
Ciência de dados: Definição e aplicações práticas
A ciência de dados é um campo de estudo relativamente recente, mas de rápido crescimento e multifacetado, usado em muitas esferas. Ele usa várias técnicas analíticas avançadas e algoritmos de modelagem preditiva para extrair insights significativos dos dados e ajudar a responder a perguntas estratégicas de negócios ou científicas. A ciência de dados combina uma ampla gama de habilidades, desde técnicas (programação, álgebra linear, estatística e modelagem) até não técnicas (representação e comunicação eficientes dos resultados). Além disso, dependendo do setor em que a ciência de dados é aplicada, é necessário ter um sólido conhecimento do domínio para poder interpretar corretamente as informações disponíveis e os insights obtidos.
Os algoritmos da ciência de dados podem ser aplicados com sucesso a diversos cenários em que muitos dados são ou podem ser coletados: finanças, comércio, marketing, gerenciamento de projetos, seguros, medicina, educação, manufatura, RH, linguística, sociologia etc. Na prática, qualquer setor ou ciência pode se beneficiar significativamente com a coleta, a análise e a modelagem de seus dados.
O que é um caso de uso de ciência de dados?
Um caso de uso de ciência de dados é uma tarefa concreta do mundo real a ser resolvida usando os dados disponíveis. Na estrutura de uma determinada empresa, muitas variáveis são analisadas usando técnicas de ciência de dados no contexto do setor específico da empresa. Os casos de uso da ciência de dados podem ser um problema a ser resolvido, uma hipótese a ser verificada ou uma pergunta a ser respondida. Essencialmente, fazer ciência de dados significa resolver casos de uso do mundo real.
Embora o conteúdo de cada caso de uso provavelmente seja muito diferente, há alguns aspectos comuns que devem ser sempre lembrados:
- O planejamento de casos de uso de ciência de dados consiste em: delinear uma meta clara e os resultados esperados, compreender o escopo do trabalho, avaliar os recursos disponíveis, fornecer os dados necessários, avaliar os riscos e definir o KPI como uma medida de sucesso.
- As abordagens mais comuns para resolver casos de uso de ciência de dados são: previsão, classificação, detecção de padrões e anomalias, recomendações e reconhecimento de imagens.
- Alguns casos de uso da ciência de dados representam tarefas típicas de diferentes campos e você pode contar com abordagens semelhantes para resolvê-los, como previsão da taxa de rotatividade de clientes, segmentação de clientes, detecção de fraudes, sistemas de recomendação e otimização de preços.
Como faço para resolver um estudo de caso de ciência de dados?
A resposta a essa pergunta é muito específica para cada caso, orientada pela estratégia de negócios da empresa e dependendo do núcleo do próprio estudo de caso. No entanto, pode ser útil delinear um roteiro geral a ser seguido em qualquer caso de uso de ciência de dados:
- Formular a pergunta certa. Essa primeira etapa é muito importante e inclui a revisão da literatura disponível e dos estudos de caso existentes, a revisão das práticas recomendadas, a elaboração de teorias relevantes e hipóteses de trabalho e o preenchimento de possíveis lacunas no conhecimento do domínio. Como resultado, devemos elaborar uma pergunta clara a ser respondida no estudo de caso de interesse.
- Coleta de dados. Nessa etapa, realizamos um inventário de dados e um processo de coleta. Na vida real, muitas vezes temos dados não representativos, incompletos, com falhas e não estruturados, ou seja, longe de ser uma tabela completa de informações que seja fácil de ler e pronta para ser analisada. Portanto, temos que pesquisar e identificar todas as fontes de dados possíveis que possam ser úteis para o nosso tópico. Os dados necessários podem ser encontrados nos arquivos da empresa, extraídos da Web ou adquiridos de um patrocinador, etc.
- Organização de dados. Geralmente, essa é a parte que consome mais tempo e recursos de qualquer projeto de ciência de dados. A qualidade e a representatividade dos dados coletados são estimadas e a exploração inicial dos dados é realizada. Os dados são limpos, pré-processados, transformados, manipulados e mapeados de sua forma bruta para um formato mais adequado.
- Análise e modelagem de dados. Os dados limpos são analisados do ponto de vista de seu status atual e, em seguida, encaixados em um modelo estatístico preditivo selecionado. A precisão do modelo é avaliada e, se não for satisfatória, outras abordagens de modelagem são testadas. Isso é repetido até que se obtenha o modelo que prevê cenários futuros com a maior precisão. Portanto, esse processo, como todos os anteriores, pode ser bastante iterativo.
- Comunicação de resultados. Em comparação com as etapas anteriores, esta exige mais comunicação e habilidades interpessoais do que conhecimentos técnicos e de programação. Isso inclui compartilhar as descobertas mais importantes e as conclusões finais com a gerência, os acionistas e quaisquer outras partes envolvidas. Os insights são geralmente representados na forma de relatórios, artigos e slides de apresentação, delineando possíveis caminhos a seguir.
