
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Os modelos de linguagem grande (LLMs) se tornaram muito importantes no desenvolvimento de modelos de aprendizado de máquina, principalmente para aprimorar os recursos dos algoritmos de processamento de linguagem natural. De chatbots a geradores de conteúdo, esses modelos transformam a maneira como interagimos com a tecnologia.
No entanto, à medida que a presença do LLM aumenta em número e complexidade, a avaliação de seu desempenho se torna mais importante. Sem uma avaliação adequada e precisa, saber se um modelo está funcionando como esperado ou se precisa de ajustes é um desafio.
É aqui que entra o MLflow. O MLflow é uma ferramenta de código aberto projetada para facilitar o gerenciamento de experimentos de aprendizado de máquina. Ele nos ajuda a acompanhar os resultados de diferentes experimentos, gerenciar modelos e manter tudo organizado!
Neste tutorial, exploraremos a função do MLflow no aprimoramento dos fluxos de trabalho do LLM. Orientarei você na configuração e mostrarei como registrar métricas e rastrear parâmetros em experimentos LLM. Por fim, veremos como o MLflow oferece suporte ao gerenciamento e à implementação eficazes de modelos.
O MLflow é uma plataforma de código aberto projetada para gerenciar o ciclo de vida do aprendizado de máquina de ponta a ponta. Ele fornece ferramentas para simplificar o processo de desenvolvimento, rastreamento e implementação de modelos de aprendizado de máquina.
Quer estejamos trabalhando em um projeto pequeno ou gerenciando experimentos complexos com modelos grandes, o MLflow pode nos ajudar a manter a organização e a eficiência.
Algumas das vantagens de usar o MLflow no ciclo de vida do aprendizado de máquina incluem:
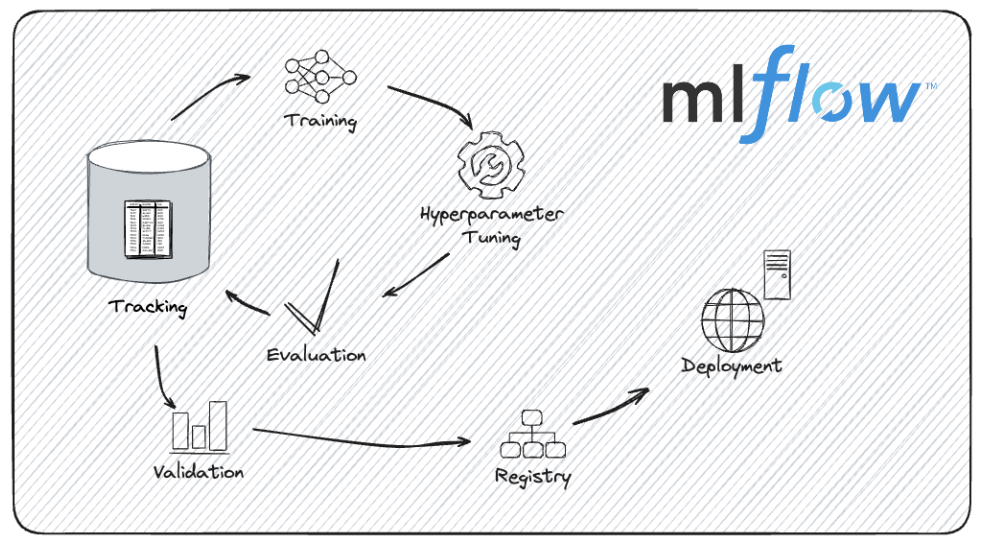
O ciclo de vida de desenvolvimento de modelos com o MLflow. Fonte da imagem: Documentação do MLflow.
O MLflow foi projetado para tornar o gerenciamento de projetos de aprendizado de máquina mais fácil e transparente. Isso é especialmente útil quando você trabalha com modelos complexos como LLMs, como veremos agora.
O uso do MLflow para avaliação do LLM tem várias vantagens, como rastreamento de versões de modelos, registro de métricas de avaliação e comparação de desempenho entre campos.
Vamos ver esses benefícios em mais detalhes.
