
Tracks
Cơ bản về Học máy trong Python
16 giờ
Ước lượng tham số là một bước nền tảng trong phân tích thống kê và học máy. Trong số nhiều phương pháp hiện có, Ước lượng Hợp lý Tối đa (Maximum Likelihood Estimation - MLE) là một trong những cách tiếp cận được sử dụng rộng rãi nhất nhờ tính trực quan, chặt chẽ về mặt toán học và khả năng áp dụng rộng trên nhiều loại dữ liệu và mô hình khác nhau.
Trong bài viết này, bạn sẽ học MLE là gì, khám phá nền tảng toán học của nó qua các phép suy diễn chi tiết và ví dụ, đồng thời tìm hiểu các phương pháp tính toán thực tiễn để triển khai MLE hiệu quả.
Ước lượng hợp lý tối đa (MLE) là một phương pháp thống kê quan trọng dùng để ước lượng các tham số của một phân phối xác suất bằng cách tối đa hóa hàm hợp lý.
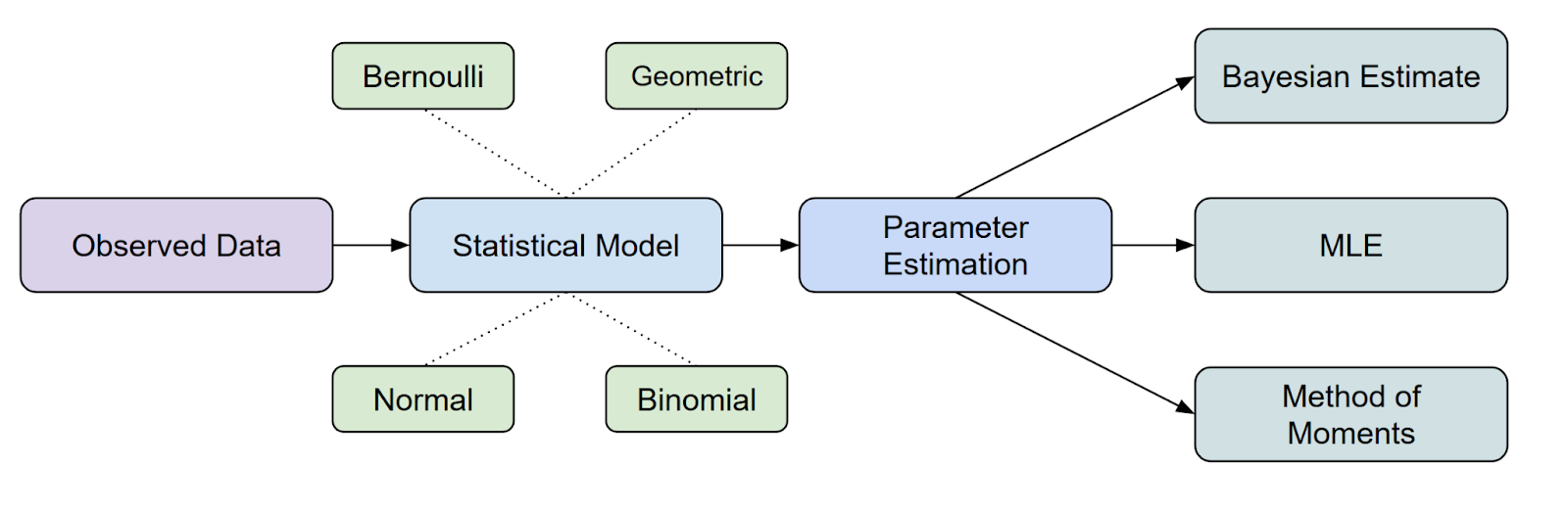
Xét về vị trí của MLE trong suy luận thống kê, đây là một trong những phương pháp phổ biến nhất để ước lượng tham số.
Tuy nhiên, bạn có thể có thêm một câu hỏi: Hàm hợp lý là gì? Hãy bàn luận thêm.
Ta có thể coi hàm hợp lý là cách đo lường mức độ một tập tham số cụ thể giải thích tốt dữ liệu bạn quan sát được như thế nào.
Nói cách khác, nó trả lời câu hỏi: “Với các giá trị tham số này, khả năng tôi nhìn thấy dữ liệu này là bao nhiêu?” Nhưng có một sự nhầm lẫn phổ biến giữa Xác suất và Hợp lý:
Tóm lại, hàm hợp lý nhận tham số của mô hình làm đầu vào và cho ra một con số biểu thị mức độ hợp lý của các tham số đó dựa trên dữ liệu của bạn.
Giá trị của hàm hợp lý càng cao, các tham số đó càng giải thích tốt dữ liệu của bạn.
Nói đơn giản hơn, hàm hợp lý giúp chúng ta “chấm điểm” các lựa chọn tham số khác nhau, để chọn ra những tham số khiến dữ liệu quan sát có xác suất cao nhất.
