
Kurs
Introduction to Databases in Python
4 sa
101.5K
Bu makale, sorgulama, veritabanı oluşturma ve yönetme gibi görevleri basitleştiren Python için bir SQL araç takımı olan SQLAlchemy’yi adım adım anlatacaktır.
Bu eğitimi okuduktan sonra daha fazla pratik için Python’da Veritabanlarına Giriş kursumuza katılmanızı öneririm. Öne çıkanlar arasında, verileri filtreleme ve gruplamadan gelişmiş SQLAlchemy sorgularına uzanan uygulamalı projeler ve SQLite, MySQL ve PostgreSQL dahil temel veritabanlarını sorgulama, oluşturma ve yazma yer alır.

SQLAlchemy, geliştiricilerin Pythonik alan dili kullanarak SQL veritabanlarına erişmesine ve bunları yönetmesine olanak tanıyan Python SQL araç takımıdır. Bir sorguyu metin olarak yazabilir veya benzer sorgular için Python nesnelerini zincirleyebilirsiniz. Nesnelerle çalışmak geliştiricilere esneklik sağlar ve yüksek performanslı SQL tabanlı uygulamalar kurmalarına imkân tanır.
Kısaca, kullanıcıların Python diliyle veritabanlarına bağlanmasını, nesne tabanlı programlama ile SQL sorguları çalıştırmasını ve iş akışını sadeleştirmesini sağlar.
Paketi yüklemek ve kodlamaya başlamak oldukça kolaydır.
SQLAlchemy’yi Python Paket Yöneticisi (pip) ile kurabilirsiniz:
pip install sqlalchemyEğer Python’un Anaconda dağıtımını kullanıyorsanız, conda terminaline şu komutu girin:
conda install -c anaconda sqlalchemyPaketin başarıyla kurulup kurulmadığını kontrol edelim:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Harika, SQLAlchemy 1.4.41 sürümünü başarıyla kurduk.
Bu bölümde SQLite veritabanlarına bağlanmayı, tablo nesneleri oluşturmayı ve bunları kullanarak SQL sorguları çalıştırmayı öğreneceğiz.
Kaggle’daki European Football SQLite veritabanını kullanacağız ve içinde iki tablo var: divisions ve matchs.
Önce, create_object kullanarak SQLite engine nesneleri oluşturacak ve veritabanının konum adresini ileteceğiz. Ardından, engine’i bağlayarak bir bağlantı nesnesi oluşturacağız. Tüm SQL sorgularını çalıştırmak için conn nesnesini kullanacağız.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() PostgreSQL, MySQL, Oracle ve Microsoft SQL Server veritabanlarına bağlanmak isterseniz, sunucuya sorunsuz bağlanmak için engine yapılandırmasına göz atın.
Bu SQLAlchemy eğitimi, Python ve SQL’in temellerini bildiğinizi varsayar. Bilmiyorsanız da sorun değil. Sağlam bir temel oluşturmak için SQL Fundamentals ve Python Fundamentals beceri yollarını alabilirsiniz.
Bir tablo nesnesi oluşturmak için tablo adlarını ve üstveriyi sağlamamız gerekir. Üstveriyi SQLAlchemy’nin MetaData() fonksiyonunu kullanarak üretebilirsiniz.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectHadi divisions üstverisini yazdıralım.
print(repr(metadata.tables['divisions']))Üstveri; tablo adı, veri türleriyle birlikte sütun adları ve şemayı içerir.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Şimdi sütun adlarını yazdırmak için division tablo nesnesini kullanalım.
print(division.columns.keys())Tablo; division, name ve country sütunlarından oluşur.
['division', 'name', 'country']Şimdi işin eğlenceli kısmına geldik. Sorguyu çalıştırmak ve sonuçları çıkarmak için tablo nesnesini kullanacağız.
Aşağıdaki kodda, division tablosunun tüm sütunlarını seçiyoruz.
query = division.select() #SELECT * FROM divisions
print(query)Not: select komutunu db.select([division]) olarak da yazabilirsiniz.
Sorguyu görmek için sorgu nesnesini yazdırın; SQL komutunu gösterecektir.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsŞimdi sorguyu bağlantı nesnesiyle çalıştıracak ve ilk beş satırı çıkaracağız.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Sonuç, tablonun ilk beş satırını gösterir.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]Bu bölümde; tablolar oluşturma, değer ekleme, SQL sorguları çalıştırma, veri analizi ve tablo yönetimi için çeşitli SQLAlchemy örneklerine bakacağız.
