
Programa
Engenheiro de dados Em Python
40 h
Como começar a trabalhar com engenharia de dados não é fácil. Em salas de aula e até mesmo em cursos on-line, você domina os fundamentos da escrita Python e SQL. Você pode até aprender um pouco sobre estruturas e ferramentas como Airflow, Databricks e Snowflake.
Uma coisa é você escrever um código que funcione. Outra coisa é escrever testes para esse código e enviá-lo para a produção, onde ele será executado em um ambiente corporativo. Felizmente, a engenharia de software já descobriu isso, e a engenharia de dados está começando a se atualizar.
Como eles fazem isso, você pode se perguntar? CI/CD. Como sabemos que o código será executado na "natureza"? Como sabemos que ele não está quebrado? Como enviamos o código final para ser executado na produção depois de ter sido aprovado? Neste artigo, exploramos a CI/CD na engenharia de dados. Também temos um guia separado sobre CI/CD em aprendizado de máquina.
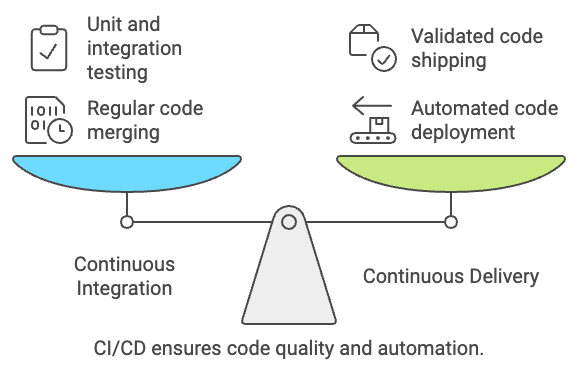
CI/CD significa integração contínua, entrega/implantação contínua. Neste momento, isso pode não significar muito para você; vamos detalhar melhor.
A integração contínua é o processo de mesclar regularmente as alterações de código em um repositório central. Por exemplo, digamos que você tenha feito uma alteração bem-sucedida em uma função Python na base de código do pipeline de dados da sua equipe de engenharia. A integração contínua diz que esse código deve ser trazido de volta ao repositório central.
Mas há mais do que você imagina. Esse código deve ser rastreado com uma espécie de ferramenta de controle de versão (como git) e testado usando testes de unidade e de integração sempre que uma nova alteração for feita. Isso permite duas coisas: primeiro, garantir que as alterações mais recentes na base de código estejam disponíveis para todos os outros usuários e, segundo, validar se a alteração do código realmente funciona conforme o esperado.
Depois que você mescla seu código de volta à base de código central e o testa, como ele chega à produção? É aí que entra o CD. CD significa continuous delivery/deployment (entrega/implantação contínua) e é a prática de implantar alterações feitas no código de forma automatizada.
Alguns podem argumentar que os testes de unidade e integração fazem parte da implantação contínua, mas, independentemente disso, somente o código que foi validado será enviado para a produção
Criado com o Napkin.AI
Portanto, juntando tudo isso, CI/CD é o processo de ponta a ponta para garantir que o código funcione (integração contínua) antes de enviá-lo para a produção (entrega contínua) de forma automatizada. Para implementar a CI/CD, precisaremos usar pipelines de CI/CD, que veremos mais detalhadamente a seguir.
As práticas recomendadas de engenharia de dados estão se aproximando das diretrizes estabelecidas pela engenharia de software. Tarefas como desenvolver e executar testes unitários e manter um ambiente de teste/QA dedicado não são mais exclusivas de nossos amigos engenheiros de software. Isso inclui CI/CD.
Você não precisa ir muito longe para encontrar casos de uso na pilha de engenharia de dados para CI/CD. Aqui estão apenas alguns casos de uso comuns:
Adicionar CI/CD a um ciclo de vida de desenvolvimento de "engenharia de dados" tem muitas vantagens, incluindo coisas como a governança sobre a qualidade do código que está sendo enviado para a produção e a redução do esforço manual para liberar essas alterações.
