
Programma
Fondamenti di apprendimento automatico in Python
16 h
Stimare i parametri è un passaggio fondamentale nell'analisi statistica e nel machine learning. Tra i vari metodi disponibili, la stima di massima verosimiglianza (MLE) è uno degli approcci più utilizzati per la sua natura intuitiva, il rigore matematico e l'ampia applicabilità a diversi tipi di dati e modelli.
In questo articolo imparerai cos'è l'MLE, ne esplorerai le basi matematiche con derivazioni ed esempi dettagliati e scoprirai metodi computazionali pratici per implementarla in modo efficace.
La stima di massima verosimiglianza (MLE) è un importante metodo statistico usato per stimare i parametri di una distribuzione di probabilità massimizzando la funzione di verosimiglianza.
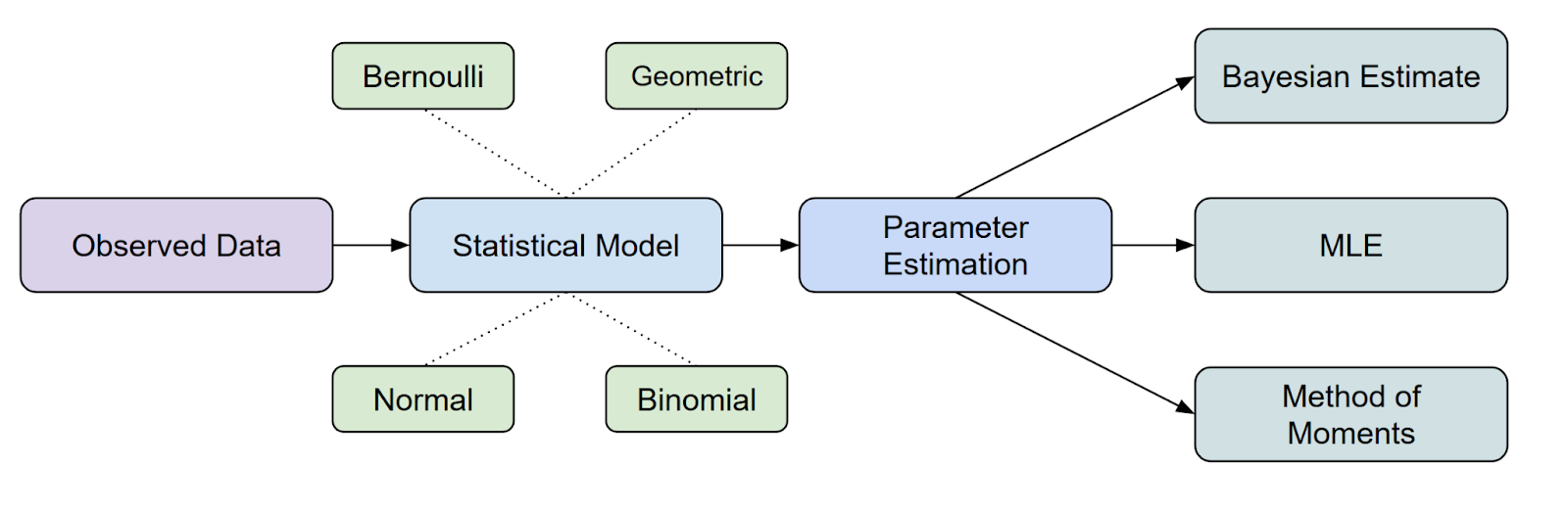
Per capire dove si colloca l'MLE nell'ambito dell'inferenza statistica, è uno dei metodi più comuni che abbiamo per stimare i parametri.
Tuttavia, a questo punto potresti avere un'altra domanda. Cos'è una funzione di verosimiglianza? Approfondiamo.
Possiamo pensare alla funzione di verosimiglianza come a un modo per misurare quanto bene un particolare insieme di parametri spiega i dati che hai osservato.
In altre parole, risponde alla domanda: «Dati questi valori dei parametri, quanto è probabile osservare questi dati?». Ma qui c'è un equivoco comune tra Probabilità e Verosimiglianza:
Riassumendo, la funzione di verosimiglianza prende in input i parametri del tuo modello e restituisce un numero che rappresenta quanto siano plausibili quei parametri, dati i tuoi dati.
Più alto è il valore della funzione di verosimiglianza, meglio quei parametri spiegano i tuoi dati.
Detto ancora più semplicemente, la funzione di verosimiglianza ci aiuta a «valutare» diverse scelte di parametri, così da poter scegliere quelle che rendono i nostri dati osservati più probabili.