O desenvolvimento de LLMs envolve iterações e aprimoramentos frequentes. Cada nova versão traz pequenos aprimoramentos ou alterações de comportamento. O MLflow gerencia essas diferentes iterações rastreando sistematicamente as versões do modelo. Esse recurso nos permite reproduzir resultados, comparar diferentes versões de forma eficaz e manter um histórico claro da evolução do modelo.
Digamos que estejamos experimentando diferentes técnicas de ajuste fino; o MLflow pode nos ajudar a gerenciar e analisar os resultados de cada versão, facilitando a identificação de qual iteração produz o melhor desempenho.
Como o MLflow garante que cada experimento e seus resultados associados sejam registrados de forma exaustiva, podemos compartilhar nossas descobertas com confiança, sabendo que outras pessoas podem reproduzir nossos resultados com exatidão.
Se o nosso projeto envolver a experimentação de diferentes arquiteturas de LLM ou metodologias de treinamento, os recursos de rastreamento do MLflow facilitarão a documentação e o compartilhamento do nosso trabalho.
A avaliação de LLMs envolve o monitoramento de várias métricas, como precisão, perplexidade e pontuação F1, entre outras.
A funcionalidade de registro do MLflow nos permite registrar essas métricas de forma eficiente e organizada. A análise dessas métricas nos dá uma boa visão do desempenho do nosso modelo.
Por exemplo, talvez você queira comparar como diferentes hiperparâmetros ou conjuntos de dados de treinamento afetam as métricas de desempenho do modelo. Com o MLflow, podemos registrar e visualizar essas métricas para obter insights práticos.
À medida que os modelos são implantados e usados em aplicativos do mundo real, eles podem sofrer desvios de modelo, em que seu desempenho diminui devido a alterações nos dados ou no ambiente. Podemos aproveitar o MLflow para monitorar e gerenciar o desvio do modelo, acompanhando o desempenho do modelo ao longo do tempo.
Podemos definir avaliações regulares e usar o MLflow para registrar e analisar como as métricas de desempenho mudam, tomando decisões acionáveis em tempo real.
Uma das vantagens mais importantes do MLflow é sua capacidade de simplificar comparações abrangentes de modelos. Ao armazenar registros detalhados de diferentes experimentos, o MLflow nos permite comparar o desempenho de vários LLMs e configurações de hiperparâmetros lado a lado.
Encontrar os hiperparâmetros corretos pode determinar o sucesso de um modelo ao desenvolver LLMs.
Imagine que estamos fazendo o ajuste fino de um LLM e queremos avaliar o impacto de diferentes configurações de hiperparâmetros. Usando o MLFlow, podemos registrar e comparar resultados de várias taxas de aprendizagem, tamanhos de lote ou taxas de abandono para determinar qual configuração produz o melhor desempenho, otimizando nosso processo de desenvolvimento de modelos.
As funcionalidades de registro e rastreamento de modelos do MLflow entram em ação ao avaliar vários LLMs para implantação.
Suponha que tenhamos várias versões de um modelo de linguagem que estamos considerando para um ambiente de produção. O MLflow pode nos ajudar a registrar as métricas de desempenho de cada modelo, compará-las e tomar uma decisão informada com base em evidências empíricas e não apenas na intuição.
Agora que temos uma visão mais clara do MLflow e de seus benefícios, vamos colocar a mão na massa!
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Antes de avaliar os LLMs com o MLflow, precisamos configurar a plataforma adequadamente. Isso envolve a instalação do MLflow, a configuração opcional de um servidor de rastreamento para registro remoto e a garantia de que nosso ambiente esteja pronto para gerenciar experimentos e rastrear resultados.
Vamos ver como você pode fazer isso.
