
Program
Makine Öğrenimi Temelleri Python'da
16 sa
Parametre tahmini, istatistiksel analiz ve makine öğrenmesinde temel bir adımdır. Mevcut çeşitli yöntemler arasında, Maksimum Olabilirlik Tahmini (MLE) sezgisel yapısı, matematiksel sağlamlığı ve farklı veri ve modellerde geniş uygulanabilirliği sayesinde en yaygın kullanılan yaklaşımlardan biridir.
Bu yazıda MLE’nin ne olduğunu öğrenecek, ayrıntılı türetmeler ve örnekler üzerinden matematiksel temellerini inceleyecek ve MLE’yi etkili biçimde uygulamak için pratik hesaplama yöntemlerini keşfedeceksiniz.
Maksimum olabilirlik tahmini (MLE), bir istatistiksel yöntem olup, bir olasılık dağılımının parametrelerini olabilirlik fonksiyonunu maksimize ederek tahmin etmek için kullanılır.
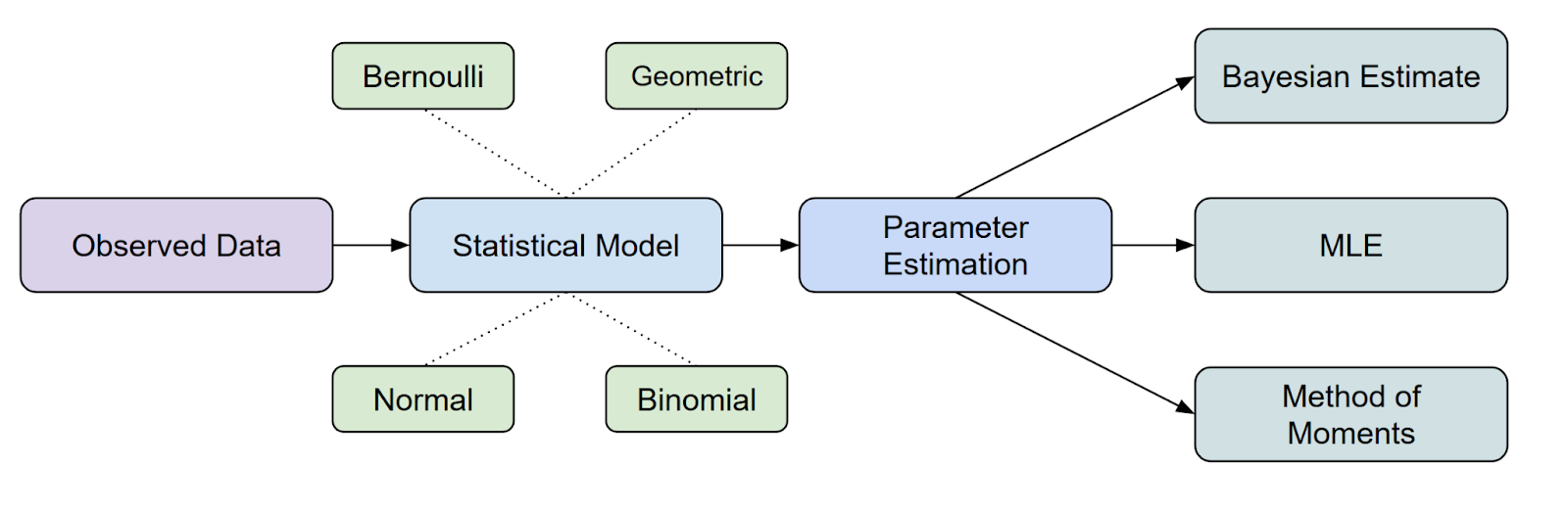
MLE’nin istatistiksel çıkarım içindeki yeri açısından, parametreleri tahmin etmek için en yaygın yöntemlerden biridir.
Ancak burada şu soru akla gelebilir: Olabilirlik fonksiyonu nedir? Bunu biraz daha açalım.
Olabilirlik fonksiyonunu, belirli bir parametre kümesinin gözlediğiniz verileri ne kadar iyi açıkladığını ölçmenin bir yolu olarak düşünebiliriz.
Başka bir deyişle şu soruyu yanıtlar: “Bu parametre değerleri verildiğinde bu veriyi görmem ne kadar olasıdır?” Fakat burada Olasılık ve Olabilirlik arasında yaygın bir yanlış anlama vardır:
Özetle, olabilirlik fonksiyonu modelinizin parametrelerini girdi olarak alır ve veriniz verildiğinde bu parametrelerin ne kadar makul olduğunu temsil eden bir sayı üretir.
Olabilirlik fonksiyonunun değeri ne kadar yüksekse, bu parametreler verinizi o kadar iyi açıklar.
Daha da basitleştirirsek, olabilirlik fonksiyonu farklı parametre seçimlerini “puanlamamıza” yardımcı olur; böylece gözlenen verimizi en olası kılanları seçebiliriz.