Giờ đây ta đã hiểu sự khác nhau giữa Xác suất và Hợp lý, cũng như MLE dùng để làm gì, hãy chuyển sang phần toán học nền tảng.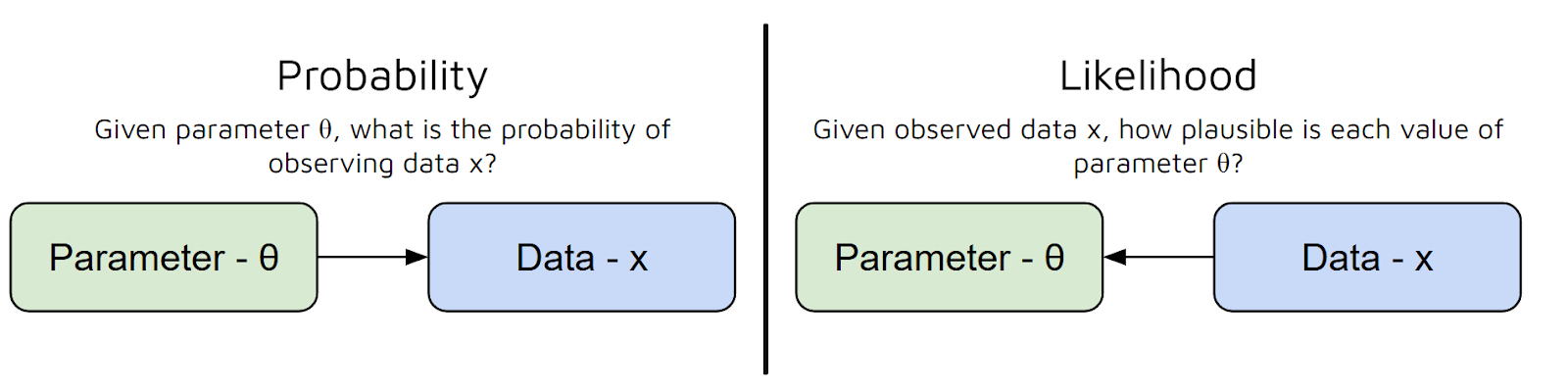
Trước khi đi vào các ví dụ cụ thể, hãy xem bộ ước lượng hợp lý tối đa (MLE) được suy ra như thế nào ở mức tổng quát. Chúng ta sẽ đi qua từng bước và giải thích lý do đằng sau.
Giả sử ta có một bộ dữ liệu: x₁, x₂, ..., xₙ. Ta tin rằng các điểm dữ liệu này được sinh ra từ một phân phối xác suất phụ thuộc vào một tham số chưa biết θ (theta). Mục tiêu chính của chúng ta là ước lượng θ.
Ví dụ, nếu bộ dữ liệu là về tung đồng xu, θ có thể là xác suất ra mặt ngửa. Nếu dữ liệu là liên tục, như chiều cao của học sinh trong lớp, θ có thể là trung bình của phân phối chuẩn.
Hàm hợp lý đo lường khả năng quan sát được dữ liệu của bạn đối với các giá trị θ khác nhau. Nó được định nghĩa như sau:
![]()
Trực giác mà nói, ta đang hỏi: với tham số θ nhận một giá trị cụ thể, xác suất quan sát được bộ dữ liệu này là bao nhiêu?
Bộ dữ liệu này được biểu diễn dưới dạng xác suất kết hợp của việc quan sát các điểm dữ liệu riêng lẻ (x₁, x₂, ..., xₙ), giả sử chúng được sinh ra theo mô hình tham số hóa bởi θ.
Sử dụng quy tắc dây chuyền của xác suất, ta có thể khai triển phương trình trên thành:
![]()
Tuy nhiên, đây là một phương trình khá phức tạp! Vì vậy ta đưa ra giả định rằng các điểm dữ liệu là độc lập - cụ thể hơn là độc lập có điều kiện.
Nhờ vậy, ta có thể đưa xác suất kết hợp về tích của các xác suất riêng lẻ:
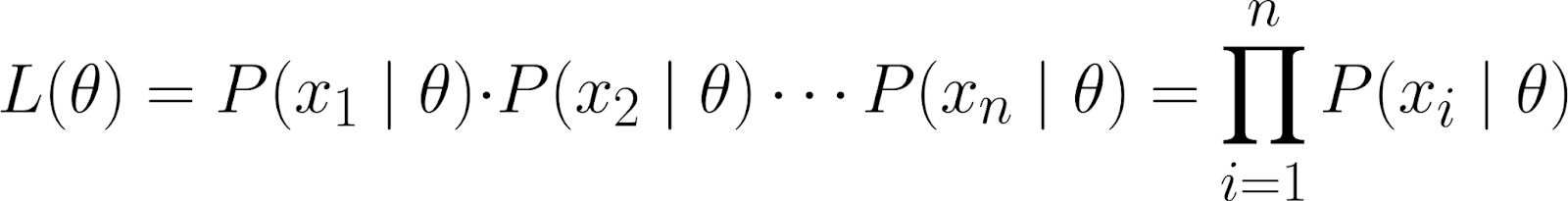
Vì các điểm dữ liệu quan sát được là độc lập có điều kiện theo θ, ta biết phương trình sau đúng:
![]()
Đó là bởi ta giả định rằng khi biết giá trị của θ, các điểm dữ liệu x₁ và x₂ là độc lập có điều kiện.
