Track
Data Engineer in Python
40 hr
Getting started in data engineering isn’t easy. In classrooms, and even online courses, you master the the basics of writing Python and SQL. You might even learn a little about frameworks, and tools like Airflow, Databricks, and Snowflake.
It’s one thing to write code that works. It’s another to write tests for this code and ship it into production where it will run in an enterprise setting. Luckily, software engineering has figured this out, and data engineering is starting to catch up.
How do they do this you might ask? CI/CD. How do we know code will run out in the “wild”? How do we know it’s not broken? How do we ship the final code to run in production once it’s been signed off on? In this article, we explore CI/CD in data engineering. We also have a separate guide on CI/CD in machine learning.
CI/CD stands for continuous integration, continuous delivery/deployment. Right now, that might not mean much to you; let’s break it down further.
Continuous integration is the process of regularly merging code changes into a central repository. For example, say you’ve successfully made a change to a Python function in your engineering team’s data pipeline codebase. Continuous integration says that this code should then be brought back into the central repository.
But, there’s more than meets the eye. This code should be tracked with a sort of version control tool (such as git) and tested using unit and integration tests each time a new change is made. This allows for two things; first, to ensure the most recent changes to the code base are available to all other users, and second, to validate that the code change does indeed work as expected.
Once you’ve merged your code back into the central code base and tested it, how does it get to production? That’s where CD comes in. CD stands for continuous delivery/deployment (we’ll stick with continuous delivery), and is the practice of deploying changes made to code in an automated fashion.
Some might argue that unit and integration testing is part of the continuous deployment, but regardless, only code that has been validated will be shipped into production
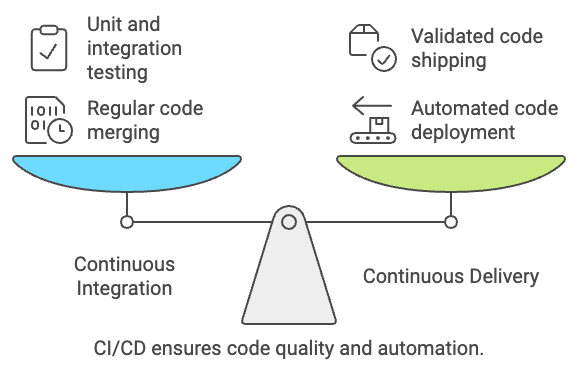
Created using Napkin.AI
So, putting it all together, CI/CD is the end-to-end process of making sure code works (continuous integration) before shipping it to production (continuous delivery) in an automated fashion. To implement CI/CD, we’ll need to use CI/CD pipelines, which we’ll take a closer look at next.
Data engineering best practices are moving closer to the guideposts that have been put in place by software engineering. Tasks such as developing and running unit tests and maintaining a dedicated testing/QA environment are no longer siloed to our software engineering friends. This includes CI/CD.
You don’t have to look too far to find use cases in the data engineering stack for CI/CD. Here are just a few common use cases:
Adding CI/CD to a “data engineering” development lifecycle has plenty of perks, including things like governance over the quality of code being shipped to production, and reduced manual effort to release these changes.
CI/CD also offers a layer of visibility into the steps that go into each release and can limit access to certain actions to a certain set of individuals.
To perform CI/CD, you’ll need to use a CI/CD pipeline. A CI/CD pipeline is a series of steps executed to test (CI) and deploy (CD) code to production after it has been checked back into the central repository. Here’s a quick peek at what a CI/CD pipeline might look like.