1. Verifique se o Python está instalado:
Primeiro, precisamos ter certeza de que temos o Python instalado em nosso computador. O MLflow é compatível com o Python 3.6 e versões superiores (lembre-se de que o Python 3.8 está obsoleto, portanto, é recomendável usar o Python >= 3.9). Podemos verificar nossa versão do Python com:
python --version2. Crie um ambiente virtual (opcional, mas recomendado):
É uma boa prática usar um ambiente virtual ao rastrear experimentos com o MLFlow, principalmente se você estiver trabalhando com o Mac OS X. Você pode criar um ambiente virtual usando venv ou virtualenv.
python -m venv mlflow-envAtivamos o ambiente virtual:
No Windows:
mlflow-env\Scripts\activateNo Mac/Linux:
source mlflow-env/bin/activate3. Instale o MLflow usando o pip:
Com o ambiente virtual ativado (se usado), podemos instalar o MLflow via pip:
pip install mlflow4. Instalar dependências adicionais:
O MLflow tem algumas dependências opcionais para melhorar a funcionalidade. Se precisarmos usar recursos específicos, como os recursos de modelo de serviço do MLflow, precisaremos instalar o site gunicorn.
pip install gunicornSe estivermos usando bibliotecas como TensorFlow ou PyTorch, talvez seja necessário instalar suas respectivas integrações do MLflow:
pip install mlflow[extras]4. Verifique a instalação:
Em seguida, precisamos nos certificar de que o MLflow está instalado corretamente, verificando sua versão:
mlflow --versionSe estivermos trabalhando em um ambiente colaborativo ou se for necessário realizar o registro remoto, devemosconfigurar um servidor de rastreamento do MLflow. Esse recurso nos permite centralizar o rastreamento e o gerenciamento de nossos experimentos.
1. Execute o servidor de rastreamento:
Você pode iniciar o servidor MLflow especificando o armazenamento de back-end e o local do artefato.
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlruns--backend-store-uri especifica onde os dados do experimento são armazenados. Podemos usar qualquer sistema de banco de dados (PostgreSQL, MySQL, etc.).--default-artifact-root especifica o diretório em que os artefatos, por exemplo, arquivos de modelo, são armazenados.2. Configure o servidor de rastreamento:
Precisamos ter certeza de que nossos clientes MLflow estão configurados para fazer login no servidor de rastreamento. Podemos definir a variável de ambiente MLFLOW_TRACKING_URI para apontar para o nosso servidor.
export MLFLOW_TRACKING_URI=http://localhost:50003. Acesse a interface de usuário de rastreamento:
Agora, podemos abrir um navegador da Web e navegarpara http://localhost:5000 paraacessar a interface do usuário do MLflow. Essa interface nos permite visualizar experimentos, comparar resultados e gerenciar seus projetos de MLflow, como veremos mais adiante.
Com o MLflow configurado e pronto, é hora de você se dedicar às principais tarefas de carregamento e avaliação de LLMs. Vamos ver como podemos selecionar um LLM pré-treinado, carregá-lo usando diferentes bibliotecas e preparar um conjunto de dados de avaliação para medir o desempenho do modelo.
Ao selecionar um LLM pré-treinado, bibliotecas como a Hugging Face Transformers oferecem muitas opções. Por exemplo, podemos carregar um modelo pré-treinado, como o GPT (para geração de texto) ou o BERT (para classificação de texto e outras tarefas).
1. Instalar transformadores de rosto
Primeiro, vamos garantir que você tenha a biblioteca Hugging Face Transformers instalada. Para isso, você pode usar o site pip.
pip install transformers2. Carregar um modelo pré-treinado e um tokenizador
Agora, carregamos o modelo BERT usando a biblioteca transformers, incluindo o modelo e o tokenizador, que são necessários para processar o texto e gerar previsões.
from transformers import (
BertForSequenceClassification,
BertTokenizer
)
# Load pre-trained model and tokenizer
model_name = "textattack/bert-base-uncased-yelp-polarity"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)O modelo bert-base-uncased é usado quando os dados de texto com os quais estamos trabalhando estão, em sua maioria, em letras minúsculas e maiúsculas, mas não precisamos que o modelo diferencie entre palavras maiúsculas e minúsculas.
Para avaliar um LLM, precisamos de um conjunto de dados adequado que corresponda à tarefa que estamos avaliando. Vamos ver como preparar uma avaliação baseada em texto conjunto de dados para análise de sentimentos:
1. Carregar ou criar e pré-processar o conjunto de dados
Nossos dados podem ser armazenados em vários locais: no disco de nossa máquina local, em um repositório do Github ou no The Hugging Face Hub, uma ampla coleção de conjuntos de dados de pesquisa populares e com curadoria da comunidade.