Casos de uso de ciência de dados por setor
Os casos de uso da ciência de dados podem ser relacionados a praticamente qualquer setor em que uma grande quantidade de dados é ou pode ser acumulada. Neste capítulo, discutiremos alguns casos de uso típicos de ciência de dados dos seguintes campos mais procurados: logística, saúde e telecomunicações. Alguns dos casos de uso que vamos considerar são interdisciplinares e podem ser facilmente encontrados em muitas outras esferas. Isso os torna mais universais e aplicáveis, portanto, vale a pena conhecer uma abordagem geral para resolvê-los. Além disso, para cada um dos setores selecionados, descreveremos alguns outros tópicos possíveis que podem ser modelados com métodos de ciência de dados.
Ciência de dados no setor de saúde
Nos três capítulos anteriores, discutimos como os métodos de ciência de dados podem ajudar empresas de diferentes setores a aumentar sua receita. Quando se trata de saúde, o uso e a interpretação corretos dos dados disponíveis podem ser benéficos não apenas para os profissionais de marketing desse setor, mas também podem ajudar no diagnóstico oportuno de doenças graves e até mesmo salvar a vida das pessoas.
A medicina e os prestadores de serviços de saúde reúnem uma enorme quantidade de dados de várias fontes: sistemas de registro eletrônico de saúde (EHR), dados de dispositivos vestíveis, estudos de pesquisa médica e documentos de faturamento. O aproveitamento de técnicas inovadoras de ciência e análise de dados está revolucionando gradualmente todo o setor de saúde, oferecendo as soluções mais promissoras e impactantes para seu desenvolvimento futuro. Em particular, alguns campos altamente especializados da área da saúde, como genética, medicina reprodutiva, oncologia, biotecnologia, radiografia, diagnósticos preditivos e produtos farmacêuticos, passaram para um nível completamente novo graças ao desbloqueio de todo o potencial de seus dados.
Para entender melhor como a ciência de dados pode ser útil na medicina, vamos nos concentrar em um dos casos de uso mais clássicos.
Caso de uso da ciência de dados no setor de saúde: Previsão de câncer de mama
De acordo com o World Cancer Research Fund International, o câncer de mama é o tipo de câncer mais comum entre as mulheres e o segundo mais comum em geral. Diagnosticar uma patologia da mama a tempo, seja ela benigna ou maligna, é extremamente importante, pois aumenta significativamente as chances de sucesso do tratamento e a taxa de sobrevivência. É nesse ponto que a ciência de dados pode ajudar.
O progresso dos métodos de mineração de dados em combinação com algoritmos de aprendizado de máquina tornou possível prever o risco de câncer de mama, detectar qualquer anomalia em potencial nos estágios iniciais, estimar sua dinâmica e, portanto, desenvolver um plano ideal para combater a doença. Essencialmente, é um problema típico de classificação do aprendizado de máquina. A boa notícia é que, como esse tipo de oncologia é bastante comum em todos os lugares, muitas investigações completas foram realizadas em todo o mundo e, como resultado, toneladas de dados foram acumuladas de pacientes de todo o mundo.
O principal problema com o uso desses conjuntos de dados em classificadores é que eles podem ser muito desequilibrados. Por exemplo, no caso em que o resultado é representado em uma forma de câncer / sem câncer, a probabilidade de ter uma patologia (as entradas do conjunto de dados que pertencem à classe minoritária) é consideravelmente menor do que a probabilidade de não ter nenhuma patologia (as entradas que pertencem à classe majoritária). Como resultado, o algoritmo tende a classificar novos casos como não patológicos. Portanto, para avaliar a precisão desses modelos com mais eficiência, faz sentido aplicar a pontuação F1 como métrica de avaliação, pois ela estima os falsos positivos (erro do tipo I) e os falsos negativos (erro do tipo II) em vez dos casos em que o algoritmo classificou as entradas corretamente.
Vamos dar uma olhada em um conjunto de dados do mundo real sobre câncer de mama de um dos estados dos EUA. Os recursos são descritos em detalhes na documentação, mas, em resumo, são a média, o erro padrão e os maiores valores dos atributos de cada imagem digitalizada que exibe os núcleos celulares da massa mamária de uma mulher. Cada entrada do conjunto de dados corresponde a uma mulher com um tumor maligno ou benigno (ou seja, todas as mulheres em questão têm algum tipo de tumor). Os atributos incluem o raio da célula, a textura, a suavidade, a compactação, a concavidade, a simetria, etc.