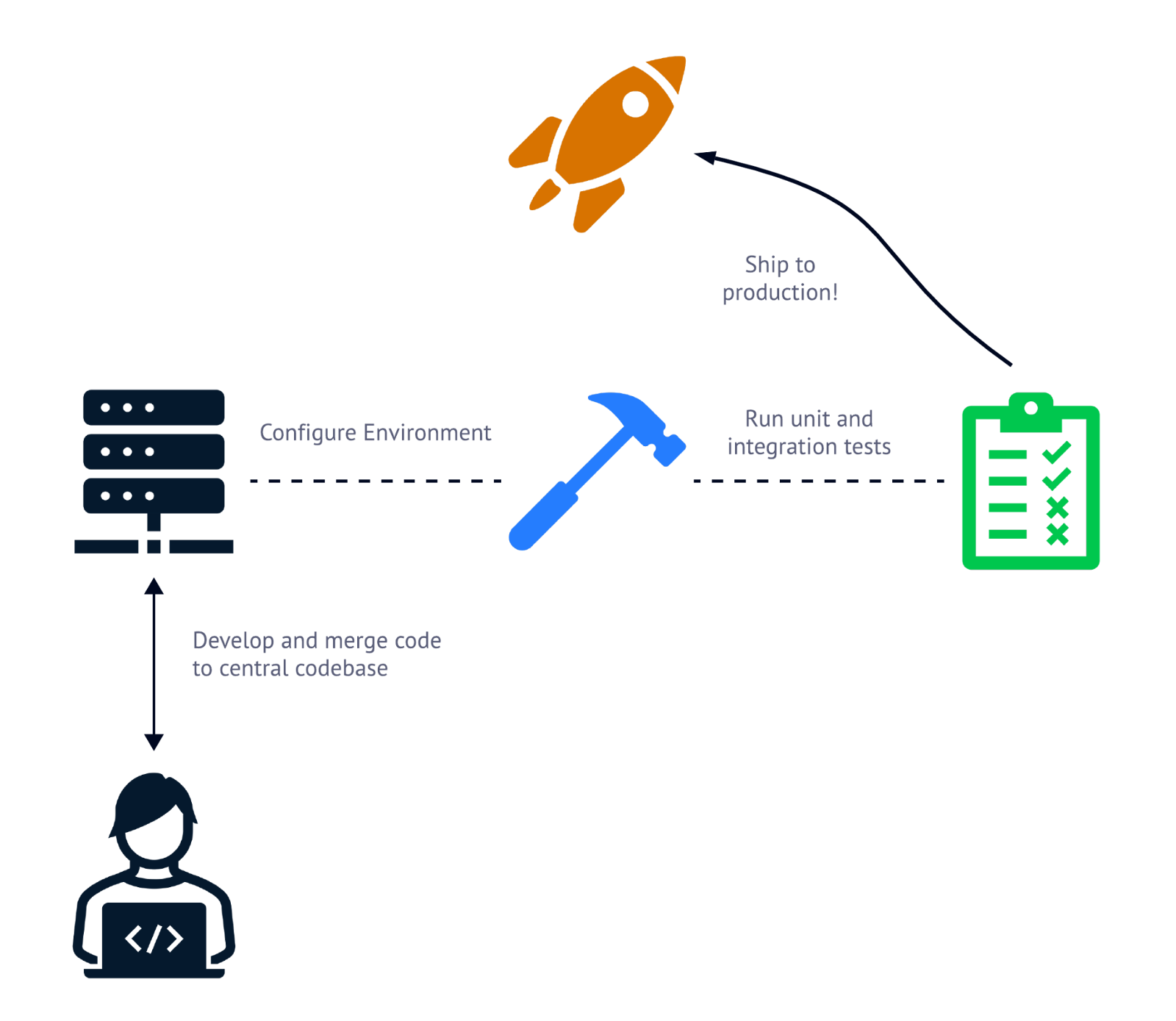
CI/CD pipelines typically are made up of three steps; configuring the building/deployment environment, running tests, and shipping the code to production.
Typically, there are three types of operations in a CI/CD pipeline. First, the environment needed to test and deploy the code must be configured where the pipeline is being run. This may include tasks such as installing a CLI, fetching secrets, and most importantly, pulling down the newly updated codebase.
After setting up the environment, the code being released must be tested. This is where unit and integration tests are run against the newly updated code base. After passing each of the test cases, the updated code can be deployed into production.
Looking for a tool to run your CI/CD pipelines? Lucky for you, there are tons! From open-source offerings to full-managed services there’s no shortage of options with which to orchestrate your CI/CD processes. Here are just a few of the most popular CI/CD tools out there.
When you think of version control, chances are, you may think of GitHub. GitHub is one of the most popular places to store your code, and for that reason, one the most attractive for which to manage your CI/CD pipelines.
GitHub actions is a fully managed CI/CD offering that allows GitHub users to develop, run, and manage their CI/CD pipelines. Pipelines are defined using YAML files typically triggered on an action such as a push to a certain branch or a pull request being merged. Using GitHub actions allows for a unified developer experience, and a central pane-of-glass into both version control and release management.