Artık Olasılık ve Olabilirlik arasındaki farkı ve MLE’nin ne için kullanıldığını anladığımıza göre, altında yatan matematiğe geçelim. 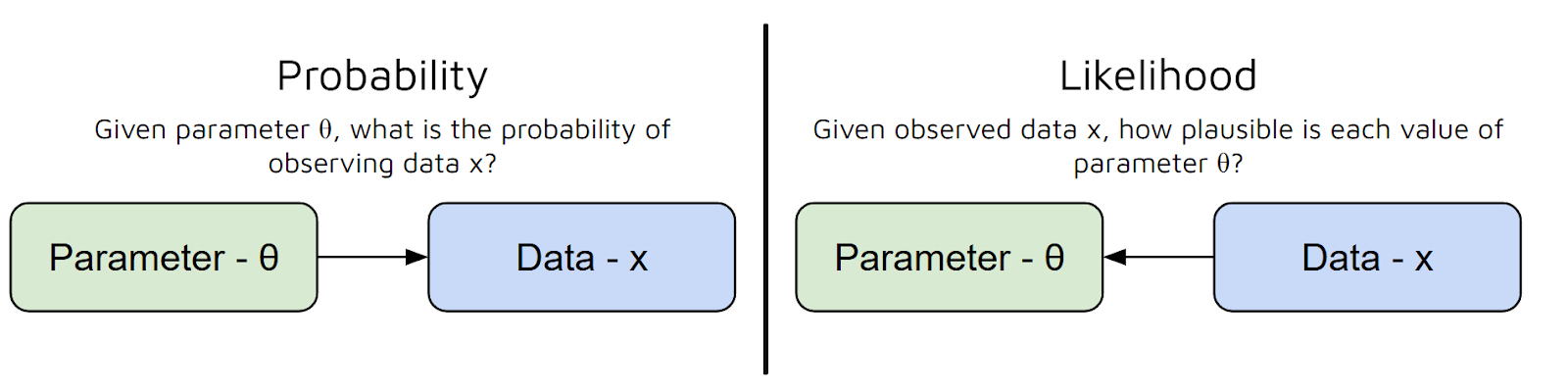
Belirli örneklere geçmeden önce, maksimum olabilirlik tahmin edicisinin (MLE) genel olarak nasıl türetildiğini görelim. Her adımı ele alacak ve arkasındaki mantığı da açıklayacağız.
x₁, x₂, ..., xₙ şeklinde bir veri kümemiz olduğunu varsayalım. Bu veri noktalarının, bilinmeyen bir parametre θ’ya (theta) bağlı bir olasılık dağılımından üretildiğine inanıyoruz. Temel amacımız θ’yı tahmin etmektir.
Örneğin veri kümemiz yazı-tura atışlarıyla ilgiliyse, θ tura gelme olasılığı olabilir. Veri kümesi sürekli ise, örneğin sınıftaki öğrencilerin boyları gibi, θ normal dağılımın ortalaması olabilir.
Olabilirlik fonksiyonu, farklı θ değerleri için verinizi gözlemlemenin ne kadar olası olduğunu ölçer. Şöyle tanımlanır:
![]()
Sezgisel olarak, parametre θ belirli bir değer aldığında bu belirli veri kümesini gözlemleme olasılığı nedir diye soruyoruz.
Bu veri kümesi, θ ile parametreleştirilmiş model altında üretildikleri varsayılan tekil veri noktalarını (x₁, x₂, ..., xₙ) gözlemlemenin ortak olasılığı olarak temsil edilir.
Olasılığın zincir kuralını kullanarak yukarıdaki denklemi şu şekilde açabiliriz:
![]()
Ancak bu oldukça karmaşık bir denklem! Bu nedenle veri noktalarının bağımsız— daha spesifik olarak koşullu bağımsız— olduğunu varsayarız.
Böylece, ortak olasılığı tekil olasılıkların çarpımı olarak yazabiliriz:
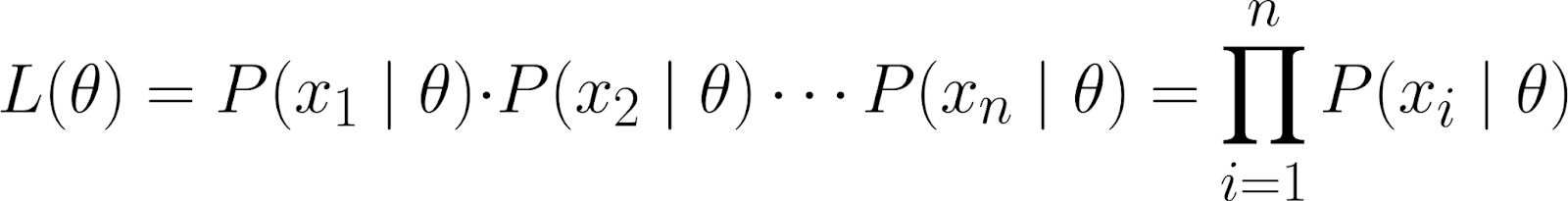
Gözlenen veri noktalarımızın θ üzerinde koşullu olarak bağımsız olduğunu varsaydığımız için şu denklem doğrudur:
![]()
Bunun nedeni, θ’nın değerini bildiğimizde x₁ ve x₂ veri noktalarının koşullu olarak bağımsız olduğunu varsaymış olmamızdır.
