


Programa
Fundamentos de machine learning Em Python
16 h
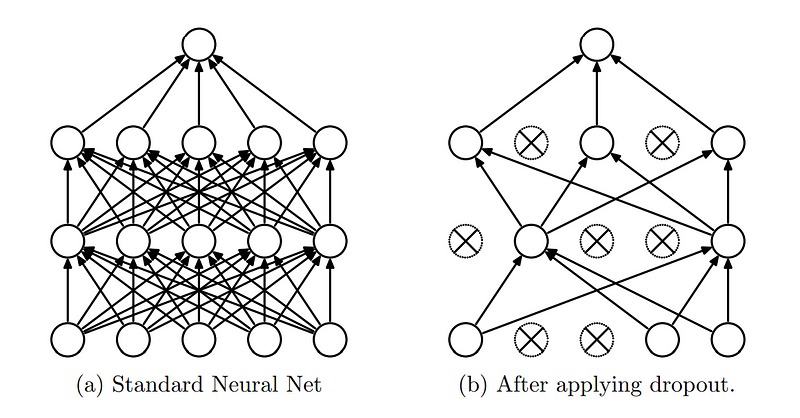
A regularização de desistência é uma técnica usada em redes neurais para evitar o ajuste excessivo, que ocorre quando um modelo aprende o ruído nos dados de treinamento em vez do padrão real.
Em 2012, Geoffrey Hinton (ganhador do Prêmio Turing) e seus colegas apresentaram a técnica em um artigo de pesquisae, desde então, ela tem sido amplamente adaptada para treinar modelos de aprendizagem profunda.
Este tutorial apresentará o conceito de regularização de queda, reforçará por que precisamos dela e apresentará as funções que ajudam a implementá-la no PyTorch. Você também aprenderá detalhes de implementação por meio de exemplos práticos, com dicas avançadas para usar o dropout de forma eficaz em seus futuros projetos de aprendizagem profunda.
A ideia central do abandono é "abandonar" aleatoriamente (definir como zero) uma fração dos neurônios da rede durante a fase de treinamento. Isso significa que uma determinada porcentagem de neurônios é ignorada ou "descartada" durante cada passagem para frente e para trás, tornando a arquitetura da rede dinamicamente diferente para cada lote de treinamento.
Regularização de desistências. (Fonte)
A camada de abandono tornou-se uma camada essencial nas redes neurais devido aos benefícios que oferece:
Como entendemos o conceito de abandono, vamos nos aprofundar na implementação dele.
Bibliotecas populares de aprendizagem profunda, como Tensorflow e PyTorch forneceram módulos e funções simplificados, de modo que a implementação da regularização de desistência em modelos de redes neurais é simples.
Como o título sugere, este tutorial se concentra na implementação da regularização de queda usando o PyTorch, mas se você optar por fazer isso no Tensorflow, as instruções estarão disponíveis na documentação oficial do Tensorflow.
PyTorch é uma biblioteca de machine learning de código aberto desenvolvida pelo Laboratório de Pesquisa de IA (FAIR) do Facebook (agora Meta), que é amplamente usada para aplicativos de aprendizagem profunda e inteligência artificial. No PyTorch, o dropout pode ser implementado usando a função torch.nn.Dropout Class.
A sintaxe da classe torch.nn.Dropout é a seguinte:
torch.nn.Dropout(p=0.5, inplace=False)Onde:
Nessa função, durante o treinamento, a camada Dropout zera aleatoriamente alguns elementos do tensor de entrada com probabilidade p. Os elementos zerados são escolhidos independentemente para cada chamada direta e são amostrados a partir de uma distribuição Bernoulli. Cada canal é zerado independentemente em cada chamada de encaminhamento.
Durante a avaliação, a camada de abandono é desativada, o que significa que a camada calcula uma função de identidade. Isso garante que todos os neurônios estejam ativos e que nenhuma escala seja aplicada.
