, zetten die gelijk aan nul en lossen op naar θ. Dit omdat het minimum van een functie ligt waar de afgeleide nul is (en de tweede afgeleide positief).
Daarom is de uiteindelijke vergelijking voor MLE:
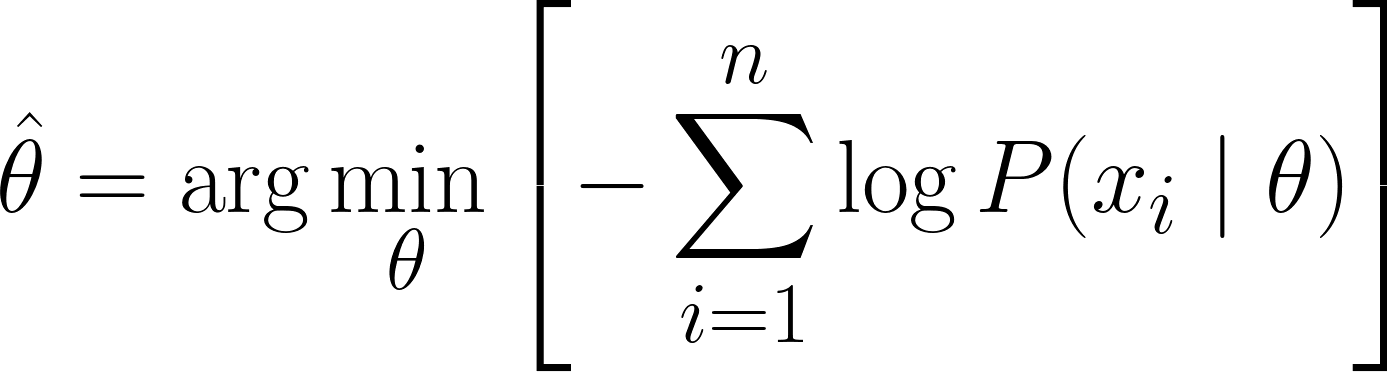
Nu we de MLE-vergelijking hebben afgeleid, bekijken we enkele uitgewerkte voorbeelden om ons begrip te versterken.
We beginnen met een eenvoudig, discreet voorbeeld: het schatten van de kans op het gooien van een zes met een mogelijk oneerlijke dobbelsteen.
Stel dat we 12 keer met een dobbelsteen gooien en de resultaten noteren. We willen deze data modelleren met een categorische verdeling, maar we focussen op het schatten van de kans θ (theta) op het gooien van een zes. In dit voorbeeld:
Nu berekenen we de likelihood-functie. Omdat we 4 zessen uit 12 worpen kregen, verkrijgen we:
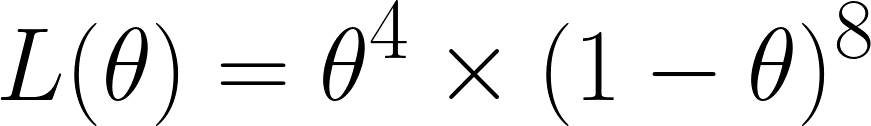
Dit krijgen we omdat we van de 12 worpen 4 keer een zes hebben — vandaar θ⁴ — en 8 keer geen zes — vandaar de term (1 - θ)⁸.
Onthoud dat we deze termen hebben vermenigvuldigd omdat we aannamen dat ze conditioneel onafhankelijk zijn.