Adımları takip edebilir veya bu DataLab çalışma defterine göz atabilirsiniz. İçinde bir veritabanı, kaynak kodu ve sonuçlar bulunur.
Önce datacamp.sqlite adlı yeni bir veritabanı oluşturacağız. create_engine, aynı ada sahip bir veritabanı yoksa otomatik olarak yeni bir veritabanı oluşturur. Bu nedenle, oluşturma ve bağlanma süreçleri oldukça benzerdir.
Ardından, veritabanına bağlanacak ve bir üstveri nesnesi oluşturacağız.
“Student” adlı bir tablo oluşturmak için SQLAlchemy’nin Table fonksiyonunu kullanacağız
Şu sütunlardan oluşur:
Tablonun yapısını oluşturduk. Bunu veritabanına `metadata.create_all(engine)` ile ekleyelim.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Tek bir satır eklemek için önce insert kullanıp tablo nesnesini ekleyeceğiz. Sonrasında values ile sütunlara değerleri elle gireceğiz. Bu, Python fonksiyonlarına argüman eklemeye benzer şekilde çalışır.
Son olarak, sorguyu bağlantı üzerinden çalıştırarak fonksiyonu icra edeceğiz.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Bir select sorgusu çalıştırıp tüm satırları çekerek Student tablosuna satır ekleyip eklemediğimizi kontrol edelim.
output = conn.execute(Student.select()).fetchall()
print(output)Değerleri başarıyla ekledik.
[(1, 'Matthew', 'English', True)]Değerleri tek tek eklemek veritabanını doldurmanın pratik bir yolu değildir. Listelerle birden fazla değeri ekleyelim.
Student tablosu için bir insert sorgusu oluşturun.
Sütun adları ve değerleriyle birden çok satırdan oluşan bir liste oluşturun.
Sorguyu ikinci argüman olarak values_list ile çalıştırın.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Sonuçlarımızı doğrulamak için basit bir select sorgusu çalıştırın.
output = conn.execute(db.select([Student])).fetchall()
print(output)Tablo artık daha fazla satır içeriyor.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Python nesneleri yerine, SQL sorgularını metin olarak da çalıştırabiliriz.
execute() fonksiyonuna argüman olarak metni ekleyin ve sonucu fetchall() ile görüntüleyin.
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Çıktı:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Daha karmaşık SQL sorguları da iletebilirsiniz. Bizim örneğimizde, sınavı geçen öğrenciler için Name ve Major sütunlarını seçiyoruz.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Çıktı:
[('Matthew', 'English'), ('Natasha', 'Math')]Önceki bölümlerde basit SQLAlchemy API/Nesnelerini kullanıyorduk. Şimdi daha karmaşık ve çok adımlı sorgulara dalalım.
Aşağıdaki örnekte, öğrencinin ana dalının İngilizce olduğu durumlarda tüm sütunları seçeceğiz.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Çıktı:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]WHERE sorgusuna AND mantığını uygulayalım.
Bizim örneğimizde, ana dalı İngilizce olan ve dersten kalan öğrencileri arıyoruz.
Not: ‘!=’ True, False’a eşittir.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Yalnızca Ben, İngilizce ana dalıyla dersten kalmıştır.
[(4, 'Ben', 'English', False)]Benzer bir tablo üzerinde, aşağıdaki tabloda gösterildiği gibi her tür komutu çalıştırabiliriz.
Bu komutları kopyalayıp yapıştırarak kendi başınıza test edebilirsiniz. Verilen komutlardan herhangi birinde takılırsanız DataLab çalışma defterine bakın.
|
Komutlar |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
and, or, not |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
order by |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
group by |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinct |
db.select([Student.columns.Major.distinct()]) |
Diğer fonksiyonlar ve komutlar hakkında bilgi almak için SQL İfadeleri ve Deyimleri API’si resmi belgelerine bakın.
Veri bilimciler ve analistler pandas veri çerçevelerini sever ve onlarla çalışmayı tercih eder. Bu kısımda, bir SQLAlchemy sorgu sonucunun pandas veri çerçevesine nasıl dönüştürüleceğini öğreneceğiz.
Önce sorguyu çalıştırın ve sonuçları kaydedin.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Sonra DataFrame() fonksiyonunu kullanın ve SQL sonuçlarını argüman olarak verin. Son olarak, sütun adlarını ilk satırın results[0] ve .keys() yöntemini kullanarak ekleyin.
Not: Sütun adlarını çıkarmak için keys() ile geçerli herhangi bir satırı sağlayabilirsiniz.
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
Bu kısımda, Avrupa futbol veritabanına bağlanacak, karmaşık sorgular çalıştıracak ve sonuçları görselleştireceğiz.