A CI/CD também oferece uma camada de visibilidade das etapas de cada versão e pode limitar o acesso a determinadas ações a um determinado grupo de pessoas.
Para executar a CI/CD, você precisará usar um pipeline de CI/CD. Um pipeline de CI/CD é uma série de etapas executadas para testar (CI) e implantar (CD) o código na produção depois que ele foi verificado novamente no repositório central. Aqui você pode dar uma olhada rápida na aparência de um pipeline de CI/CD.
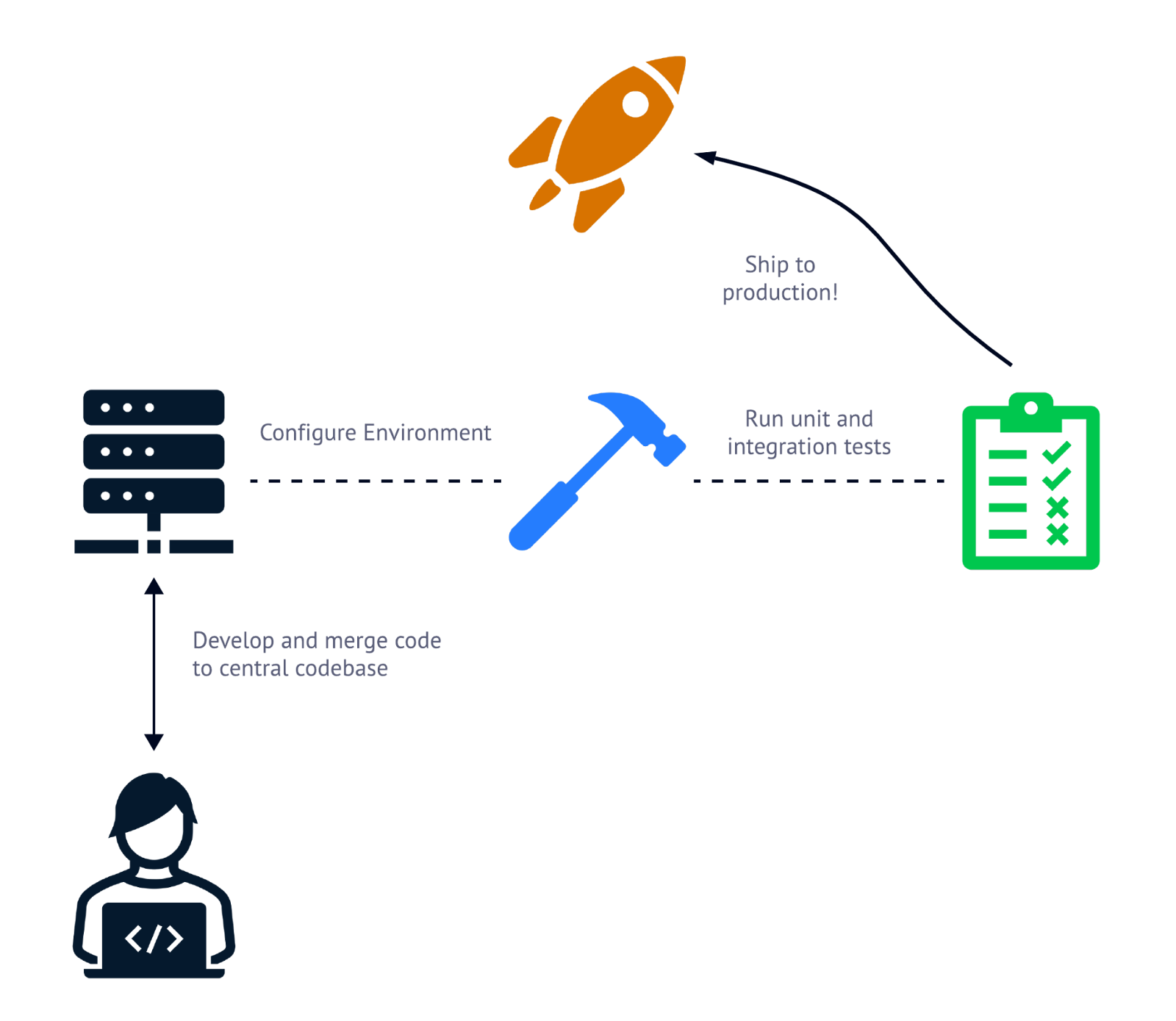
Normalmente, os pipelines de CI/CD são compostos de três etapas: configuração do ambiente de criação/implantação, execução de testes e envio do código para produção.