Vervolgens nemen we de negatieve log-likelihood zoals eerder besproken, wat deze vergelijking oplevert:
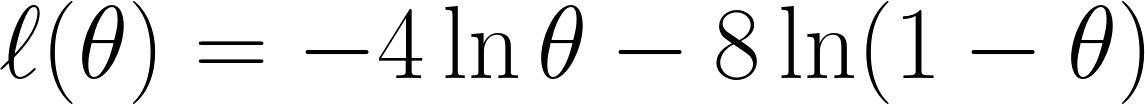
Ten slotte differentiëren we de vergelijking naar θ en zetten die gelijk aan 0 (omdat we het minimum willen vinden):
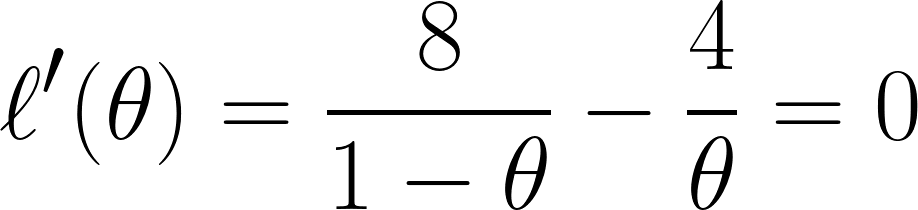
Uit deze vergelijking kunnen we concluderen dat θ gelijk is aan ⅓.
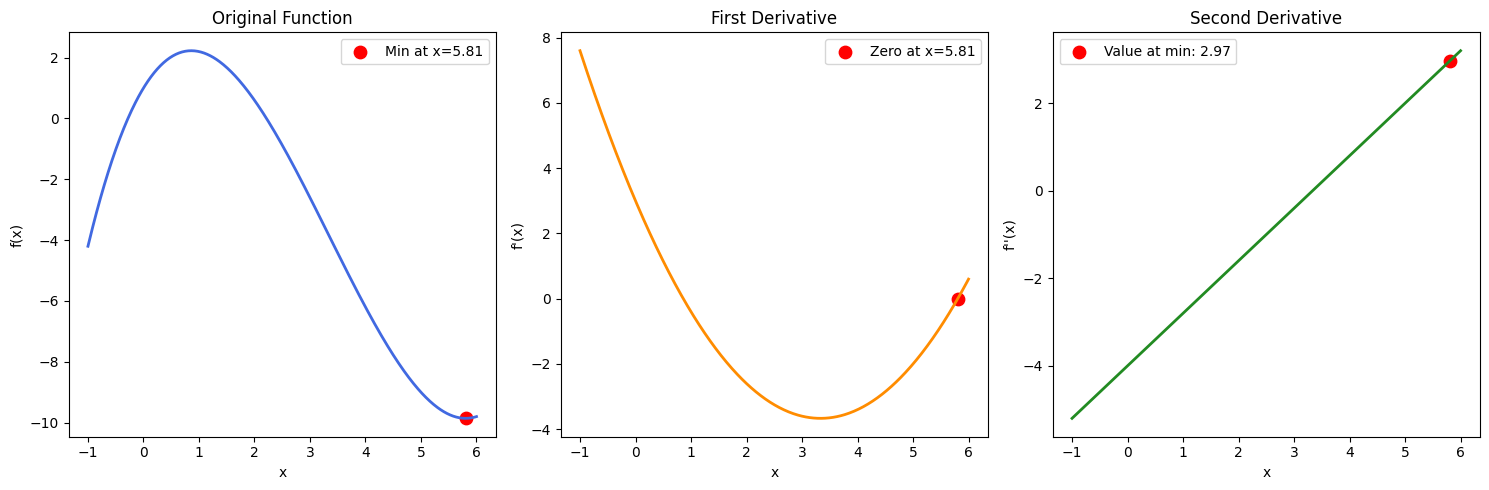
Let op: Als we meerdere oplossingen voor θ zouden krijgen, dan moeten we ook de tweede afgeleide bepalen en kijken welke θ-waarden een positieve uitkomst geven (om te bevestigen dat we een minimum hebben gevonden). Dit wordt geïllustreerd in de voorbeeldfunctie hieronder:
Kijk nu naar een continu voorbeeld — het schatten van het gemiddelde van een normale (Gaussische) verdeling.
Stel dat we een dataset hebben met de lengtes van 5 personen: 160, 165, 170, 175, 180 (in cm). We nemen aan dat deze getrokken zijn uit een normale verdeling met een onbekend gemiddelde μ (mu) en bekende variantie σ² (neem σ² = 25 voor de eenvoud).
