
Cursus
Introductie tot databases in Python
4 Hr
101.5K
Dit artikel loodst je door SQLAlchemy, een SQL-toolkit voor Python die taken als query’s uitvoeren, databases opbouwen en beheren eenvoudiger maakt.
Na het lezen van deze tutorial raad ik je aan je in te schrijven voor onze cursus Introduction to Databases in Python voor extra oefening. Highlights zijn hands-on projecten die je begeleiden bij het filteren en groeperen van data, geavanceerde SQLAlchemy-query’s en leren hoe je essentiële databases kunt raadplegen, opbouwen en naar schrijven, waaronder SQLite, MySQL en PostgreSQL.

SQLAlchemy is de Python SQL-toolkit waarmee ontwikkelaars SQL-databases kunnen benaderen en beheren met Pythonic domeintaal. Je kunt een query schrijven als string of Python-objecten aan elkaar koppelen voor vergelijkbare query’s. Werken met objecten geeft ontwikkelaars flexibiliteit en stelt hen in staat om hoogpresterende, SQL-gebaseerde applicaties te bouwen.
Eenvoudig gezegd: het stelt je in staat om databases te verbinden met Python, SQL-query’s uit te voeren via objectgeoriënteerd programmeren en zo je workflow te stroomlijnen.
Het is vrij eenvoudig om het pakket te installeren en te beginnen met coderen.
Je kunt SQLAlchemy installeren met de Python Package Manager (pip):
pip install sqlalchemyAls je de Anaconda-distributie van Python gebruikt, voer dan deze opdracht uit in de conda-terminal:
conda install -c anaconda sqlalchemyLaten we controleren of het pakket succesvol is geïnstalleerd:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Top, we hebben SQLAlchemy versie 1.4.41 succesvol geïnstalleerd.
In deze sectie leren we SQLite-databases te verbinden, tabelobjecten aan te maken en deze te gebruiken om SQL-query’s uit te voeren.
We gebruiken de European Football SQLite-database van Kaggle, met twee tabellen: divisions en matchs.
Eerst maken we SQLite-engineobjecten met create_object en geven we het pad naar de database door. Daarna maken we een connectieobject door de engine te verbinden. We gebruiken het conn-object om alle soorten SQL-query’s uit te voeren.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Als je verbinding wilt maken met PostgreSQL-, MySQL-, Oracle- en Microsoft SQL Server-databases, bekijk dan de engineconfiguratie voor een vlotte verbinding met de server.
Deze SQLAlchemy-tutorial gaat ervan uit dat je de basis van Python en SQL kent. Zo niet, dan is dat helemaal oké. Volg de skill tracks SQL Fundamentals en Python Fundamentals om een sterke basis op te bouwen.
Om een tabelobject te maken, moeten we de tabelnaam en metadata opgeven. Je kunt metadata genereren met de MetaData()-functie van SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectLaten we de metadata van divisions afdrukken.
print(repr(metadata.tables['divisions']))De metadata bevat de tabelnaam, kolomnamen met hun type en het schema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Gebruik het tabelobject division om de kolomnamen af te drukken.
print(division.columns.keys())De tabel bestaat uit de kolommen division, name en country.
['division', 'name', 'country']Nu komt het leuke gedeelte. We gebruiken het tabelobject om de query uit te voeren en de resultaten op te halen.
In de onderstaande code selecteren we alle kolommen van de tabel division.
query = division.select() #SELECT * FROM divisions
print(query)Let op: je kunt het select-commando ook schrijven als db.select([division]).
Om de query te bekijken, print je het queryobject; dan zie je het SQL-commando.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsWe voeren nu de query uit met het connectieobject en halen de eerste vijf rijen op.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Het resultaat toont de eerste vijf rijen van de tabel.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]In deze sectie bekijken we verschillende SQLAlchemy-voorbeelden voor het aanmaken van tabellen, invoegen van waarden, uitvoeren van SQL-query’s, data-analyse en tabelbeheer.