Como você já entendeu como funciona a regularização de desistências e a função usada no PyTorch, vamos apresentar a seguir um exemplo prático.
Usaremos o popular conjunto de dados MNIST e criaremos uma rede neural convolucional simples para detectar números escritos à mão em imagens. Em seguida, aprenderemos a adicionar camadas de abandono à rede neural e examinaremos seu impacto.
Primeiro, se você ainda não instalou o Python, as instruções de instalação podem ser encontradas no site oficial do Python. Depois que o Python estiver instalado, você poderá usar o gerenciador de pacotes pip para instalar as bibliotecas do PyTorch.
Abra o terminal e execute o seguinte comando:
pip install torch torchvisionObserve que as bibliotecas do PyTorch dependem de seu ambiente e da versão do CUDA. A documentação oficial de instalação fornece instruções claras de instalação com base na configuração de seu ambiente.
Se estiver com pressa para testar os códigos e preferir pular a configuração do ambiente, você pode abrir um novo notebook do Google Collab com o PyTorch pré-instalado para que você possa colocar a mão na massa imediatamente.
Desde que o conjunto de dados MNIST (Instituto Nacional de Padrões e Tecnologia modificado) está disponível diretamente na biblioteca do PyTorch, não precisamos baixá-lo em outro lugar.
O conjunto de dados MNIST é uma grande coleção de dígitos manuscritos comumente usados para treinamento e teste. Ele consiste em 70.000 imagens em escala de cinza de dígitos (0-9), divididas em 60.000 imagens de treinamento e 10.000 imagens de teste. Cada imagem é rotulada com o dígito que representa, o que a torna um conjunto de dados de aprendizado supervisionado.
O conjunto de dados MNIST.
Carregaremos as bibliotecas relevantes e leremos o conjunto de dados.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
# Transformation to normalize the data
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# Loading the MNIST dataset
full_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# Splitting the dataset into training and validation sets
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
train_loader = DataLoader(dataset=train_dataset, batch_size=100, shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=100, shuffle=False)
test_loader = DataLoader(dataset=test_dataset, batch_size=100, shuffle=False)Para este exemplo, 20% das imagens de treinamento foram divididas em imagens de validação. Em seguida, verificamos as dimensões dos conjuntos de dados:
# Inspecting the train dataset
train_data_iter = iter(train_loader)
train_images, train_labels = next(train_data_iter)
print(f"Train Images Shape: {train_images.shape}")
print(f"Train Labels Shape: {train_labels.shape}")
print("-----------------------------------------")
# Inspecting the val dataset
val_data_iter = iter(val_loader)
val_images, val_labels = next(val_data_iter)
print(f"Validation Images Shape: {val_images.shape}")
print(f"Validation Labels Shape: {val_labels.shape}")
print("-----------------------------------------")
# Inspecting the test dataset
test_data_iter = iter(test_loader)
test_images, test_labels = next(test_data_iter)
print(f"Test Images Shape: {test_images.shape}")
print(f"Test Labels Shape: {test_labels.shape}")
Você verá o resultado da seguinte forma:
Saída: As dimensões do conjunto de dados.
Essas saídas indicam que os lotes contêm 100 imagens, cada uma com um canal e dimensões de 28x28 pixels. Os rótulos são simplesmente um tensor 1D de tamanho 100, correspondendo aos rótulos de cada imagem no lote.
Depois de carregar e transformar os dados, definimos um modelo de rede neural convolucional simples, sendo o primeiro o modelo que não usa dropout.