Ora che abbiamo capito la differenza tra Probabilità e Verosimiglianza, e a cosa serve l'MLE, passiamo alla matematica di base. 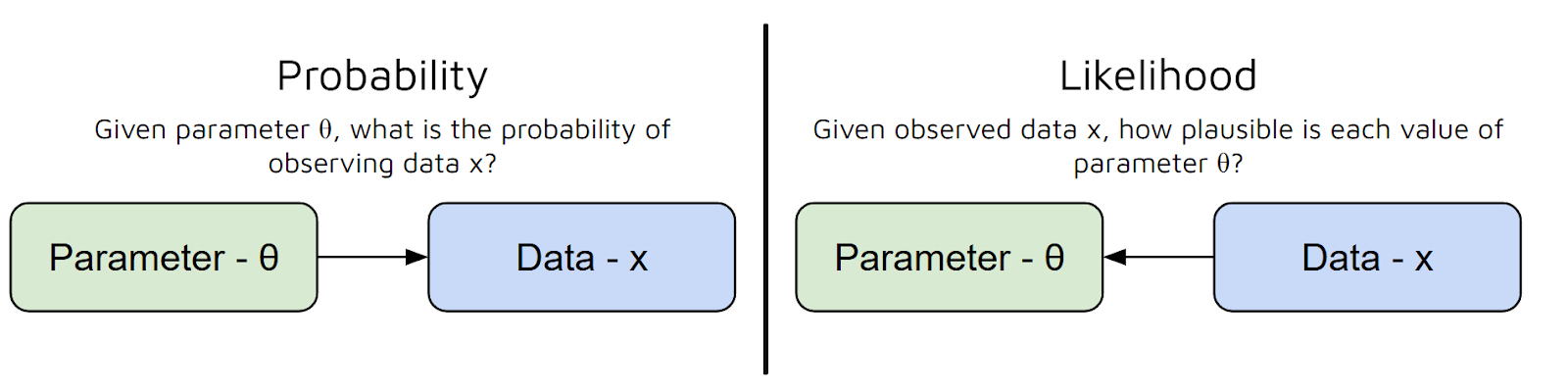
Prima di passare a esempi specifici, vediamo in generale come si deriva lo stimatore di massima verosimiglianza (MLE). Percorreremo ogni passaggio spiegandone anche la logica.
Supponiamo di avere un dataset: x₁, x₂, ..., xₙ. Riteniamo che questi punti dati siano generati da una distribuzione di probabilità che dipende da un parametro ignoto θ (theta). Il nostro obiettivo principale è stimare θ.
Per esempio, se il nostro dataset riguardasse i lanci di una moneta, θ potrebbe essere la probabilità di testa. Se il dataset fosse continuo, come le altezze degli studenti in classe, θ potrebbe essere la media di una distribuzione normale.
La funzione di verosimiglianza misura quanto è probabile osservare i tuoi dati per diversi valori di θ. È definita come:
![]()
Intuitivamente, ci chiediamo: dato che il parametro θ assume un valore specifico, qual è la probabilità di osservare questo particolare dataset?
Questo dataset è rappresentato come la probabilità congiunta di osservare i singoli punti dati (x₁, x₂, ..., xₙ), assumendo che siano stati generati sotto il modello parametrizzato da θ.
Usando la regola della catena della probabilità, possiamo espandere l'equazione precedente in questa:
![]()
Tuttavia, questa è un'equazione piuttosto complicata! Quindi facciamo l'assunzione che i punti dati siano indipendenti - più precisamente, condizionalmente indipendenti.
Così facendo, possiamo esprimere la probabilità congiunta come il prodotto delle probabilità individuali:
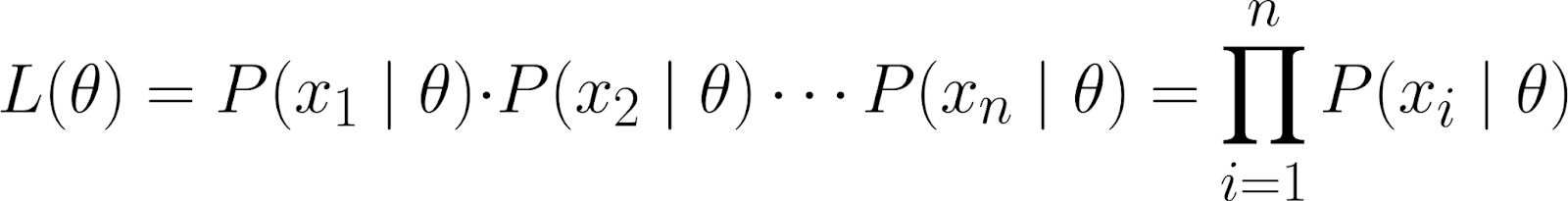
Dal momento che i nostri punti dati osservati sono condizionalmente indipendenti dato θ, sappiamo che la seguente equazione è vera:
![]()
Questo perché abbiamo assunto che, una volta noto il valore di θ, i punti dati x₁ e x₂ siano condizionalmente indipendenti.
Siamo nella situazione in cui dobbiamo trovare i valori di θ che massimizzano la funzione di verosimiglianza (cioè rendono i dati osservati i più probabili):
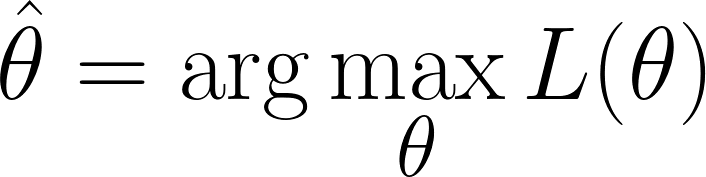
Ricorda però che la nostra funzione di verosimiglianza contiene un prodotto. Lavorare con i prodotti può essere complicato, soprattutto con molti punti dati. Per semplificare, prendiamo il logaritmo della funzione di verosimiglianza poiché converte il prodotto in una sommatoria.