import pandas as pd
cancer_data = pd.read_csv('data.csv')
pd.options.display.max_columns = len(cancer_data)
print(f'Number of entries: {cancer_data.shape[0]:,}\n'
f'Number of features: {cancer_data.shape[1]:,}\n\n'
f'Number of missing values: {cancer_data.isnull().sum().sum()}\n\n'
f'{cancer_data.head(2)}')Number of entries: 569
Number of features: 33
Number of missing values: 569
id diagnosis radius_mean texture_mean perimeter_mean area_mean \
0 842302 M 17.99 10.38 122.8 1001.0
1 842517 M 20.57 17.77 132.9 1326.0
smoothness_mean compactness_mean concavity_mean concave points_mean \
0 0.11840 0.27760 0.3001 0.14710
1 0.08474 0.07864 0.0869 0.07017
symmetry_mean fractal_dimension_mean radius_se texture_se perimeter_se \
0 0.2419 0.07871 1.0950 0.9053 8.589
1 0.1812 0.05667 0.5435 0.7339 3.398
area_se smoothness_se compactness_se concavity_se concave points_se \
0 153.40 0.006399 0.04904 0.05373 0.01587
1 74.08 0.005225 0.01308 0.01860 0.01340
symmetry_se fractal_dimension_se radius_worst texture_worst \
0 0.03003 0.006193 25.38 17.33
1 0.01389 0.003532 24.99 23.41
perimeter_worst area_worst smoothness_worst compactness_worst \
0 184.6 2019.0 0.1622 0.6656
1 158.8 1956.0 0.1238 0.1866
concavity_worst concave points_worst symmetry_worst \
0 0.7119 0.2654 0.4601
1 0.2416 0.1860 0.2750
fractal_dimension_worst Unnamed: 32
0 0.11890 NaN
1 0.08902 NaN Vamos eliminar a última coluna que contém apenas valores ausentes:
cancer_data = cancer_data.drop('Unnamed: 32', axis=1)Quantas mulheres, em %, têm um câncer confirmado (um tumor maligno na mama)?
round(cancer_data['diagnosis'].value_counts()*100/len(cancer_data)).convert_dtypes()B 63
M 37
Name: diagnosis, dtype: Int6437% de todos os entrevistados têm câncer de mama, portanto, o conjunto de dados é, na verdade, bastante equilibrado.
Como os valores da variável de diagnóstico são categóricos, temos que codificá-los em formato numérico para uso posterior no aprendizado de máquina. Antes de fazer isso, vamos dividir os dados em recursos de previsão e diagnóstico da variável de destino:
X = cancer_data.iloc[:, 2:32].values
y = cancer_data.iloc[:, 1].values
# Encoding categorical data
from sklearn.preprocessing import LabelEncoder
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)Agora, vamos criar os conjuntos de treinamento e teste e, em seguida, dimensionar os recursos:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Para modelar nossos dados, vamos aplicar os seguintes algoritmos de modelagem com seus parâmetros padrão: k-nearest neighbors (KNN) e regressão logística:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
# KNN
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
knn_predictions = knn.predict(X_test)
# Logistic regression
lr = LogisticRegression()
lr.fit(X_train, y_train)
lr_predictions = lr.predict(X_test)Vimos anteriormente que nosso conjunto de dados é bastante equilibrado, portanto, podemos usar a métrica de avaliação da pontuação de precisão para identificar o modelo mais preciso:
from sklearn.metrics import accuracy_score
print(f'Accuracy scores:\n'
f'KNN model:\t\t {accuracy_score(y_test, knn_predictions):.3f}\n'
f'Logistic regression model: {accuracy_score(y_test, lr_predictions):.3f}')Accuracy scores:
KNN model: 0.956
Logistic regression model: 0.974Com base em nossos dados, o modelo de regressão logística tem o melhor desempenho na previsão de um tumor de mama maligno/benigno para uma mulher com uma patologia mamária detectada de qualquer natureza.
Como possíveis caminhos a seguir, considerando que o algoritmo de regressão logística não tem nenhum parâmetro crítico a ser ajustado, podemos brincar com diferentes abordagens para treinar/testar a divisão e/ou várias técnicas de modelagem preditiva.
Outros casos de uso comuns de ciência de dados no setor de saúde:
- monitoramento de dados em tempo real de wearables
- análise preditiva
- análise de imagens médicas
- descoberta de medicamentos
- pesquisa genética
- assistentes virtuais
- gerenciamento de dados do cliente
Ciência de dados em transporte e logística
A logística é a organização do processo de entrega de produtos de um ponto a outro, enquanto o transporte implica o ato de transportar clientes ou mercadorias. Dependendo do perfil da atividade da empresa (por exemplo, entrega de almoço, serviço de correio, remessa internacional, companhias aéreas e serviços de táxi ou ônibus), as fontes de dados podem ser representadas por cronogramas, planilhas de horas, detalhes de rotas, itemização do estoque do depósito, relatórios, contratos, acordos, documentos legais e feedback do cliente. Os dados em si podem ser estruturados ou não e incluir informações sobre horários, itinerários, rotas, coordenadas, dados de clientes, detalhes de mercadorias, custos e preços.
