
Cursus
Principes fondamentaux de l'apprentissage automatique en Python
16 h
L'estimation des paramètres est une étape fondamentale dans l'analyse statistique et l'apprentissage automatique. Parmi les différentes méthodes disponibles,l'estimation du maximum de vraisemblance (EMV) est l'une des approches les plus utilisées en raison de sa nature intuitive, de sa rigueur mathématique et de sa large applicabilité à différents types de données et de modèles.
Dans cet article, vous apprendrez ce qu'est le MLE, vous explorerez ses fondements mathématiques à travers des dérivations détaillées et des exemples, et vous découvrirez des méthodes de calcul pratiques pour mettre en œuvre efficacement le MLE.
L'estimation du maximum de vraisemblance (EMV) est une méthode statistique importante méthode statistique utilisée pour estimer les paramètres d'une distribution de probabilité en maximiser la fonction de vraisemblance.
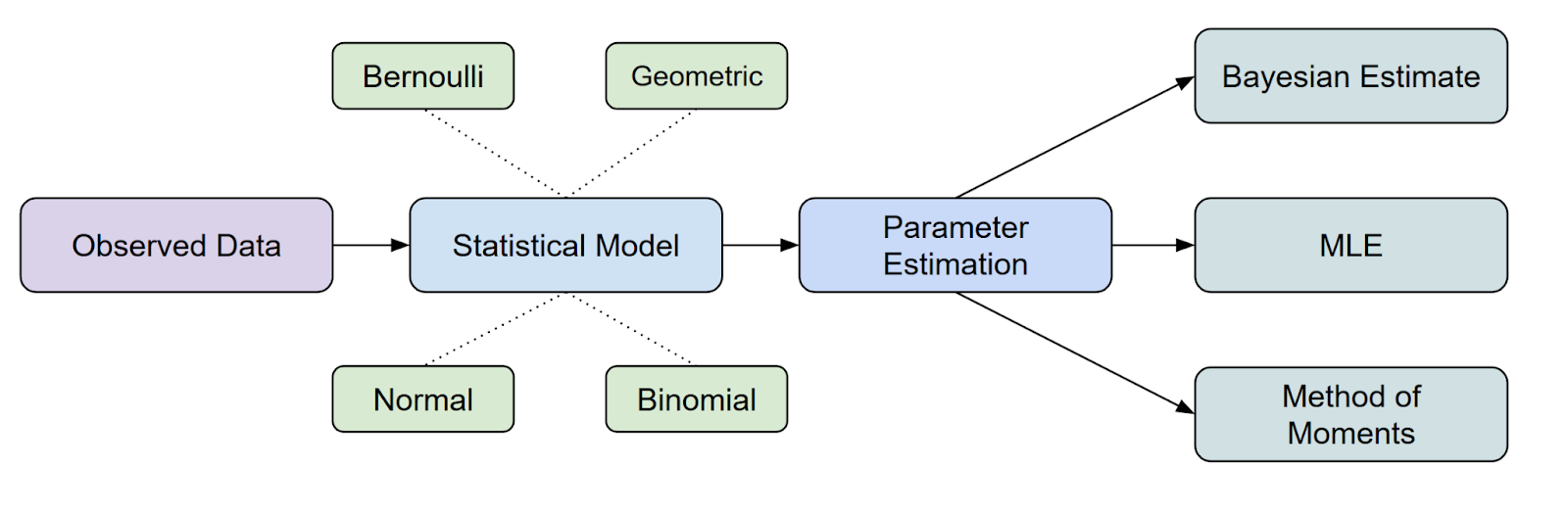
En ce qui concerne la place de la MLE dans l' l'inférence statistique, il s'agit de l'une des méthodes les plus courantes dont nous disposons pour estimer des paramètres.
Cependant, vous pourriez vous poser une autre question ici. Qu'est-ce qu'une fonction de vraisemblance ? Discutons-en plus en détail.
Nous pouvons considérer la fonction de vraisemblance comme un moyen de mesurer dans quelle mesure un ensemble particulier de paramètres explique les données que vous avez observées.
En d'autres termes, cela répond à la question suivante : « Compte tenu de ces valeurs paramétriques, quelle est la probabilité que je constate ces données ? » Cependant, il existe une confusion courante entre la probabilité et la vraisemblance :
En résumé, la fonction de vraisemblance utilise les paramètres de votre modèle comme données d'entrée et vous fournit un nombre qui représente la plausibilité de ces paramètres, compte tenu de vos données.
Plus la valeur de la fonction de vraisemblance est élevée, mieux ces paramètres expliquent vos données.
Pour simplifier davantage, la fonction de vraisemblance nous aide à « noter » différents choix de paramètres, afin que nous puissions sélectionner ceux qui rendent nos données observées les plus probables.
