programa
Ingeniero de datos en Python
40 h
Iniciarse en ingeniería de datos no es fácil. En las aulas, e incluso en los cursos online, se dominan los fundamentos de la escritura de Python y SQL. Puede que incluso aprendas algo sobre marcos de trabajo y herramientas como Airflow, Databricks y Snowflake.
Una cosa es escribir código que funcione. Otra cosa es escribir pruebas para este código y enviarlo a producción, donde se ejecutará en un entorno empresarial. Por suerte, la ingeniería de software se ha dado cuenta de esto, y la ingeniería de datos está empezando a ponerse al día.
¿Cómo lo hacen? CI/CD. ¿Cómo sabemos que el código se agotará en la "naturaleza"? ¿Cómo sabemos que no está roto? ¿Cómo enviamos el código final para que se ejecute en producción una vez que ha sido aprobado? En este artículo, exploramos la CI/CD en la ingeniería de datos. También tenemos una guía separada sobre CI/CD en el aprendizaje automático.
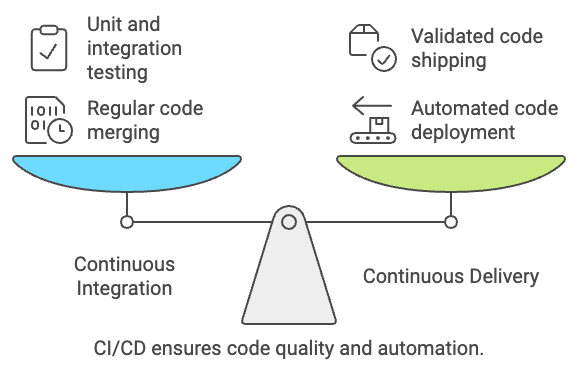
CI/CD significa integración continua, entrega/despliegue continuos. Ahora mismo, puede que eso no signifique mucho para ti; vamos a desglosarlo un poco más.
La integración continua es el proceso de fusionar regularmente los cambios de código en un repositorio central. Por ejemplo, digamos que has realizado con éxito un cambio en una función de Python en la base de código de la canalización de datos de tu equipo de ingeniería. La integración continua dice que este código debe volver al repositorio central.
Pero hay más de lo que parece. Este código debe rastrearse con algún tipo de herramienta de control de versiones (como git) y probarse mediante pruebas unitarias y de integración cada vez que se realice un nuevo cambio. Esto permite dos cosas: en primer lugar, garantizar que los cambios más recientes en la base de código estén disponibles para todos los demás usuarios y, en segundo lugar, validar que el cambio de código funciona realmente como se espera.
Una vez que has fusionado tu código de nuevo en la base de código central y lo has probado, ¿cómo llega a producción? Ahí es donde entra en juego el CD. CD significa entrega/despliegue continuos (nos quedaremos con entrega continua), y es la práctica de desplegar los cambios realizados en el código de forma automatizada.
Algunos podrían argumentar que las pruebas unitarias y de integración forman parte del despliegue continuo, pero independientemente de ello, sólo se enviará a producción el código que haya sido validado.
Creado con Napkin.AI
Así que, juntándolo todo, CI/CD es el proceso integral de asegurarse de que el código funciona (integración continua) antes de enviarlo a producción (entrega continua) de forma automatizada. Para implantar CI/CD, necesitaremos utilizar canalizaciones CI/CD, que veremos más detenidamente a continuación.
Las mejores prácticas de la ingeniería de datos se acercan cada vez más a las pautas establecidas por la ingeniería de software. Tareas como el desarrollo y la ejecución de pruebas unitarias y el mantenimiento de un entorno dedicado de pruebas/QA ya no están aisladas de nuestros amigos ingenieros de software. Esto incluye CI/CD.
No tienes que buscar demasiado para encontrar casos de uso en la pila de ingeniería de datos para CI/CD. He aquí algunos casos de uso común:
Añadir CI/CD a un ciclo de vida de desarrollo de "ingeniería de datos" tiene muchas ventajas, como el control de la calidad del código que se envía a producción y la reducción del esfuerzo manual para publicar estos cambios.