A eficiência dos negócios na cadeia de suprimentos e nos setores de transporte nem sempre é simples e depende de vários fatores: problemas de tráfego imprevistos, qualidade das rotas, condições climáticas, emergências, flutuações no preço do combustível, escassez de estoque em armazéns, danos técnicos, atrasos em remessas relacionadas à segurança, regulamentações e sanções governamentais e muitos outros. Além disso, nos últimos anos, muitas empresas novas surgiram no mercado, e a concorrência nesse setor se tornou bastante acirrada. Portanto, para acompanhar os concorrentes e aumentar a produtividade operacional, tornou-se imprescindível que cada empresa de logística/transporte analise o big data e o transforme em insights significativos.
Como exatamente a ciência de dados pode ser útil para os setores de transporte e logística? Aqui está uma lista incompleta de suas possíveis aplicações:
- rastrear todo o processo de transporte de ponta a ponta,
- tornando todas as atividades totalmente automatizadas e transparentes,
- entrega no prazo,
- otimização de rotas,
- preços dinâmicos,
- manter o estoque de suprimentos,
- proteger produtos perecíveis,
- monitoramento das condições dos veículos,
- melhorar as redes de produção,
- melhorar o atendimento ao cliente.
Caso de uso de ciência de dados em transporte e logística: Identificação do posicionamento ideal dos veículos de táxi
A Uber Technologies Inc., ou Uber, é uma empresa americana que fornece vários serviços de logística e transporte. Neste estudo de caso, vamos agrupar dados de GPS de compartilhamento de carona da Uber para identificar o posicionamento ideal dos veículos de táxi. Em particular, ele pode ser útil para as seguintes finalidades:
- Cada nova solicitação de viagem é atribuída ao cluster mais próximo, de modo que a Uber envia o carro mais próximo desse cluster para o local do cliente.
- Analisando os clusters identificados do ponto de vista de sua carga de trabalho, opcionalmente por hora ou dia da semana, a Uber pode redistribuir os carros com antecedência e enviá-los para os locais mais estratégicos e com maior demanda entre os clientes.
- Dependendo da relação demanda/oferta em diferentes clusters, a empresa pode ajustar dinamicamente as tarifas de preço.
Vamos usar um conjunto de dados do FiveThirtyEight sobre viagens de Uber em Nova York em abril de 2014:
import pandas as pd
uber_data = pd.read_csv('uber-raw-data-apr14.csv')
print(f'Number of trips: {uber_data.shape[0]:,}\n\n'
f'{uber_data.head()}')Number of trips: 564,516
Date/Time Lat Lon Base
0 4/1/2014 0:11:00 40.7690 -73.9549 B02512
1 4/1/2014 0:17:00 40.7267 -74.0345 B02512
2 4/1/2014 0:21:00 40.7316 -73.9873 B02512
3 4/1/2014 0:28:00 40.7588 -73.9776 B02512
4 4/1/2014 0:33:00 40.7594 -73.9722 B02512Vamos visualizar esquematicamente todos os pontos de coleta, levando em conta que a longitude corresponde ao eixo x e a latitude ao eixo y:
import matplotlib.pyplot as plt
plt.scatter(uber_data.iloc[:, 2], uber_data.iloc[:, 1])
plt.show()
Para agrupar esses dados, vamos usar um algoritmo não supervisionado de aprendizado de máquina chamado k-means clustering. A ideia por trás dessa abordagem é dividir todas as amostras de dados em vários grupos de variância igual. Essencialmente, ele recebe o número de clusters n_clusters (8 por padrão) e separa os dados de acordo. Para descobrir o número ideal de clusters, é usado um método de cotovelo gráfico. Ele inclui as seguintes etapas:
- Treinar vários modelos com um número diferente de clusters e coletar os valores de WCSS (Within Cluster Sum of Squares) para cada um, ou seja, a soma das distâncias quadradas das observações em relação ao centroide do cluster mais próximo.
- Plotagem dos valores de WCSS em relação aos valores correspondentes do número de clusters.
- Selecionando o menor número de clusters em que ocorre uma redução significativa do WCSS.