# Define the CNN Without Dropout
class CNNWithoutDropout(nn.Module):
def __init__(self):
super(CNNWithoutDropout, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model_without_dropout = CNNWithoutDropout()Após a definição do modelo, definimos o otimizador e a função de perda.
criterion = nn.CrossEntropyLoss()
optimizer_without_dropout = optim.SGD(model_without_dropout.parameters(), lr=0.01, momentum=0.9)Em seguida, treinamos o modelo sem desistência, registrando as métricas de treinamento e validação. Vamos escrever os códigos como funções para que possamos reutilizá-los mais tarde.
def train_validate_model(model, train_loader, val_loader, criterion, optimizer, num_epochs=10):
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = 100 * correct / total
train_losses.append(epoch_loss)
train_accuracies.append(epoch_accuracy)
# Validation Phase
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_accuracy = 100 * correct / total
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, train_accuracies, val_accuraciesAgora podemos chamar essa função com os conjuntos de dados de treinamento e validação.
train_losses_without_dropout, val_losses_without_dropout, train_accuracies_without_dropout, val_accuracies_without_dropout = train_validate_model(
model_without_dropout, train_loader, val_loader, criterion, optimizer_without_dropout
)
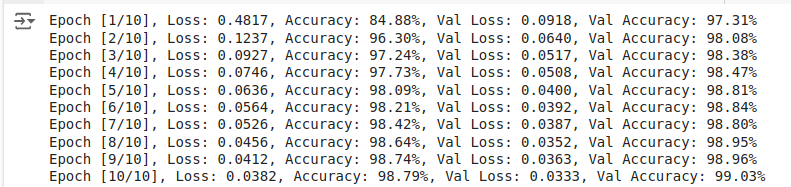
Você verá as métricas de treinamento e validação abaixo:
Saída: Métricas de treinamento e validação.
A precisão da validação é um pouco menor do que a precisão do treinamento. Mesmo sem o abandono, o modelo tem um desempenho excepcional durante a fase de treinamento e validação, demonstrando alta precisão nos conjuntos de treinamento e validação.
Após a conclusão do treinamento, podemos avaliar o desempenho do modelo nas imagens de teste para obter a pontuação de precisão do teste, que serve como nossa pontuação de linha de base antes de adicionarmos camadas de eliminação.
def evaluate_model(model, test_loader, criterion):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy
accuracy_without_dropout = evaluate_model(model_without_dropout, test_loader, criterion)
print(f'Accuracy of the model without dropout on the test images: {accuracy_without_dropout:.2f}%')A precisão final resultante, como podemos ver, é:
Saída: Precisão nas imagens de teste.
A precisão de 99,07% é extremamente boa, um pouco menor que a precisão do treinamento, mas melhor que a precisão da validação. Vejamos como o modelo se comporta quando adicionamos camadas de desistência, que dificultam o aprendizado de dígitos manuscritos.
Agora você sabe como definir, treinar e avaliar uma rede neural simples. Vamos repetir o procedimento, começando com a definição de um modelo e adicionando uma camada de dropout.
# Define the CNN With Dropout
class CNNWithDropout(nn.Module):
def __init__(self):
super(CNNWithDropout, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.dropout = nn.Dropout(p=0.5) # Dropout layer with 50% probability
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = self.dropout(torch.relu(self.fc1(x))) # Apply dropout after ReLU activation
x = self.fc2(x)
return x
model_with_dropout = CNNWithDropout()Observe a alteração do código: Foram adicionadas duas novas linhas de código, que acrescentam as camadas de dropout à definição do modelo. Sim, adicionar camadas de dropout é tão simples quanto algumas linhas de código usando a função relevante disponível no PyTorch.
Mantemos nossa função de perda e o otimizador iguais aos do modelo de linha de base.
criterion = nn.CrossEntropyLoss()
optimizer_with_dropout = optim.SGD(model_with_dropout.parameters(), lr=0.01, momentum=0.9)Em seguida, treinamos o modelo com dropout reutilizando as funções escritas anteriormente e registrando as métricas de treinamento e validação.
train_losses_with_dropout, val_losses_with_dropout, train_accuracies_with_dropout, val_accuracies_with_dropout = train_validate_model(
model_with_dropout, train_loader, val_loader, criterion, optimizer_with_dropout
)
As pontuações de treinamento e validação resultantes são:
Saída: Métricas de treinamento e validação.
