
Track
Machine Learning Fundamentals in Python
16 hr
Estimating parameters is a fundamental step in statistical analysis and machine learning. Among the various methods available, Maximum Likelihood Estimation (MLE) is one of the most widely used approaches due to its intuitive nature, mathematical rigor, and broad applicability across different types of data and models.
In this article, you'll learn what MLE is, explore its mathematical foundations through detailed derivations and examples, and discover practical computational methods for implementing MLE effectively.
Maximum likelihood estimation (MLE) is an important statistical method used to estimate the parameters of a probability distribution by maximizing the likelihood function.
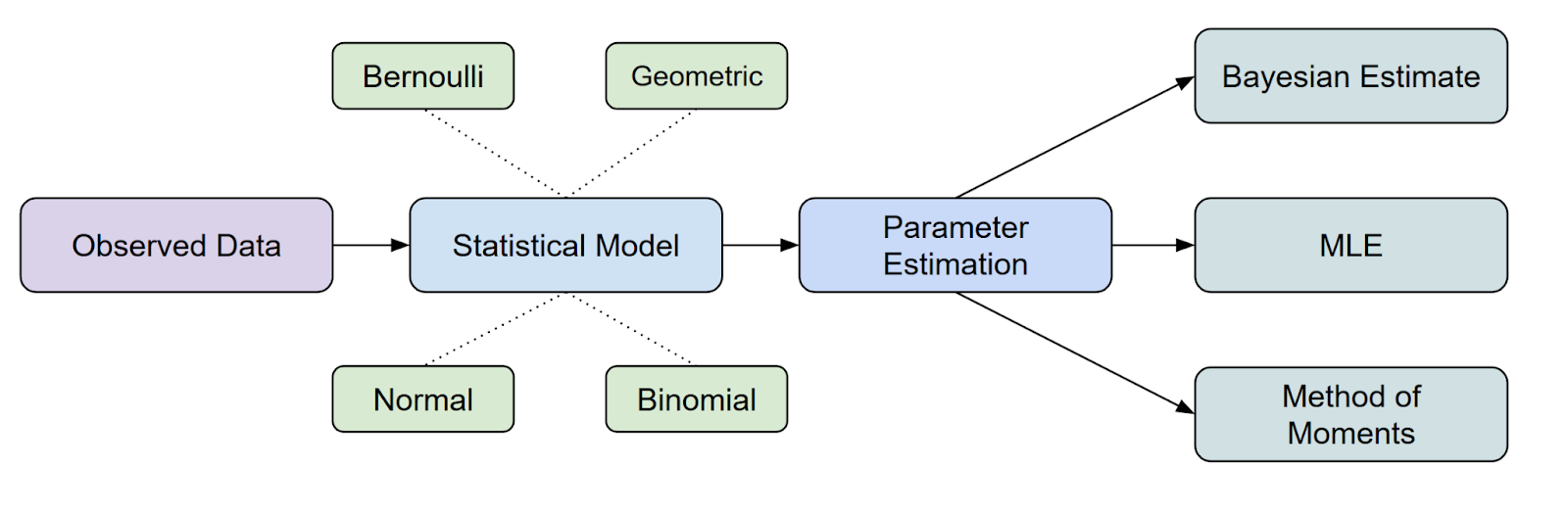
In terms of where MLE fits in statistical inference, it is one of the most common methods we have to estimate parameters.
However, here you might have another question. What is a likelihood function? Let's discuss this further.
We can think of the likelihood function as a way to measure how well a particular set of parameters explains the data you have observed.
In other words, it answers the question: “Given these parameter values, how likely is it that I would see this data?” But there is a common misconception here between Probability and Likelihood:
Thus, to summarize, the likelihood function takes the parameters of your model as input and gives you a number that represents how plausible those parameters are, given your data.
The higher the value of the likelihood function, the better those parameters explain your data.
To put it even more simply, the likelihood function helps us “score” different parameter choices, so we can pick the ones that make our observed data most probable.