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, random_state=1)
kmeans.fit(uber_data[['Lat', 'Lon']])
wcss.append(kmeans.inertia_)
plt.figure(figsize=(12, 5))
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method', fontsize=25)
plt.xlabel('Number of clusters', fontsize=18)
plt.ylabel('WCSS', fontsize=18)
plt.xticks(ticks=list(range(1, 11)),
labels=['1', '2', '3', '4', '5', '6', '7', '8', '9', '10'])
plt.show()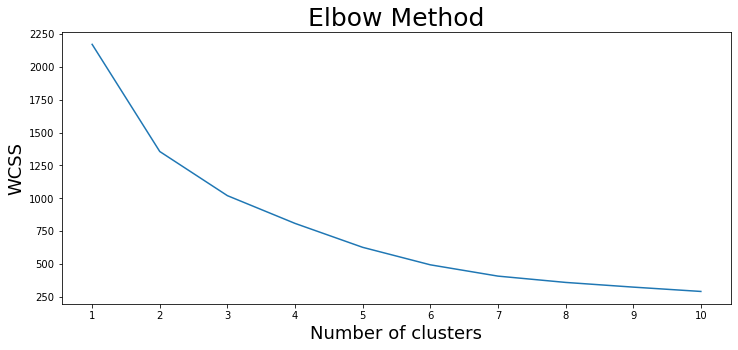
Em nosso caso, o número mais adequado de clusters parece ser 7. Vamos usar esse valor para ajustar um modelo e prever o número do cluster para cada ponto de coleta. Além disso, ilustraremos as entradas de dados graficamente mais uma vez, desta vez adicionando os locais dos sete centroides de cluster:
kmeans = KMeans(n_clusters=7, random_state=1)
kmeans.fit_predict(df[['Lat', 'Lon']])
plt.scatter(uber_data.iloc[:, 2], uber_data.iloc[:, 1])
plt.scatter(kmeans.cluster_centers_[:, 1], kmeans.cluster_centers_[:, 0], s=100, c='lime')
plt.show()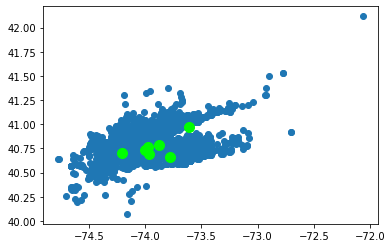
Agora, extrairemos as coordenadas exatas de todos os centroides e as exibiremos separadamente, sem os dados em si:
centroids = pd.DataFrame(kmeans.cluster_centers_)
centroids.columns = ['Lat', 'Lon']
print(centroids)
plt.scatter(centroids['Lon'], centroids['Lat'])
plt.show() Lat Lon
0 40.688588 -73.965694
1 40.765423 -73.973165
2 40.788001 -73.879858
3 40.656997 -73.780035
4 40.731074 -73.998644
5 40.700541 -74.201673
6 40.971229 -73.611288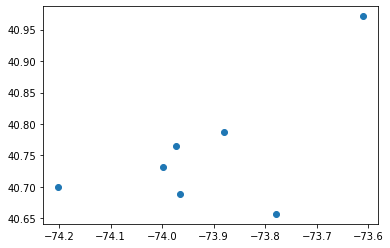
Seria mais ilustrativo mostrar esses centroides em um mapa da cidade de Nova York:
import folium
centroids_values = centroids.values.tolist()
nyc_map = folium.Map(location=[40.79659011772687, -73.87341741832425], zoom_start=50000)
for point in range(0, len(centroids_values)):
folium.Marker(centroids_values[point], popup=centroids_values[point]).add_to(nyc_map)
nyc_map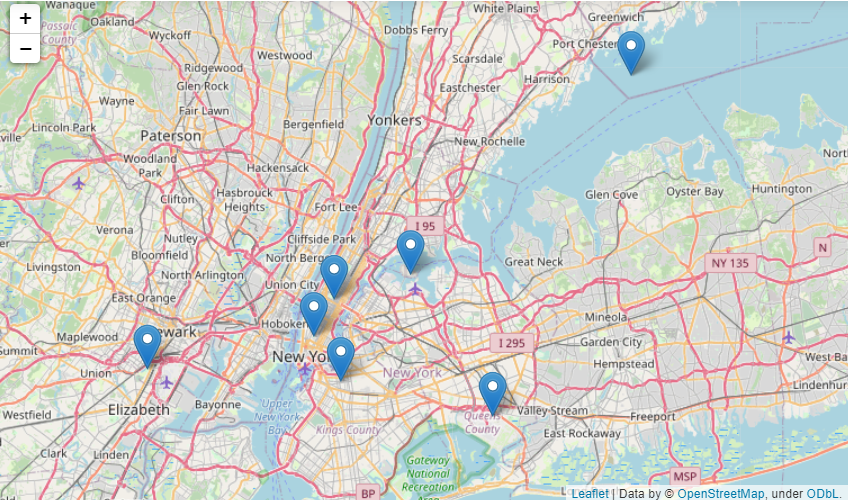
Usando nosso modelo, podemos prever o cluster mais próximo para qualquer local em Nova York expresso em coordenadas geográficas. Em termos práticos, isso significa que a Uber enviará um táxi disponível do local mais próximo e atenderá o cliente mais rapidamente.
