Programa
Fundamentos da IA
10 h
A incorporação de texto (o mesmo que incorporação de palavras) é uma técnica transformadora no processamento de linguagem natural (PLN) que melhorou a forma como as máquinas entendem e processam a linguagem humana.
A incorporação de texto converte o texto bruto em vetores numéricos, permitindo que os computadores o entendam melhor.
A razão para isso é simples: os computadores só pensam em números e não conseguem entender palavras humanas de forma independente. Graças às incorporações de texto, é mais fácil para os computadores lerem, entenderem os textos e fornecerem respostas mais precisas às consultas.
Neste artigo, analisaremos o significado da incorporação de texto, sua importância, evolução, caso de uso, principais modelos e intuição.
As incorporações de texto são uma forma de converter palavras ou frases do texto em dados numéricos que uma máquina pode entender. Pense nisso como se estivesse transformando o texto em uma lista de números, em que cada número captura uma parte do significado do texto. Essa técnica ajuda as máquinas a entender o contexto e as relações entre as palavras.
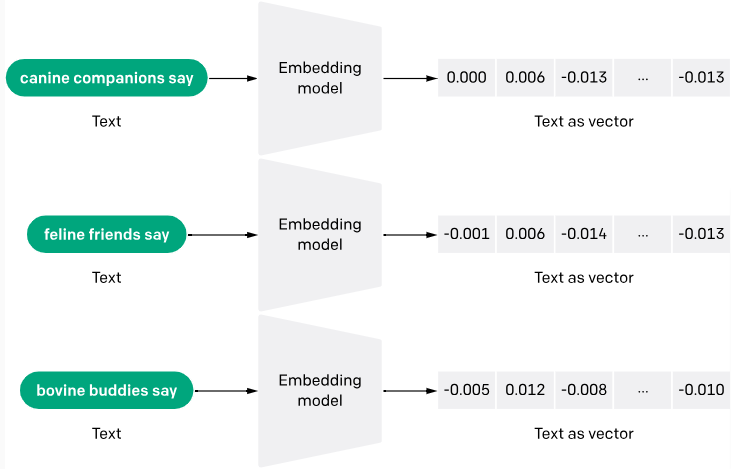
O processo de geração de incorporações de texto geralmente envolve redes neurais que aprendem a codificar o significado semântico das palavras em vetores densos de números reais. Métodos como Word2Vec e GloVe são populares para gerar essas incorporações analisando a ocorrência conjunta de palavras em grandes blocos de texto.
Você pode saber mais sobre a incorporação de texto com a API da OpenAI e ver uma aplicação prática em um artigo separado.
Os modelos de linguagem convencionais consideravam as palavras como unidades independentes. A incorporação de palavras aborda esse problema posicionando palavras que compartilham significados ou contextos próximos uns dos outros em um espaço multidimensional.
Aqui estão mais alguns motivos pelos quais as incorporações de texto são importantes:
As incorporações ajudam os modelos a generalizar melhor palavras ou frases novas e não vistas usando o contexto aprendido dos dados de treinamento. Isso é especialmente útil em idiomas dinâmicos em que novas palavras surgem com frequência.
As incorporações são amplamente usadas como atributos em várias tarefas de aprendizado de máquina, como classificação de documentos, análise de sentimentos e tradução automática. Eles melhoram o desempenho dos algoritmos fornecendo uma forma rica e condensada de dados que captura propriedades textuais básicas.
As incorporações de texto são capazes de lidar com vários idiomas, identificando e representando semelhanças semânticas entre esses diferentes idiomas. Um exemplo é o modelo LaBSE (Language-agnostic BERT Sentence Embedding), que demonstrou recursos notáveis na produção de incorporações de frases entre idiomas, abrangendo 109 idiomas.
Os métodos tradicionais, como a codificação one-hot, podem gerar dados esparsos (especialmente porque a maioria das observações tem um valor 0) e vetores de alta dimensão, que são ineficientes para grandes vocabulários. As incorporações reduzem a dimensionalidade e a complexidade computacional, o que as torna adequadas para lidar melhor com dados de texto extensos.
As incorporações de texto são representações vetoriais densas de dados de texto, em que palavras e documentos com significados semelhantes são representados por vetores semelhantes em um espaço vetorial de alta dimensão.
A intuição por trás das incorporações de texto é capturar as relações semânticas e contextuais entre os elementos do texto, permitindo que os modelos de aprendizado de máquina raciocinem e processem os dados de texto com mais eficiência.