Je kunt meedoen of deze DataLab-workbook bekijken. Het bevat een database, broncode en resultaten.
Eerst maken we een nieuwe database met de naam datacamp.sqlite. De create_engine maakt automatisch een nieuwe database aan als er nog geen database met dezelfde naam bestaat. Aanmaken en verbinden lijken dus sterk op elkaar.
Daarna verbinden we met de database en maken we een metadata-object aan.
We gebruiken de Table-functie van SQLAlchemy om een tabel “Student” te maken.
Deze bestaat uit kolommen:
We hebben de structuur van de tabel aangemaakt. Laten we die toevoegen aan de database met `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Om één rij toe te voegen gebruiken we eerst insert met het tabelobject. Daarna gebruik je values en vul je handmatig de kolommen. Dit werkt vergelijkbaar met het doorgeven van argumenten aan Python-functies.
Tot slot voeren we de query uit via de connectie.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Laten we controleren of we de rij hebben toegevoegd aan de tabel Student door een select-query uit te voeren en alle rijen op te halen.
output = conn.execute(Student.select()).fetchall()
print(output)We hebben de waarden succesvol toegevoegd.
[(1, 'Matthew', 'English', True)]Waarden één voor één toevoegen is niet praktisch. Laten we meerdere waarden toevoegen met lijsten.
Maak een insert-query voor de tabel Student.
Maak een lijst met meerdere rijen met kolomnamen en waarden.
Voer de query uit met als tweede argument values_list.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Voer een simpele select-query uit om te controleren.
output = conn.execute(db.select([Student])).fetchall()
print(output)De tabel bevat nu meer rijen.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]In plaats van Python-objecten kun je ook SQL-query’s als string uitvoeren.
Geef de string door als argument aan de functie execute() en bekijk het resultaat met fetchall().
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Output:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Je kunt zelfs complexere SQL-query’s doorgeven. In ons geval selecteren we de kolommen Name en Major waar de studenten geslaagd zijn.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Output:
[('Matthew', 'English'), ('Natasha', 'Math')]In de vorige secties gebruikten we eenvoudige SQLAlchemy-API/objecten. Laten we nu meer complexe en meerstapsquery’s bekijken.
In het onderstaande voorbeeld selecteren we alle kolommen waar het hoofdvak van de student English is.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Output:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Laten we AND-logica toepassen op de WHERE-query.
In ons geval zoeken we studenten met English als hoofdvak die gezakt zijn.
Let op: niet gelijk aan ‘!=’ True is False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Alleen Ben is gezakt met English als hoofdvak.
[(4, 'Ben', 'English', False)]Met een soortgelijke tabel kunnen we allerlei commando’s uitvoeren, zoals in de onderstaande tabel.
Je kunt deze commando’s kopiëren en plakken om zelf te testen. Bekijk het DataLab-workbook als je ergens vastloopt.
|
Commando’s |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
and, or, not |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
order by |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
group by |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinct |
db.select([Student.columns.Major.distinct()]) |
Wil je meer weten over andere functies en commando’s? Bekijk de officiële documentatie SQL Statements and Expressions API.
Data scientists en analisten werken graag met pandas-dataframes. In dit onderdeel leren we hoe je een SQLAlchemy-queryresultaat omzet naar een pandas-dataframe.
Voer eerst de query uit en sla de resultaten op.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Gebruik daarna de functie DataFrame() en geef de SQL-resultaten als argument door. Voeg tenslotte de kolomnamen toe met de eerste rij van het resultaat results[0] en .keys().
Let op: je kunt elke geldige rij gebruiken om de kolomnamen met keys() op te halen.
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
In dit onderdeel verbinden we met de European Football-database, voeren we complexe query’s uit en visualiseren we de resultaten.
Zoals gewoonlijk verbinden we de database met de functies create_engine() en connect().
In ons geval voegen we twee tabellen samen, dus maken we twee tabelobjecten aan: division en match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Je kunt nog complexere query’s maken door extra modules toe te voegen.