Her zamanki gibi, create_engine() ve connect() fonksiyonlarını kullanarak veritabanına bağlanacağız.
Bizim durumumuzda iki tabloyu birleştireceğiz; bu nedenle iki tablo nesnesi oluşturmalıyız: division ve match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Ek modüller ekleyerek daha da karmaşık sorgular oluşturabilirsiniz.
Not: iki tabloyu otomatik birleştirmek için şunu da kullanabilirsiniz: db.select([division.columns.division,match.columns.Div]).
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data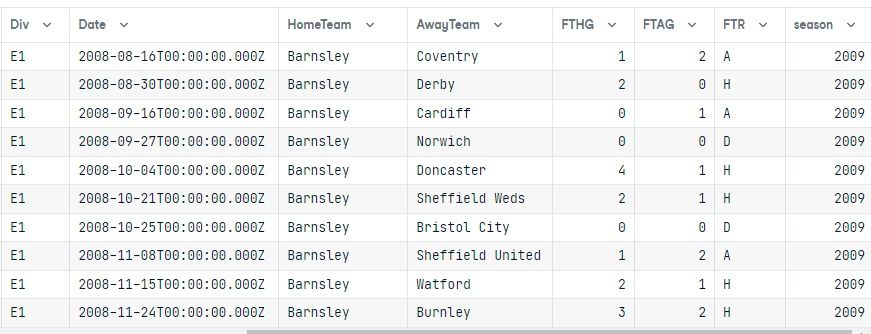
Sorguyu çalıştırdıktan sonra sonucu bir pandas veri çerçevesine dönüştürdük.
Her iki tablo birleştirildi ve sonuçlar, HomeTeam sütununa göre sıralanmış şekilde yalnızca 2009 sezonundaki E1 division’ını gösteriyor.
Artık bir veri çerçevemiz olduğuna göre, sonuçları Seaborn kullanarak çubuk grafik şeklinde görselleştirebiliriz.
Şunları yapacağız:
Bu kısmın temel amacı, bir SQL sorgusunun çıktısını kullanarak nasıl etkileyici veri görselleştirmeleri oluşturabileceğinizi göstermektir.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)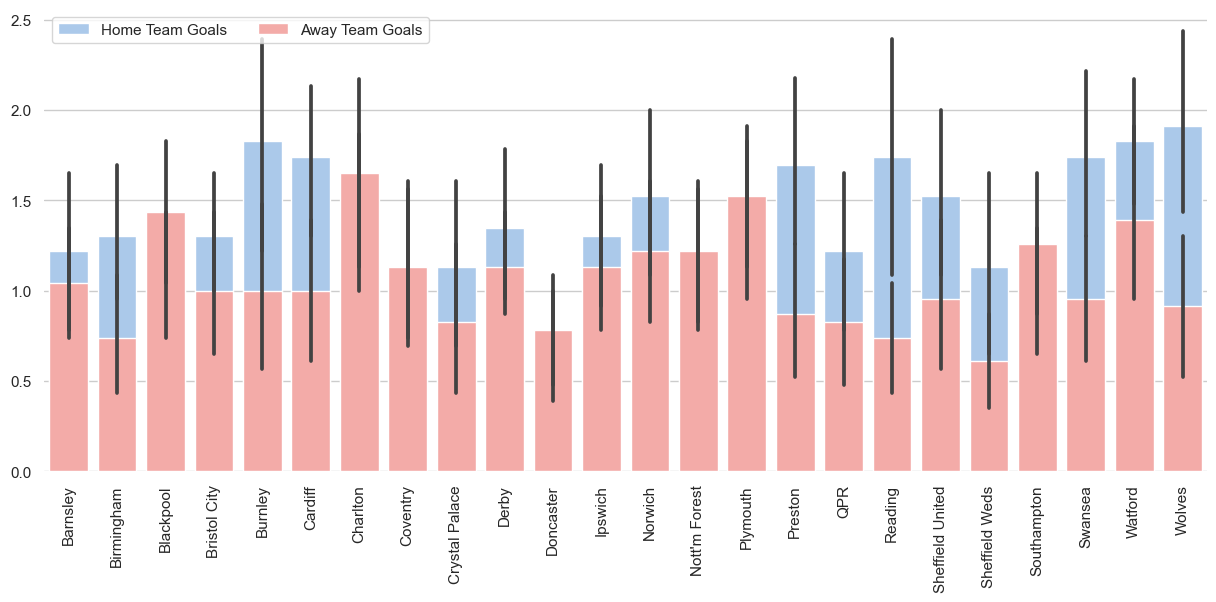
Sorgu sonucunu pandas veri çerçevesine dönüştürdükten sonra, dosya adıyla birlikte .to_csv() fonksiyonunu kolayca kullanabilirsiniz.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()“Index” adlı bir sütun eklemekten kaçınmak için `index=False` kullanın.
data.to_csv("SQl_result.csv",index=False)Bu bölümde, Borsa Verileri CSV dosyasını bir SQL tablosuna dönüştüreceğiz.