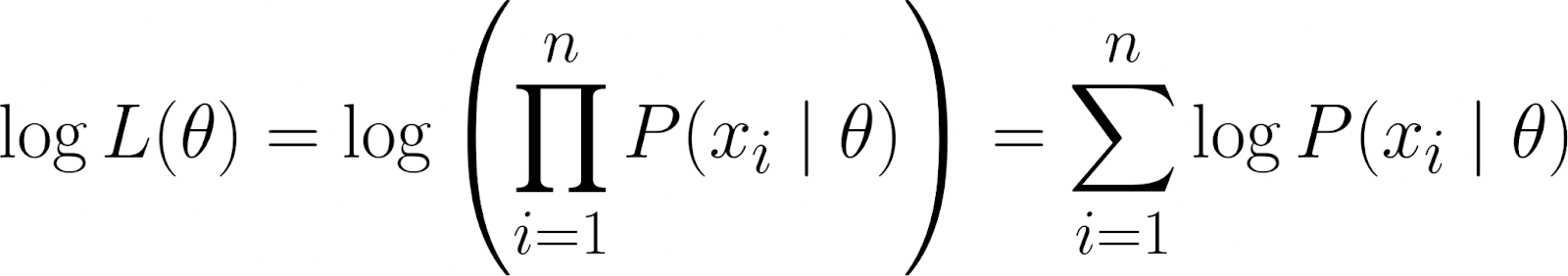
Questo ci dà la log-verosimiglianza, che ha alcune proprietà utili:
Ora possiamo derivare, tuttavia nel machine learning tendiamo a voler minimizzare le funzioni di perdita. Per fortuna, la soluzione è semplice.
Inserendo un segno meno (cioè moltiplicando per -1) all'inizio della nostra funzione, ora dobbiamo minimizzare la nostra funzione di perdita, che ora si chiama funzione di perdita della log-verosimiglianza negativa.
Ora possiamo usare il calcolo differenziale per ottenere il valore di θ. Prendiamo la derivata della log-verosimiglianza rispetto a θ, la poniamo uguale a zero e risolviamo per θ. Questo perché il minimo di una funzione si trova dove la sua derivata è zero (e la seconda derivata è positiva).
Pertanto, l'equazione finale per l'MLE è:
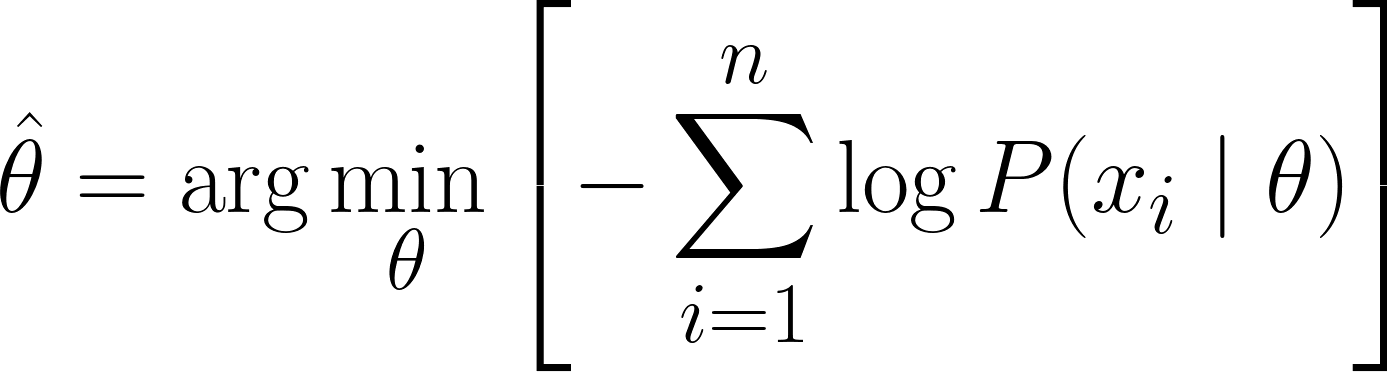
Poiché abbiamo derivato con successo l'equazione dell'MLE, vediamo alcuni esempi svolti per consolidare la comprensione.
Iniziamo con un semplice esempio discreto: stimare la probabilità di ottenere un sei con un dado possibilmente truccato.
Supponiamo di lanciare un dado 12 volte e di registrare i risultati. Vogliamo modellare questi dati usando una distribuzione categoriale, ma concentriamoci sulla stima della probabilità θ (theta) di ottenere un sei. In questo esempio:
Ora calcoliamo la funzione di verosimiglianza che, dato che abbiamo ottenuto 4 sei su 12 lanci, risulta:
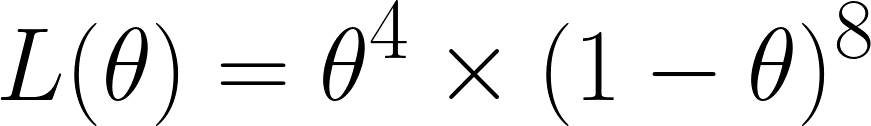
L'abbiamo ottenuta perché su 12 lanci abbiamo ottenuto il sei 4 volte - quindi abbiamo θ⁴ - e non-sei 8 volte - quindi compare il termine (1 - θ)⁸.
