
Courses
Nhập môn Cơ sở dữ liệu với Python
4 giờ
101.5K
Bài viết này sẽ hướng dẫn bạn về SQLAlchemy, một bộ công cụ SQL cho Python giúp đơn giản hóa các tác vụ như truy vấn, xây dựng và quản lý cơ sở dữ liệu.
Sau khi đọc xong hướng dẫn này, tôi khuyến khích bạn đăng ký khóa học Giới thiệu về cơ sở dữ liệu trong Python của chúng tôi để luyện tập thêm. Điểm nổi bật gồm có các dự án thực hành hướng dẫn bạn lọc và nhóm dữ liệu, các truy vấn SQLAlchemy nâng cao, và học cách truy vấn, xây dựng, ghi dữ liệu vào các cơ sở dữ liệu thiết yếu như SQLite, MySQL và PostgreSQL.

SQLAlchemy là bộ công cụ SQL cho Python cho phép nhà phát triển truy cập và quản lý cơ sở dữ liệu SQL bằng ngôn ngữ miền mang phong cách Pythonic. Bạn có thể viết truy vấn dưới dạng chuỗi hoặc xâu chuỗi các đối tượng Python để tạo các truy vấn tương tự. Làm việc với đối tượng mang lại sự linh hoạt và cho phép xây dựng các ứng dụng hiệu năng cao dựa trên SQL.
Nói đơn giản, nó cho phép người dùng kết nối cơ sở dữ liệu bằng ngôn ngữ Python, chạy các truy vấn SQL bằng lập trình hướng đối tượng và tinh gọn quy trình làm việc.
Việc cài đặt gói và bắt đầu viết mã khá dễ dàng.
Bạn có thể cài đặt SQLAlchemy bằng Trình quản lý gói Python (pip):
pip install sqlalchemyNếu bạn đang dùng bản phân phối Anaconda của Python, hãy thử nhập lệnh trong terminal của conda:
conda install -c anaconda sqlalchemyHãy kiểm tra xem gói đã được cài đặt thành công chưa:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Tuyệt vời, chúng ta đã cài đặt thành công SQLAlchemy phiên bản 1.4.41.
Trong phần này, chúng ta sẽ học cách kết nối cơ sở dữ liệu SQLite, tạo đối tượng bảng và dùng chúng để chạy truy vấn SQL.
Chúng ta sẽ sử dụng cơ sở dữ liệu SQLite European Football từ Kaggle, và nó có hai bảng: divisions và matchs.
Đầu tiên, chúng ta sẽ tạo đối tượng engine SQLite bằng create_object và truyền đường dẫn vị trí của cơ sở dữ liệu. Sau đó, tạo đối tượng kết nối bằng cách kết nối engine. Chúng ta sẽ dùng đối tượng conn để chạy mọi loại truy vấn SQL.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Nếu bạn muốn kết nối các cơ sở dữ liệu PostgreSQL, MySQL, Oracle và Microsoft SQL Server, hãy xem cấu hình engine để kết nối máy chủ mượt mà.
Hướng dẫn SQLAlchemy này giả định rằng bạn nắm được những kiến thức cơ bản về Python và SQL. Nếu chưa, thì cũng không sao. Bạn có thể học các lộ trình kỹ năng SQL Cơ bản và Python Cơ bản để xây nền tảng vững chắc.
Để tạo đối tượng bảng, chúng ta cần cung cấp tên bảng và metadata. Bạn có thể tạo metadata bằng hàm MetaData() của SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectHãy in metadata của divisions.
print(repr(metadata.tables['divisions']))Metadata chứa tên bảng, tên cột với kiểu dữ liệu, và schema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Hãy dùng đối tượng bảng division để in tên các cột.
print(division.columns.keys())Bảng gồm các cột division, name và country.
['division', 'name', 'country']Giờ đến phần thú vị. Chúng ta sẽ dùng đối tượng bảng để chạy truy vấn và trích xuất kết quả.
Trong đoạn mã dưới đây, chúng ta đang chọn tất cả các cột của bảng division.
query = division.select() #SELECT * FROM divisions
print(query)Lưu ý: bạn cũng có thể viết lệnh select là db.select([division]).
Để xem truy vấn, hãy in đối tượng truy vấn, nó sẽ hiển thị câu lệnh SQL.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsBây giờ chúng ta sẽ thực thi truy vấn bằng đối tượng kết nối và trích xuất năm hàng đầu tiên.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Kết quả hiển thị năm hàng đầu tiên của bảng.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]Trong phần này, chúng ta sẽ xem các ví dụ SQLAlchemy khác nhau để tạo bảng, chèn giá trị, chạy truy vấn SQL, phân tích dữ liệu và quản lý bảng.