Let op: om twee tabellen automatisch te joinen kun je ook gebruiken: db.select([division.columns.division,match.columns.Div]).
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data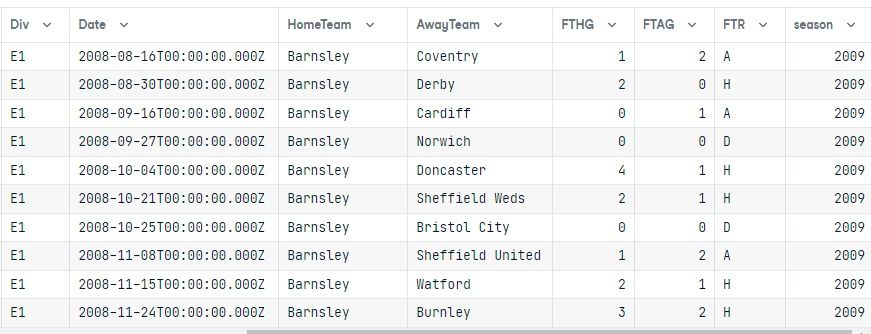
Na het uitvoeren van de query hebben we het resultaat omgezet in een pandas-dataframe.
Beide tabellen zijn gejoined en de resultaten tonen alleen de E1-divisie voor het seizoen 2009, gesorteerd op de kolom HomeTeam.
Nu we een dataframe hebben, kunnen we de resultaten visualiseren als staafdiagram met Seaborn.
We zullen:
Het doel hier is te laten zien hoe je de output van een SQL-query kunt gebruiken om sterke datavisualisaties te maken.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)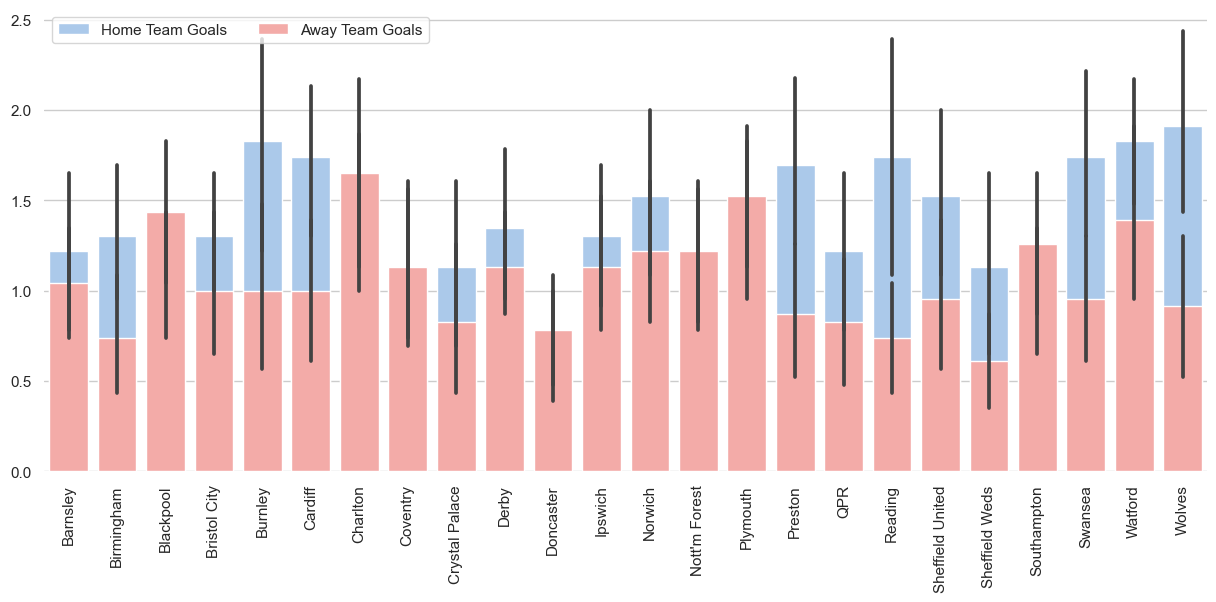
Nadat je het queryresultaat naar een pandas-dataframe hebt omgezet, kun je eenvoudig de functie .to_csv() gebruiken met de bestandsnaam.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Voorkom een kolom genaamd “Index” door `index=False` te gebruiken.
data.to_csv("SQl_result.csv",index=False)In dit onderdeel zetten we het CSV-bestand met beursgegevens om naar een SQL-tabel.