Vamos encontrar o cluster mais próximo do Lincoln Center for the Performing Arts no bairro de Manhattan:
lincoln_center = [(40.7725, -73.9835)]
kmeans.predict(lincoln_center)array([1])E para Howard Beach, no bairro do Queens:
howard_beach = [(40.6571, -73.8430)]
kmeans.predict(howard_beach)array([3])Como possíveis caminhos a seguir, podemos considerar a aplicação de outros algoritmos de agrupamento de aprendizado de máquina, analisando diferentes fatias de dados (por hora/dia da semana/mês), encontrando os clusters mais e menos carregados ou descobrindo as relações entre os clusters identificados e a variável Base do quadro de dados.
Outros casos de uso comuns de ciência de dados em transporte e logística:
- correspondência dinâmica de preços entre oferta e demanda
- previsão de demanda
- automação de operações manuais
- veículos autônomos
- visibilidade da cadeia de suprimentos
- detecção de danos
- gerenciamento de armazém
- análise do sentimento do cliente
- chatbots de atendimento ao cliente
Ciência de dados em telecomunicações
Nas últimas duas décadas, as tecnologias de telecomunicações cresceram em um ritmo incrivelmente rápido e entraram em um novo estágio de desenvolvimento. Hoje em dia, estamos cercados por dispositivos eletrônicos de todos os tipos, e muitas pessoas se tornaram literalmente dependentes da Internet, principalmente de redes sociais e mensageiros. Às vezes, esse vício em dispositivos é criticado por substituir a comunicação real face a face. No entanto, temos que admitir que as telecomunicações facilitaram muito nossas vidas, permitindo que nos conectemos com pessoas de todo o mundo em questão de segundos.
Isso se tornou especialmente verdadeiro no período da pandemia da COVID-19, quando muitas empresas e escolas adotaram esquemas de trabalho ou aprendizado remotos. Em uma realidade que muda tão rapidamente, a qualidade e a fluidez da conectividade digital assumiram uma importância sem precedentes em todas as esferas. Os períodos de bloqueio tornaram necessário que as pessoas ligassem e enviassem mensagens de texto para seus colegas, parentes e amigos com muito mais frequência do que antes. Todas essas novas tendências levaram a um imenso aumento nos volumes de telecomunicações, o que, por sua vez, resultou na geração de grandes quantidades de dados nesse setor.
O uso de métodos de ciência de dados para trabalhar com os dados acumulados pode ajudar o setor de telecomunicações de várias maneiras:
- simplificar as operações,
- otimizando a rede,
- filtragem de spam,
- melhorando as transmissões de dados,
- realizar análises em tempo real,
- desenvolver estratégias de negócios eficientes,
- criar campanhas de marketing bem-sucedidas,
- aumentar a receita.
Vamos explorar em mais detalhes uma tarefa comum de ciência de dados em telecomunicações, relacionada à detecção e à filtragem de mensagens indesejadas.
Caso de uso de ciência de dados em telecomunicações: Criação de um filtro de spam
A filtragem de spam é uma função vital de todos os canais modernos de comunicação escrita, pois nos protege de sermos bombardeados com e-mails diários que tentam nos enganar e tirar nosso dinheiro. Tecnicamente, é outro exemplo de um problema de classificação: com base nos dados históricos, cada nova mensagem de entrada é rotulada como ham (ou seja, uma mensagem normal) e, em seguida, chega diretamente ao destinatário, ou como spam e, em seguida, é bloqueada ou chega à pasta de spam.
Um algoritmo popular de aprendizado de máquina supervisionado para essa finalidade é o classificador Naive Bayes. Ele se baseia no teorema homônimo da teoria da probabilidade, enquanto "ingênuo" significa a suposição subjacente de que todas as palavras em cada mensagem são mutuamente independentes. Essa suposição não é exatamente correta, pois ignora a existência inevitável de contextos e incorporações naturais de palavras. Entretanto, na maioria das tarefas de classificação de textos com poucos dados, essa abordagem parece funcionar bem e fazer previsões precisas.
Há várias versões do classificador Naive Bayes, cada uma com seus próprios casos de aplicabilidade: multinomial, Bernoulli, Gaussiano e Bayes flexível. O melhor tipo para o nosso caso (detecção de spam) é o classificador multinomial Naive Bayes. Ele se baseia em contagens de frequência discreta dos recursos categóricos ou contínuos que representam a contagem de palavras em cada mensagem.
Vamos aplicar a filtragem de spam multinomial Naive Bayes ao conjunto de dados de coleta de spam de SMS do UCI Machine Learning Repository.
import pandas as pd
sms_data = pd.read_csv('SMSSpamCollection', sep='\t', header=None, names=['Label', 'SMS'])
print(f'Number of messages: {sms_data.shape[0]:,}\n\n'
f'{sms_data.head()}')Number of messages: 5,572
Label SMS
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives aro...Há 5.572 mensagens classificadas por humanos. Quantos deles (em porcentagem) são spam?
round(sms_data['Label'].value_counts()*100/len(sms_data)).convert_dtypes()ham 87
spam 13
Name: Label, dtype: Int6413% dos SMS foram identificados manualmente como spam.