Giờ chúng ta cần tìm các giá trị θ tối đa hóa hàm hợp lý (tức là làm cho dữ liệu quan sát trở nên có khả năng nhất):
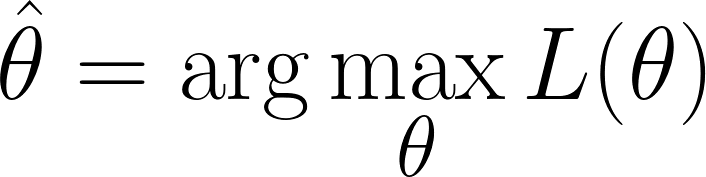
Tuy nhiên, nhớ rằng hàm hợp lý của chúng ta chứa một tích. Làm việc với tích có thể rối rắm, đặc biệt khi có nhiều điểm dữ liệu. Để đơn giản hóa, ta lấy logarit của hàm hợp lý vì điều này biến tích thành tổng.
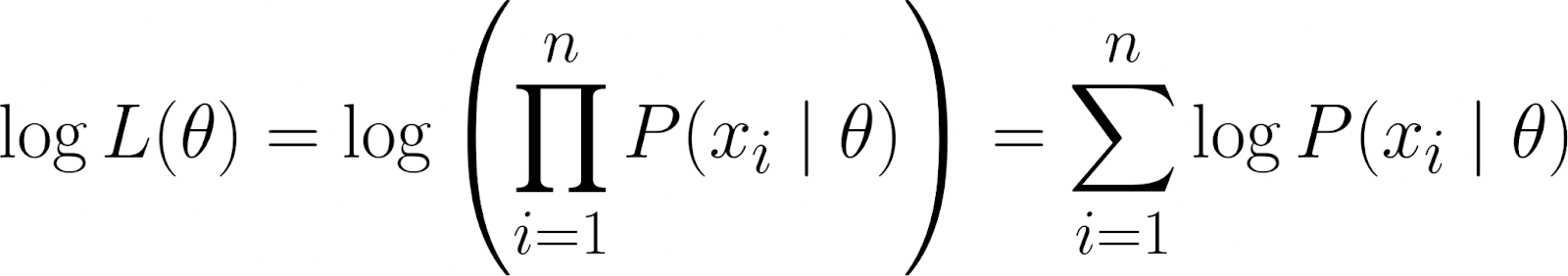
Điều này cho ta log-hợp lý, có một số tính chất hữu ích:
Giờ chúng ta có thể lấy đạo hàm, tuy nhiên trong học máy, ta thường muốn hàm mất mát được tối thiểu hóa. May mắn là việc này khá đơn giản.
Bằng cách thêm dấu trừ (tức nhân với -1) ở đầu hàm, giờ ta cần tối thiểu hóa hàm mất mát, hiện được gọi là Hàm Mất mát Log-Hợp lý Âm (Negative Log-Likelihood).
Giờ ta có thể dùng giải tích để thu được giá trị của θ. Bằng cách lấy đạo hàm của log-hợp lý theo θ, đặt bằng 0 và giải θ. Điều này là vì điểm cực tiểu của một hàm xảy ra khi đạo hàm của nó bằng 0 (và đạo hàm bậc hai dương).
Vì vậy, phương trình cuối cùng cho MLE là:
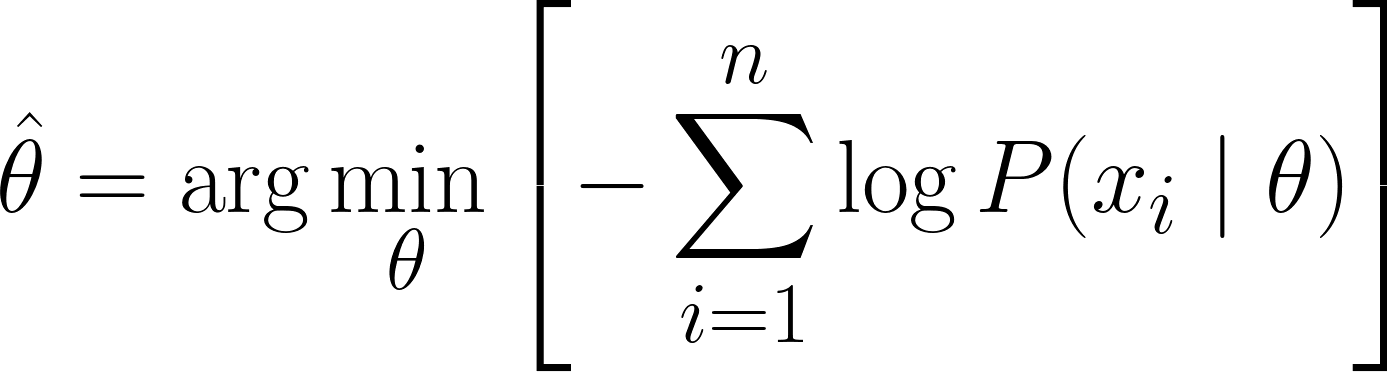
Vì ta đã suy ra thành công phương trình MLE, hãy xem một vài ví dụ đã giải để củng cố hiểu biết.
Hãy bắt đầu với một ví dụ rời rạc, đơn giản: ước lượng xác suất gieo được mặt sáu với một con xúc xắc có thể bị lệch.