Artık, gözlenen veriyi en olası kılan, yani olabilirlik fonksiyonunu maksimize eden θ değer(ler)ini bulma konumundayız:
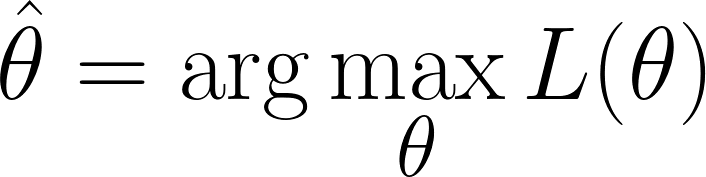
Ancak, olabilirlik fonksiyonumuzun bir çarpım içerdiğini unutmayın. Çarpımlarla çalışmak, özellikle çok sayıda veri noktası olduğunda zorlaşır. Bunu basitleştirmek için, olabilirlik fonksiyonunun logaritmasını alırız; çünkü bu, çarpımı toplamaya dönüştürür.
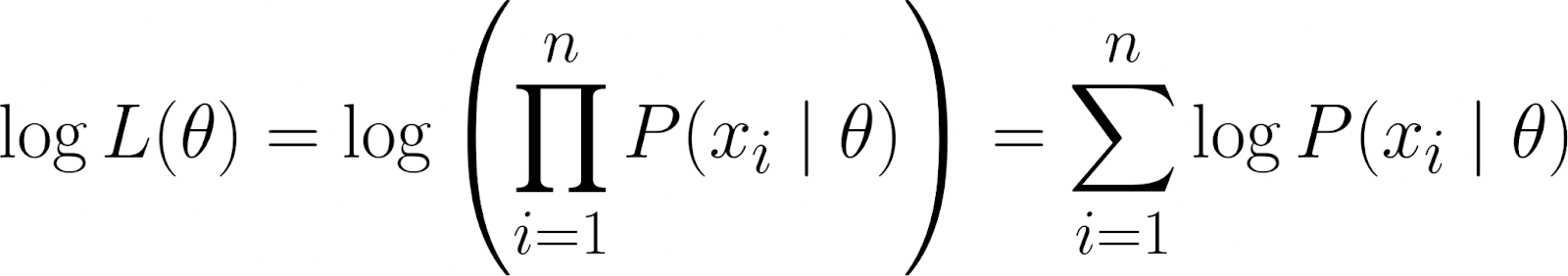
Bu bize log-olabilirliği verir ve bunun bazı faydalı özellikleri vardır:
Artık türev alabileceğimiz bir konumdayız; ancak makine öğrenmesinde genellikle kayıp fonksiyonlarımızı minimize etmek isteriz. Neyse ki bu oldukça kolay çözülebilir.
Fonksiyonumuzun başına bir eksi işareti ekleyerek (yani -1 ile çarparak) artık minimize etmemiz gereken kayıp fonksiyonunu elde ederiz; buna artık Negatif Log-Olabilirlik Kayıp Fonksiyonu denir.
Şimdi, θ değerini elde etmek için hesap kullanabiliriz. Log-olabilirliğin θ’ya göre türevini alıp sıfıra eşitler, ardından θ için çözeriz. Bunun nedeni, bir fonksiyonun minimumunun türevinin sıfır olduğu (ve ikinci türevinin pozitif olduğu) noktada gerçekleşmesidir.
Dolayısıyla, MLE için nihai denklem şöyledir:
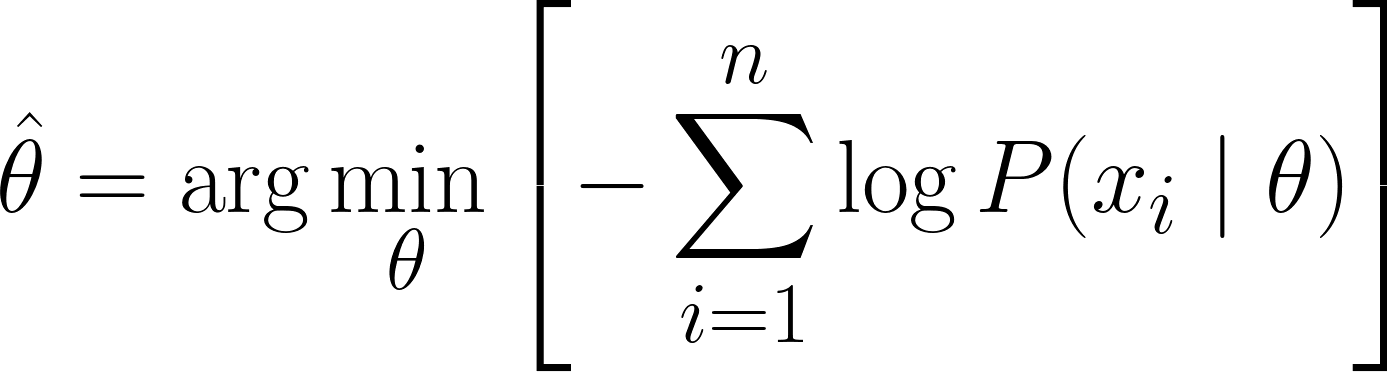
MLE Denklemini başarıyla türettiğimize göre, anlayışımızı pekiştirmek için bazı çözümlü örneklere bakalım.
Basit, ayrık bir örnekle başlayalım: hileli olabilecek bir zar ile altı gelme olasılığını tahmin etmek.