Now that we have understood the difference between Probability and Likelihood, as well as what MLE is used for, let's proceed to the underlying mathematics. 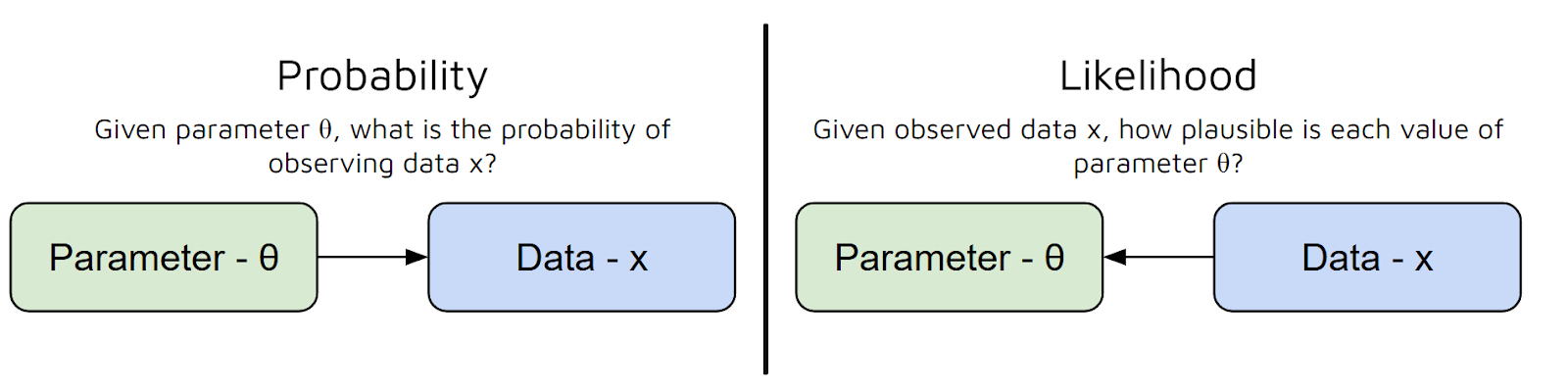
Before we jump into specific examples, let’s see how the maximum likelihood estimator (MLE) is derived in general. We will go through each step and also explain the reasoning behind it.
Let’s suppose we have a dataset: x₁, x₂, ..., xₙ. We believe these data points are generated from a probability distribution that depends on some unknown parameter θ (theta). Our main goal is to estimate θ.
For example, if our dataset were about coin flips, θ could be the probability of heads. If the dataset were continuous, like the heights of students in the class, θ could be the mean of a normal distribution.
The likelihood function measures how likely it is to observe your data for different values of θ. It is defined as:
![]()
Intuitively, we are asking, given that the parameter θ takes a specific value, what is the probability of observing this particular dataset?
This dataset is represented as the joint probability of observing the individual data points (x₁, x₂, ..., xₙ), assuming they were generated under the model parameterized by θ.
Using the chain rule of probability, we can expand the above equation into this:
![]()
However, this is quite a complicated equation! So we make the assumption that the data points are independent - more specifically, conditionally independent.
By doing so, we can get the joint probability to be the product of individual probabilities:
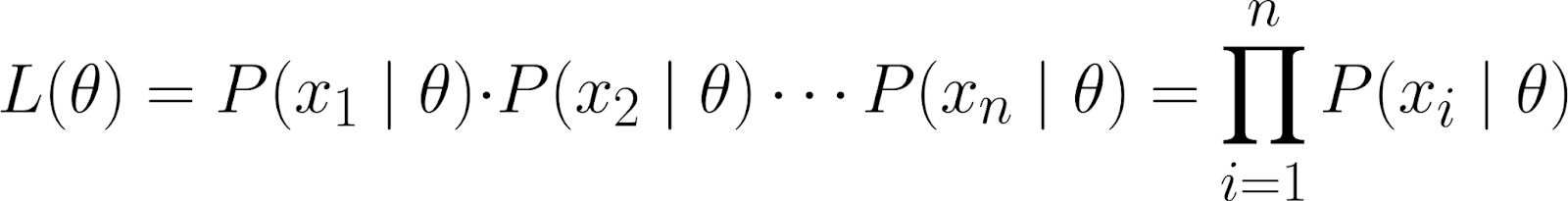
Since our observed data points are conditionally independent on θ, we know the following equation is true:
![]()
This is because we have assumed that once we know the value of θ, the data points x₁ and x₂ are conditionally independent.