Para preparar os dados para a classificação multinomial Naive Bayes, primeiro precisamos concluir as etapas a seguir:
- Codificar rótulos de string para formato numérico. Em nosso caso, os rótulos são binários, portanto, os codificaremos como 0/1.
- Extraia as variáveis preditoras e alvo.
- Dividir os dados em conjuntos de treinamento e teste
- Vetorize as cadeias de caracteres da coluna SMS dos conjuntos de treinamento e teste do preditor para obter matrizes CSR (linha esparsa comprimida).
A quarta etapa precisa de uma explicação mais detalhada. Aqui, criamos um objeto de matriz, ajustamos a ele o dicionário de vocabulário (todas as palavras exclusivas de todas as mensagens do conjunto de treinamento do preditor com suas frequências correspondentes) e, em seguida, transformamos os conjuntos de treinamento e teste do preditor em matrizes. O resultado serão duas matrizes para os conjuntos de treinamento e teste do preditor, em que as colunas correspondem a cada palavra exclusiva de todas as mensagens do conjunto de treinamento do preditor, as linhas às próprias mensagens correspondentes e os valores nas células à contagem de frequência de palavras para cada mensagem.
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
# Encoding labels
sms_data = sms_data.replace('ham', 0).replace('spam', 1)
X = sms_data['SMS'].values
y = sms_data['Label'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Vectorizing strings from the 'SMS' column
cv = CountVectorizer(max_df=0.95)
cv.fit(X_train)
X_train_csr_matrix = cv.transform(X_train)
X_test_csr_matrix = cv.transform(X_test)Em seguida, criaremos um classificador Naive Bayes multinomial com os parâmetros padrão e verificaremos sua precisão:
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, f1_score
clf = MultinomialNB()
clf.fit(X_train_csr_matrix, y_train)
predictions = clf.predict(X_test_csr_matrix)
print(f'Model accuracy:\n'
f'Accuracy score: {accuracy_score(y_test, predictions):.3f}\n'
f'F1-score: {f1_score(y_test, predictions):.3f}\n')Model accuracy:
Accuracy score: 0.990
F1-score: 0.962Como resultado, obtivemos um filtro de spam altamente preciso.
Os possíveis caminhos a seguir aqui podem ser tentar outros métodos de divisão de treinamento/teste para aprimorar o processo de vetorização ajustando alguns de seus inúmeros parâmetros (por exemplo, o corte de palavras muito frequentes em mensagens de spam e de spam) e verificar os casos muito raros em que o classificador detectou uma mensagem erroneamente e tentar entender por que isso aconteceu. Além disso, podemos visualizar as palavras mais frequentes nas mensagens de spam e ham usando um método como uma nuvem de palavras (após a limpeza preliminar dos dados e a exclusão de todas as stopwords ou palavras pouco informativas). Por fim, podemos aplicar outros algoritmos de aprendizado profundo ou de máquina (máquinas de vetor de suporte, árvores de decisão, redes neurais) e comparar os resultados com a abordagem Naive Bayes.
Outros casos de uso comuns de ciência de dados em telecomunicações:
- segmentação de clientes
- desenvolvimento de produtos
- análise de registros de detalhes de chamadas
- sistemas de recomendação
- previsão da taxa de rotatividade de clientes
- marketing direcionado
- detecção de fraudes
- gerenciamento e otimização de redes
- maior segurança da rede
- otimização de preços
- previsão do valor da vida útil do cliente
Estudos de caso de ciência de dados: Cursos
Percorremos um longo caminho até agora e exploramos em detalhes inúmeras aplicações da ciência de dados em diferentes campos. Se agora você se sente inspirado a aprender mais casos de uso de ciência de dados com base em conjuntos de dados do mundo real e a aplicar seus novos conhecimentos e habilidades técnicas para resolver tarefas práticas em sua própria esfera, talvez considere úteis os seguintes cursos rápidos para iniciantes sobre vários estudos de caso de ciência de dados:
- Estudo de caso: Orçamento escolar com aprendizado de máquina em Python. Neste curso, baseado em um estudo de caso de uma competição de aprendizado de máquina no DrivenData, você explorará um problema relacionado ao orçamento de distritos escolares e como tornar mais fácil e rápido para as escolas comparar seus gastos com os de outras. Aplicando algumas técnicas de linguagem natural, você preparará os orçamentos da escola e criará um modelo para classificar automaticamente seus itens, começando com uma versão simples e passando gradualmente para uma mais avançada. Além disso, você poderá ver e analisar a solução do vencedor da competição, bem como visualizar os envios dos outros participantes.