Bạn có thể làm theo hoặc xem DataLab workbook này. Nó chứa cơ sở dữ liệu, mã nguồn và kết quả.
Đầu tiên, chúng ta sẽ tạo một cơ sở dữ liệu mới tên là datacamp.sqlite. create_engine sẽ tự động tạo cơ sở dữ liệu mới nếu chưa có cơ sở dữ liệu trùng tên. Vì vậy, tạo và kết nối gần như tương tự nhau.
Sau đó, chúng ta sẽ kết nối cơ sở dữ liệu và tạo đối tượng metadata.
Chúng ta sẽ dùng hàm Table của SQLAlchmy để tạo một bảng tên “Student”
Nó bao gồm các cột:
Chúng ta đã tạo cấu trúc của bảng. Hãy thêm nó vào cơ sở dữ liệu bằng `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Để thêm một hàng, trước tiên chúng ta sẽ dùng insert và thêm đối tượng bảng. Sau đó, dùng values và thêm thủ công giá trị cho các cột. Cách này hoạt động tương tự như thêm đối số vào hàm Python.
Cuối cùng, chúng ta sẽ thực thi truy vấn bằng đối tượng kết nối để thực hiện hàm.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Hãy kiểm tra xem chúng ta đã thêm hàng vào bảng Student chưa bằng cách chạy truy vấn select và lấy tất cả các hàng.
output = conn.execute(Student.select()).fetchall()
print(output)Chúng ta đã thêm giá trị thành công.
[(1, 'Matthew', 'English', True)]Thêm giá trị từng cái một không phải là cách thực tế để đổ dữ liệu. Hãy thêm nhiều giá trị bằng danh sách.
Tạo một truy vấn insert cho bảng Student.
Tạo một danh sách nhiều hàng với tên cột và giá trị.
Thực thi truy vấn với đối số thứ hai là values_list.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Để kiểm chứng kết quả, hãy chạy truy vấn select đơn giản.
output = conn.execute(db.select([Student])).fetchall()
print(output)Bảng hiện đã có nhiều hàng hơn.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Thay vì dùng các đối tượng Python, chúng ta cũng có thể thực thi truy vấn SQL bằng chuỗi.
Chỉ cần thêm đối số dạng Chuỗi vào hàm execute() và xem kết quả bằng fetchall().
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Kết quả:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Bạn thậm chí có thể truyền các truy vấn SQL phức tạp hơn. Ở đây, chúng ta chọn các cột Name và Major nơi sinh viên đã đỗ kỳ thi.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Kết quả:
[('Matthew', 'English'), ('Natasha', 'Math')]Ở các phần trước, chúng ta đã dùng các API/Đối tượng SQLAlchemy đơn giản. Hãy đi sâu vào các truy vấn phức tạp và nhiều bước hơn.
Trong ví dụ dưới đây, chúng ta sẽ chọn tất cả các cột nơi chuyên ngành của sinh viên là English.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Kết quả:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Hãy áp dụng logic AND cho truy vấn WHERE.
Trong trường hợp này, chúng ta tìm sinh viên có chuyên ngành English và bị trượt.
Lưu ý: khác với ‘!=’ True là False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Chỉ có Ben trượt kỳ thi với chuyên ngành English.
[(4, 'Ben', 'English', False)]Với một bảng tương tự, chúng ta có thể chạy mọi loại lệnh như trong bảng dưới đây.
Bạn có thể sao chép và dán các lệnh này để tự kiểm thử kết quả. Xem DataLab workbook nếu bạn gặp khó khăn với bất kỳ lệnh nào.
|
Lệnh |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
and, or, not |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
order by |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
group by |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinct |
db.select([Student.columns.Major.distinct()]) |
Để tìm hiểu các hàm và lệnh khác, hãy xem tài liệu chính thức API Câu lệnh và Biểu thức SQL.
Các nhà khoa học dữ liệu và nhà phân tích đánh giá cao dataframe của pandas và thích làm việc với chúng. Ở phần này, chúng ta sẽ học cách chuyển kết quả truy vấn SQLAlchemy thành một dataframe pandas.
Đầu tiên, thực thi truy vấn và lưu kết quả.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Sau đó, dùng hàm DataFrame() và cung cấp kết quả SQL làm đối số. Cuối cùng, thêm tên cột bằng hàng đầu tiên của kết quả results[0] và .keys().
Lưu ý: bạn có thể cung cấp bất kỳ hàng hợp lệ nào để trích xuất tên cột bằng keys().