Giả sử chúng ta gieo xúc xắc 12 lần và ghi lại kết quả. Ta muốn mô hình hóa dữ liệu này bằng phân phối phân loại (categorical), nhưng hãy tập trung vào việc ước lượng xác suất θ (theta) gieo được mặt sáu. Trong ví dụ này:
Giờ ta tính hàm Hợp lý; vì ta được 4 lần mặt sáu trong 12 lần gieo, ta thu được:
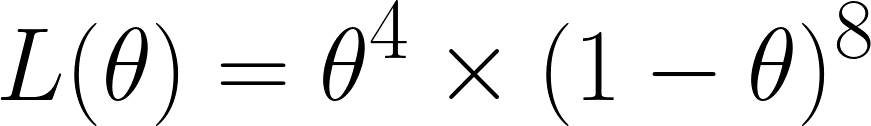
Ta thu được như vậy vì trong 12 lần, ta được mặt sáu 4 lần - do đó có θ⁴ và không phải mặt sáu 8 lần - do đó có hạng (1 - θ)⁸.
Nhớ rằng ta đã nhân các hạng này vì ta giả định chúng độc lập có điều kiện.
Giờ ta lấy log-hợp lý âm như đã thảo luận, cho ta phương trình sau:
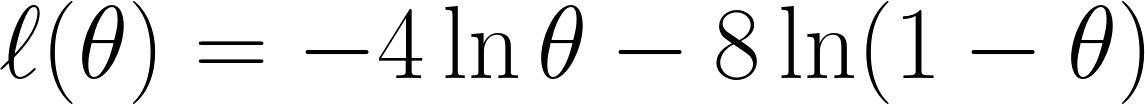
Cuối cùng, ta lấy đạo hàm phương trình theo θ và đặt bằng 0 (vì ta muốn tìm điểm cực tiểu):
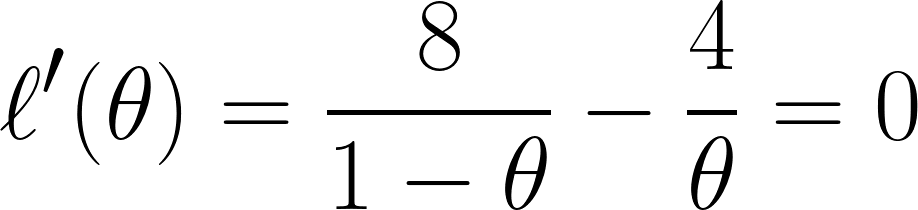
Và qua phương trình này, ta kết luận θ bằng ⅓.
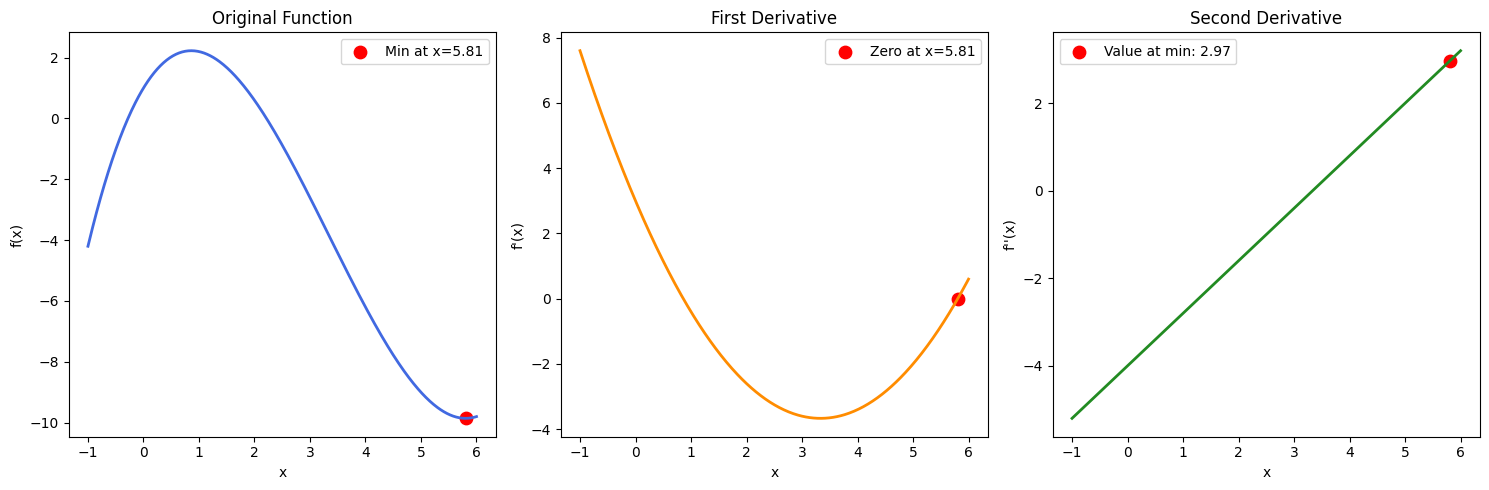
Lưu ý: Nếu ta thu được nhiều nghiệm θ, thì ta cũng cần tìm đạo hàm bậc hai và xem giá trị θ nào cho kết quả dương (để xác nhận ta đã tìm được điểm cực tiểu). Điều này có thể được kiểm chứng qua ví dụ hàm trong hình dưới đây:
Giờ hãy xem một ví dụ liên tục - ước lượng trung bình của phân phối chuẩn (Gaussian).
Giả sử ta có bộ dữ liệu chiều cao của 5 người: 160, 165, 170, 175, 180 (cm). Ta cũng giả định chúng được rút ra từ phân phối chuẩn với trung bình μ (mu) chưa biết và phương sai σ² đã biết (giả sử σ² = 25 để đơn giản).