Diyelim ki zarı 12 kez atıyoruz ve sonuçları kaydediyoruz. Bu veriyi bir kategorik dağılım ile modellemek istiyoruz; ancak burada altı gelme olasılığı θ’yı (theta) tahmin etmeye odaklanalım. Bu örnekte:
Şimdi Olabilirlik fonksiyonunu hesaplıyoruz; 12 atışta 4 kez altı geldiği için şu ifadeyi elde ederiz:
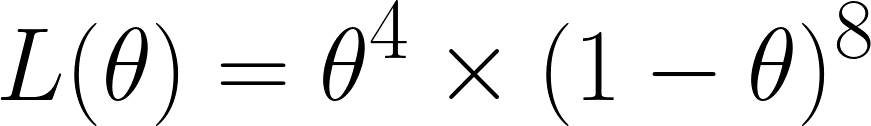
Bunu, 12 denemeden 4’ünde altı geldiği için θ⁴ terimine; 8’inde altı gelmediği için ise (1 - θ)⁸ terimine sahip olduğumuzdan elde ettik.
Unutmayın, bunları çarpıyoruz çünkü bunların koşullu olarak bağımsız olduğunu varsaydık.
Şimdi daha önce tartıştığımız gibi negatif log-olabilirliği alıyoruz ve şu denklemi elde ediyoruz:
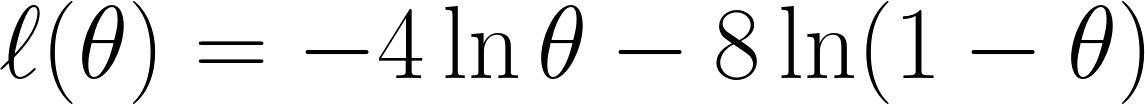
Son olarak, denklemin θ’ya göre türevini alır ve 0’a eşitleriz (minimum noktayı bulmak istediğimiz için):
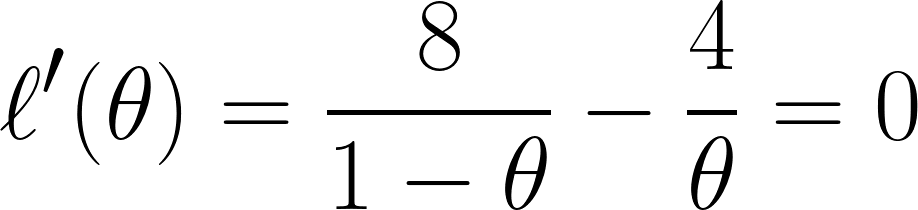
Ve bu denklem üzerinden θ’nın ⅓’e eşit olduğu sonucuna varırız.
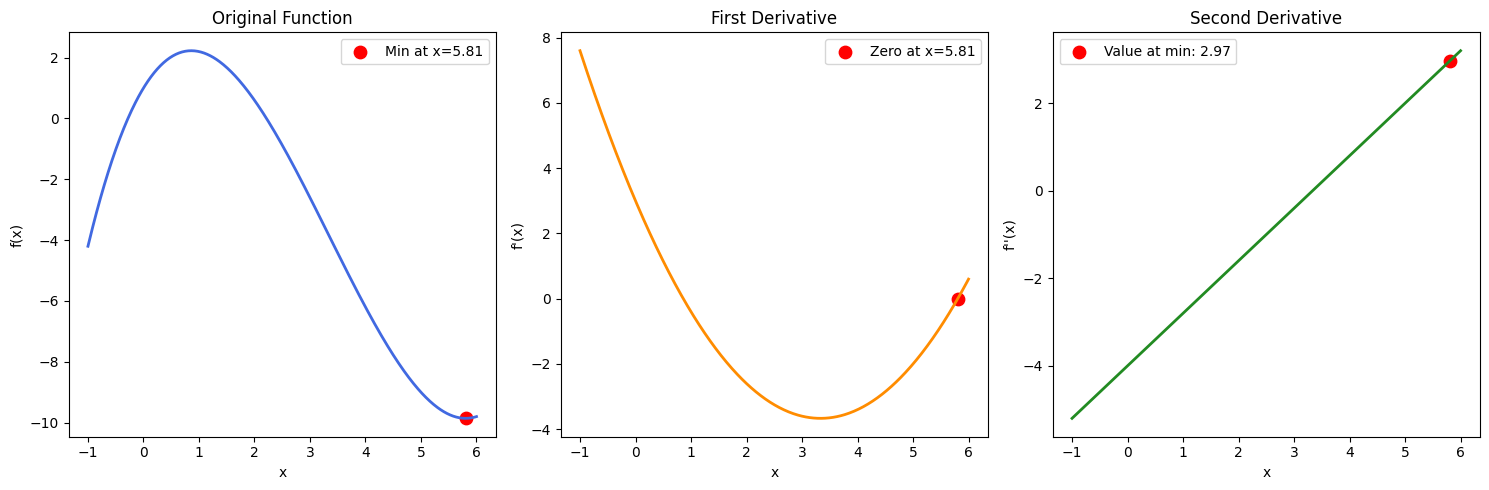
Not: Eğer θ için birden fazla çözüm elde etmiş olsaydık, ikinci türevi de bulmamız ve hangi θ değerlerinin pozitif sonuç verdiğine (minimum noktayı bulduğumuzu doğrulamak için) bakmamız gerekirdi. Bu, aşağıdaki görseldeki örnek fonksiyonla da gösterilebilir:
Şimdi sürekli bir örneğe bakalım — normal (Gauss) dağılımın ortalamasını tahmin etmek.
Diyelim ki 5 kişinin boylarından oluşan bir veri kümemiz var: 160, 165, 170, 175, 180 (cm cinsinden). Bunların, bilinmeyen ortalama μ (mu) ve bilinen varyans σ² (basitlik için σ² = 25 diyelim) ile normal bir dağılımdan geldiğini varsayacağız.