Maintenant que nous avons compris la différence entre probabilité et vraisemblance, ainsi que l'utilité du MLE, passons aux mathématiques sous-jacentes. 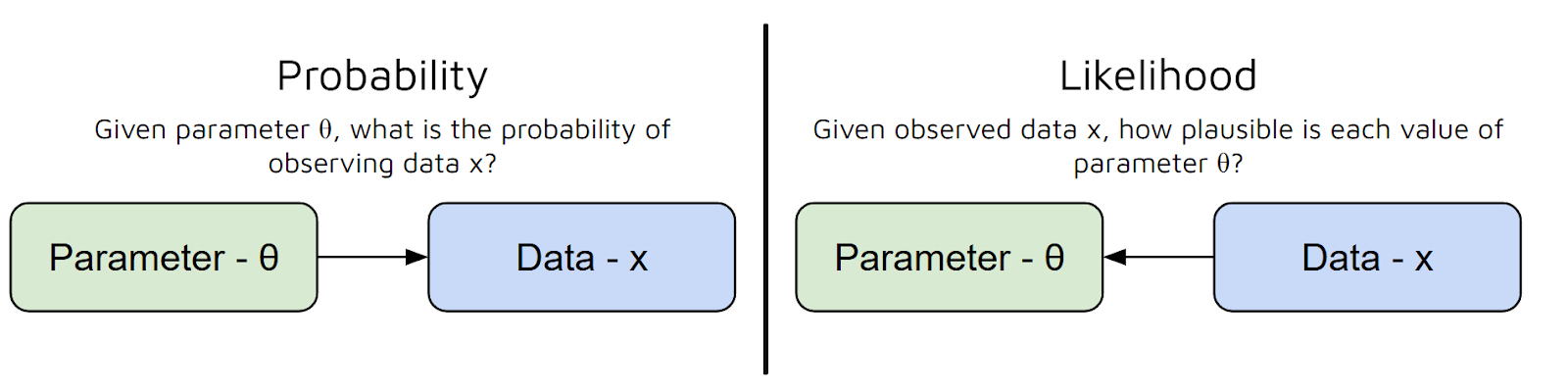
Avant de passer à des exemples spécifiques, examinons comment l'estimateur du maximum de vraisemblance (EMV) est dérivé en général. Nous allons passer en revue chaque étape et expliquer le raisonnement qui la sous-tend.
Supposons que nous disposons d'un ensemble de données : x₁, x₂, ..., xₙ. Nous estimons que ces points de données sont générés à partir d'une distribution de probabilité qui dépend d'un paramètre inconnu θ (thêta). Notre objectif principal est d'estimer θ.
Par exemple, si notre ensemble de données concernait des lancers de pièces, θ pourrait être la probabilité d'obtenir pile. Si l'ensemble de données était continu, comme la taille des élèves d'une classe, θ pourrait être la moyenne d'une distribution normale.
La fonction de vraisemblance mesure la probabilité d'observer vos données pour différentes valeurs de θ. Il est défini comme suit :
![]()
Intuitivement, nous demandons, étant donné que le paramètre θ prend une valeur spécifique, quelle est la probabilité d'observer cet ensemble de données particulier ?
Cet ensemble de données est représenté sous forme de probabilité conjointe d'observer les points de données individuels (x₁, x₂, ..., xₙ), en supposant qu'ils ont été générés selon le modèle paramétré par θ.
En utilisant la règle de la chaîne en probabilité, nous pouvons développer l'équation ci-dessus comme suit :
![]()
Cependant, cette équation est assez complexe. Nous partons donc du principe que les points de données sontindépendants de l' , ou plus précisément, conditionnellement indépendants.
Ce faisant, nous pouvons obtenir la probabilité conjointe comme étant le produit des probabilités individuelles :
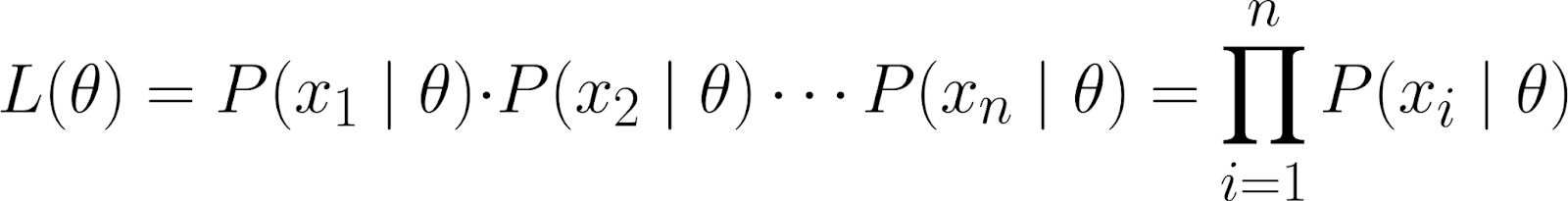
Étant donné que nos points de données observés sont conditionnellement indépendants de θ, nous savons que l'équation suivante est vraie :
![]()
En effet, nous avons supposé qu'une fois la valeur de θ connue, les points de données x₁ et x₂ sont conditionnellement indépendants.
Nous sommes dans une situation où nous devons trouver les valeurs de θ qui maximisent la fonction de vraisemblance. maximisent la fonction de vraisemblance(c'est-à-dire qui rend les données observées les plus probables) :
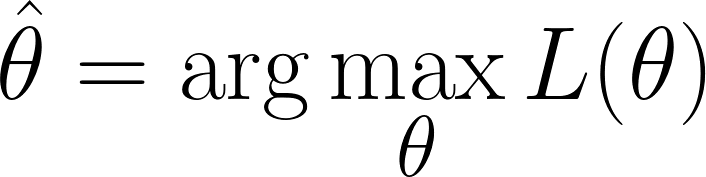
Cependant, rappelons que notre fonction de vraisemblance contient un produit. Travailler avec des produits peut s'avérer compliqué, en particulier lorsque de nombreux points de données sont impliqués. Pour simplifier, nous prenons lelogarithme d' e de la fonction de vraisemblance, car cela convertit le produit en une somme.