Hàm hợp lý cho phân phối chuẩn (với phương sai đã biết) là:
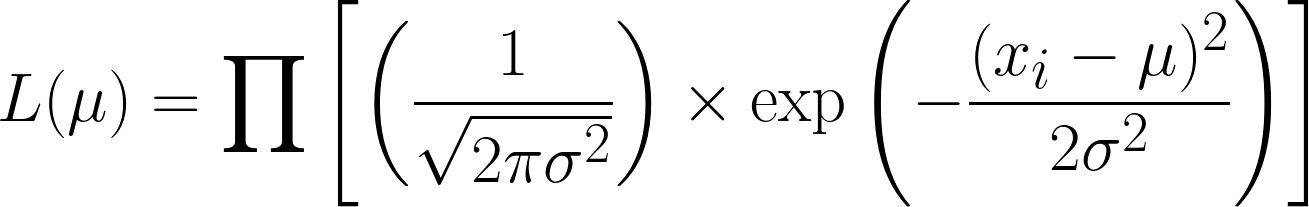
Điều này rất phức tạp, nhưng lấy log âm giúp mọi thứ dễ hơn. Hy vọng giờ bạn thấy sức mạnh của việc dùng hàm log trong phương trình. Phương trình ta thu được là:
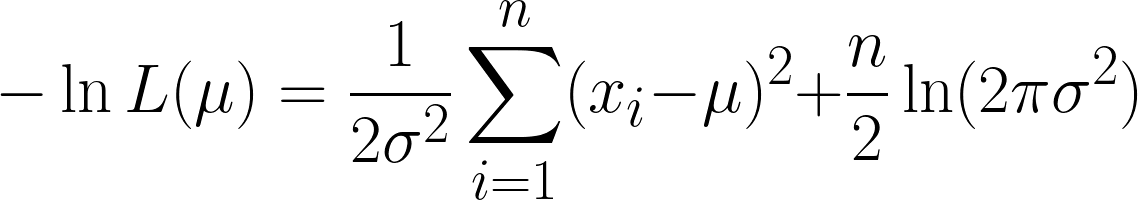
Ta thu được hai hạng ở đây, nhưng lưu ý rằng hạng thứ hai có thể bỏ qua khi ta tiếp tục lấy đạo hàm, vì ta đang lấy đạo hàm theo μ, và hạng thứ hai không chứa μ.
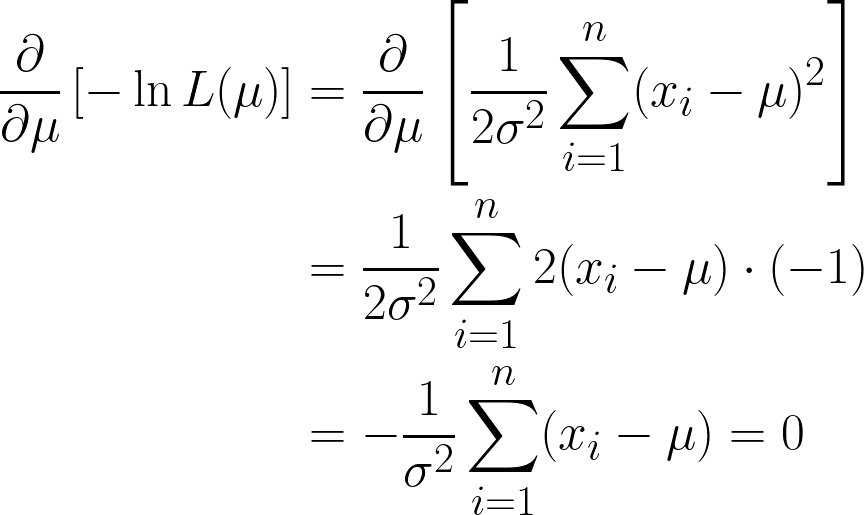
Ta gần xong rồi, nhưng hãy để ý μ trong ngoặc.
Vì nó là một hằng số, ta có thể đơn giản nhân với n, vì cộng μ n lần đơn giản sẽ là n*μ.
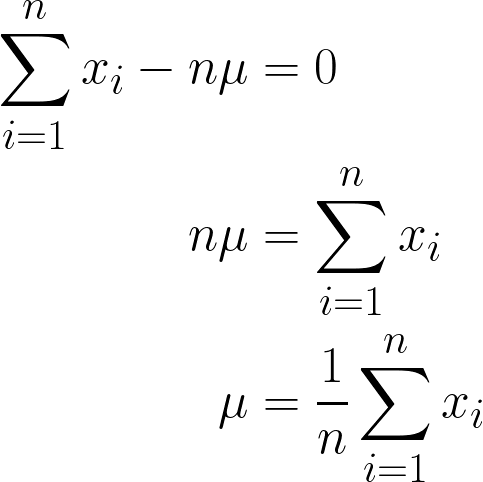
Đáp án cuối cùng ta thu được là hợp lý về trực giác, vì về mặt toán học là cộng tất cả các giá trị x và chia cho n (số quan sát), và đó cũng chính là định nghĩa của trung bình!
Vậy, thay dữ liệu vào phương trình này, ta thu được trung bình là 170cm.