- Análise de campanhas de marketing com pandas. O Pandas é a biblioteca mais popular do Python, e o desenvolvimento de habilidades sólidas com seu kit de ferramentas é uma obrigação para qualquer cientista de dados. Neste curso altamente prático, você desenvolverá os fundamentos do Python e do pandas (adição de novas colunas, mesclagem/divisão de conjuntos de dados, trabalho com colunas de datas, visualização de resultados no matplotlib) usando um conjunto de dados de marketing falso em uma empresa de assinaturas on-line. Você praticará a tradução de perguntas típicas de marketing em valores mensuráveis. Algumas das perguntas que você responderá são: "Qual foi o desempenho dessa campanha?", "Por que um determinado canal está tendo um desempenho inferior?", "Qual canal está encaminhando o maior número de assinantes?", etc.
- Analisando dados do Censo dos EUA em Python. Neste curso, você aprenderá a navegar facilmente pelo Decennial Census e pela American Community Survey anual e a extrair deles vários dados demográficos e socioeconômicos, como renda familiar, deslocamento, raça e estrutura familiar. Você usará o Python para solicitar os dados de diferentes regiões geográficas da API do Censo e a biblioteca pandas para manipular os dados coletados e obter insights significativos a partir deles. Além disso, você praticará o mapeamento com a biblioteca de geopandas.
- Estudo de caso: Análise exploratória de dados em R. Este curso de curta duração será ideal para você que já tem algum conhecimento básico de manipulação de dados e ferramentas de visualização em R. Ao aprender os materiais deste curso, você testará suas habilidades em ação em um conjunto de dados real para explorar os dados históricos de votação da Assembleia Geral das Nações Unidas. Em especial, você analisará as tendências de votação entre países, ao longo do tempo e entre questões internacionais. Este estudo de caso permitirá que você realize uma análise exploratória de dados do início ao fim, adquira mais prática com os pacotes dplyr e ggplot2 e aprenda algumas novas habilidades.
- Análise de recursos humanos: Explorando dados de funcionários no R. O R é conhecido por ser mais bem adaptado à análise estatística do que o Python. Neste curso, você aproveitará essa vantagem do R para manipular, visualizar e realizar testes estatísticos em uma série de estudos de caso de análise de RH. As técnicas de ciência de dados surgiram no setor de recursos humanos há relativamente pouco tempo. No entanto, hoje em dia, eles representam uma direção muito promissora, pois muitas empresas estão contando cada vez mais com seus departamentos de RH para fornecer percepções e recomendações acionáveis usando o banco de dados de seus funcionários.
- Tomada de decisão orientada por dados em SQL. Neste curso, você aprenderá a usar o SQL para apoiar a tomada de decisões e relatar os resultados à gerência. O estudo de caso de interesse se concentra em uma empresa de aluguel de filmes on-line com um banco de dados sobre dados de clientes, classificações de filmes, informações básicas sobre atores, etc. Algumas das tarefas serão aplicar consultas SQL para estudar as preferências do cliente, o envolvimento do cliente e o desenvolvimento de vendas. Você aprenderá sobre as extensões SQL para processamento analítico on-line que ajudam a obter insights importantes de dados multidimensionais complexos.
Se você deseja se tornar um especialista de alto nível em ciência de dados ou se sua intenção é apenas aprender habilidades úteis de codificação para extrair insights valiosos orientados por dados em seu próprio campo de estudo, os recursos acima são um ótimo ponto de partida.
Conclusão
Em resumo, neste artigo, investigamos o que é ciência de dados sob vários ângulos, como ela difere da análise de dados, em quais esferas ela é aplicável, o que é um caso de uso de ciência de dados e um roteiro geral a ser seguido para resolvê-lo com sucesso. Discutimos exatamente como a ciência de dados pode ser útil para tarefas da vida real em alguns setores em demanda. Ao delinear muitos aplicativos existentes e potenciais, concentramo-nos nos casos de uso mais comuns em cada um desses campos populares e demonstramos como resolver cada um deles usando algoritmos de ciência de dados e análise de dados. Se quiser saber mais sobre casos de uso em outros setores, confira nossos artigos sobre casos de uso em bancos, marketing e vendas. Por fim, analisamos vários cursos on-line úteis para se aprofundar em alguns outros estudos de caso de ciência de dados.
Uma última observação curiosa: Nenhum dos setores que consideramos neste trabalho é totalmente novo. De fato, alguns deles, como medicina e vendas, existem há séculos. Durante toda a sua história, muito antes do início de nossa nova era de digitalização global, os dados desses setores também foram coletados de uma forma ou de outra, escritos em livros e documentos e mantidos em arquivos e bibliotecas. O que realmente mudou drasticamente nos últimos anos, com o advento de novas tecnologias, foi o entendimento fundamental do imenso potencial oculto em qualquer dado e a importância vital de registrá-lo, coletá-lo e armazená-lo adequadamente. A aplicação desses esforços e o aprimoramento constante dos sistemas de gerenciamento de dados possibilitaram o acúmulo de big data em todos os setores para análise e previsão adicionais.