On the other end of the spectrum is Jenkins. Jenkins is an open-source, CI/CD offering that makes it easy to build and maintain custom pipelines and is often regarded as the industry standard for CI/CD.
Jenkins boasts an additional layer of extensibility, including prebuilt plugins and support for a distributed architecture. With Jenkins, if you can dream it up, chances are you can build it. But, with this customizability comes responsibility, including a certain level of management over Jenkins itself.
Different than GitHub Actions, Jenkins is a program that needs to be hosted and managed by the users themselves. To do this, a data engineering team needs to configure and manage things like Jenkins server, build agents, security access, integrations with a version control client, and a Java runtime environment. This means signification overhead, and may not make sense for smaller shops.
For data engineering teams with a cloud presence, using a CI/CD solution from their cloud provider is often quite appealing. AWS offers tools such as CodeBuild and CodePipeline. Azure supports DevOps and Pipelines, and GCP provides Cloud Build.
Typically, applications in an existing cloud environment do not need to go through procurement and don’t require committed spend. These tools are often intuitive to data engineers who are used to working in the cloud and are easy to get started with.
When configuring your own CI/CD workflow, there are a few best practices that help to make the experience seamless. First up, version control.
Tracking your code using version control is the first step to building a robust data platform. Version control tools (such as git) not only allow for code to be tracked but a production version of the code to be maintained. Version control clients (think GitHub) can then be used to trigger a CI/CD pipeline when a certain event occurs.
Here’s a sample workflow; you’re a data engineer tasked with creating a new ETL workflow. To do this, you check out a feature branch and make your changes on that branch. When you’re ready to push these changes into production, you’ll merge your feature branch to the main branch, which will then trigger a CI/CD pipeline, deploying your code to production.
It’s not always possible to add visibility to a CI/CD pipeline, but when it is, it’s important to do so. Depending on the CI/CD tool that you’re using, you can break out each step in the pipeline into a single task. Then, if one of these tasks fail, it’s easy to identify and begin remediation. If you’re using GitHub Actions to run your CI/CD pipelines, try breaking up your environment configuration, tests, and deployment steps into three different tasks.
Just as important as visibility into the actual execution of the pipeline is documentation. Adding notes around how a pipeline is triggered, the tests being run against the codebase, and the deployment target helps to jumpstart the troubleshooting process
Chances are, you’re going to need to use some sort of password or key to deploy your codebase once it has been tested. It’s important to never store these sensitive in a CI/CD pipeline configuration itself (doing so is one surefire way to drive your security team crazy). Instead, take advantage of your CI/CD tooling to store and reference these secrets as variables. With a tool like AWS CodeBuild, sensitive values can be stored outside the pipeline definition using environment variables, which are then safely referenced.
So far, we’ve only discussed using a CI/CD pipeline to push code to production. However, enterprise-grade development processes look a little different. Rather than pushing straight to production when a code change is made, data engineers will typically push code to a dedicated testing environment.
This allows them to test their solution manually, making sure it produces the results they expect. To do this, both a test and main branch will be maintained using version control, each triggering a slightly different CI/CD job when a certain event occurs.
Yes, CI/CD can be tricky. And yes, it may take some time to initially configure. But CI/CD is an investment in enabling governed and efficient releases of code to a production environment. Spending the time upfront to develop a CI/CD pipeline helps reduce the time manually spent testing code changes and packing code to ship to production.
Understanding and implementing CI/CD is one of the quickest ways to level up your career; if you can build a project in Python or SQL, you’ve developed solid, fundamental skills as a data engineer. But, if you can build a CI/CD workflow with test cases that execute each time changes are made, and automate a production push, you’ve shown you’re ready to build enterprise-grade solutions.
Get started on your path to becoming a data engineer today with DataCamp’s Data Engineer in Python career track and Data Engineer Career certification.
Top DataCamp Courses
Track
Track
Course
blog
Abid Ali Awan
10 min
blog
Çağlar Uslu
8 min
blog
Alena Guzharina
3 min
blog
Srujana Maddula
9 min
Tutorial
Amberle McKee
Tutorial
Abid Ali Awan