Ricorda, li abbiamo moltiplicati perché abbiamo assunto che siano condizionalmente indipendenti.
Ora prendiamo la log-verosimiglianza negativa come discusso in precedenza, ottenendo questa equazione:
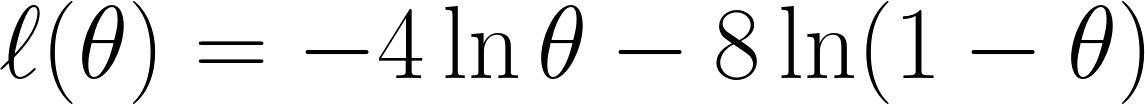
Infine, deriviamo l'equazione rispetto a θ e la poniamo uguale a 0 (poiché vogliamo trovare il punto di minimo):
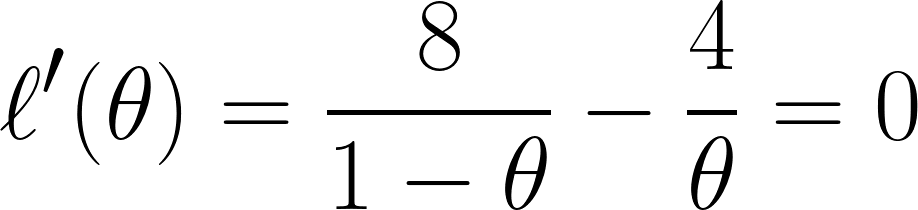
E tramite questa equazione, possiamo concludere che θ è uguale a ⅓.
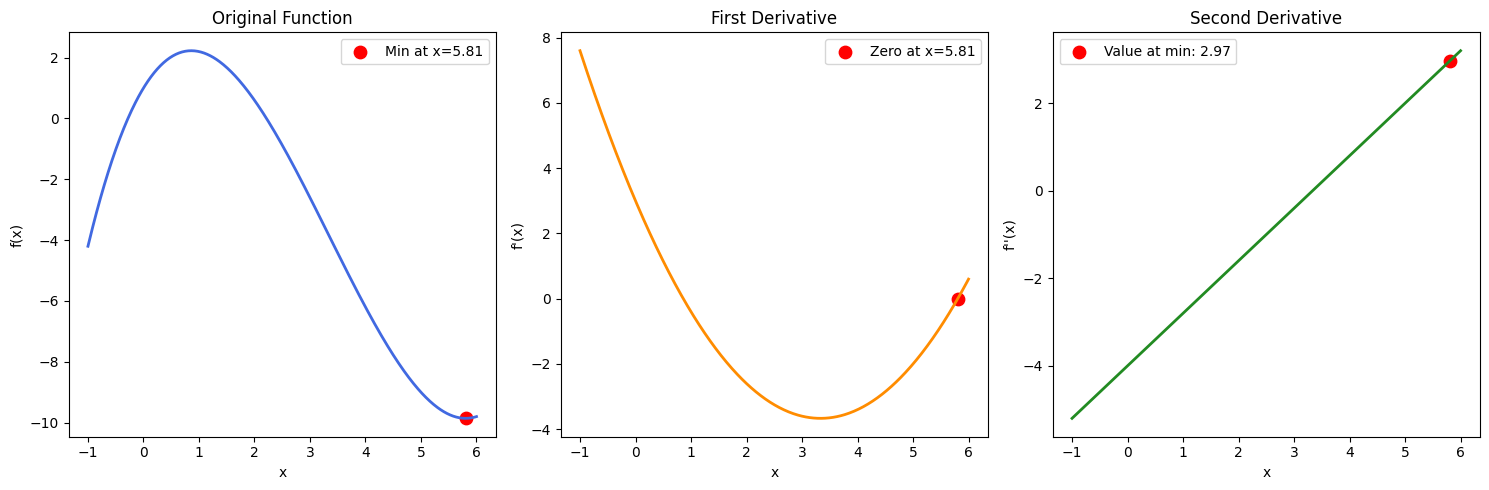
Nota: se avessimo ottenuto più soluzioni per θ, allora dovremmo anche calcolare la seconda derivata e vedere quali valori di θ restituiscono un risultato positivo (per confermare di aver trovato un punto di minimo). Ciò può essere confermato tramite una funzione di esempio nell'immagine seguente:
Vediamo ora un esempio continuo: stimare la media di una distribuzione normale (gaussiana).
Supponiamo di avere un dataset con le altezze di 5 persone: 160, 165, 170, 175, 180 (in cm). Assumiamo anche che siano estratte da una distribuzione normale con media μ sconosciuta (mu) e varianza nota σ² (poniamo σ² = 25 per semplicità).
La funzione di verosimiglianza per la distribuzione normale (con varianza nota) è.