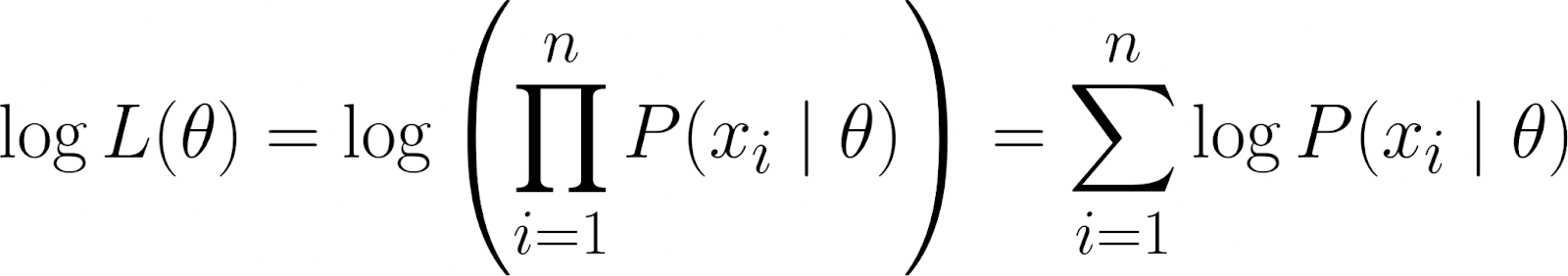
TCela nous donne la log-vraisemblance, qui présente certaines propriétés avantageuses :
Nous sommes maintenant en mesure de faire la distinction, mais dans le domaine de l'apprentissage automatique, nous avons tendance à vouloir minimiser nos fonctions de perte. Heureusement, il est assez facile d'y remédier.
En incluant un symbole moins (c'est-à-dire en multipliant par -1) au début de notre fonction, nous devons maintenant minimiser notre fonction de perte, qui s'appelle désormais la fonction de perte de log-vraisemblance négative.
Maintenant, nous pouvons utiliser le calcul différentiel pour obtenir la valeur de θ. En dérivant la log-vraisemblance par rapport à θ, en la mettant à zéro et en résolvant pour θ. En effet, le minimum d'une fonction se trouve là où sa dérivée est nulle (et où la dérivée seconde est positive).
Par conséquent, l'équation finale pour MLE est la suivante :
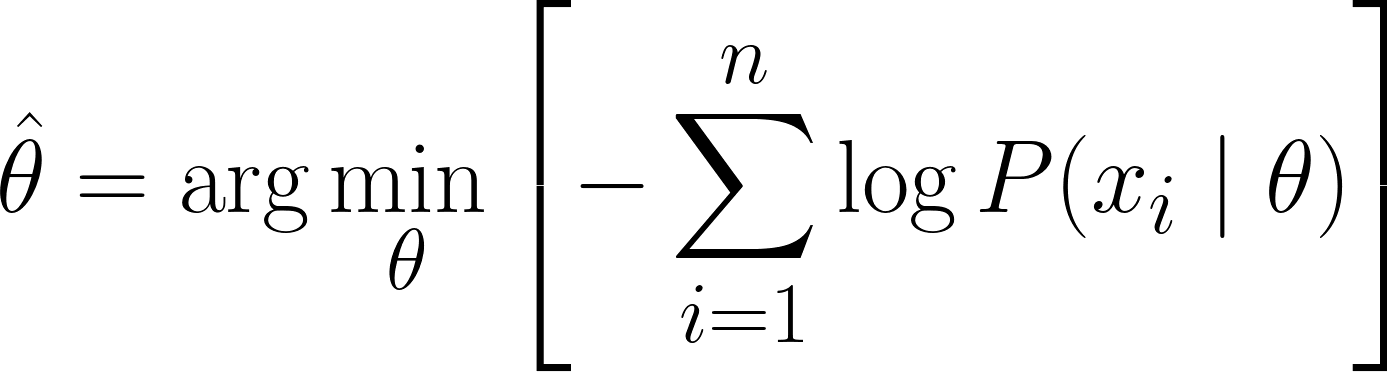
Maintenant que nous avons réussi à dériver l'équation MLE, examinons quelques exemples pratiques pour consolider notre compréhension.
Commençons par un exemple simple et discret : estimer la probabilité d'obtenir un six avec un dé potentiellement biaisé.
Supposons que nous lancions un dé 12 fois et que nous enregistrions les résultats. Nous souhaitons modéliser ces données à l'aide d'unedistribution catégorielle d' , mais concentrons-nous sur l'estimation de la probabilité θ (thêta) d'obtenir un six. Dans cet exemple :
Nous calculons maintenant la fonction de vraisemblance, qui, comme nous avons obtenu 4 six sur 12 lancers, nous donne :
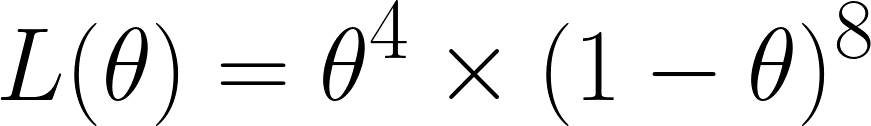
Nous avons obtenu ce résultat car, sur les 12 essais, nous avons obtenu 4 fois le chiffre 6, d'où le terme θ⁴, et 8 fois un autre chiffre, d'où le terme (1 - θ)⁸.