Önce datacamp sqlite veritabanına bağlanın.
engine = create_engine("sqlite:///datacamp.sqlite")Ardından, read_csv() fonksiyonunu kullanarak CSV dosyasını içe aktarın. Son olarak, pandas veri çerçevesini bir SQL tablosu olarak kaydetmek için to_sql() fonksiyonunu kullanın.
Temelde to_sql() fonksiyonu, bağlantı ve tablo adını argüman olarak gerektirir. Ayrıca aynı ada sahip mevcut bir tabloyu değiştirmek için if_exisits ve indeks sütununu düşürmek için index argümanlarını kullanabilirsiniz.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Sonuçları doğrulamak için veritabanına bağlanmamız ve bir tablo nesnesi oluşturmamız gerekir.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Ardından, sorguyu çalıştırın ve sonuçları görüntüleyin.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Gördüğünüz gibi, CSV dosyasındaki tüm değerleri başarıyla SQL tablosuna aktardık.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Değerleri güncellemek basittir. Tablodaki belirli bir değeri güncellemek için update, values ve where fonksiyonlarını kullanacağız.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)Bizim durumda, öğrencinin adı Nisha olan yerde Pass değerini False’tan True’ya çevirdik.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Sonuçları doğrulamak için basit bir sorgu çalıştırıp sonuçları bir pandas veri çerçevesi olarak görüntüleyelim.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataNisha adlı öğrenci için Pass değerini True olarak başarıyla değiştirdik.
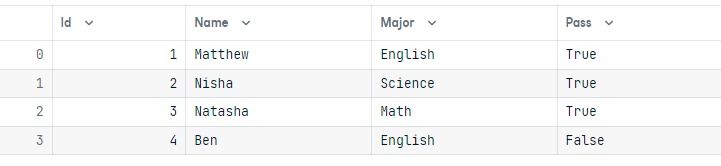
Satırları silmek güncellemeye benzer. delete() ve where() fonksiyonlarını gerektirir.
table.delete().where(table.columns.column_1 == 6)Bizim örneğimizde, adı Ben olan öğrencinin kaydını siliyoruz.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Sonuçları doğrulamak için hızlı bir sorgu çalıştıracak ve sonuçları bir veri çerçevesi olarak görüntüleyeceğiz. Gördüğünüz gibi, adı Ben olan öğrencinin bulunduğu satırı sildik.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
SQLite kullanıyorsanız, tabloyu düşürmek database is locked hatası verecektir. Neden? Çünkü SQLite çok hafif bir sürümdür. Aynı anda yalnızca bir işlem gerçekleştirebilir. Şu anda bir select sorgusu yürütülmektedir. Tabloyu silmeden önce tüm yürütmeyi kapatmamız gerekir.
results.close()
exe.close()Ardından, metadata’nın drop_all() fonksiyonunu kullanın ve tek bir tabloyu düşürmek için bir tablo nesnesi seçin. Tek bir tabloyu düşürmek için Student.drop(engine) komutunu da kullanabilirsiniz.
metadata.drop_all(engine, [Student], checkfirst=True)drop_all() fonksiyonu için herhangi bir tablo belirtmezseniz, veritabanındaki tüm tabloları düşürür.
metadata.drop_all(engine)SQLAlchemy eğitimi, veritabanına bağlanmadan tabloları değiştirmeye kadar SQLAlchemy’nin çeşitli fonksiyonlarını kapsar ve daha fazlasını öğrenmekle ilgileniyorsanız, Python’da İlişkisel Veritabanlarına Giriş etkileşimli kursunu tamamlamayı deneyin. İlişkisel veritabanlarının temelleri, filtreleme, sıralama ve gruplamayı öğreneceksiniz. Ayrıca, veri işleme için gelişmiş SQLAlchemy fonksiyonlarını da öğreneceksiniz.
Eğitimi takip ederken herhangi bir sorunla karşılaşıyorsanız, DataLab çalışma defterine gidin ve kodunuzu onunla karşılaştırın. Çalışma defterinin bir kopyasını çıkarıp doğrudan DataLab içinde de çalıştırabilirsiniz.
Python & SQL Kursları
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