Para este tutorial, usaremos um grande conjunto de dados de resenhas de filmes para análise de sentimentoschamado IMDB. Usaremos a biblioteca datasets para carregar o conjunto de dados pré-criado:
Instalando a biblioteca de conjuntos de dados:
pip install datasetsCarregando um conjunto de dados:
from datasets import load_dataset
# Load the dataset IMDb for sentiment analysis
dataset = load_dataset("imdb")2. Pré-processamento para análise de sentimentos
Usaremos o tokenizador BERT carregado anteriormente para pré-processar o conjunto de dados para análise de sentimentos.
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(preprocess_function, batched=True)Agora que nossos LLMs estão carregados e nosso conjunto de dados de avaliação preparado, é hora de executar as avaliações e as métricas de registro.
1. Importar o MLflow e iniciar um novo experimento
Para rastrear experimentos com o MLflow, primeiro precisamos iniciar um novo experimento e registrar os metadados relevantes, como o nome do modelo, a versão e os parâmetros de avaliação.
import mlflow
import mlflow.pytorch
# Start a new experiment
mlflow.set_experiment("LLM_Evaluation")
with mlflow.start_run() as run:
# Log experiment metadata
mlflow.log_param("model_name", "bert")
mlflow.log_param("model_version", "v1.0")
mlflow.log_param("evaluation_task", "sentiment_analysis")2. Parâmetros de avaliação de registros
Agora podemos registrar todos os parâmetros relacionados ao processo de avaliação, como o tamanho do conjunto de dados de avaliação ou as configurações específicas usadas durante a avaliação.
with mlflow.start_run() as run:
mlflow.log_param("dataset_size", len(dataset['test']))Depois de treinarmos e fazermos as previsões correspondentes usando nosso modelo, podemos avaliar o LLM e registrar várias métricas que refletem seu desempenho.
A análise de sentimento é um problema de classificação, portanto, podemos avaliar nosso modelo usando métricas como precisão e pontuação F1. Para tarefas de geração de texto, métricas como a pontuação BLEU ou a perplexidade são comumente usadas.
from sklearn.metrics import accuracy_score, f1_score
# Assuming y_true and y_pred are true labels and model predictions
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
with mlflow.start_run() as run:
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)Depois que várias execuções de avaliação são rastreadas com o MLflow, a comparação de seu desempenho é essencial para determinar os modelos e as configurações de melhor desempenho.
Vamos entender como rastrear várias execuções e usar a interface do usuário do MLflow para visualizar e comparar os resultados de forma eficaz.
Primeiro, precisamos rastrear várias execuções no mesmo experimento ou em experimentos diferentes para comparar o desempenho de diferentes versões do LLM.
1. Registre várias execuções
Podemos registrar várias execuções em um único experimento, iniciando novas execuções para cada modelo ou configuração que desejamos avaliar.
models = [("bert-base-cased", "v1.0"), ("bert-base-uncased", "v1.0")]
y_pred_dict = {
"bert-base-cased": y_pred_case,
"bert-base-uncased": y_pred_uncase
}
for model_name, model_version in models:
with mlflow.start_run() as run:
# Log model and version
mlflow.log_param("model_name", model_name)
mlflow.log_param("model_version", model_version)
# Perform evaluation and log metrics
y_pred = y_pred_dict[model_name]
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)2. Acompanhe os experimentos com diferentes modelos
Vamos imaginar que você queira avaliar diferentes tipos de modelos. Para isso, podemos usar o MLFlow para criar um experimento e registrar os modelos juntos.
Realizar o registro de modelos no MLFlow é o mesmo que fazer o controle de versão dos modelos de aprendizado de máquina. O registro dos detalhes do modelo e do ambiente garante a reprodutibilidade.
Primeiro, vamos montar um experimento. Em seguida, registramos cada modelo em uma execução separada do MLFlow, incluindo os IDs de execução e os caminhos dos artefatos.