Rappelons que nous avons multiplié car nous avons supposé qu'elles sont conditionnellement indépendants.
Nous prenons maintenant la log-vraisemblance négative comme nous l'avons vu précédemment, ce qui nous donne l'équation suivante :
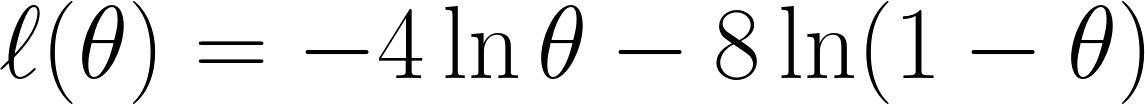
Enfin, nous dérivons l'équation avec par rapport à θ et la fixons à 0 (puisque nous voulons trouver le point minimum) :
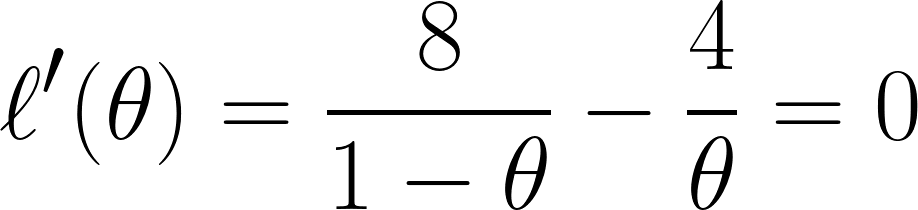
Grâce à cette équation, nous pouvons conclure que θ est égal à ⅓.
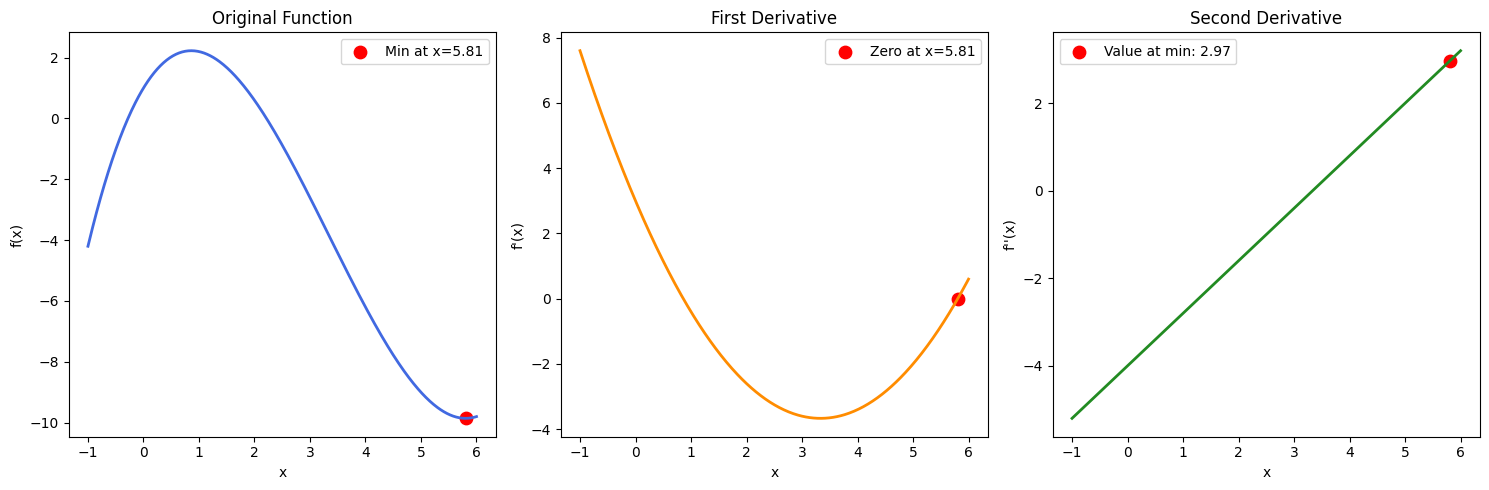
Remarque : Si nous avions obtenu plusieurs solutions de θ, nous aurions également dû trouver la dérivée seconde et déterminer quelles valeurs de θ nous donneraient un résultat positif (afin de confirmer que nous avons trouvé un point minimum). Ceci peut être confirmé à l'aide d'un exemple de fonction dans l'image ci-dessous :
Examinons maintenant un exemple continu : l'estimation de la moyenne d'une distribution normale (gaussienne).
Supposons que nous disposions d'un ensemble de données contenant la taille de 5 personnes : 160, 165, 170, 175, 180 (en cm). Nous supposerons également qu'ils sont tirés d'une distribution normale avecune moyenne μ (mu)inconnue et une variance σ² connue (disons σ² = 25 pour simplifier).