Uma das principais intuições por trás das incorporações de texto é a hipótese distributiva, que afirma que palavras ou frases que aparecem em contextos semelhantes tendem a ter significados semelhantes.
Por exemplo, considere as palavras "rei" e "rainha". Embora não sejam sinônimos, elas compartilham um contexto semelhante relacionado à realeza e à monarquia. A incorporação de texto visa capturar essa semelhança semântica, representando essas palavras com vetores próximos no espaço vetorial.
Outra intuição por trás da incorporação de texto é a ideia de operações de espaço vetorial. Ao representar o texto como vetores numéricos, podemos usar operações de espaço vetorial como adição, subtração e similaridade de cosseno para capturar e manipular relações semânticas entre palavras e frases. Vamos considerar o seguinte exemplo:
rei - homem + mulher ≈ rainha
Nesse exemplo, a operação vetorial "rei - homem + mulher" pode resultar em um vetor muito próximo da incorporação de "rainha", capturando a relação analógica entre essas palavras.
Outra intuição que gostaria de destacar é a redução da dimensionalidade na incorporação de texto. As representações tradicionais de texto esparso, como a codificação one-hot, podem ter uma dimensionalidade extremamente alta (igual ao tamanho do vocabulário). As incorporações de texto, por outro lado, geralmente têm uma dimensionalidade menor (por exemplo, 300 dimensões), o que permite capturar os atributos mais importantes do texto e, ao mesmo tempo, reduzir o ruído e a complexidade computacional.
Usarei o exemplo de um restaurante para ilustrar uma intuição geral de incorporação de palavras:
Imagine que você tenha um corpus de avaliações de restaurantes e queira criar um sistema que classifique automaticamente o sentimento de cada avaliação como positivo ou negativo. Recomendo usar incorporações de texto para representar cada avaliação como um vetor denso, de modo a capturar o significado semântico e o sentimento expresso no texto.
Vamos considerar duas avaliações:
Revisão 1: "A comida estava deliciosa e o serviço foi excelente. Eu recomendo muito esse restaurante."
Revisão 2: "A comida era medíocre e o serviço era ruim. Não voltarei lá".
Embora essas avaliações não compartilhem muitas palavras, suas incorporações devem estar distantes umas das outras no espaço vetorial, refletindo os sentimentos contrastantes expressos. As palavras de sentimento positivo, como "delicioso" e "excelente" na Avaliação 1, teriam incorporações mais próximas da região positiva do espaço vetorial, enquanto as palavras de sentimento negativo, como "medíocre" e "ruim" na Avaliação 2, teriam incorporações mais próximas da região negativa.
Ao treinar um modelo de aprendizado de máquina com essas incorporações de texto, ele pode aprender a mapear os padrões semânticos e as informações de sentimento codificadas nas incorporações para os rótulos de sentimento correspondentes (positivos ou negativos), classificando com precisão novas avaliações não vistas.
De acordo com o livro "Embeddings in Natural Language Processing: Theory and Advances in Vector Representations of Meaning" - de Mohammad Taher Pilehvar e Jose Camacho-Collados, as incorporações de texto foram
"popularizadas principalmente após 2013, com a introdução do Word2vec."
Este ano, de fato, marcou um grande avanço para a incorporação de texto. No entanto, as pesquisas sobre incorporações de texto remontam à década de 1950. Embora esta seção não seja exaustiva, abordarei alguns dos principais marcos na evolução das incorporações de texto.
Entre as décadas de 1950 e 2000, métodos como codificação one-hot e Bag-of-Words (BoW) eram a norma. Infelizmente, esses métodos não eram muito suficientes e apresentavam alguns desafios, como, por exemplo:
O TF-IDF (Term Frequency-Inverse Document Frequency) foi outra tentativa inicial, nos anos 70, de capturar textos como números. Essa abordagem calculou o peso de cada palavra não apenas por sua frequência em um documento específico, mas também por sua frequência em todos os documentos, atribuindo valores mais altos a palavras menos comuns. Embora tenha melhorado em relação à codificação one-hot, oferecendo mais informações, ainda não conseguiu capturar o significado semântico das palavras.
De acordo com a IBM, a década de 2000 começou com os pesquisadores,
"explorando modelos de linguagem neural (NLMs), que usam redes neurais para modelar as relações entre palavras em um espaço contínuo. Esses primeiros modelos estabeleceram a base para o desenvolvimento posterior de incorporação de palavras."