# Create an experiments for the different models
mlflow.set_experiment("sentiment_analysis_comparison")
model_names = ["bert-base-cased", "bert-base-uncased"]
run_ids = []
artifact_paths = []
for model, name in zip([betcased, bertuncased], model_names):
with mlflow.start_run(run_name=f"log_model_{name}"):
artifact_path = f"models/{name}"
mlflow.pyfunc.log_model(
artifact_path=artifact_path,
python_model=model,
)
run_ids.append(mlflow.active_run().info.run_id)
artifact_paths.append(artifact_path)Agora, podemos avaliar os modelos e registrar os resultados. O MLflow fornece uma API, mlflow.evaluate(), para ajudar você a avaliar nossos LLMs.
for i in len(model_names):
with mlflow.start_run(run_id=run_ids[i]):
# reopen the run with the stored run ID
evaluation_results = mlflow.evaluate(
model=f"runs:/{run_ids[i]}/{artifact_paths[i]}",
model_type="text",
data=dataset['test'],
)Depois de registrarmos as diferentes métricas e modelos no MLFlow, podemos fazer uma comparação. Podemos usar a interface amigável do MLflow para visualizar e comparar métricas de avaliação de diferentes execuções. Para fazer isso, precisamos iniciar o servidor MLflow, se ele ainda não estiver em execução
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlrunsEm seguida, abrimos um navegador da Web e navegamos para http://localhost:5000 paraacessar a interface do usuário do MLflow. Na interface do usuário do MLflow, vamos para a página "Experiments" (Experimentos) para visualizar todos os nossos experimentos. Clicamos no nome do experimento para ver uma lista de execuções associadas a ele.
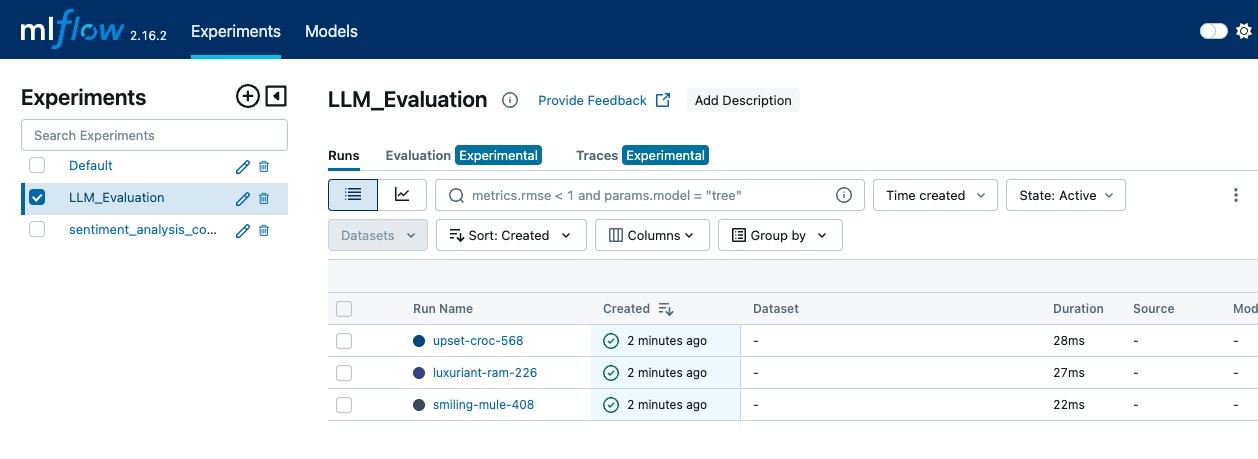
A interface do MLFLow mostra a guia Experimentos, onde as diferentes execuções e eventos de registro podem ser vistos - imagem por autor.
Em um experimento, podemos comparar diferentes execuções selecionando várias execuções e visualizando suas métricas lado a lado.
A interface do usuário nos permite ver uma representação visual de métricas como precisão, pontuação F1 e outras métricas de avaliação. Você também pode usar as visualizações integradas do MLflow para gerar plotagens e gráficos para comparações mais detalhadas.