Em comparação com o modelo com dropout, o modelo sem dropout atinge maior precisão de treinamento e menor perda de treinamento, o que é esperado, pois o dropout introduz ruído durante o treinamento, dificultando o ajuste perfeito do modelo aos dados de treinamento.
Apesar da redução nas pontuações de treinamento, a precisão da validação do modelo com desistência aumentou.
Durante as fases de avaliação (incluindo validação), as camadas de abandono são desativadas. Isso significa que todas as unidades estão ativas e nenhuma entrada é descartada.
No PyTorch, a alternância entre os modos de treinamento e avaliação é feita usando model.train() e model.eval()respectivamente:
model.train(): Define o modelo para o modo de treinamento, ativando o abandono e outros comportamentos específicos de treinamento, como a normalização de lotes.model.eval(): Define o modelo para o modo de avaliação, desativando o dropout e usando a rede completa para previsões.Vamos calcular a precisão do teste:
accuracy_with_dropout = evaluate_model(model_with_dropout, test_loader, criterion)
print(f'Accuracy of the model with dropout on the test images: {accuracy_with_dropout:.2f}%')A precisão resultante é a seguinte:
Saída: Precisão nas imagens de teste.
Obtivemos uma precisão de 99,12%, um pouco melhor do que a obtida com o modelo sem desistência.
Como armazenamos todas as métricas durante as fases de treinamento, validação e avaliação, vamos plotá-las em gráficos usando o Matplotlib para analisá-las melhor.
O código para fazer isso é o seguinte:
# Plotting the Results
plt.figure(figsize=(14, 10))
# Plot training loss
plt.subplot(2, 2, 1)
plt.plot(train_losses_without_dropout, label='Without Dropout')
plt.plot(train_losses_with_dropout, label='With Dropout')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plot validation loss
plt.subplot(2, 2, 2)
plt.plot(val_losses_without_dropout, label='Without Dropout')
plt.plot(val_losses_with_dropout, label='With Dropout')
plt.title('Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plot training accuracy
plt.subplot(2, 2, 3)
plt.plot(train_accuracies_without_dropout, label='Without Dropout')
plt.plot(train_accuracies_with_dropout, label='With Dropout')
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
# Plot validation accuracy
plt.subplot(2, 2, 4)
plt.plot(val_accuracies_without_dropout, label='Without Dropout')