De likelihood-functie voor de normale verdeling (met bekende variantie) is:
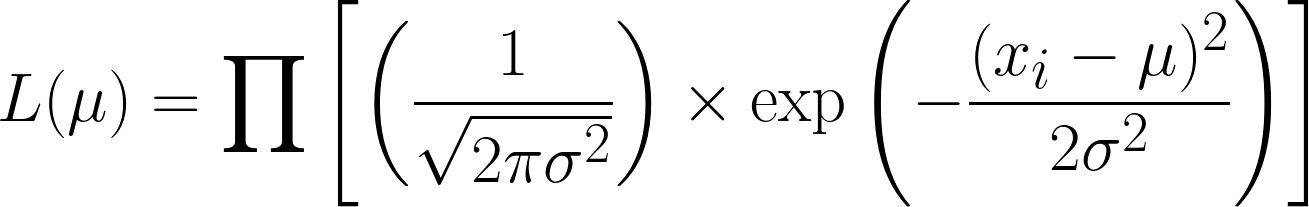
Dit is erg ingewikkeld, maar de negatieve log nemen maakt het eenvoudiger. Hopelijk zie je nu de kracht van de logfunctie in onze vergelijking. De vergelijking die we krijgen is:
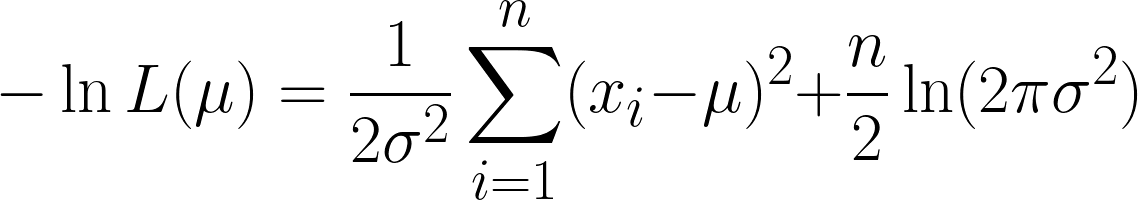
We krijgen hier twee termen, maar let erop dat de tweede term kan worden genegeerd bij het differentiëren, omdat we differentieëren naar μ, en de tweede term geen μ bevat.
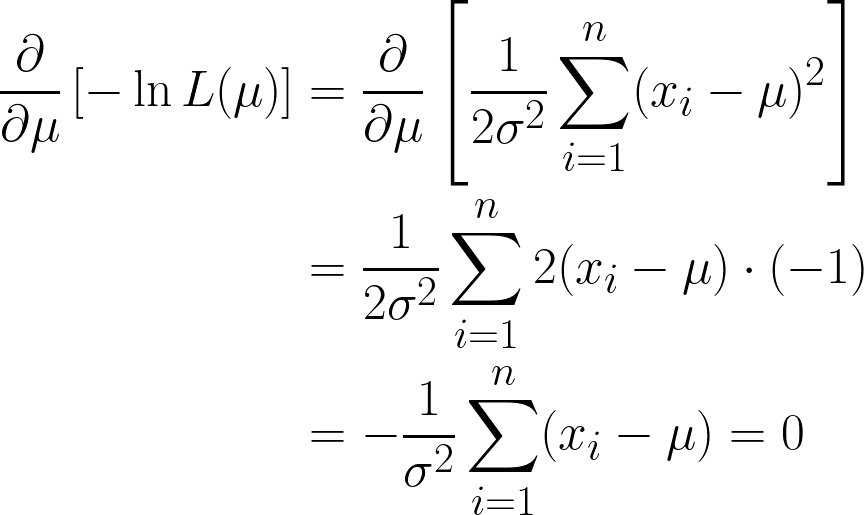
We zijn er bijna, maar kijk naar μ tussen de haakjes.
Omdat het een constante is, kunnen we die eenvoudig vermenigvuldigen met n; μ n keer optellen is simpelweg n*μ.