Để trực quan hơn, dưới đây là một ảnh động cho thấy hợp lý thay đổi thế nào khi ta thay đổi μ:
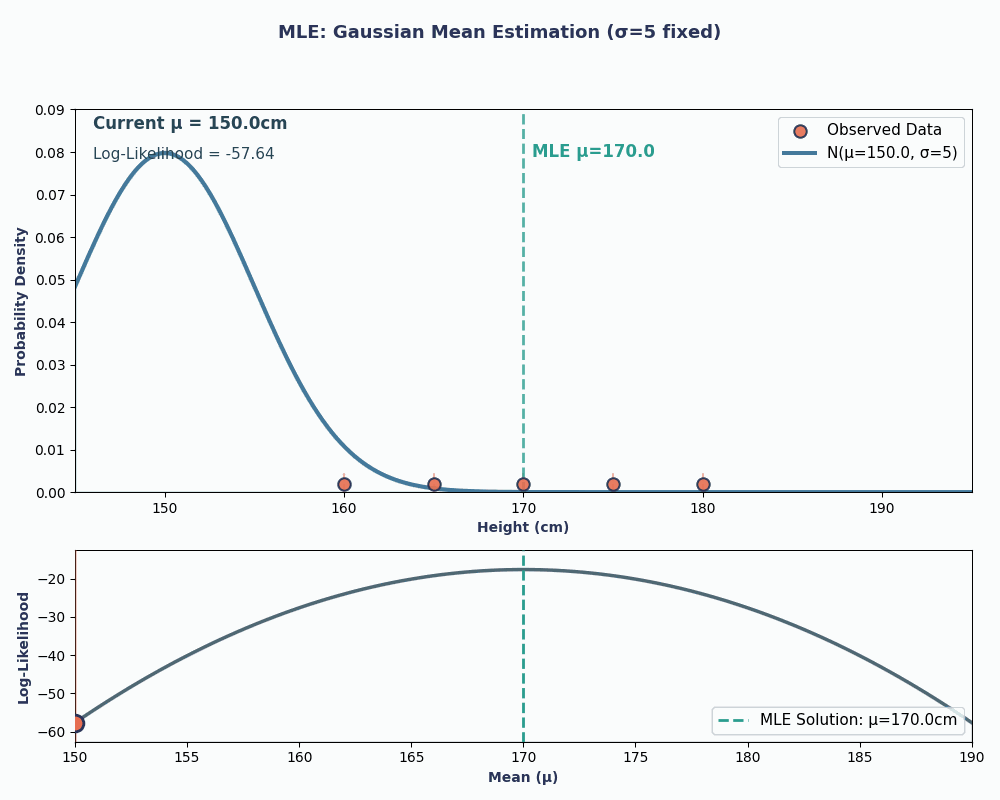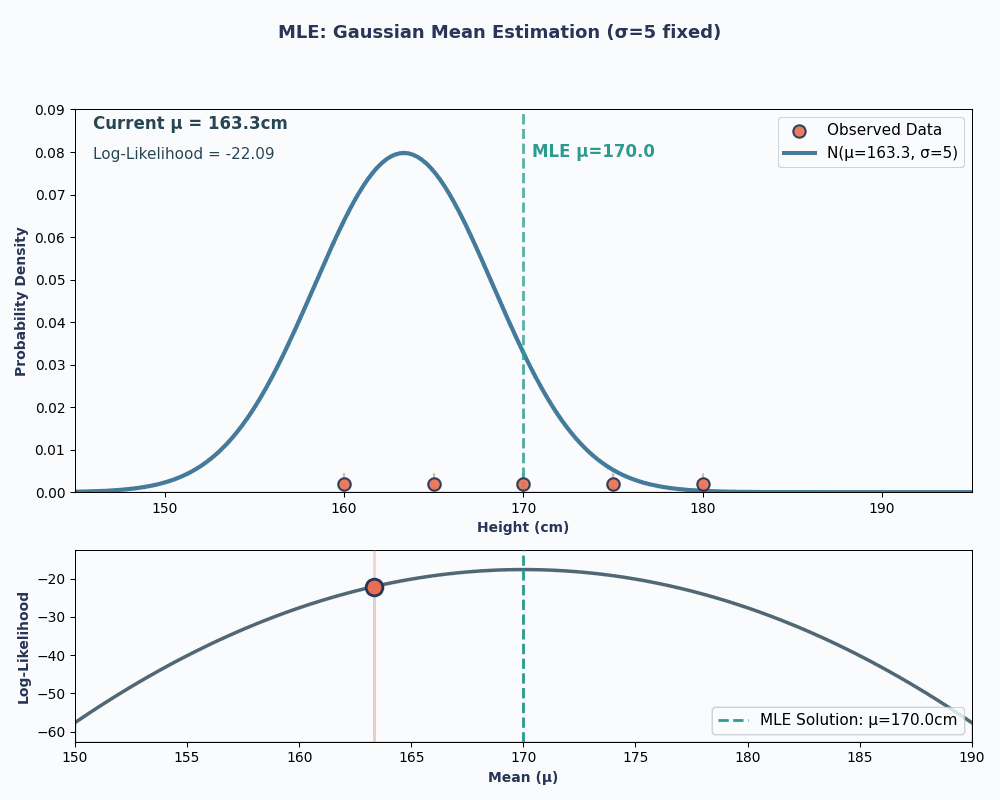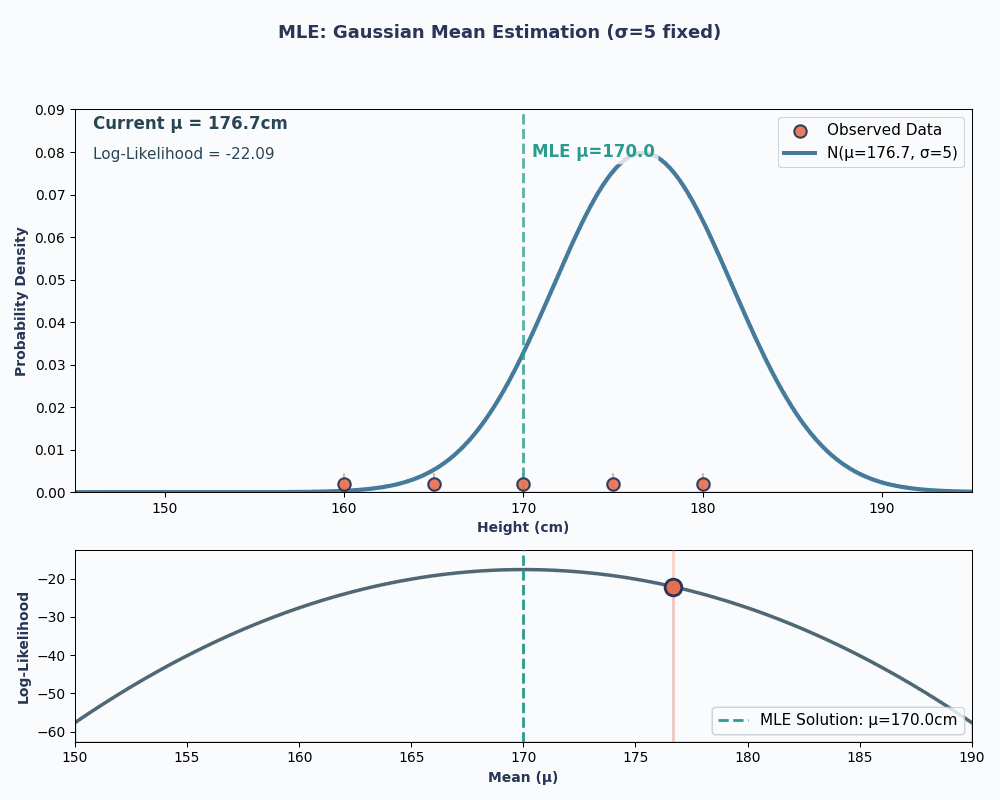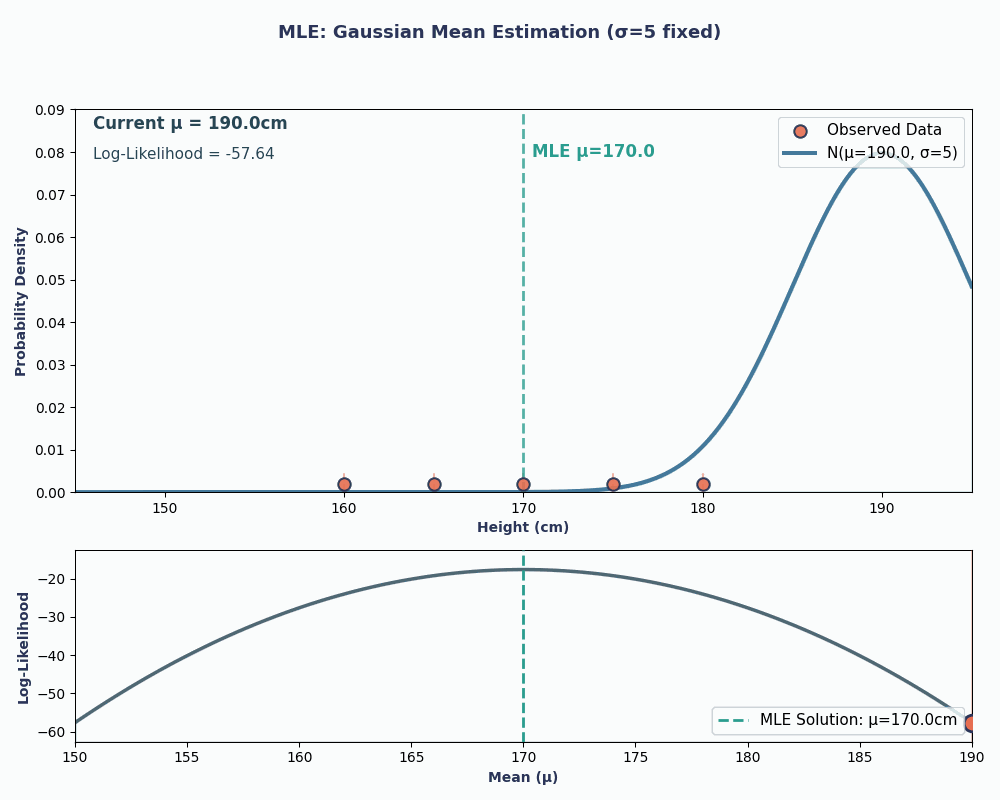
Trong cả hai ví dụ, dùng MLE cho ta giá trị tham số khiến dữ liệu quan sát có khả năng cao nhất dưới mô hình đã chọn. Dĩ nhiên, MLE cũng có thể cho nhiều giá trị tham số, dù phép tính sẽ dài hơn đôi chút!