La fonction de vraisemblance pour la distribution normale (avec variance connue) est la suivante.
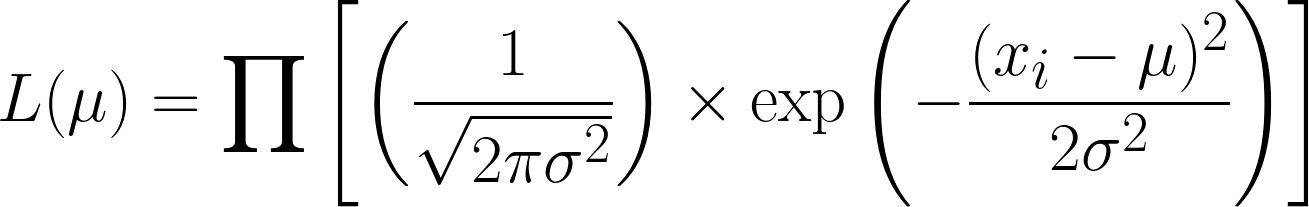
C'est très complexe, mais en prenant le logarithme négatif, cela devient plus simple. Nous espérons que vous comprenez désormais l'utilité de la fonction logarithmique dans notre équation. L'équation que nous obtenons est la suivante :
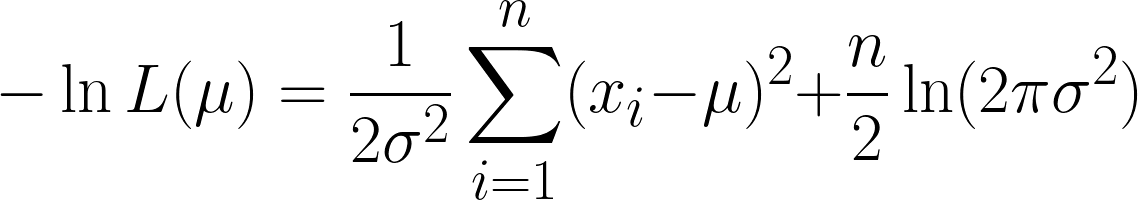
Nous obtenons ici deux termes, mais notez que le second peut être ignoré lorsque nous procédons à la dérivation, car nous différencions par rapport à μet que le deuxième terme ne contient pas μ.
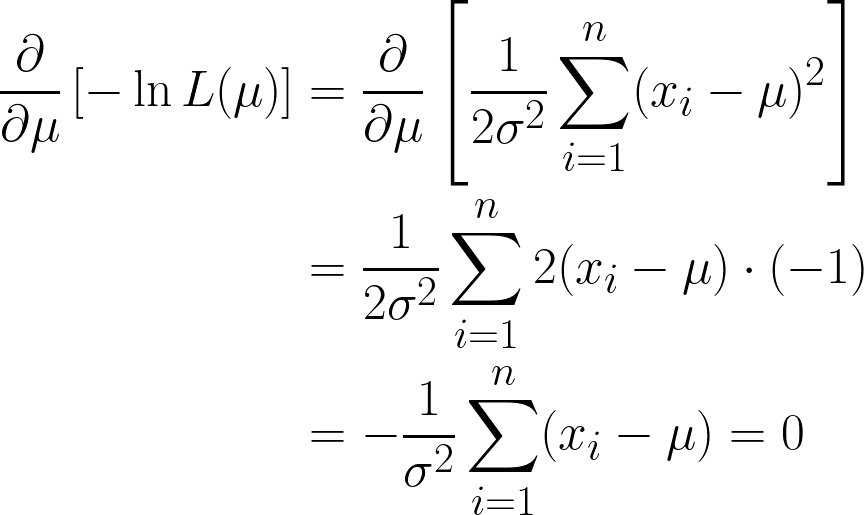
Nous y sommes presque, mais veuillez examiner μ entre parenthèses.
Comme il s'agit d'un processus continu, il est important de vérifier régulièrement l'état constante, nous pouvons simplement la multiplier par n, car ajouter μ n fois équivaut simplement à n*μ.
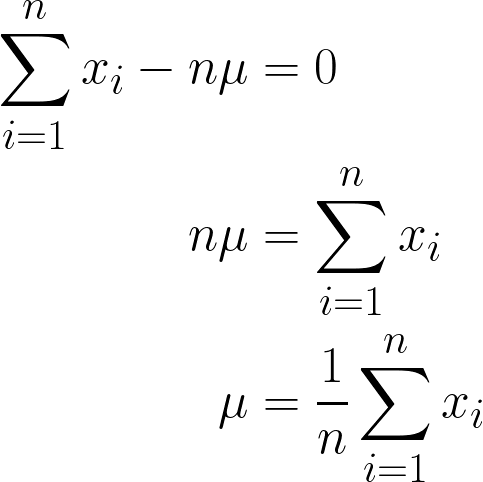
La réponse finale que nous avons obtenue devrait sembler intuitive, puisqu'elle est mathématiquement exprimée comme la somme de toutes les valeurs de x divisée par n (qui est le nombre d'observations dont nous disposons), ce qui correspond également à la définition de la moyenne. définition de la moyenne!
Ainsi, en intégrant les valeurs de nos données dans cette équation, nous obtenons une moyenne de 170 cm.