Normal dağılım (bilinen varyansla) için olabilirlik fonksiyonu şöyledir.
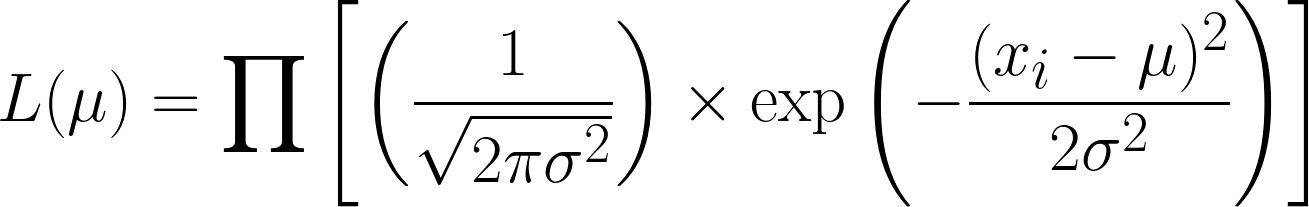
Bu oldukça karmaşık; ancak negatif log almak işleri kolaylaştırır. Umarız, denklemlerimizde log fonksiyonunu kullanmanın gücünü şimdi görebiliyorsunuzdur. Elde ettiğimiz denklem şudur:
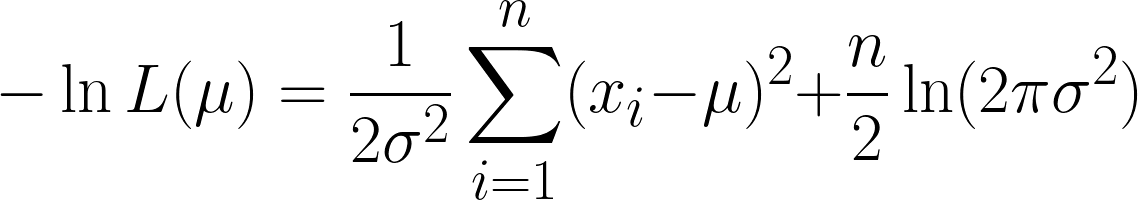
Burada iki terim elde ediyoruz; ancak türeve geçtiğimizde ikinci terimin göz ardı edilebileceğine dikkat edin; çünkü μ’ya göre türev alıyoruz ve ikinci terim μ içermiyor.
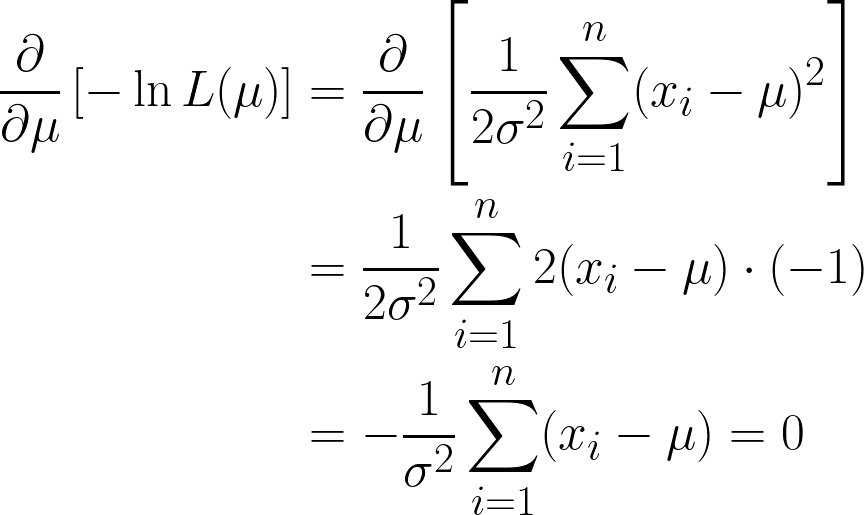
Neredeyse hazırız; ancak parantez içindeki μ’ya dikkat edin.
Bu bir sabit olduğundan, n kez toplandığında n*μ olacağı için basitçe n ile çarpabiliriz.
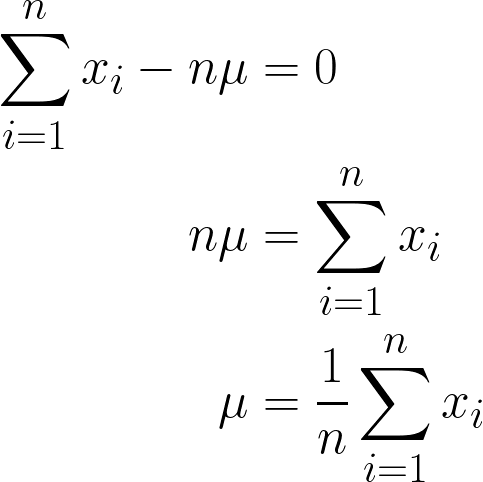
Elde ettiğimiz nihai yanıt sezgisel olarak da anlamlıdır; çünkü matematiksel olarak tüm x değerlerini toplayıp n’e bölmeyi (yani sahip olduğumuz gözlem sayısını) söyler ve bu, ortalamanın tanımıdır!