Sau khi hiểu cấu trúc nền tảng của MLE, hãy xem cách viết mã điều này bằng Python. Chúng ta sẽ mã hóa lời giải ví dụ trước (chiều cao).
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Lưu ý khi lập trình ví dụ trước, ta đã tạo một hàm negative_log_likelihood() chứa logic chính để tính MLE cho phân phối Gaussian đơn biến.
Một mặt, có thể nói rằng cuối cùng ta đã mã hóa cứng phương trình này, và sử dụng scipy.optimize để tối thiểu hóa hàm đó. Tất nhiên, đây vẫn là một lời giải hoàn toàn khả thi, vì phân phối Gaussian có nghiệm dạng đóng.
Hãy khám phá các phương pháp khác để tính nghiệm cho MLE.
Như đã bàn ở trên, trong một số trường hợp may mắn, ta có thể giải phương trình MLE một cách giải tích, tức là ta có thể suy ra công thức chính xác cho các ước lượng tham số. Đây được gọi là nghiệm dạng đóng (closed-form), thường đơn giản, trực quan và nhanh để lập trình cũng như tính toán.
Một câu hỏi quan trọng là: khi nào tồn tại nghiệm dạng đóng?
|
Phân phối |
Tham số ước lượng |
Nghiệm MLE dạng đóng |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = #số lần thành công/n |
|
Nhị thức (Binomial) |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gaussian/Chuẩn |
μ |
μ = 1/n*Σx_i |
Với các mô hình phức tạp hơn, nghiệm giải tích không tồn tại hoặc quá khó suy ra. Khi đó, ta dùng phương pháp tối ưu hóa số - các thuật toán lặp để tìm tham số tối đa hóa log-hợp lý. Hãy lược giải:
Từ các ví dụ và phép tính, rõ ràng MLE hữu ích. Nói một cách chính thức, MLE có các tính chất sau:
Tuy nhiên, có những tình huống MLE có thể không phải lựa chọn tốt nhất:
Trong phần này, hãy khám phá MLE thực sự được dùng ở đâu trong Học máy và AI.
Một trong những nơi quan trọng nhất MLE xuất hiện là trong hồi quy logistic. Ở đây, ta ước lượng xác suất một kết quả thuộc về một lớp nào đó (như rời bỏ dịch vụ) và ta làm điều này bằng cách khớp tham số để tối đa hóa hợp lý của các kết quả quan sát.
Ngay cả trong hồi quy tuyến tính, nếu ta giả định sai số phân phối chuẩn, thì nghiệm bình phương tối thiểu thực ra cũng chính là MLE.
MLE cũng có thể dùng để so sánh mô hình.
Ví dụ, kiểm định tỷ số hợp lý (LRT) giúp ta kiểm tra liệu việc thêm biến vào mô hình có cải thiện hiệu năng đáng kể hay không. Nó hoạt động bằng cách so sánh hợp lý của hai mô hình: một đơn giản (không) và một phức tạp hơn (thay thế).
Ta cũng có Tiêu chuẩn Thông tin Akaike (AIC), trừng phạt độ phức tạp để tránh quá khớp. Các công cụ này được dùng rộng rãi trong tài chính, y học và tiếp thị.
Nếu bạn quan tâm khám phá thêm các cách đo sự khác biệt giữa các phân phối xác suất ngoài hợp lý, hãy xem hướng dẫn: Giải thích KL-Divergence.
Mặc dù mạnh mẽ, MLE vẫn có nhược điểm. Hãy điểm nhanh những nơi nó gặp khó và ta có thể dùng gì thay thế.
Khi MLE không hiệu quả, có thể cân nhắc:
Các phương pháp khác nhau sẽ hiệu quả hơn trong các bối cảnh khác nhau. MLE có thể không phải lúc nào cũng là câu trả lời, nhưng thường là điểm khởi đầu tuyệt vời.
Ước lượng Hợp lý Tối đa là một trong những phương pháp tự nhiên và được sử dụng rộng rãi nhất cho ước lượng tham số. Ý tưởng là làm cho dữ liệu quan sát được có xác suất lớn nhất có thể, nhờ đó có thể dùng trong nhiều bối cảnh khác nhau, như tung đồng xu, chiều cao Gaussian, v.v.
MLE có thể thích ứng trên nhiều mô hình và mở rộng theo dữ liệu, vừa thanh nhã về toán học vừa mạnh mẽ về thực tiễn. Dù có nhược điểm, đặc biệt với dữ liệu nhỏ hoặc lộn xộn, MLE vẫn là công cụ nền tảng khi học Học máy và AI.
Nếu bạn đang trên hành trình học máy, hãy xem lộ trình nghề nghiệp Machine Learning Scientist in Python của chúng tôi, bao quát học có giám sát, không giám sát và học sâu.
Sẵn sàng đào sâu hiểu biết về Ước lượng Hợp lý Tối đa bằng các bài tập thực hành? Những tài nguyên sau sẽ giúp bạn áp dụng kiến thức và tích lũy trải nghiệm thực tế:
Các khóa học hàng đầu của DataCamp
Tracks
Tracks
Courses