Um dos primeiros exemplos é a introdução de "modelos de linguagem probabilísticos neurais" por Bengio et al. por volta de 2000, cujo objetivo era aprender representações distribuídas de palavras.
Mais tarde, em 2013, o Word2Vec entrou em cena como o modelo revolucionário que introduziu a ideia de transformar palavras em vetores numéricos. Esses vetores capturaram as semelhanças semânticas, de modo que as palavras com significados semelhantes ficaram mais próximas no espaço vetorial. Foi como criar um mapa de palavras com base em suas relações.
Em 2014, o GloVe foi apresentado em um artigo de pesquisa intitulado "Glove: Global Vectors for Word Representation", de Jeffery Pennington e seus coautores. O GloVe aprimorou o Word2Vec ao compreender melhor os significados das palavras, considerando o contexto imediato de uma palavra e o uso geral no corpus.
Durante esse período, surgiram métodos como mecanismos de atenção (2017) e Transfer Learning and Context (2018).
Os mecanismos de atenção permitiram que os modelos se concentrassem em partes específicas de uma frase e atribuíssem a elas pesos diferentes com base em sua importância. Isso ajudou o modelo a entender as relações entre as palavras e como elas contribuem para o seu significado.
Por exemplo, nesta frase, "The quick brown fox jumps over the lazy dog" (A rápida raposa marrom pula sobre o cachorro preguiçoso), o mecanismo de atenção pode prestar mais atenção em "quick" e "jumps" ao prever a próxima palavra, em comparação com "the" ou "brown".
Por outro lado, a Aprendizagem por Transferência e o Contexto acolheram o uso de modelos pré-treinados. Técnicas como ULMFiT e BERT permitiram que esses modelos pré-treinados fossem ajustados para tarefas específicas. Isso significa que menos dados e potência de computação são necessários para o alto desempenho.
As APIs de incorporação são uma abordagem recente para a incorporação de texto. Embora recente, seu surgimento gradual remonta à década de 2010, quando as soluções de IA baseadas em nuvem e os avanços nos modelos pré-treinados estavam se difundindo.
Avançando para a década de 2020. A adoção de APIs cresceu enormemente na comunidade de desenvolvedores, assim como as APIs de incorporação. Uma API de incorporação facilita a obtenção de textos por meio de modelos pré-treinados.
Um bom exemplo de uma API de incorporação é a API de incorporação da OpenAI. A OpenAI apresentou sua API de incorporação com atualizações significativas em dezembro de 2022. Essa API oferece um modelo unificado conhecido como text-embedding-ada-002, que integra recursos de vários modelos anteriores em um único modelo. Esse modelo foi projetado para se destacar em tarefas como pesquisa de texto, pesquisa de código e similaridade de frases.
Vamos discutir alguns dos casos de uso de incorporação de texto.
A incorporação de palavras permite que os mecanismos de pesquisa entendam o significado subjacente da sua consulta e encontrem documentos relevantes, mesmo que eles não contenham as palavras exatas que você usou. Isso é particularmente útil para pesquisas ambíguas ou para encontrar conteúdo semelhante.
Plataformas de comércio eletrônico, plataformas de mídia social e serviços de streaming são exemplos comuns de aplicativos que usam incorporação de texto para recomendar produtos ou conteúdo com base em suas preferências anteriores. Ao analisar as descrições e avaliações dos itens com os quais você interagiu, eles podem sugerir coisas semelhantes nas quais você pode estar interessado.
A Meta (Facebook) usa incorporações de texto para sua pesquisa social. Você pode saber mais sobre isso neste resumo.
As incorporações de texto vão além da tradução de palavras uma a uma. Eles consideram o contexto e o significado do texto, o que resulta em traduções mais precisas e naturais.
Os chatbots com tecnologia de incorporação de texto podem entender a intenção por trás de suas perguntas e responder de forma mais razoável e envolvente. Eles podem analisar o sentimento da sua mensagem e ajustar o estilo de comunicação de acordo.
As incorporações de palavras podem ser usadas para gerar diferentes formatos de texto criativo, como descrições de produtos ou publicações em mídias sociais. As marcas também podem usar incorporações de texto para analisar as conversas nas mídias sociais e entender o sentimento dos clientes em relação aos seus produtos ou serviços.