Dolayısıyla, bu denkleme veri değerlerimizi koyarak ortalamayı 170 cm olarak elde ederiz.
Bunu daha görsel hale getirmek için, μ’yu değiştirdikçe olabilirliğin nasıl değiştiğini gösteren bir animasyon:
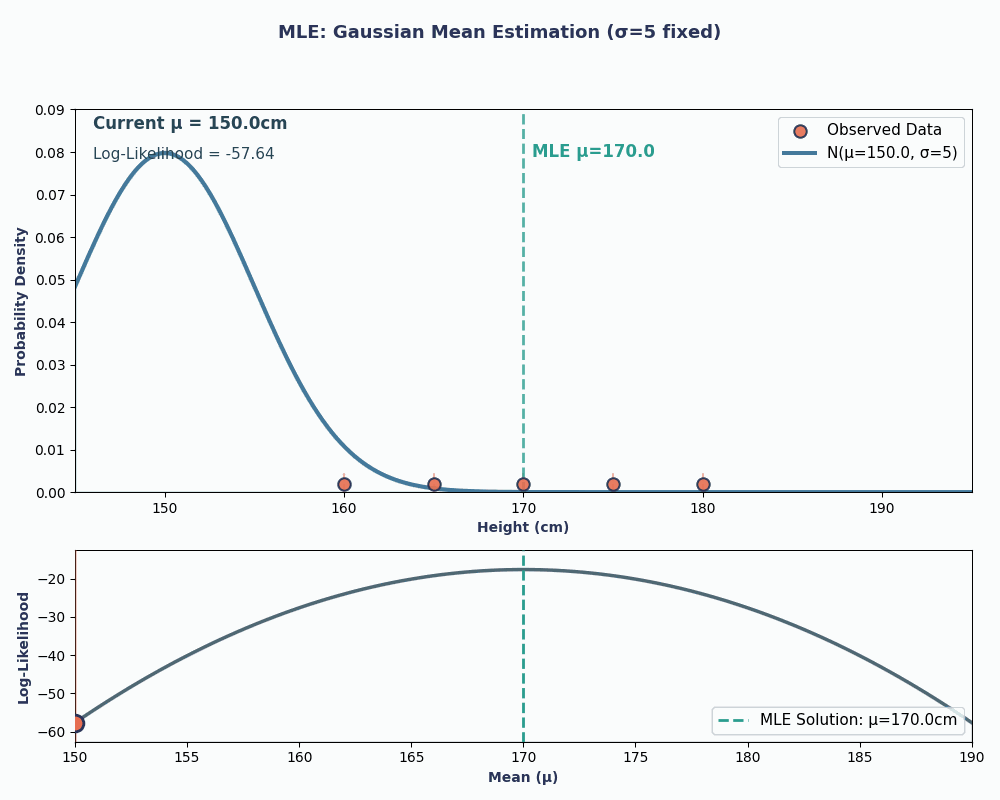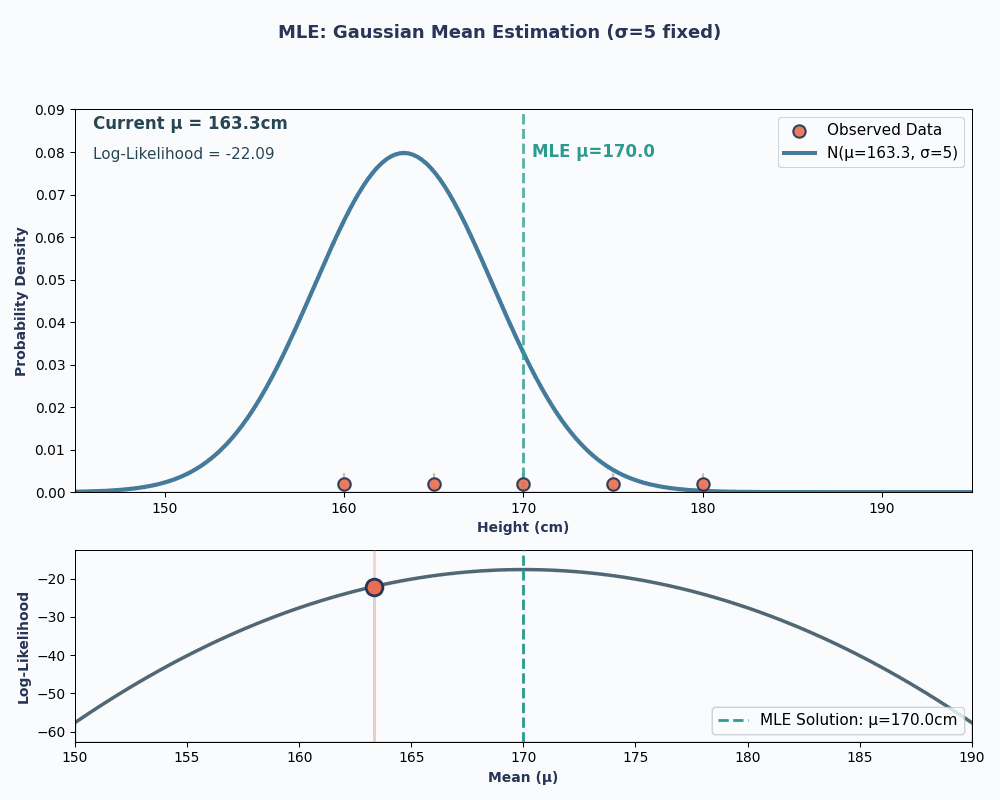