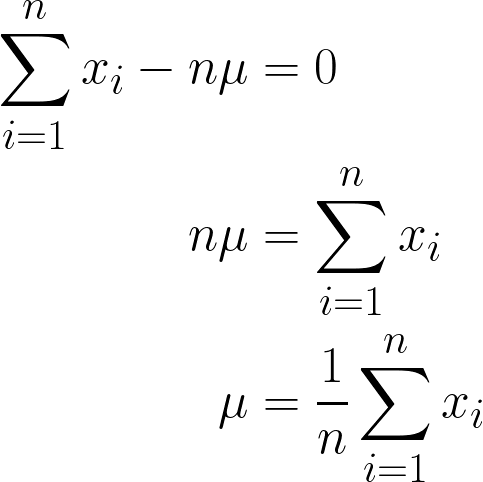
Het uiteindelijke antwoord moet intuïtief aanvoelen, want wiskundig staat er dat je alle waarden van x optelt en deelt door n (het aantal observaties), en dat is ook precies de definitie van het gemiddelde!
Door onze datapunten in te vullen in deze vergelijking, krijgen we een gemiddelde van 170 cm.
Om dit visueler te maken, zie je hier een animatie die laat zien hoe de likelihood verandert als we μ variëren:
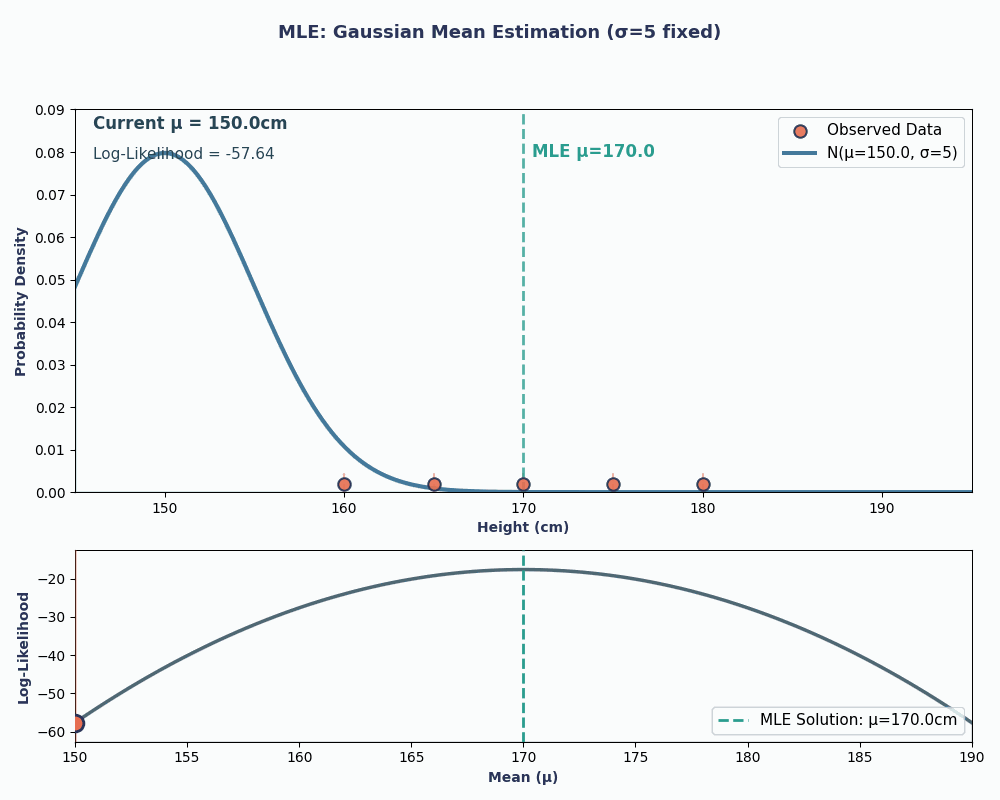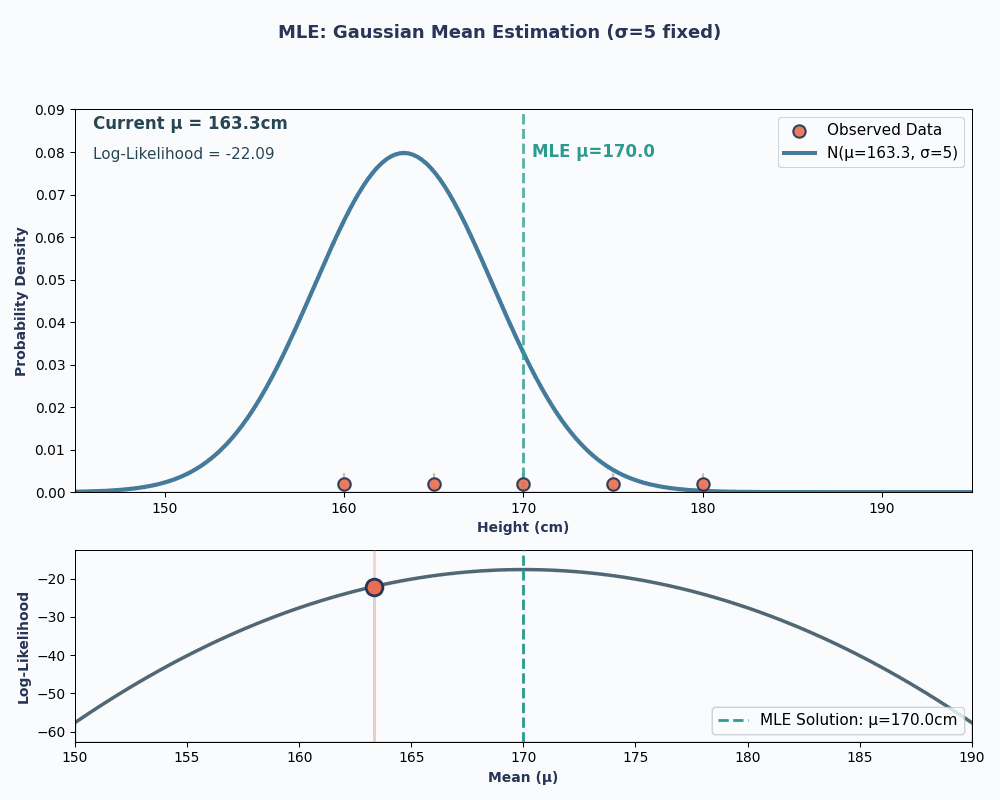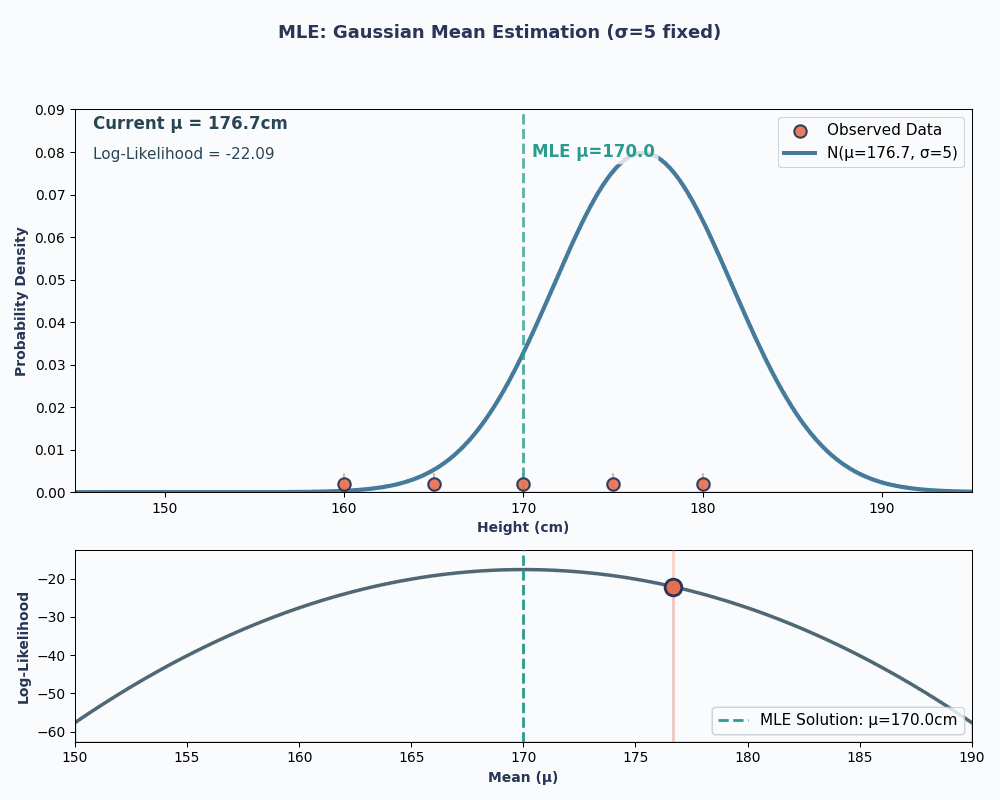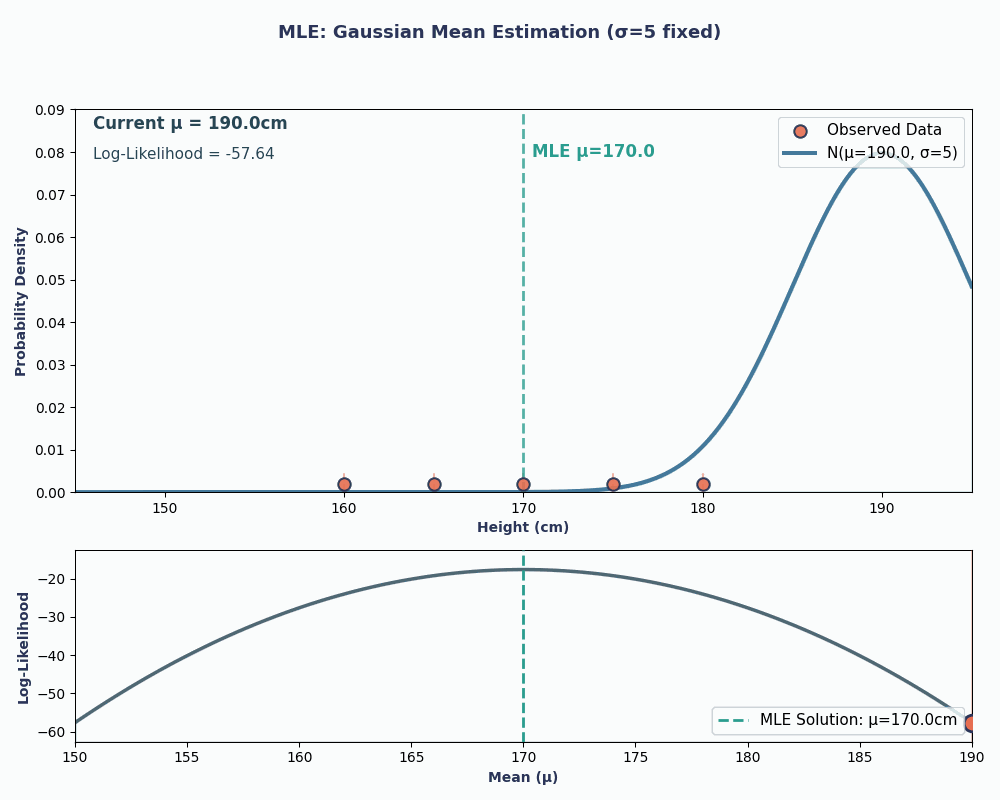
In beide voorbeelden gaf MLE ons de parameterwaarde die onze geobserveerde data het meest waarschijnlijk maakte onder het gekozen model. Uiteraard kan MLE ook meerdere parameterwaarden opleveren, al is de berekening dan iets langer!
Nu we de onderliggende structuur van MLE begrijpen, kijken we hoe je dit in Python codeert. We coderen de oplossing van het vorige (lengte-)voorbeeld.
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Merk op dat we in het vorige codevoorbeeld een functie negative_log_likelihood() hebben gemaakt met de kernlogica voor het berekenen van de MLE van een univariate Gaussische verdeling.
Enerzijds kun je stellen dat we deze vergelijking uiteindelijk hardcodeerden en scipy.optimize gebruikten om die functie te minimaliseren. Dit is uiteraard een prima oplossing, aangezien de Gaussische verdeling een gesloten vormoplossing heeft.