We are in the position where we have to find the values of θ which maximizes the likelihood function(i.e, it makes the observed data most likely):
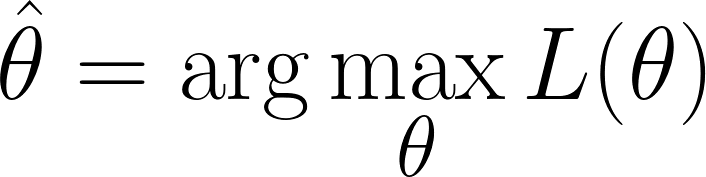
However, recall that our likelihood function contains a product. Working with products can get messy, especially with lots of data points. To simplify, we take the logarithm of the likelihood function since this converts the product into a summation.
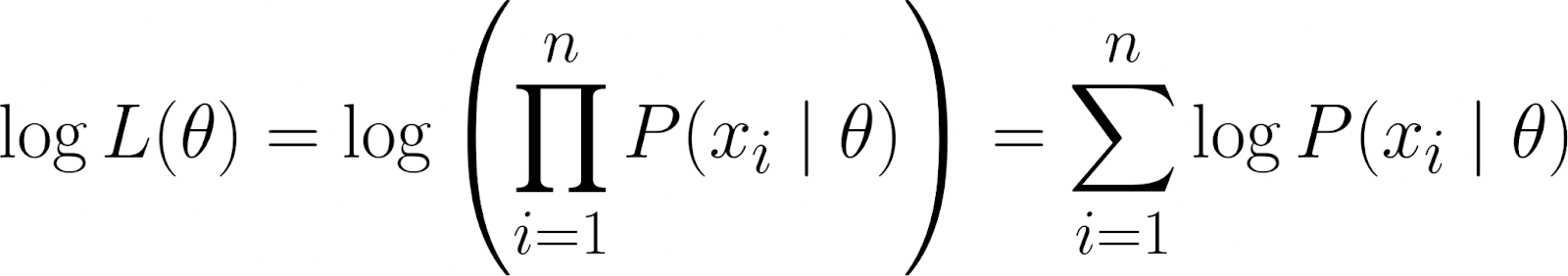
This gives us the log-likelihood, which has some beneficial properties:
We are now at a place where we can differentiate, however in machine learning, we tend to want our loss functions to be minimized. Luckily, this is quite an easy fix.
By including a minus symbol (i.e., multiplying by -1) at the start of our function, we now need to minimize our loss function, which is now called the Negative Log-Likelihood Loss Function.
Now, we can use calculus to obtain the value of θ. By taking the derivative of the log-likelihood with respect to θ, setting it to zero, and solving for θ. This is because the minimum of a function occurs where its derivative is zero (and the second derivative is positive).
Therefore, the final equation for MLE is:
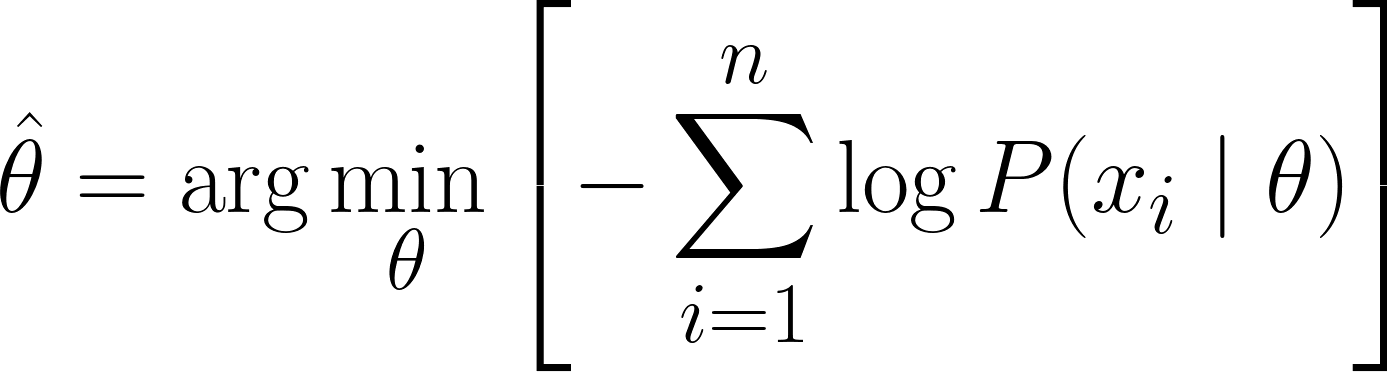
Since we have successfully derived the MLE Equation, let's look at some worked examples to solidify our understanding.