Pour rendre cela plus clair, voici une animation illustrant comment la probabilité évolue lorsque nous modifions μ :
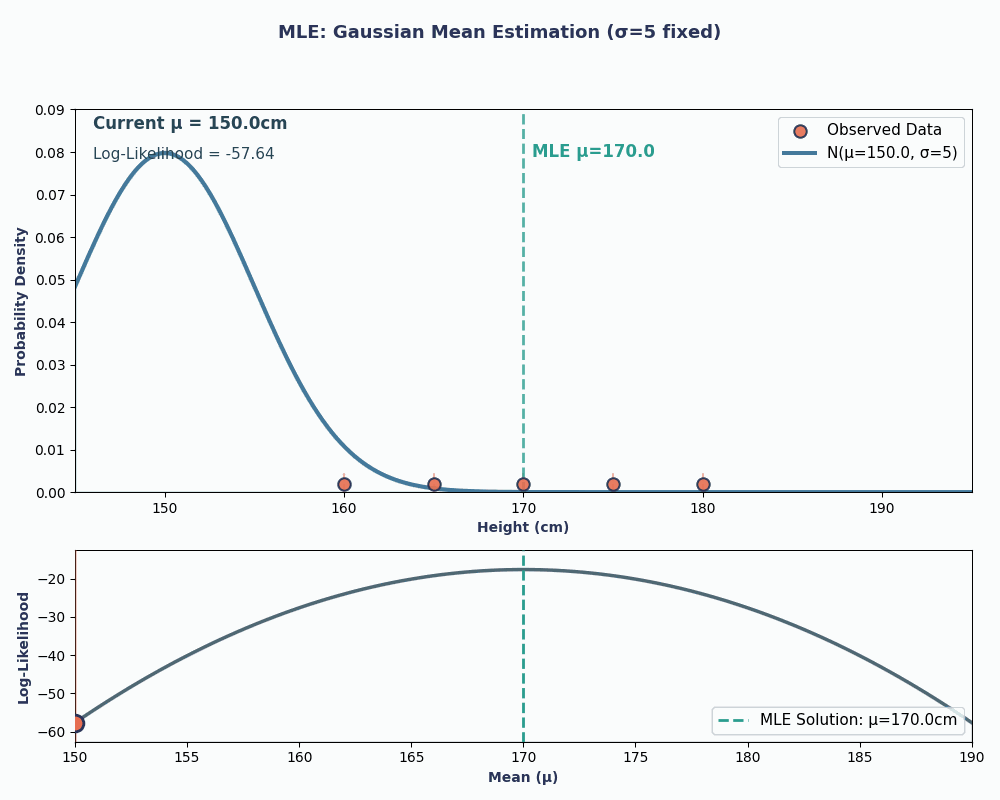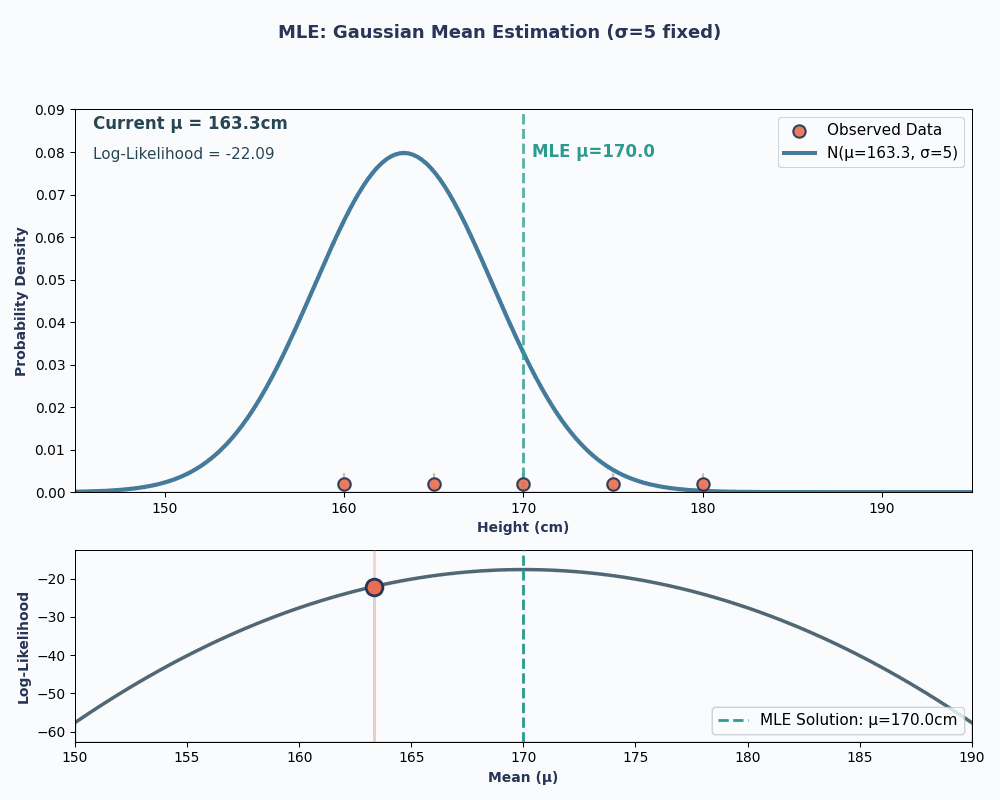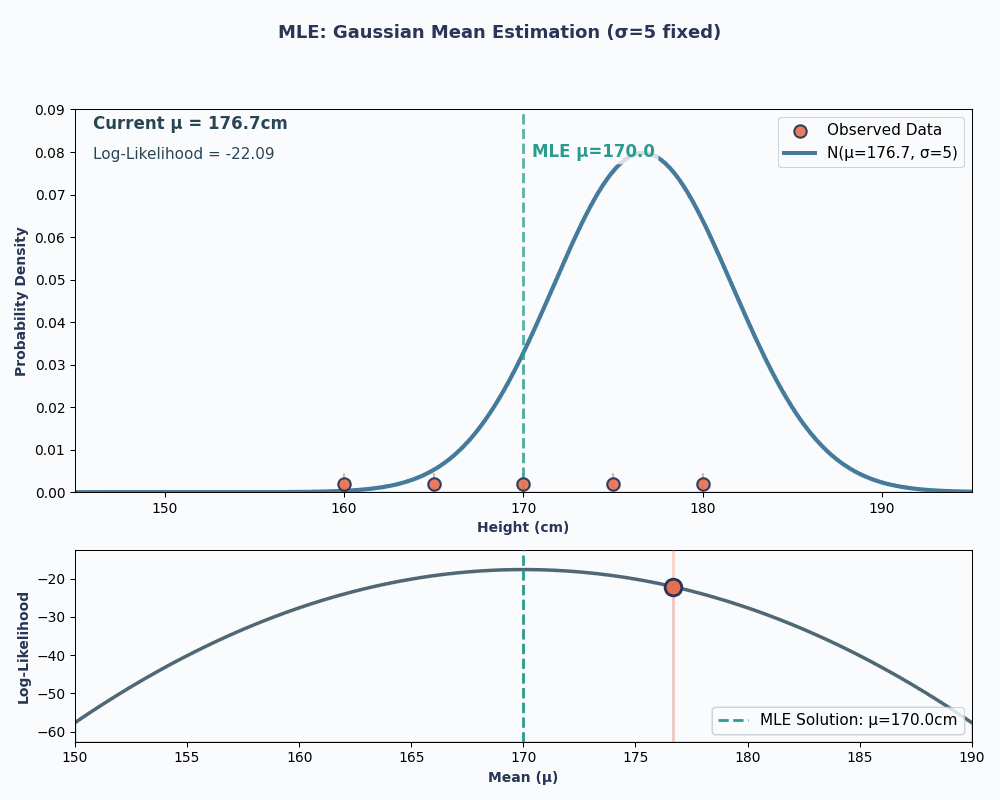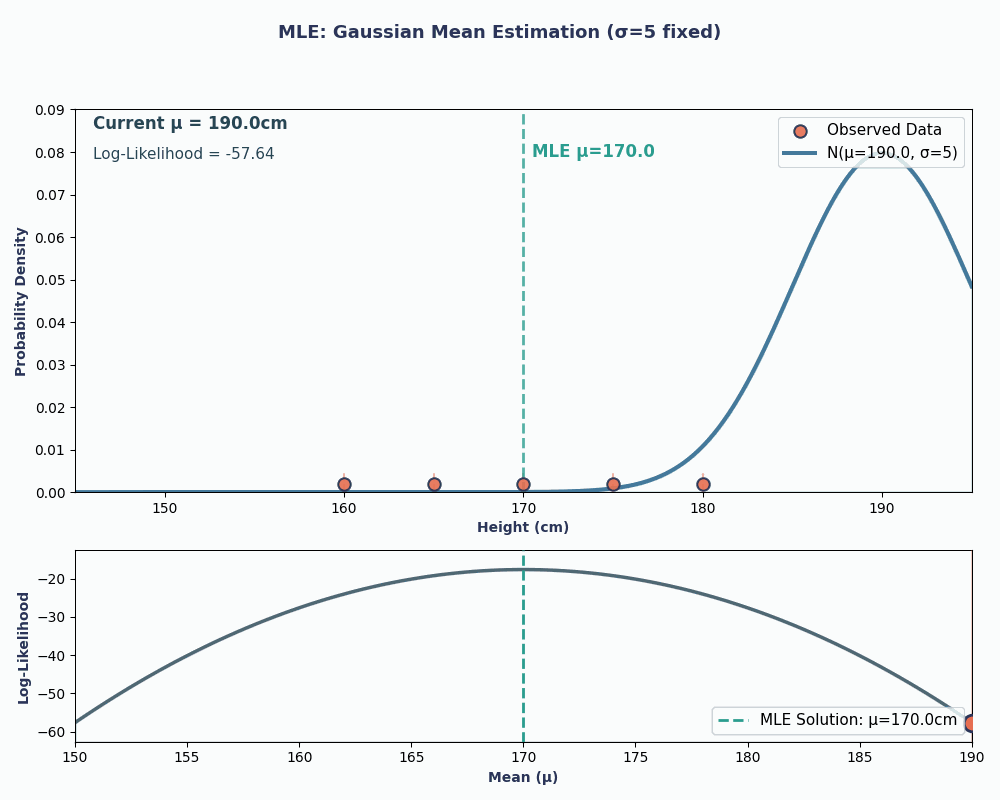
Dans les deux exemples, l'utilisation de la MLE nous a permis d'obtenir la valeur du paramètre qui rendait nos données observées les plus probables dans le modèle choisi. Il est évident que la MLE peutégalement fonctionner en nous fournissantplusieurs valeurs de paramètres d' , bien que le calcul soit légèrement plus long.