plt.plot(val_accuracies_with_dropout, label='With Dropout')
plt.title('Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()
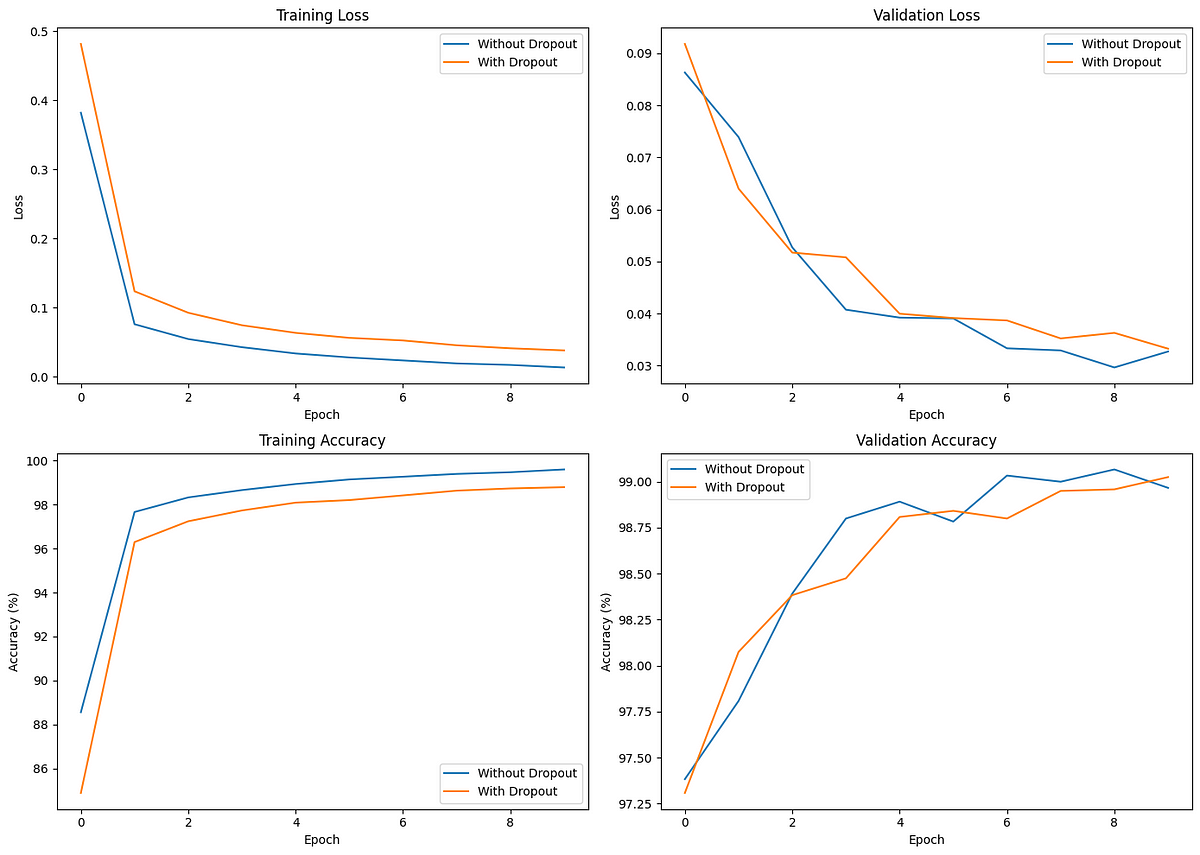
Os gráficos de comparação são os seguintes:
Comparando o efeito da desistência no treinamento e na validação.
A perda de treinamento inicial é menor para o modelo sem abandono, o que indica uma convergência mais rápida. Entretanto, o modelo com desistência demonstra perda de validação e precisão mais consistentes, indicando melhor generalização.
Ao analisar esses gráficos, o modelo com abandono atinge uma precisão de validação (e de teste) ligeiramente maior do que o modelo sem abandono, apesar de o modelo com abandono ter uma precisão de treinamento menor em comparação com o modelo sem abandono.
O abandono ajuda a evitar o ajuste excessivo, conforme observado pela menor diferença entre o desempenho do treinamento e da validação. Embora insignificante em nosso exemplo, a diferença se torna cada vez mais crucial ao treinar modelos mais complexos e maiores.
Aqui estão algumas dicas úteis quando você estiver treinando modelos de aprendizagem profunda usando o Dropout:
Se você é um praticante de aprendizagem profunda, vale a pena ler o artigo original da pesquisa "Aprimorando as redes neurais ao impedir a co-adaptação de detectores de recursos." Nele, os autores discutem várias outras diretrizes úteis baseadas em seus experimentos.
O ajuste excessivo dos dados de treinamento é um problema comum em redes neurais, especialmente em modelos maiores treinados para iterações mais altas. As técnicas de regularização, como o dropout, impedem que as redes neurais memorizem os dados de treinamento e as ajudam a aprender melhor os padrões úteis nos dados.
Este tutorial introduziu o conceito de regularização de desistência, explicou por que precisamos dela e a implementou usando o PyTorch por meio de um caso de uso de exemplo. Também aprendemos algumas práticas recomendadas avançadas e dicas para usar o abandono de forma eficaz em redes neurais profundas.
Para saber mais sobre como usar o PyTorch para tarefas de aprendizagem profunda, confira o guia para iniciantes Introdução à aprendizagem profunda com PyTorch e o curso Aprendizagem profunda intermediária com PyTorch nessa ordem.
Aprenda PyTorch com a DataCamp
Programa
Programa
Curso
Tutorial
Avinash Navlani
Tutorial
DataCamp Team
Tutorial
Zoumana Keita
Tutorial