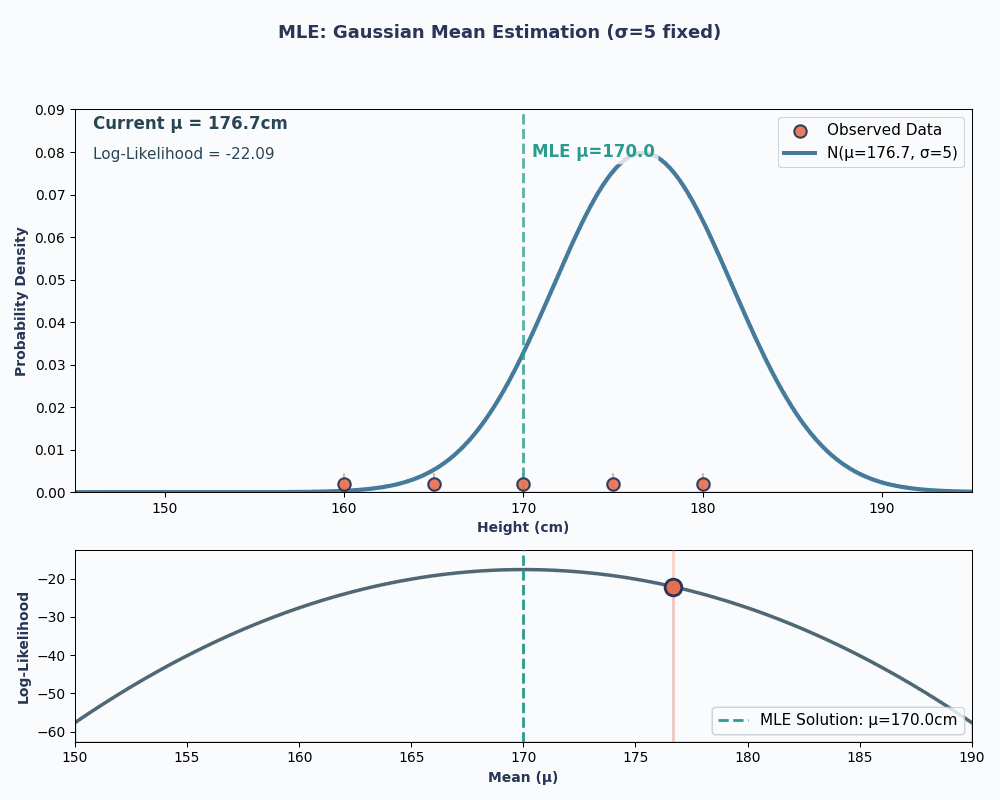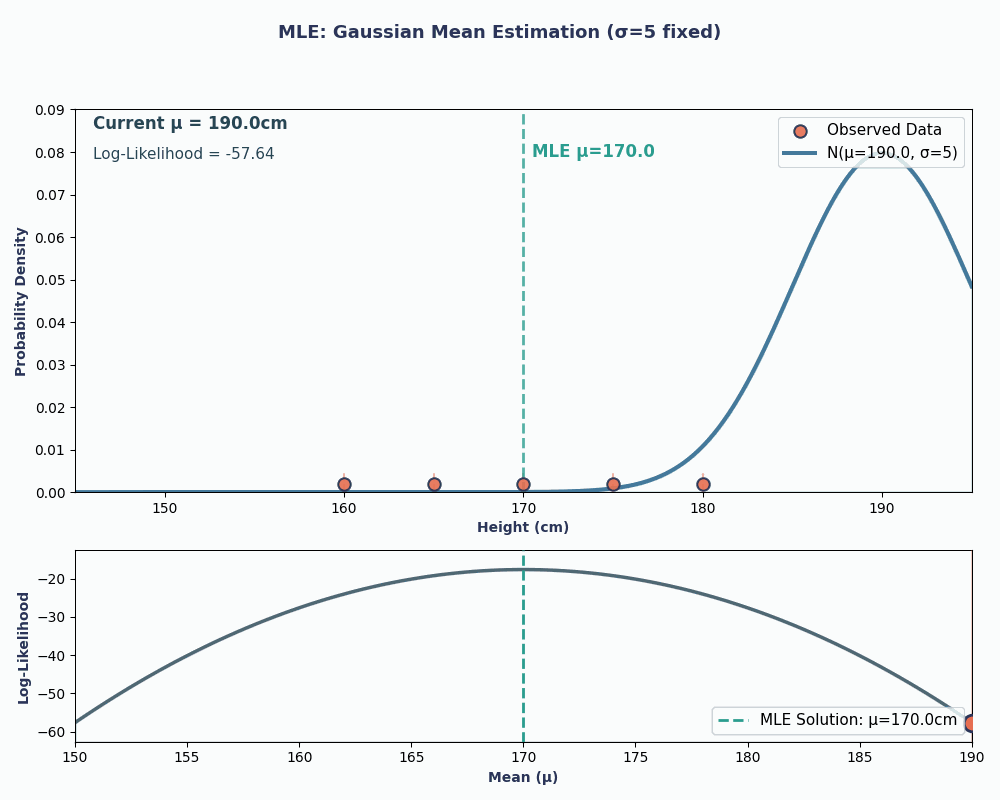
Her iki örnekte de MLE’yi kullanmak, seçilen model altında gözlenen verimizi en olası kılan parametre değerini verdi. Elbette, MLE bize birden fazla parametre değeri de verebilir; ancak hesap biraz daha uzun olur!