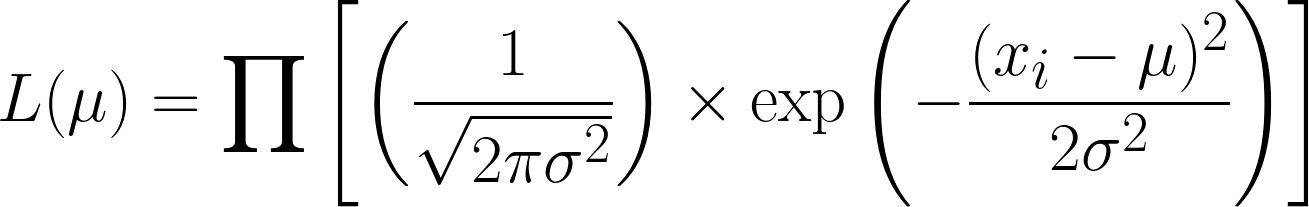
È molto complicata, ma prendere il log negativo semplifica le cose. Ora dovresti percepire la potenza dell'uso del log nella nostra equazione. L'equazione che otteniamo è questa:
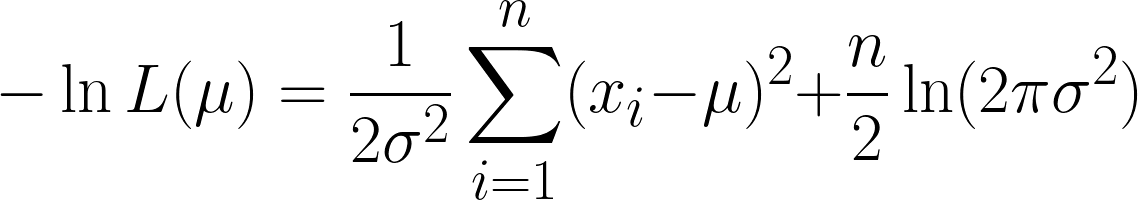
Otteniamo due termini, ma nota come il secondo si possa trascurare quando procediamo con la derivazione, poiché stiamo derivando rispetto a μ e il secondo termine non contiene μ.
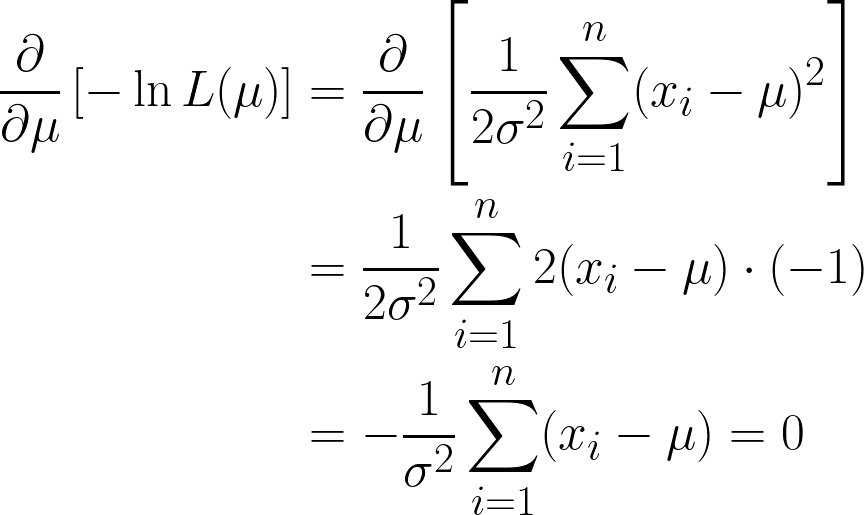
Ci siamo quasi, ma guarda μ tra parentesi.
Poiché è una costante, possiamo semplicemente moltiplicarla per n, dato che sommare μ n volte equivale a n*μ.
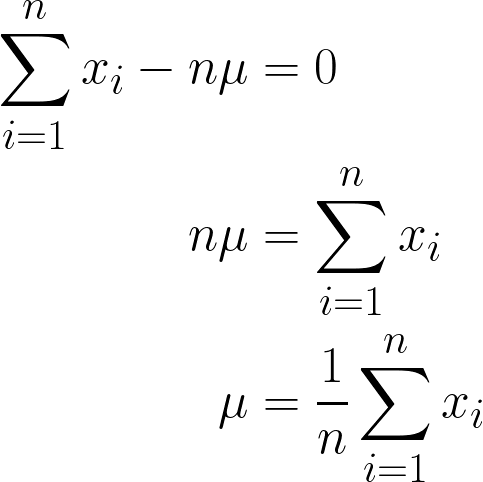
La risposta finale ottenuta dovrebbe avere senso in modo intuitivo, poiché è espresso matematicamente come sommare tutti i valori di x e dividere per n (il numero di osservazioni), che è anche la definizione di media!
Inserendo i nostri valori di dati in questa equazione, possiamo ottenere una media pari a 170 cm.