Normalmente, há três tipos de operações em um pipeline de CI/CD. Primeiro, o ambiente necessário para testar e implantar o código deve ser configurado onde o pipeline está sendo executado. Isso pode incluir tarefas como a instalação de uma CLI, a obtenção de segredos e, o mais importante, o download da base de código recém-atualizada.
Depois de configurar o ambiente, o código que está sendo liberado deve ser testado. É aqui que os testes unitários e de integração são executados na base de código recém-atualizada. Depois de passar em cada um dos casos de teste, o código atualizado pode ser implantado na produção.
Você está procurando uma ferramenta para executar seus pipelines de CI/CD? Para a sorte de vocês, há muitos! De ofertas de código aberto a serviços totalmente gerenciados, não faltam opções para você orquestrar seus processos de CI/CD. Aqui estão apenas algumas das ferramentas de CI/CD mais populares que existem.
Quando você pensa em controle de versão, é provável que pense no GitHub. O GitHub é um dos locais mais populares para armazenar seu código e, por esse motivo, um dos mais atraentes para gerenciar seus pipelines de CI/CD.
Ações do GitHub é uma oferta de CI/CD totalmente gerenciada que permite que os usuários do GitHub desenvolvam, executem e gerenciem seus pipelines de CI/CD. Os pipelines são definidos por meio de arquivos YAML, normalmente acionados em uma ação, como um push para um determinado branch ou um pull request sendo mesclado. O uso das ações do GitHub permite uma experiência unificada para o desenvolvedor e um painel de controle central para o controle de versões e o gerenciamento de versões.
Na outra ponta do espectro está Jenkins. O Jenkins é uma oferta de CI/CD de código aberto que facilita a criação e a manutenção de pipelines personalizados e é frequentemente considerado o padrão do setor para CI/CD.
O Jenkins apresenta uma camada adicional de extensibilidade, incluindo plugins pré-construídos e suporte para uma arquitetura distribuída. Com o Jenkins, se você pode sonhar com isso, é provável que possa construí-lo. Porém, com essa capacidade de personalização, vem a responsabilidade, incluindo um certo nível de gerenciamento do próprio Jenkins.
Diferente do GitHub Actions, o Jenkins é um programa que precisa ser hospedado e gerenciado pelos próprios usuários. Para isso, uma equipe de engenharia de dados precisa configurar e gerenciar itens como o servidor Jenkins, agentes de compilação, acesso de segurança, integrações com um cliente de controle de versão e um ambiente de tempo de execução Java. Isso significa uma sobrecarga significativa e pode não fazer sentido para lojas menores.
Para as equipes de engenharia de dados com presença na nuvem, usar uma solução de CI/CD do provedor de nuvem costuma ser bastante atraente. O AWS oferece ferramentas como o CodeBuild e o CodePipeline. O Azure oferece suporte a DevOps e pipelines, e o GCP oferece o Cloud Build.
Normalmente, os aplicativos em um ambiente de nuvem existente não precisam passar por aquisições e não exigem gastos comprometidos. Essas ferramentas geralmente são intuitivas para os engenheiros de dados que estão acostumados a trabalhar na nuvem e são fáceis de usar.
Ao configurar seu próprio fluxo de trabalho de CI/CD, existem algumas práticas recomendadas que ajudam a tornar a experiência perfeita. Em primeiro lugar, o controle de versão.