Let’s start with a simple, discrete example: estimating the probability of rolling a six with a possibly biased die.
Suppose we roll a die 12 times and record the results. We want to model this data using a categorical distribution, but let’s focus on estimating the probability θ (theta) of rolling a six. In this example:
Now we calculate the Likelihood function, which, because we got 4 sixes out of 12 rolls, we would obtain:
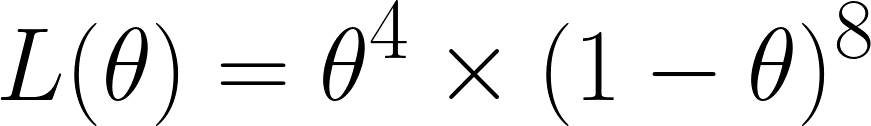
We obtained this since out of the 12 times, we obtain sixes 4 times - hence we have θ⁴ and we obtained non-sixes 8 times - hence we have the (1 - θ)⁸ term.
Recall, we have multiplied these since we have assumed that these are conditionally independent.
Now we take the negative log-likelihood as we previously discussed, giving us this equation:
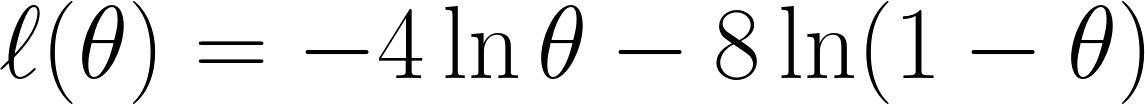
Finally, we differentiate the equation with respect with θ and set it to 0 (since we want to find the minimum point):
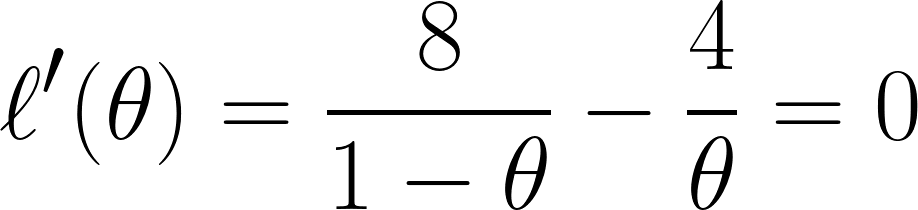
And through this equation, we can conclude that θ is equal to ⅓ .
Note: If we had obtained multiple solutions of θ, then we would have to also find the second derivative and see which θ values would give us a positive result (to confirm we have found a minimum point). This can be confirmed through an example function in the image below:
Let’s now look at a continuous example - estimating the mean of a normal (Gaussian) distribution.
Lets suppose we have a dataset of the heights of 5 people: 160, 165, 170, 175, 180 (in cm). We will also assume these are drawn from a normal distribution with unknown mean μ (mu) and known variance σ² (let’s say σ² = 25 for simplicity).
The likelihood function for the normal distribution (with known variance) is.
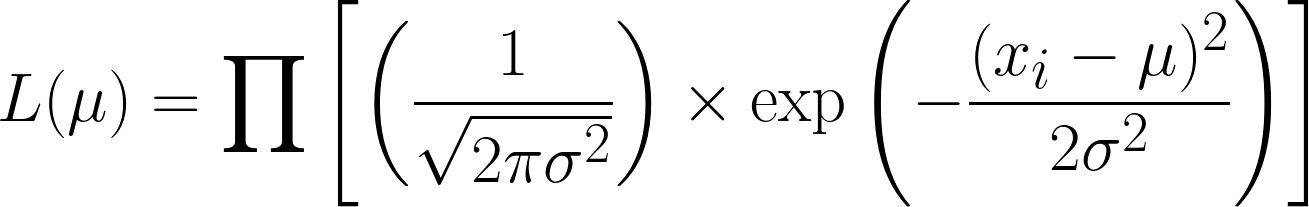
This is very complicated but taking the negative log makes things easier. Hopefully, you can now see the power of using the log function in our equation. The equation we obtain is this:
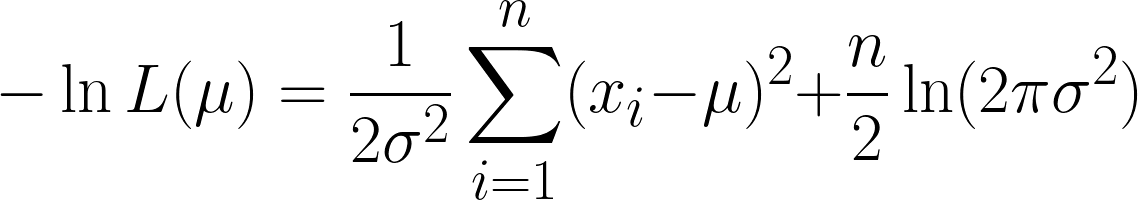
We obtain two terms here, but note how the second term can be disregarded when we proceed with differentiation, since we are differentiating with respect to μ, and the second term does not contain μ.