El CI/CD también ofrece una capa de visibilidad de los pasos que se dan en cada lanzamiento y puede limitar el acceso a ciertas acciones a un determinado conjunto de personas.
Para realizar CI/CD, necesitarás utilizar una canalización CI/CD. Una canalización CI/CD es una serie de pasos que se ejecutan para probar (CI) y desplegar (CD) código en producción después de que se haya comprobado en el repositorio central. He aquí un vistazo rápido a lo que podría ser un canal de CI/CD.
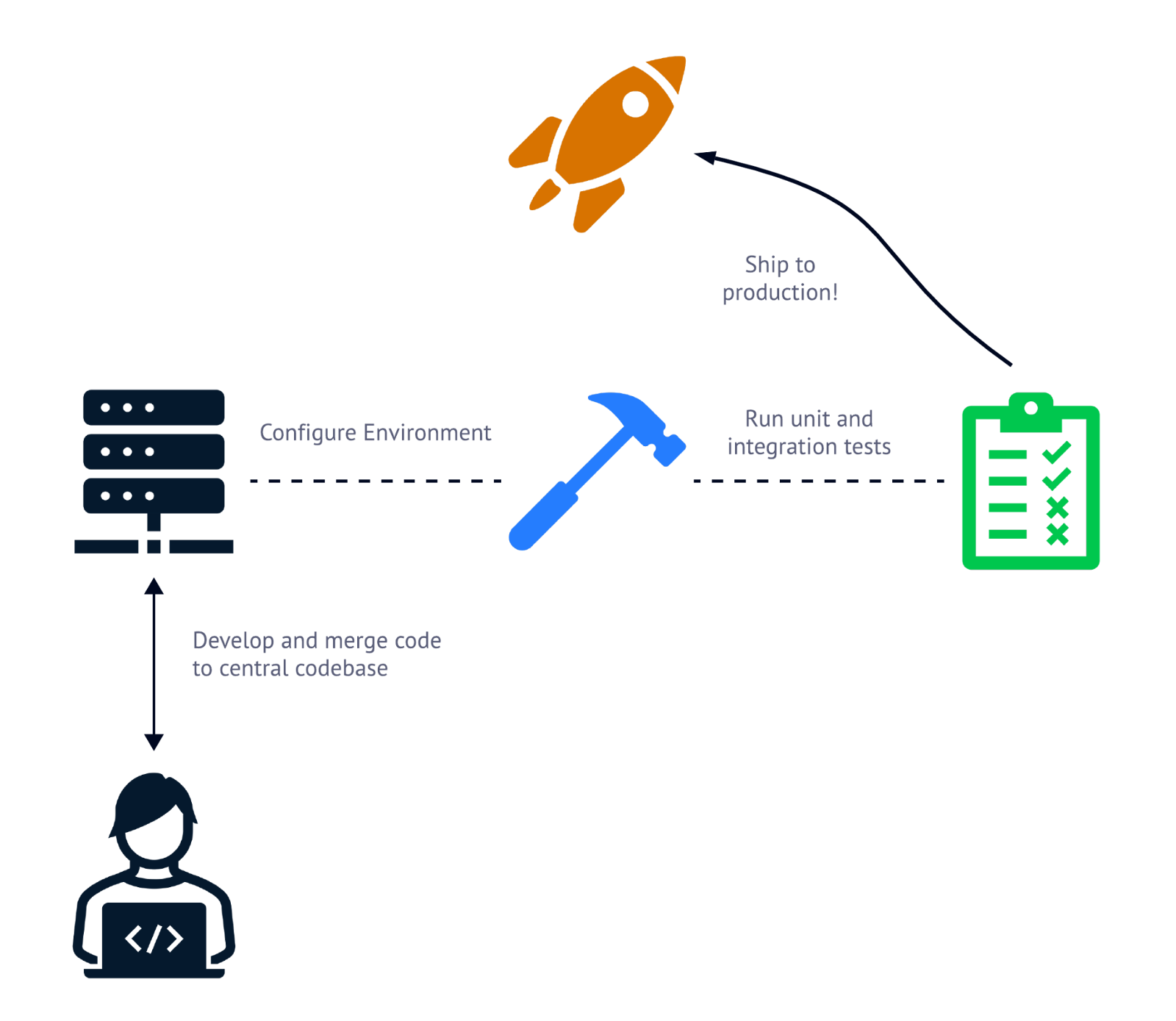
Las canalizaciones CI/CD suelen constar de tres pasos: configurar el entorno de construcción/despliegue, ejecutar las pruebas y enviar el código a producción.