MLE’nin temel yapısını anladığımıza göre, bunu Python’da nasıl kodlayacağımıza bakalım. Önceki örneğin (boylar) çözümünü kodlayacağız.
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Önceki örneği kodlarken, ana MLE hesaplama mantığını içeren negative_log_likelihood() adlı bir fonksiyon oluşturduğumuzu fark edin; bu, Tek Değişkenli Gauss Dağılımı için MLE’yi hesaplıyordu.
Bir yandan, nihayetinde bu denklemi elle yazdığımız ve bu fonksiyonu minimize etmek için scipy.optimize kullandığımız söylenebilir. Elbette bu tamamen geçerli bir çözümdür; çünkü Gauss Dağılımı kapalı form bir çözüme sahiptir.
MLE çözümlerini hesaplamak için diğer yöntemleri keşfedelim.
Yukarıda tartıştığımız gibi, bazı şanslı durumlarda MLE denklemlerini analitik olarak çözebiliriz; yani parametre tahminleri için tam bir formül türetebiliriz. Bunlara kapalı form çözümler denir ve genellikle basit, sezgisel, kodlaması ve hesaplaması hızlıdır.
Şimdi önemli bir soru: Kapalı form çözümler ne zaman vardır?
|
Dağılım |
Tahmin Edilen Parametre |
Kapalı Form MLE Çözümü |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = başarı sayısı/n |
|
Binom |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gauss/Normal |
μ |
μ = 1/n*Σx_i |
Daha karmaşık modellerde analitik çözümler yoktur veya türetmek için fazla karmaşıktır. Bu durumlarda, sayısal optimizasyon yöntemleri kullanırız — log-olabilirliği maksimize eden parametreleri arayan yinelemeli algoritmalar. Kısaca açıklayalım:
Örneklerimiz ve hesaplarımızdan MLE’nin faydalı olduğu açıktır. Resmi olarak MLE’nin şu özellikleri vardır:
Bununla birlikte, MLE’nin en iyi seçenek olmayabileceği senaryolar vardır:
Bu bölümde, MLE’nin Makine Öğrenmesi ve Yapay Zekâ’da nerede kullanıldığına bakalım.
MLE’nin en önemli göründüğü yerlerden biri lojistik regresyondur. Burada, bir sonucun belirli bir sınıfa ait olma olasılığını (ör. müşteri kaybı) tahmin ederiz ve bunu, gözlenen sonuçların olabilirliğini maksimize edecek parametreleri uydurarak yaparız.
Hatta doğrusal regresyonda bile, hataların normal dağıldığını varsayarsak, en küçük kareler çözümü aslında MLE’ye karşılık gelir.
MLE, modelleri karşılaştırmak için de kullanılabilir.
Örneğin olabilirlik oranı testi (LRT), bir modele fazladan değişken eklemenin performansı anlamlı biçimde iyileştirip iyileştirmediğini kontrol etmeye yardımcı olur. Daha basit (sıfır) bir model ile daha karmaşık (alternatif) bir modelin olabilirliklerini karşılaştırarak çalışır.
Ayrıca, aşırı öğrenmeyi önlemek için karmaşıklığı cezalandıran Akaike Bilgi Kriteri (AIC) de vardır. Bu araçlar finans, tıp ve pazarlama gibi alanlarda yaygın olarak kullanılır.
Sadece olabilirliğin ötesinde, olasılık dağılımları arasındaki farkları ölçmenin başka yollarını keşfetmekle ilgileniyorsanız, şu eğitimime göz atın: KL-Uzaklığı Açıklaması.
Güçlü olsa da, bazı eksikleri vardır. Nerelerde zorlandığını ve bunun yerine neler kullanabileceğimizi kısaca gözden geçirelim.
MLE iyi çalışmadığında şu seçenekler mevcuttur:
Farklı yöntemler farklı durumlarda daha iyi çalışır. MLE her zaman cevap olmayabilir; ancak çoğu zaman harika bir başlangıç noktasıdır.
Maksimum Olabilirlik Tahmini, parametre tahmini için en doğal ve en yaygın yöntemlerden biridir. Gözlenen veriyi olabildiğince olası kılma fikrine dayanır ve bu nedenle yazı-tura, Gauss dağılımlı boylar gibi pek çok farklı senaryoda kullanılabilir.
MLE, modeller arasında uyarlanabilir ve veriyle ölçeklenebilir; hem matematiksel zarafet hem de pratik güç sunar. Küçük veya dağınık veri kümelerinde bazı eksikleri olsa da, Makine Öğrenmesi ve Yapay Zekâ öğrenilirken temel bir araç olmaya devam eder.
Makine öğrenmesi yolculuğunuzdaysanız, denetimli, denetimsiz ve derin öğrenmeyi kapsayan Python ile Makine Öğrenmesi Bilimcisi kariyer yolumuza mutlaka göz atın.
Maksimum Olabilirlik Tahmini’ni pratik alıştırmalarla pekiştirmeye hazır mısınız? Bu kaynaklar bilginizi uygulamanıza ve deneyim kazanmanıza yardımcı olabilir:
Öne Çıkan DataCamp Kursları
Program
Program
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