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
Trong phần này, chúng ta sẽ kết nối cơ sở dữ liệu European football, thực hiện các truy vấn phức tạp và trực quan hóa kết quả.
Như thường lệ, chúng ta sẽ kết nối cơ sở dữ liệu bằng các hàm create_engine() và connect().
Trong trường hợp này, chúng ta sẽ nối hai bảng, vì vậy cần tạo hai đối tượng bảng: division và match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Bạn còn có thể tạo các truy vấn phức tạp hơn bằng cách thêm các mô-đun bổ sung.
Lưu ý: để tự động nối hai bảng, bạn cũng có thể dùng: db.select([division.columns.division,match.columns.Div]).
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data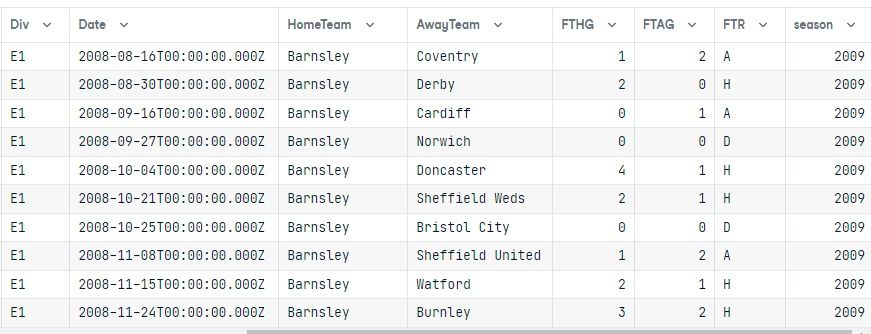
Sau khi thực thi truy vấn, chúng ta đã chuyển kết quả thành một dataframe pandas.
Hai bảng đã được nối, và kết quả chỉ hiển thị giải E1 cho mùa 2009 được sắp xếp theo cột HomeTeam.
Bây giờ chúng ta đã có một dataframe, có thể trực quan hóa kết quả dưới dạng biểu đồ cột bằng Seaborn.
Chúng ta sẽ:
Mục đích chính của phần này là cho bạn thấy cách sử dụng đầu ra của truy vấn SQL để tạo nên các trực quan hóa dữ liệu ấn tượng.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)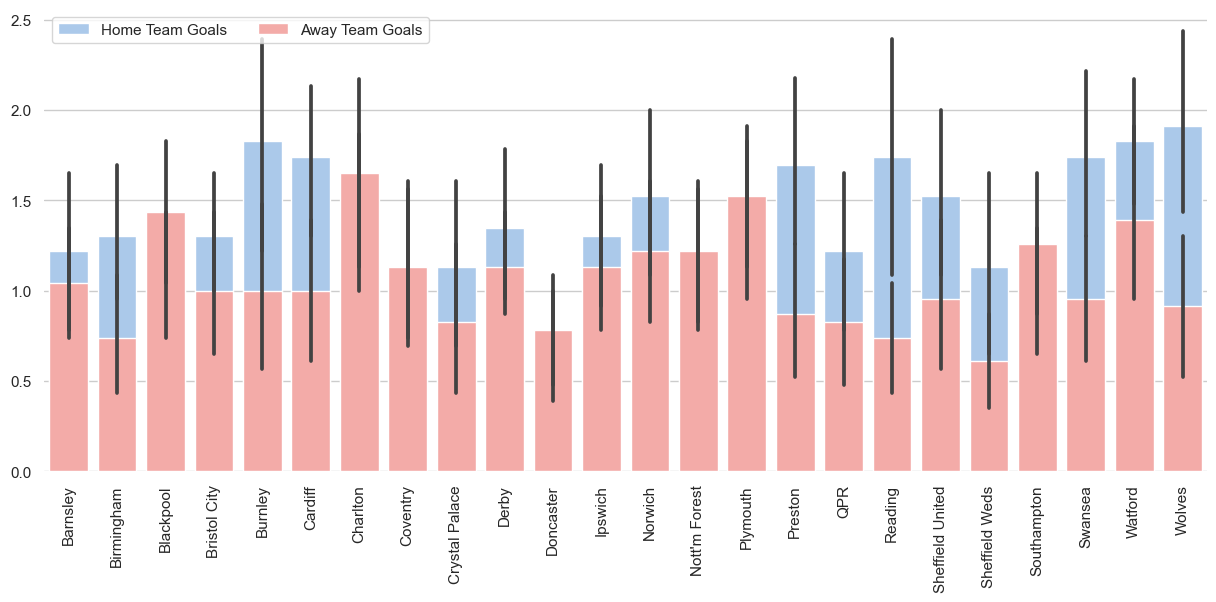
Sau khi chuyển kết quả truy vấn thành dataframe pandas, bạn có thể đơn giản dùng hàm .to_csv() với tên tệp.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Tránh thêm một cột tên “Index” bằng cách dùng `index=False`.
data.to_csv("SQl_result.csv",index=False)Trong phần này, chúng ta sẽ chuyển tệp CSV Dữ liệu Thị trường Chứng khoán thành một bảng SQL.