Maintenant que nous avons compris la structure sous-jacente du MLE, voyons comment le coder en Python. Nous allons coder la solution de l'exemple précédent (hauteurs).
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Veuillez noter que lorsque nous avons codé l'exemple précédent, nous avons créé une fonction negative_log_likelihood() qui contenait la logique principale pour calculer le MLE d'une distribution gaussienne univariée.
D'une part, on pourrait soutenir que nous avons finalement codé cette équation de manière rigide et que nous avons utilisé l'algorithme de minimisation de la fonction ( scipy.optimize ) pour minimiser cette fonction. Bien entendu, cette solution reste tout à fait viable, car la distribution gaussienne a une solution fermée.
Explorons d'autres méthodes pour calculer des solutions pour MLE.
Comme nous l'avons vu précédemment, dans certains cas favorables, nous pouvons résoudre les équations MLE de manière analytique, ce qui signifie que nous pouvons dériver une formule exacte pour les estimations des paramètres. Cessolutions sont appeléessolutions fermées d' . Elles sont souvent simples, intuitives et rapides à coder et à calculer.
Une question importante à se poser maintenant est la suivante : quand existe-t-il des solutions fermées ?
|
Distribution |
Paramètre estimé |
Solution MLE sous forme fermée |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = nombre de succès/n |
|
Binomial |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gaussien/Normal |
μ |
μ = 1/n*Σx_i |
Pour les modèles plus complexes, il n'existe pas de solutions analytiques ou celles-ci sont trop compliquées à dériver. Dans ces cas, nous utilisonsdes méthodes d'optimisation numérique d' , des algorithmes itératifs qui recherchent les paramètres qui maximisent la log-vraisemblance. Expliquons-les brièvement :
Nos exemples et nos calculs démontrent clairement l'utilité de la MLE. D'un point de vue formel, la MLE présente les propriétés suivantes :
Cependant, il existe des cas où l'utilisation de la MLE n'est pas la meilleure option :
Dans cette section, nous allons explorer les domaines dans lesquels le MLE est réellement utilisé dans le Machine Learning et l'IA.
L'un des domaines les plus importants dans lesquels la MLE est utilisée est celui de la régression logistique. Ici, nous estimons la probabilité qu'un résultat appartienne à une certaine catégorie (telle que la perte d'un client) et nous le faisons en ajustant les paramètres àl' fin de maximiser la probabilité des résultats observés.
Même dans le cas d'une régression linéaire, si l'on suppose que les erreurs sont normalement distribuées, la solution des moindres carrés s'avère en fait être également la MLE.
La MLE peut également être utilisée pour comparer des modèles.
Par exemple, le test du rapport de vraisemblance (LRT) nous aide à vérifier si l'ajout de variables supplémentaires à un modèle améliore significativement ses performances. Il fonctionne en comparant les probabilités de deux modèles : l'un plus simple (nul), l'autre plus complexe (alternatif).
Nous disposons également du critère d'information d'Akaike (AIC), qui pénalise la complexité afin d'éviter le surajustement. Ces outils sont largement utilisés dans des domaines tels que la finance, la médecine et le marketing.
Bien qu'il soit puissant, il présente certains inconvénients. Passons rapidement en revue ses points faibles et ce que nous pouvons utiliser à la place.
Lorsque la MLE ne fonctionne pas correctement, voici quelques options :
Différentes méthodes fonctionnent mieux dans différentes situations. Le MLE n'est peut-être pas toujours la solution, mais il constitue souvent un excellent point de départ.
L'estimation du maximum de vraisemblance est l'une des méthodes les plus naturelles et les plus utilisées pour l'estimation des paramètres. Il s'agit de rendre les données observéesaussi probables que possible, afin qu'elles puissent être utilisées dans de nombreux scénarios différents, tels que les lancers de pièces, les hauteurs gaussiennes, etc.
Le MLE s'adapte à différents modèles et évolue en fonction du volume de données, alliant élégance mathématique et puissance pratique. Bien qu'il présente certains inconvénients, en particulier avec des ensembles de données de petite taille ou désorganisés, il reste un outil fondamental pour l'apprentissage del' , du Machine Learning et de l'IA.
Si vous vous intéressez au machine learning, nous vous invitons à découvrir notre cursus Machine Learning Scientist in Python, qui explore le machine learning supervisé, non supervisé et profond.
Êtes-vous prêt à approfondir vos connaissances sur l'estimation du maximum de vraisemblance à l'aide d'exercices pratiques ? Ces ressources peuvent vous aider à mettre en pratique vos connaissances et à acquérir une expérience pratique :
Meilleurs cours DataCamp
Cursus
Cursus
Cours
Tutoriel
DataCamp Team
Tutoriel
Moez Ali
Tutoriel
Kurtis Pykes
Tutoriel
Sejal Jaiswal
Tutoriel
Mark Pedigo
Tutoriel
Laiba Siddiqui