Verbind eerst met de datacamp-sqlite-database.
engine = create_engine("sqlite:///datacamp.sqlite")Importeer vervolgens het CSV-bestand met de functie read_csv(). Gebruik tot slot de functie to_sql() om het pandas-dataframe als SQL-tabel op te slaan.
Primair heeft de functie to_sql() een connectie en tabelnaam als argument nodig. Je kunt ook if_exisits gebruiken om een bestaande tabel met dezelfde naam te vervangen en index om de indexkolom te verwijderen.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Om de resultaten te valideren, verbinden we met de database en maken we een tabelobject aan.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Voer daarna de query uit en toon de resultaten.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Zoals je ziet, hebben we alle waarden uit het CSV-bestand succesvol overgezet naar de SQL-tabel.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Waarden bijwerken is eenvoudig. We gebruiken de functies update, values en where om een specifieke waarde in de tabel te wijzigen.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)In ons geval hebben we de waarde Pass van False naar True gewijzigd waar de naam van de student Nisha is.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Voer om te controleren een eenvoudige query uit en toon de resultaten in een pandas-dataframe.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataWe hebben de waarde Pass voor de student Nisha succesvol gewijzigd naar True.
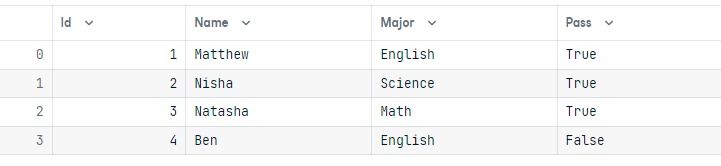
Rijen verwijderen lijkt op bijwerken. Je hebt de functies delete() en where() nodig.
table.delete().where(table.columns.column_1 == 6)In ons geval verwijderen we het record van de student met de naam Ben.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Om de resultaten te controleren, voeren we een snelle query uit en tonen we de resultaten als dataframe. Zoals je ziet hebben we de rij met de student Ben verwijderd.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Als je SQLite gebruikt, kan het droppen van een tabel de fout database is locked geven. Waarom? Omdat SQLite erg lichtgewicht is en maar één bewerking tegelijk kan uitvoeren. Op dit moment wordt er een select-query uitgevoerd. We moeten de volledige uitvoering sluiten voordat we de tabel kunnen verwijderen.
results.close()
exe.close()Gebruik daarna de functie drop_all() van metadata en geef een tabelobject op om een enkele tabel te droppen. Je kunt ook het commando Student.drop(engine) gebruiken om één tabel te droppen.
metadata.drop_all(engine, [Student], checkfirst=True)Als je geen tabel specificeert voor de functie drop_all(), dan dropt deze alle tabellen in de database.
metadata.drop_all(engine)De SQLAlchemy-tutorial behandelt verschillende functies van SQLAlchemy, van het verbinden met de database tot het wijzigen van tabellen. Wil je meer leren, rond dan de interactieve cursus Introduction to Databases in Python af. Je leert de basis van relationele databases, filteren, sorteren en groeperen. Daarnaast leer je geavanceerde SQLAlchemy-functies voor datamanipulatie.
Loop je ergens tegenaan bij het volgen van de tutorial, ga dan naar het DataLab-workbook en vergelijk je code ermee. Je kunt ook een kopie maken van het workbook en het direct in DataLab uitvoeren.
Python & SQL-cursussen
Cursus
Cursus
blog
Adel Nehme
15 min