Normalmente, hay tres tipos de operaciones en un canal de CI/CD. En primer lugar, debe configurarse el entorno necesario para probar y desplegar el código en el lugar donde se ejecuta la canalización. Esto puede incluir tareas como la instalación de una CLI, la obtención de secretos y, lo que es más importante, la descarga del código base recién actualizado.
Después de configurar el entorno, hay que probar el código que se va a liberar. Aquí es donde se ejecutan las pruebas unitarias y de integración con el código base recién actualizado. Tras superar cada uno de los casos de prueba, el código actualizado puede desplegarse en producción.
¿Buscas una herramienta para ejecutar tus pipelines CI/CD? Por suerte para ti, ¡hay montones! Desde ofertas de código abierto hasta servicios totalmente gestionados, no faltan opciones con las que orquestar tus procesos de CI/CD. Aquí tienes algunas de las herramientas de CI/CD más populares.
Cuando piensas en el control de versiones, lo más probable es que pienses en GitHub. GitHub es uno de los lugares más populares para almacenar tu código, y por ello, uno de los más atractivos para gestionar tus canalizaciones CI/CD.
Acciones GitHub es una oferta de CI/CD totalmente gestionada que permite a los usuarios de GitHub desarrollar, ejecutar y gestionar sus canalizaciones de CI/CD. Los pipelines se definen mediante archivos YAML que suelen activarse con una acción, como un push a una rama determinada o la fusión de un pull request. Utilizar las acciones de GitHub permite una experiencia unificada para el desarrollador, y un panel de visión central tanto del control de versiones como de la gestión de lanzamientos.
En el otro extremo del espectro está Jenkins. Jenkins es una oferta de CI/CD de código abierto que facilita la creación y el mantenimiento de canalizaciones personalizadas, y a menudo se considera el estándar del sector para CI/CD.
Jenkins cuenta con una capa adicional de extensibilidad, que incluye plugins preconstruidos y soporte para una arquitectura distribuida. Con Jenkins, si puedes soñarlo, lo más probable es que puedas construirlo. Pero esta personalización conlleva responsabilidad, incluido cierto nivel de gestión sobre el propio Jenkins.
A diferencia de las Acciones de GitHub, Jenkins es un programa que debe ser alojado y gestionado por los propios usuarios. Para ello, un equipo de ingeniería de datos necesita configurar y gestionar cosas como el servidor Jenkins, agentes de construcción, acceso de seguridad, integraciones con un cliente de control de versiones y un entorno de ejecución Java. Esto supone unos gastos generales considerables, y puede no tener sentido para las tiendas más pequeñas.
Para los equipos de ingeniería de datos con presencia en la nube, utilizar una solución CI/CD de su proveedor en la nube suele ser bastante atractivo. AWS ofrece herramientas como CodeBuild y CodePipeline. Azure admite DevOps y Pipelines, y GCP proporciona Cloud Build.
Normalmente, las aplicaciones en un entorno de nube existente no necesitan pasar por el proceso de adquisición y no requieren un gasto comprometido. Estas herramientas suelen ser intuitivas para los ingenieros de datos acostumbrados a trabajar en la nube y son fáciles de utilizar.
Al configurar tu propio flujo de trabajo CI/CD, hay algunas prácticas recomendadas que ayudan a que la experiencia sea fluida. En primer lugar, el control de versiones.