Laten we andere methoden verkennen om oplossingen voor MLE te berekenen.
Zoals we hierboven bespraken, kunnen we in gelukkige gevallen de MLE-vergelijkingen analytisch oplossen, wat betekent dat we een exacte formule voor de parameterschattingen kunnen afleiden. Dit noemen we gesloten vormoplossingen; ze zijn vaak eenvoudig, intuïtief en snel te programmeren en te berekenen.
Een belangrijke vraag is nu: wanneer bestaan gesloten vormoplossingen?
|
Verdeling |
Geschatte parameter |
Gesloten-vorm MLE-oplossing |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = #aantal successen/n |
|
Binomiaal |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gaussisch/Normaal |
μ |
μ = 1/n*Σx_i |
Voor complexere modellen bestaan analytische oplossingen niet of zijn ze te ingewikkeld om af te leiden. In die gevallen gebruiken we numerieke optimalisatiemethoden — iteratieve algoritmen die zoeken naar de parameters die de log-likelihood maximaliseren. Kort uitgelegd:
Uit onze voorbeelden en berekeningen blijkt duidelijk dat MLE nuttig is. Formeel heeft MLE de volgende eigenschappen:
Er zijn echter scenario’s waarin MLE niet de beste optie is:
In deze sectie verkennen we waar MLE daadwerkelijk gebruikt wordt in Machine Learning en AI.
Een van de belangrijkste plekken waar MLE verschijnt is bij logistische regressie. Hierbij schatten we de kans dat een uitkomst tot een bepaalde klasse behoort (zoals klantverloop) en doen we dit door parameters te fitten die de likelihood maximaliseren van de geobserveerde uitkomsten.
Zelfs bij lineaire regressie, als we normaal verdeelde fouten aannemen, blijkt de kleinste-kwadratenoplossing ook de MLE te zijn.
MLE kan ook worden gebruikt om modellen te vergelijken.
Zo helpt de likelihood ratio test (LRT) ons te controleren of het toevoegen van extra variabelen aan een model de prestaties significant verbetert. Dit gebeurt door de likelihoods van twee modellen te vergelijken: één eenvoudiger (nulmodel) en één complexer (alternatief).
We hebben ook het Akaike Information Criterion (AIC), dat complexiteit afstraft om overfitting te vermijden. Deze tools worden veel gebruikt in bijvoorbeeld finance, geneeskunde en marketing.
Als je geïnteresseerd bent in het verder verkennen van manieren om verschillen tussen kansverdelingen te meten, voorbij alleen likelihood, bekijk dan mijn tutorial: KL-divergentie uitgelegd.
Hoewel MLE krachtig is, heeft het ook nadelen. Laten we kort doornemen waar het moeite mee heeft en wat je in plaats daarvan kunt gebruiken.
Wanneer MLE minder goed werkt, zijn dit opties:
Verschillende methoden werken beter in verschillende situaties. MLE is niet altijd het antwoord, maar vaak wel een uitstekend startpunt.
Maximum Likelihood Estimation is een van de meest natuurlijke en wijdverspreide methoden voor parameterschatting. Het draait om het zo waarschijnlijk mogelijk maken van de geobserveerde data en is daardoor in veel scenario’s inzetbaar, zoals muntworpen, Gaussische lengtes, enz.
MLE past zich aan over modellen heen en schaalt met data, en biedt zowel wiskundige elegantie als praktische kracht. Hoewel het zijn eigen nadelen heeft, vooral bij kleine of rommelige datasets, blijft het een fundamenteel hulpmiddel bij het leren van Machine Learning en AI.
Als je bezig bent met je machine-learningreis, bekijk dan zeker ons Machine Learning Scientist in Python-careertrack, waarin supervised, unsupervised en deep learning aan bod komen.
Klaar om je begrip van Maximum Likelihood Estimation te verdiepen met praktische oefeningen? Deze resources helpen je je kennis toe te passen en hands-on ervaring op te doen:
Topcursussen bij DataCamp
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