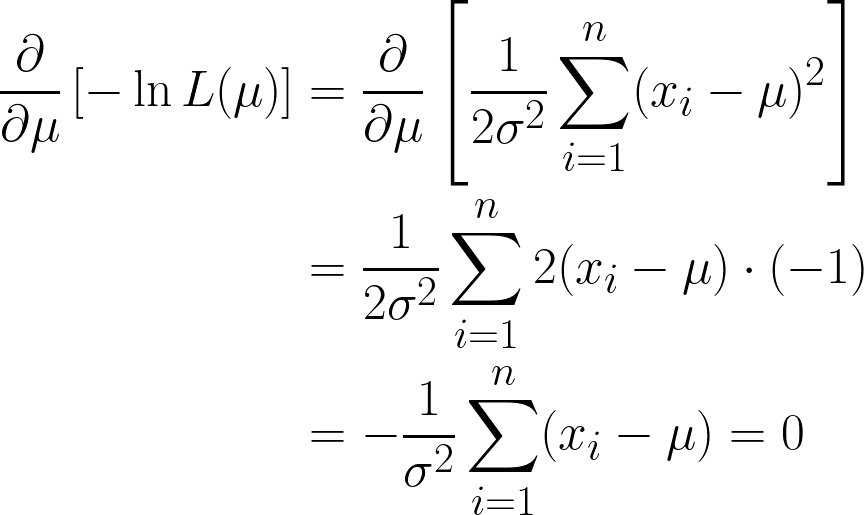
We are almost there, but take a look at μ in the brackets.
Since it is a constant, we can simply multiply it by n, since adding μ n-times, will simply be n*μ.
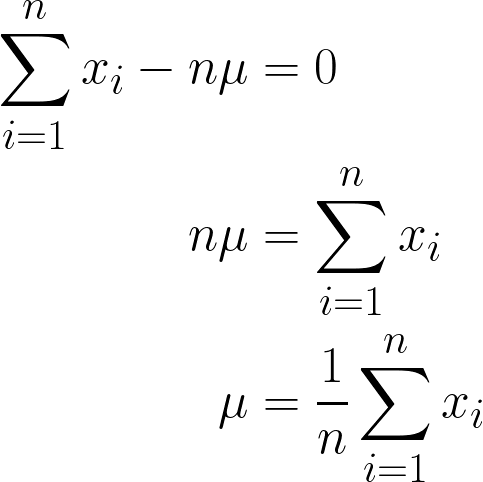
The final answer we have obtained should make intuitive sense, since it is mathematically stated to sum all values of x and divide by n (which is the number of observations we have), and this is also the mean’s definition!
Thus, by putting in our data values to this equation, we can obtain the mean to be 170cm.