Per renderlo più visivo, ecco un'animazione che mostra come cambia la verosimiglianza al variare di μ:
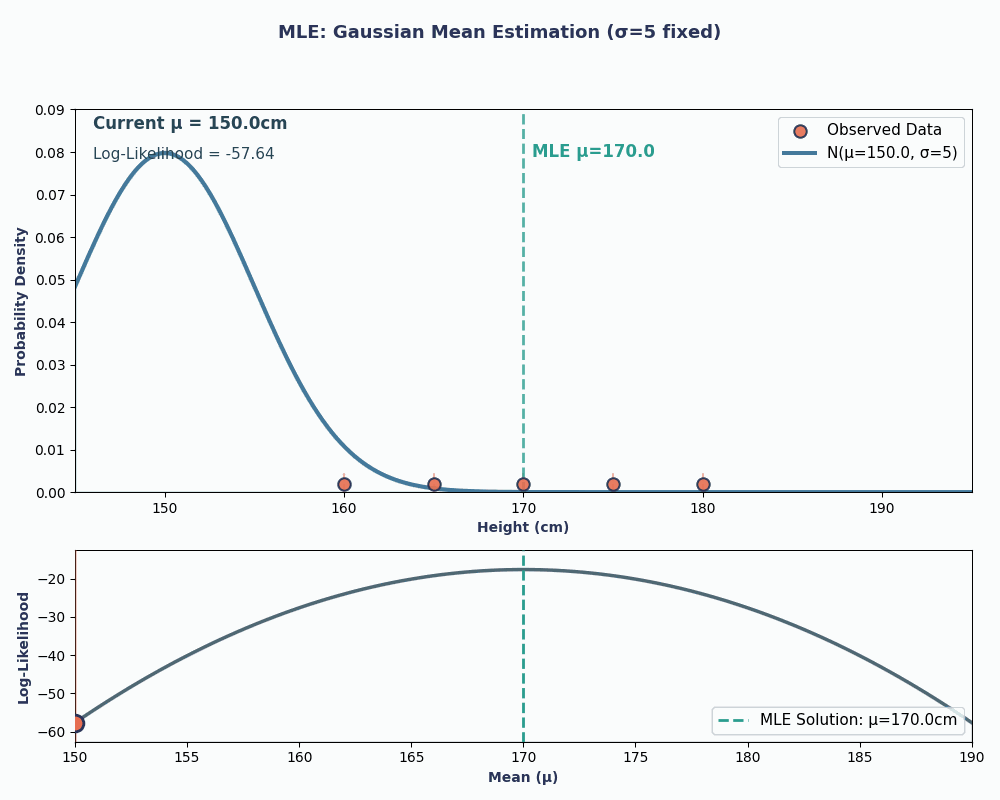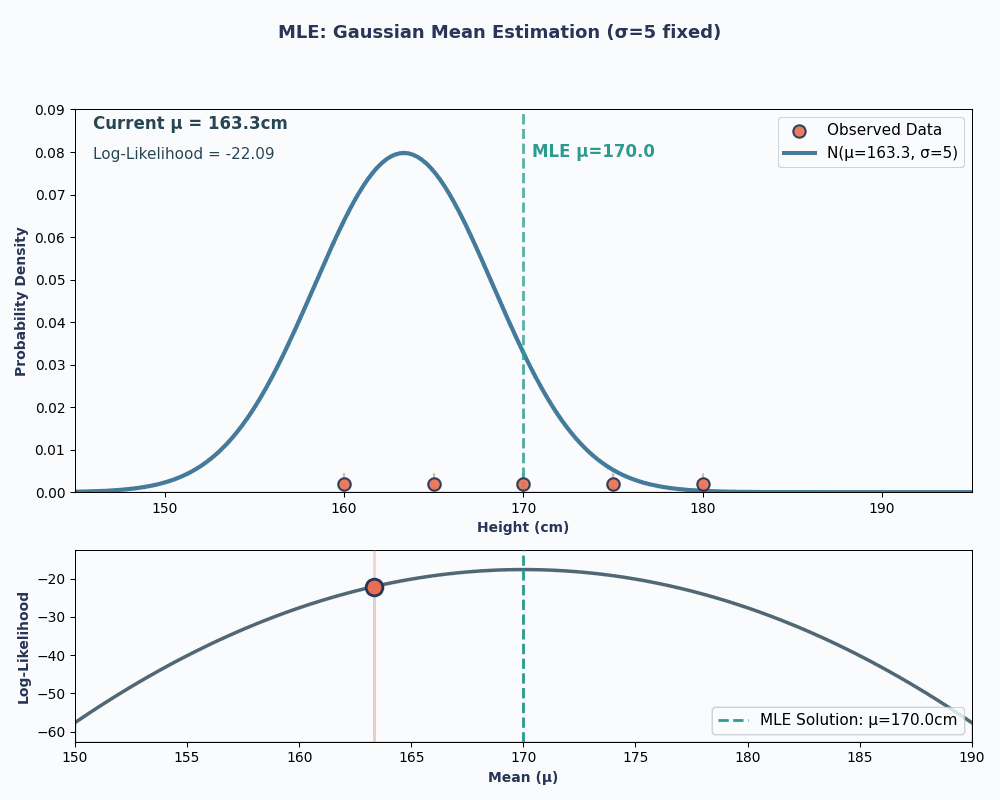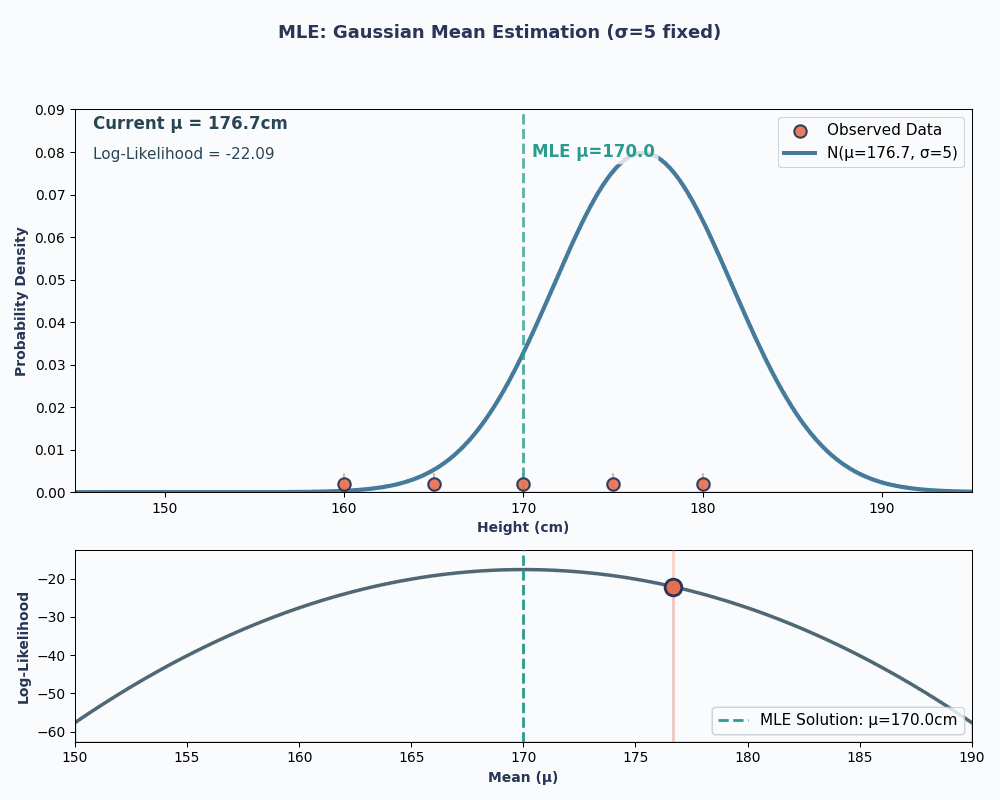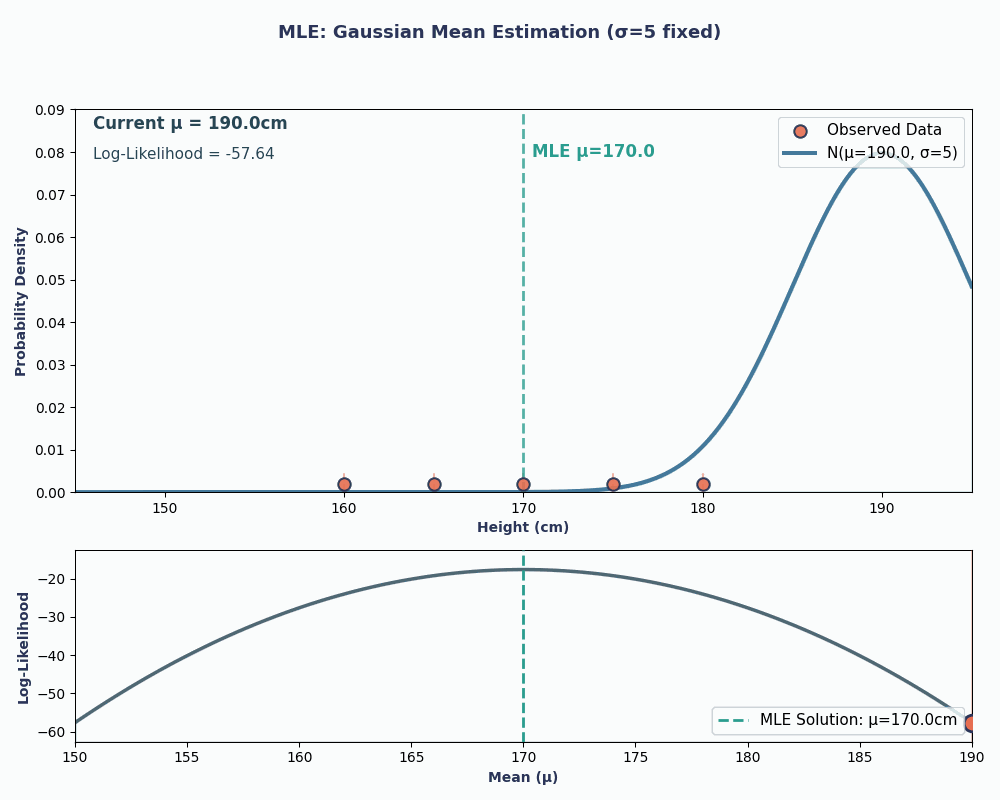
In entrambi gli esempi, usando l'MLE abbiamo ottenuto il valore del parametro che rende i nostri dati osservati più probabili sotto il modello scelto. Ovviamente, l'MLE può funzionare anche con più parametri, anche se il calcolo sarebbe un po' più lungo!
Ora che abbiamo compreso la struttura di base dell'MLE, vediamo come codificarla in Python. Implementeremo la soluzione dell'esempio precedente (altezze).