Rastrear seu código usando o controle de versão é o primeiro passo para você criar uma plataforma de dados robusta. As ferramentas de controle de versão (como git) não só permitem que o código seja rastreado, mas também que uma versão de produção do código seja mantida. Os clientes de controle de versão (como o GitHub) podem ser usados para acionar um pipeline de CI/CD quando ocorrer um determinado evento.
Aqui está um exemplo de fluxo de trabalho; você é um engenheiro de dados encarregado de criar um novo fluxo de trabalho de ETL. Para fazer isso, você verifica uma ramificação de recurso e faz suas alterações nessa ramificação. Quando estiver pronto para colocar essas alterações em produção, você mesclará sua ramificação de recurso com a ramificaçãoprincipal do site , que acionará um pipeline de CI/CD, implantando seu código na produção.
Nem sempre é possível adicionar visibilidade a um pipeline de CI/CD, mas quando for possível, é importante que você faça isso. Dependendo da ferramenta de CI/CD que estiver usando, você pode dividir cada etapa do pipeline em uma única tarefa. Assim, se uma dessas tarefas falhar, será fácil identificar e iniciar a correção. Se você estiver usando o GitHub Actions para executar seus pipelines de CI/CD, tente dividir as etapas de configuração do ambiente, testes e implantação em três tarefas diferentes.
Tão importante quanto a visibilidade da execução real do pipeline é a documentação. A adição de notas sobre como um pipeline é acionado, os testes que estão sendo executados na base de código e o destino da implantação ajudam a iniciar o processo de solução de problemas
Provavelmente, você precisará usar algum tipo de senha ou chave para implantar sua base de código depois de testada. É importante nunca armazenar essas informações confidenciais na própria configuração de um pipeline de CI/CD (fazer isso é uma maneira infalível de enlouquecer sua equipe de segurança). Em vez disso, aproveite as ferramentas de CI/CD para armazenar e referenciar esses segredos como variáveis. Com uma ferramenta como o AWS CodeBuild, os valores confidenciais podem ser armazenados fora da definição do pipeline usando variáveis de ambiente, que são então referenciadas com segurança.
Até agora, discutimos apenas o uso de um pipeline de CI/CD para enviar o código para a produção. No entanto, os processos de desenvolvimento de nível empresarial são um pouco diferentes. Em vez de enviar diretamente para a produção quando uma alteração de código é feita, os engenheiros de dados normalmente enviam o código para um ambiente de teste dedicado.
Isso permite que eles testem a solução manualmente, garantindo que ela produza os resultados esperados. Para isso, tanto oteste quanto a ramificaçãoprincipal serão mantidos usando o controle de versão, cada um acionando um trabalho de CI/CD ligeiramente diferente quando ocorrer um determinado evento.
Sim, a CI/CD pode ser complicada. E sim, você pode levar algum tempo para configurar inicialmente. No entanto, a CI/CD é um investimento que permite liberações de código controladas e eficientes em um ambiente de produção. Gastar tempo antecipadamente para desenvolver um pipeline de CI/CD ajuda a reduzir o tempo gasto manualmente com testes de alterações de código e empacotamento de código para envio à produção.
Compreender e implementar a CI/CD é uma das maneiras mais rápidas de elevar o nível da sua carreira. Se você puder criar um projeto em Python ou SQL, terá desenvolvido habilidades sólidas e fundamentais como engenheiro de dados. Mas, se você puder criar um fluxo de trabalho de CI/CD com casos de teste que são executados sempre que são feitas alterações e automatizar um push de produção, você mostrou que está pronto para criar soluções de nível empresarial.
Comece a trilhar seu caminho para se tornar um engenheiro de dados hoje mesmo com o curso de Engenheiro de dados em Python e a certificação Certificação de carreira de engenheiro de dados.
Principais cursos da DataCamp
Programa
Programa
Curso