To make this more visual, here is an animation showing how the likelihood changes as we change μ:
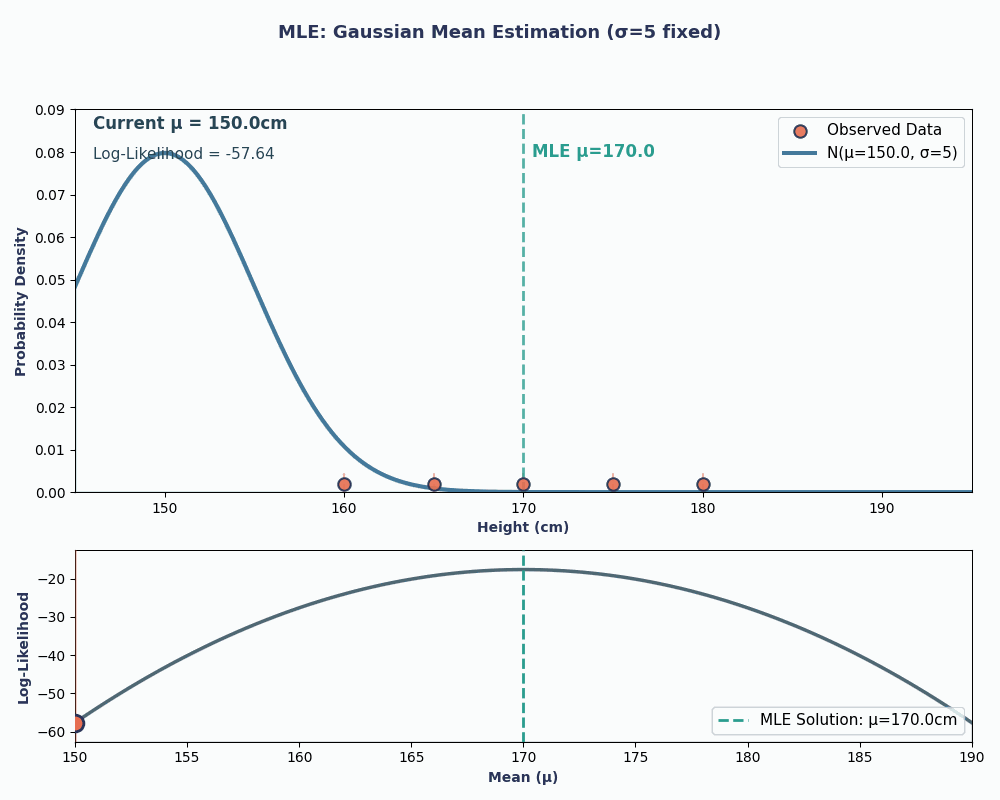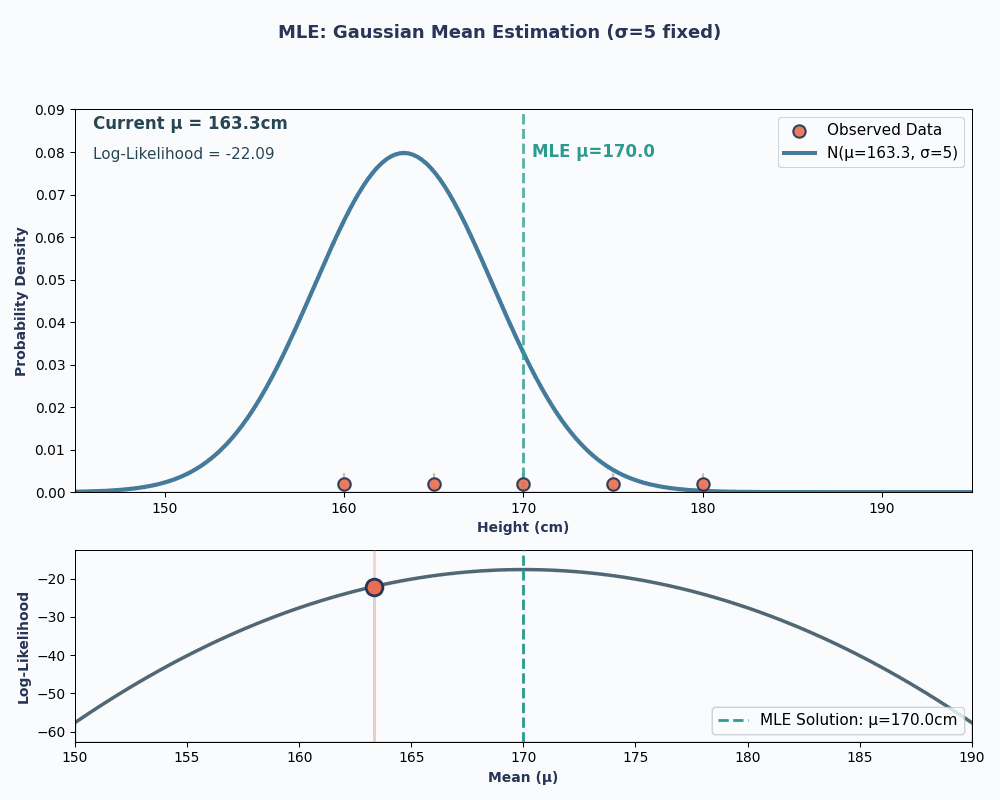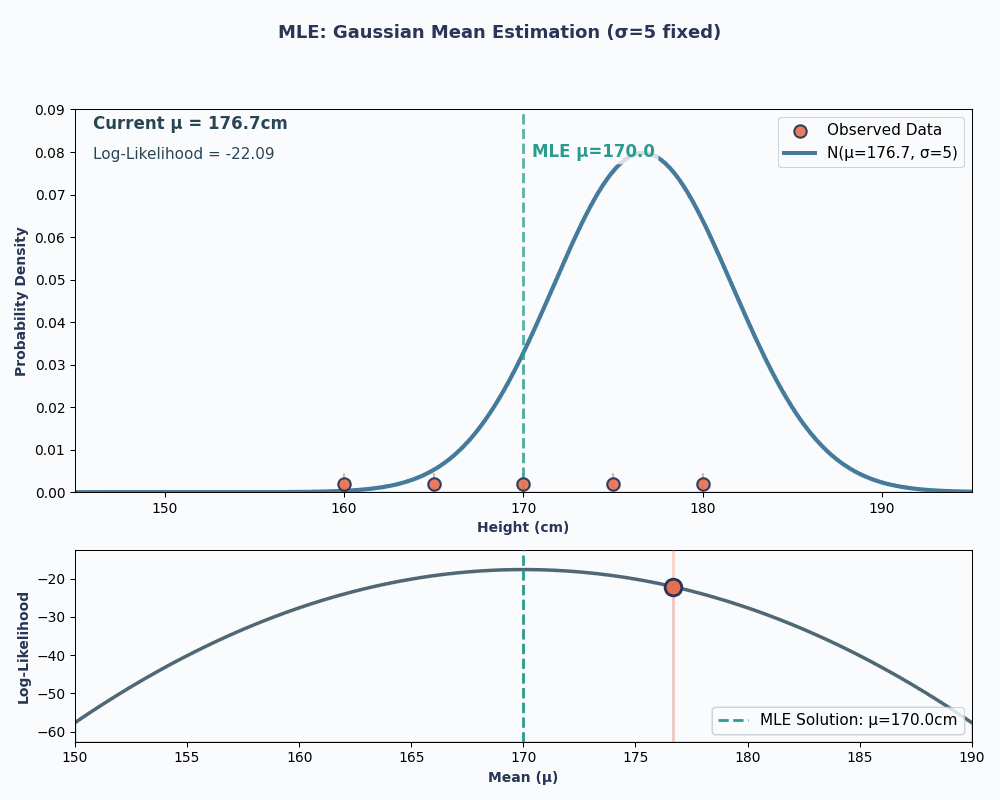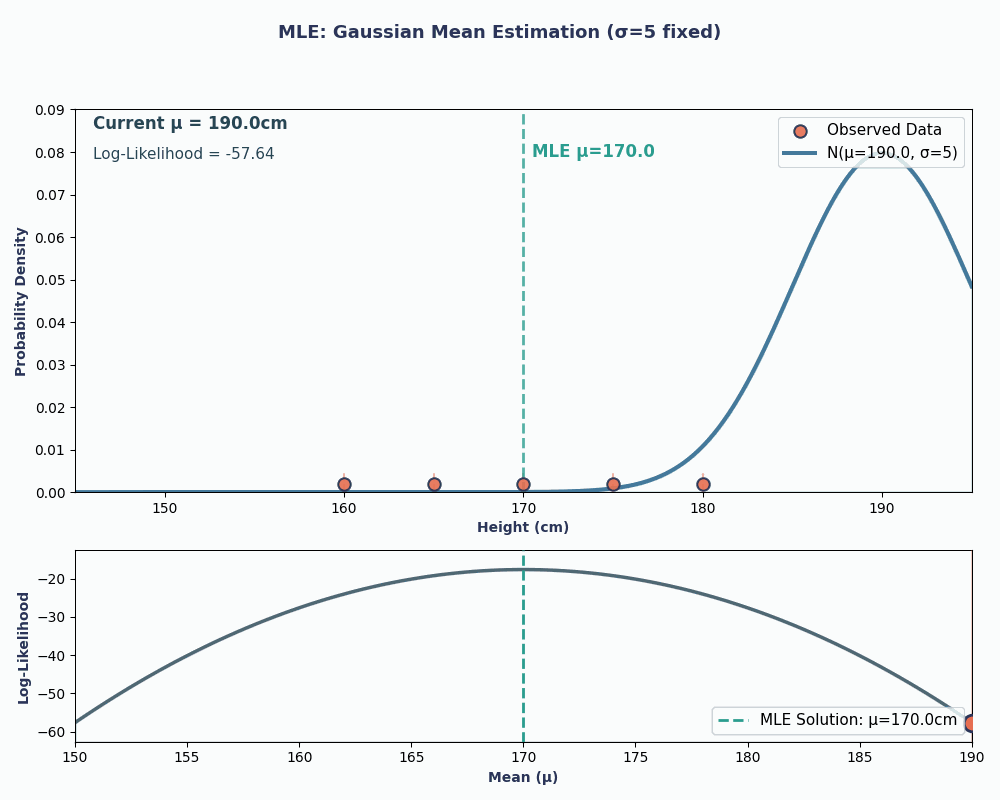
In both examples, using MLE gave us the parameter value that made our observed data most probable under the chosen model. Obviously, MLE can work with giving us multiple parameter values as well, although the calculation would be slightly longer!