Trước tiên, kết nối tới cơ sở dữ liệu sqlite của datacamp.
engine = create_engine("sqlite:///datacamp.sqlite")Sau đó, nhập tệp CSV bằng hàm read_csv(). Cuối cùng, dùng hàm to_sql() để lưu dataframe pandas thành một bảng SQL.
Về cơ bản, hàm to_sql() cần kết nối và tên bảng làm đối số. Bạn cũng có thể dùng if_exisits để thay thế một bảng hiện có trùng tên và index để bỏ cột chỉ mục.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Để kiểm chứng kết quả, chúng ta cần kết nối cơ sở dữ liệu và tạo đối tượng bảng.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Sau đó, thực thi truy vấn và hiển thị kết quả.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Như bạn thấy, chúng ta đã chuyển thành công tất cả giá trị từ tệp CSV sang bảng SQL.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Cập nhật giá trị khá đơn giản. Chúng ta sẽ dùng các hàm update, values và where để cập nhật giá trị cụ thể trong bảng.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)Trong trường hợp này, chúng ta đã đổi giá trị Pass từ False thành True nơi tên sinh viên là Nisha.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Để kiểm chứng kết quả, hãy thực thi truy vấn đơn giản và hiển thị kết quả dưới dạng dataframe pandas.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataChúng ta đã đổi thành công giá trị Pass thành True cho sinh viên tên Nisha.
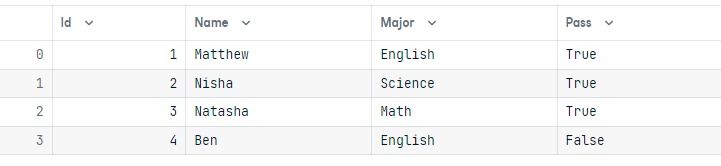
Xóa hàng tương tự như cập nhật. Nó cần các hàm delete() và where().
table.delete().where(table.columns.column_1 == 6)Trong trường hợp này, chúng ta đang xóa bản ghi của sinh viên tên Ben.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Để kiểm chứng kết quả, chúng ta sẽ chạy một truy vấn nhanh và hiển thị kết quả dưới dạng dataframe. Như bạn thấy, chúng ta đã xóa hàng chứa sinh viên tên Ben.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Nếu bạn dùng SQLite, xóa bảng sẽ ném lỗi database is locked. Tại sao? Vì SQLite là phiên bản rất nhẹ. Nó chỉ có thể thực hiện một chức năng tại một thời điểm. Hiện tại, nó đang thực thi một truy vấn select. Chúng ta cần đóng toàn bộ thực thi trước khi xóa bảng.
results.close()
exe.close()Sau đó, dùng hàm drop_all() của metadata và chọn đối tượng bảng để xóa một bảng đơn lẻ. Bạn cũng có thể dùng lệnh Student.drop(engine) để xóa một bảng đơn.
metadata.drop_all(engine, [Student], checkfirst=True)Nếu bạn không chỉ định bảng nào cho hàm drop_all(), nó sẽ xóa tất cả các bảng trong cơ sở dữ liệu.
metadata.drop_all(engine)Hướng dẫn SQLAlchemy này bao quát nhiều chức năng của SQLAlchemy, từ kết nối cơ sở dữ liệu đến sửa đổi bảng, và nếu bạn muốn học thêm, hãy thử hoàn thành khóa học tương tác Giới thiệu về cơ sở dữ liệu trong Python. Bạn sẽ học về những điều cơ bản của cơ sở dữ liệu quan hệ, lọc, sắp xếp và nhóm dữ liệu. Hơn nữa, bạn sẽ học các hàm SQLAlchemy nâng cao để thao tác dữ liệu.
Nếu bạn gặp vấn đề khi theo dõi hướng dẫn, hãy truy cập DataLab workbook và so sánh mã của bạn với đó. Bạn cũng có thể tạo một bản sao của workbook và chạy trực tiếp trong DataLab.
Khóa học Python & SQL
Courses
Courses