Seguimiento de tu código mediante control de versiones es el primer paso para construir una plataforma de datos sólida. Las herramientas de control de versiones (como git) no sólo permiten hacer un seguimiento del código, sino también mantener una versión de producción del mismo. Los clientes de control de versiones (piensa en GitHub) pueden utilizarse para activar un canal CI/CD cuando se produzca un determinado evento.
He aquí un ejemplo de flujo de trabajo; eres un ingeniero de datos encargado de crear un nuevo flujo de trabajo ETL. Para ello, comprueba una rama de características y realiza tus cambios en esa rama. Cuando estés listo para pasar estos cambios a producción, fusionarás tu rama de características con la ramaprincipal de , que activará entonces una canalización CI/CD, desplegando tu código en producción.
No siempre es posible añadir visibilidad a una canalización CI/CD, pero cuando lo es, es importante hacerlo. Dependiendo de la herramienta CI/CD que utilices, puedes dividir cada paso del proceso en una única tarea. Entonces, si una de estas tareas falla, es fácil identificarla y empezar a remediarla. Si utilizas las Acciones de GitHub para ejecutar tus canalizaciones CI/CD, intenta dividir los pasos de configuración del entorno, pruebas y despliegue en tres tareas diferentes.
Tan importante como la visibilidad de la ejecución real del pipeline es la documentación. Añadir notas sobre cómo se activa una canalización, las pruebas que se ejecutan con el código base y el objetivo de despliegue ayuda a poner en marcha el proceso de resolución de problemas.
Lo más probable es que tengas que utilizar algún tipo de contraseña o clave para desplegar tu código base una vez probado. Es importante que nunca almacenes estos datos sensibles en la propia configuración de un canal CI/CD (hacerlo es una forma segura de volver loco a tu equipo de seguridad). En su lugar, aprovecha tus herramientas de CI/CD para almacenar y referenciar estos secretos como variables. Con una herramienta como AWS CodeBuild, los valores sensibles pueden almacenarse fuera de la definición de la canalización mediante variables de entorno, a las que luego se hace referencia de forma segura.
Hasta ahora, sólo hemos hablado de utilizar un canal CI/CD para enviar código a producción. Sin embargo, los procesos de desarrollo de nivel empresarial son algo diferentes. En lugar de pasar directamente a producción cuando se realiza un cambio en el código, los ingenieros de datos suelen pasar el código a un entorno de pruebas específico.
Esto les permite probar su solución manualmente, asegurándose de que produce los resultados que esperan. Para ello, se mantendrán una rama deprueba y una ramaprincipal de mediante el control de versiones, cada una de las cuales activará un trabajo de CI/CD ligeramente distinto cuando se produzca un determinado evento.
Sí, CI/CD puede ser complicado. Y sí, puede llevar algún tiempo configurarlo inicialmente. Pero CI/CD es una inversión para permitir lanzamientos de código gobernados y eficientes a un entorno de producción. Dedicar tiempo por adelantado a desarrollar una canalización CI/CD ayuda a reducir el tiempo dedicado a probar manualmente los cambios de código y a empaquetar el código para enviarlo a producción.
Comprender e implementar CI/CD es una de las formas más rápidas de subir de nivel en tu carrera; si puedes construir un proyecto en Python o SQL, habrás desarrollado habilidades sólidas y fundamentales como ingeniero de datos. Pero, si puedes crear un flujo de trabajo CI/CD con casos de prueba que se ejecuten cada vez que se realicen cambios, y automatizar un empuje de producción, habrás demostrado que estás preparado para crear soluciones de nivel empresarial.
Comienza hoy mismo tu camino para convertirte en ingeniero de datos con el curso de DataCamp Ingeniero de Datos en Python y la certificación certificación de la carrera de Ingeniero de Datos.
Los mejores cursos de DataCamp
programa
programa
Curso
blog
Mike Shakhomirov
11 min
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Oluseye Jeremiah