Aqui está uma mostra dos principais modelos de incorporação de texto, incluindo opções de código aberto e fechado:
Como já discutimos, o Word2Vec é um dos modelos pioneiros de incorporação de texto. Ele foi desenvolvido por Tomas Mikolov e colegas no Google. O Word2Vec usa redes neurais superficiais para gerar vetores de palavras que capturam semelhanças semânticas.
O Word2Vec utiliza duas arquiteturas de modelo: Bag-of-Words Contínuo (CBOW) e Skip-Gram. O CBOW prevê uma palavra com base em seu contexto circundante, enquanto o Skip-Gram prevê palavras circundantes com base em uma determinada palavra. Esse processo ajuda a codificar as relações semânticas entre as palavras.
Bibliotecas populares de PNL, como Gensim e spaCY, oferecem implementações do Word2Vec. Você pode encontrar a versão de código aberto do Word2vec hospedada pelo Google e lançada sob a licença Apache 2.0.
O GloVe de Stanford é outro modelo amplamente utilizado. Ele se concentra em capturar o contexto local e global, analisando as estatísticas de ocorrência conjunta de palavras em um grande corpus de texto. O GloVe constrói uma matriz de ocorrência conjunta de palavras e, em seguida, a divide em fatores para obter vetores de palavras. Esse processo considera as coocorrências de palavras próximas e distantes, levando a uma compreensão abrangente do significado das palavras.
O GloVe também é de código aberto. Os vetores GloVe pré-treinados estão disponíveis para download, e as implementações também podem ser encontradas em bibliotecas como a Gensim.
O FastText, desenvolvido pelo Facebook (agora Meta), é uma extensão do Word2Vec que aborda a limitação de não lidar com palavras fora do vocabulário (OOV). Ele incorpora informações de subpalavras para representar palavras, o que permite criar incorporações para palavras não vistas.
O FastText decompõe as palavras em n-gramas de caracteres (subpalavras). Semelhante ao Word2Vec, ele treina vetores de palavras com base nessas unidades de subpalavras. Isso permite que o modelo represente novas palavras com base no significado de suas subpalavras constituintes.
O FastText tem código aberto e está disponível na biblioteca FastText. Os vetores FastText pré-treinados também podem ser baixados para vários idiomas.
O incorporação v3 (Text-embedding-3) é a versão mais recente dos modelos de incorporação da OpenAI. Os modelos são oferecidos em duas classes: text-embedding-3-small (o modelo menor) e text-embedding-3-large (o modelo maior). Eles são de código fechado, e você precisa de uma API paga para obter acesso.
Os modelos Text-embedding-3 transformam o texto em representações numéricas, primeiro dividindo-o em tokens (palavras ou subpalavras). Cada token é mapeado para um vetor em um espaço de alta dimensão. Em seguida, um codificador Transformer analisa esses vetores, considerando o contexto de cada palavra com base em seu entorno.
Por fim, o modelo gera um único vetor que representa o texto inteiro, capturando seu significado geral e as relações entre as palavras nele contidas. A versão grande apresenta uma arquitetura mais complexa e maior dimensionalidade para uma precisão potencialmente melhor, enquanto a versão pequena prioriza a velocidade e a eficiência com uma arquitetura mais simples e menor dimensionalidade.
Para saber mais sobre as incorporações da OpenAI, confira nosso guia: Exploring Text-Embedding-3-Large: Um guia abrangente para as novas incorporações da OpenAI.
O USE é um modelo de incorporação de frases de código fechado criado pela IA do Google. Ele converte o texto em incorporações de alta dimensão que refletem os significados semânticos de frases ou parágrafos curtos.
Ao contrário dos modelos que incorporam palavras individuais, o USE lida com frases inteiras usando uma rede neural profunda pré-treinada em um corpus de texto diversificado. Esse design permite capturar relações semânticas de forma eficaz, produzindo vetores de tamanho fixo para frases de comprimento variável que aumentam a eficiência computacional.
O Google fornece acesso por meio de seu repositório TensorFlow Hub.
Neste guia, apresentamos uma introdução abrangente às incorporações de texto, o que elas significam, sua importância e os principais marcos de sua evolução. Também examinamos os casos de uso de incorporação de texto e os principais modelos de incorporação de texto.
Para saber mais sobre IA, PNL e incorporação de texto, confira estes recursos:
Saiba mais sobre IA com o DataCamp
Programa
Curso
Curso
blog
Matt Crabtree
15 min
blog
Javier Canales Luna
8 min
blog
Matt Crabtree
11 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Moez Ali