# Importing libraries
import numpy as np # used for handling arrays and mathematical operations.
from scipy.optimize import minimize # function that minimizes another function
# This is our sample data
data = np.array([160, 165, 170, 175, 180])
# This was the variance we had assumed before
sigma_squared = 25
# Negative Log-Likelihood function
def negative_log_likelihood(mu):
n = len(data) # Number of data points
return 0.5 * n * np.log(2 * np.pi * sigma_squared) + \
np.sum((data - mu)**2) / (2 * sigma_squared) # The NLL is for the Univariate Gaussian Distribution
# Optimizing the NLL
result = minimize(negative_log_likelihood, x0=170) # initial guess
# Our final estimated mean
estimated_mu = result.x[0]
print(f"MLE estimate of mu: {estimated_mu}")Nota che, quando abbiamo codificato l'esempio precedente, abbiamo creato una funzione negative_log_likelihood() che conteneva la logica principale per calcolare l'MLE di una distribuzione gaussiana univariata.
Da un lato, si potrebbe sostenere che in definitiva abbiamo codificato in modo esplicito questa equazione e abbiamo usato scipy.optimize per minimizzarla. Naturalmente, è comunque una soluzione completamente valida, dato che la distribuzione gaussiana ha una soluzione in forma chiusa.
Esploriamo altri metodi per calcolare soluzioni di MLE.
Come discusso sopra, in alcuni casi fortunati possiamo risolvere le equazioni MLE analiticamente, il che significa che possiamo derivare una formula esatta per le stime dei parametri. Queste sono note come soluzioni in forma chiusa, e spesso sono semplici, intuitive e veloci da implementare e calcolare.
Una domanda importante ora è: quando esistono soluzioni in forma chiusa?
|
Distribuzione |
Parametro stimato |
Soluzione MLE in forma chiusa |
|---|---|---|
|
Bernoulli |
p |
\hat{p} = #numero di successi/n |
|
Binomiale |
p |
\hat{p} = x/n |
|
Poisson |
λ |
λ = 1/n*Σx_i |
|
Gaussiana/Normale |
μ |
μ = 1/n*Σx_i |
Per modelli più complessi, le soluzioni analitiche non esistono o sono troppo complicate da derivare. In questi casi, usiamo metodi di ottimizzazione numerica - algoritmi iterativi che cercano i parametri che massimizzano la log-verosimiglianza. Spieghiamoli brevemente:
Dai nostri esempi e calcoli è chiaro che l'MLE è utile. Più formalmente, l'MLE ha le seguenti proprietà:
Tuttavia, ci sono scenari in cui usare l'MLE potrebbe non essere l'opzione migliore:
In questa sezione esploriamo dove l'MLE viene effettivamente usata nel Machine Learning e nell'AI.
Uno dei luoghi più importanti in cui compare l'MLE è nella regressione logistica. Qui stimiamo la probabilità che un esito appartenga a una certa classe (come il churn dei clienti) e lo facciamo adattando i parametri per massimizzare la verosimiglianza degli esiti osservati.
Anche nella regressione lineare, se assumiamo errori distribuiti normalmente, allora la soluzione ai minimi quadrati risulta essere anch'essa l'MLE.
L'MLE può essere usata anche per confrontare modelli.
Per esempio, il test del rapporto di verosimiglianza (LRT) ci aiuta a verificare se aggiungere variabili extra a un modello ne migliora significativamente le prestazioni. Funziona confrontando le verosimiglianze di due modelli: uno più semplice (nullo) e uno più complesso (alternativo).
Abbiamo anche l'Akaike Information Criterion (AIC), che penalizza la complessità per evitare l'overfitting. Questi strumenti sono ampiamente usati in campi come finanza, medicina e marketing.
Se vuoi esplorare ulteriormente modi per misurare le differenze tra distribuzioni di probabilità oltre alla sola verosimiglianza, dai un'occhiata al mio tutorial: KL-Divergence Explained.
Sebbene sia potente, ha i suoi limiti. Rivediamo rapidamente dove incontra difficoltà e cosa possiamo usare al suo posto.
Quando l'MLE non funziona bene, ecco alcune opzioni:
Metodi diversi funzionano meglio in situazioni diverse. L'MLE potrebbe non essere sempre la risposta, ma spesso è un ottimo punto di partenza.
La stima di massima verosimiglianza è uno dei metodi più naturali e diffusi per la stima dei parametri. L'idea è rendere i dati osservati il più probabili possibile, e quindi può essere usata in molti scenari diversi, come i lanci di moneta, le altezze gaussiane, ecc.
L'MLE si adatta ai modelli e scala con i dati, offrendo sia eleganza matematica che potenza pratica. Sebbene abbia i suoi svantaggi, soprattutto con dataset piccoli o disordinati, rimane uno strumento fondamentale quando si studiano Machine Learning e AI.
Se sei nel tuo percorso di machine learning, dai un'occhiata alla nostra carriera Machine Learning Scientist in Python, che esplora apprendimento supervisionato, non supervisionato e deep learning.
Pronto ad approfondire la stima di massima verosimiglianza con esercizi pratici? Queste risorse possono aiutarti ad applicare le tue conoscenze e fare esperienza pratica:
I migliori corsi DataCamp
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