Now that we have understood the underlying structure of MLE, let’s see how to code this in Python. We will be coding the previous example (heights) solution.
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Notice when we were coding the previous example, we had created a function negative_log_likelihood() which contained the main logic for calculating the MLE of a Univariate Gaussian Distribution.
On the one hand, it could be argued that we ultimately hard-coded this equation, and we used the scipy.optimize to minimize that function. Of course, this is still a completely viable solution, since the Gaussian Distribution has a closed form solution.
Let’s explore other methods to compute solutions for MLE.
As we discussed above, in some fortunate cases, we can solve the MLE equations analytically, which means we can derive an exact formula for the parameter estimates. These are known as closed-form solutions, and they are often simple, intuitive, and fast to code and compute.
An important question to ask now is, when do closed-form solutions exist?
|
Distribution |
Parameter Estimated |
Closed-form MLE Solution |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = #number of success/n |
|
Binomial |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gaussian/Normal |
μ |
μ = 1/n*Σx_i |
For more complex models, analytical solutions don't exist or are too complicated to derive. In these cases, we use numerical optimization methods - iterative algorithms that search for the parameters that maximize the log-likelihood. Let’s briefly explain them:
From our examples and calculations, it is clear that MLE is useful. Formally speaking, MLE has the following properties:
However, there are scenarios where using MLE might not be the best option:
In this section, let’s explore where MLE is actually used in Machine Learning and AI.
One of the most important places MLE appears is in logistic regression. Here, we are estimating the probability that an outcome belongs to a certain class (such as customer churn) and we do this by fitting parameters to maximize the likelihood of the observed outcomes.
Even in linear regression, if we assume normally distributed errors, then the least squares solution actually turns out to be the MLE too.
MLE can also be used to compare models.
For example, the likelihood ratio test (LRT) helps us check if adding extra variables to a model significantly improves its performance. It works by comparing the likelihoods of two models: one simpler (null), one more complex (alternative).
We also have the Akaike Information Criterion (AIC), which penalizes complexity to avoid overfitting. These tools are widely used in fields like finance, medicine, and marketing.
If you're interested in further exploring ways to measure differences between probability distributions beyond likelihood alone, check out my tutorial: KL-Divergence Explained.
Although it is powerful, it does have its drawbacks. Let's quickly go over where it struggles, and what we can use instead.
When MLE doesn’t work well, here are some options:
Different methods work better in different situations. MLE might not always be the answer, but it’s often a great starting point.
Maximum Likelihood Estimation is one of the most natural and widely used methods for parameter estimation. It is the idea of making the observed data as probable as possible, and thus can be used in many different scenarios, such as coin flips, Gaussian heights, etc.
MLE can adapt across models and scale with data, offering both mathematical elegance and practical power. Although it does have its own drawbacks, especially in small or messy datasets, it remains a foundational tool when learning Machine Learning and AI.
If you’re on your machine learning journey, be sure to check out our Machine Learning Scientist in Python career track, which explores supervised, unsupervised, and deep learning.
Ready to deepen your understanding of Maximum Likelihood Estimation with practical exercises? These resources can help you apply your knowledge and gain hands-on experience:
Top DataCamp Courses
Track
Track
Course
cheat-sheet
Karlijn Willems
Tutorial
Aditya Sharma
Tutorial
Mark Pedigo
Tutorial
Joanne Xiong
Tutorial
Vinod Chugani
code-along
George Boorman