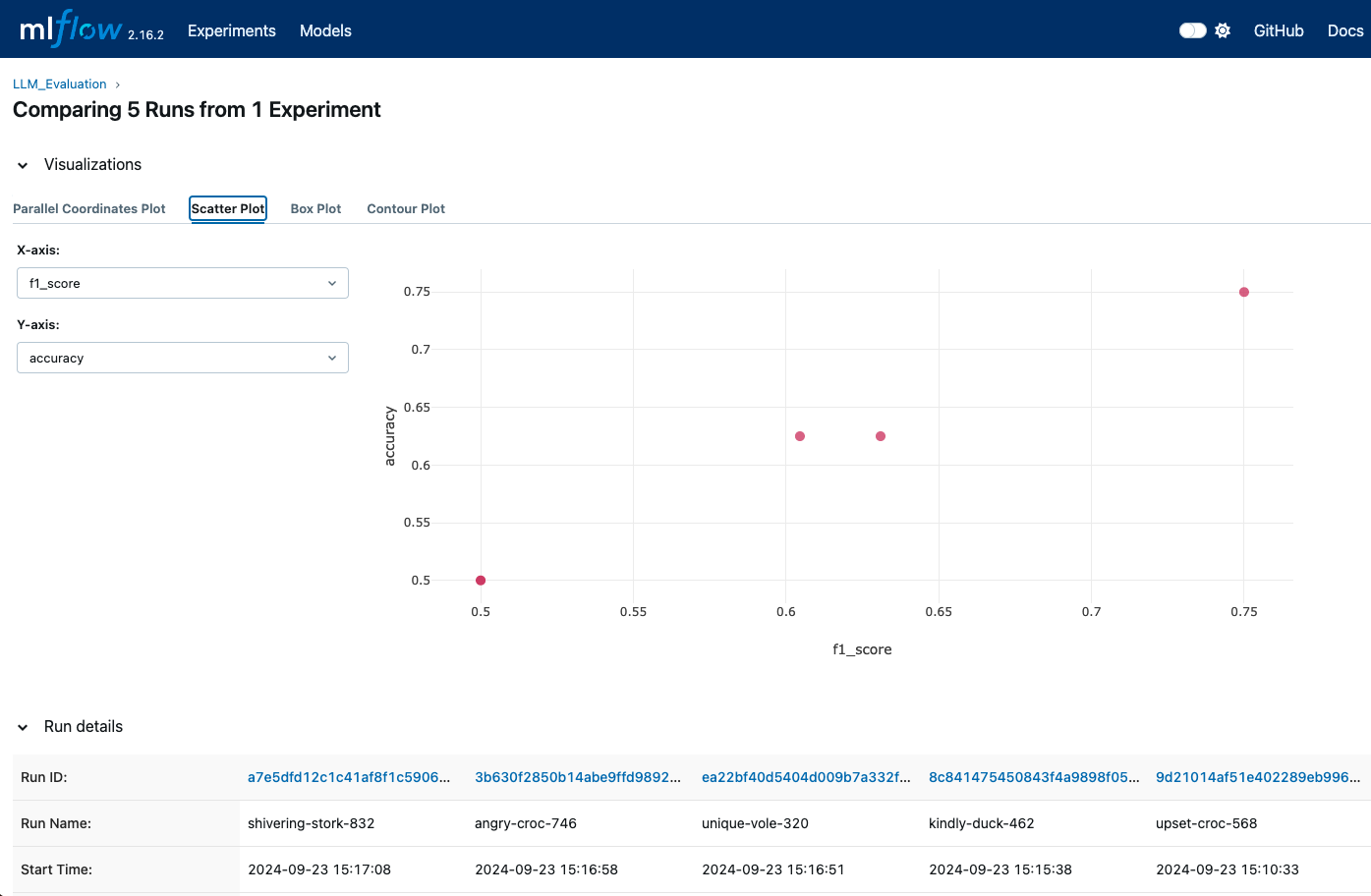
As visualizações do MLFlow podem nos mostrar quando diferentes execuções são registradas para que possamos comparar diferentes métricas - imagem por autor.
A interface de usuário do MLflow fornece gráficos e registros detalhados para cada execução. Podemos acessar esses logs e visualizações para entender qual modelo ou configuração tem melhor desempenho com base nas métricas registradas.
Para uma avaliação mais profunda e abrangente dos LLMs, o MLflow oferece técnicas avançadas que aprimoram o rastreamento e a análise. Analisaremos como registrar os artefatos do modelo para rastreamento completo e utilizaremos o MLflow para ajuste de hiperparâmetros para otimizar o desempenho do LLM .
O registro de artefatos do modelo é muito importante para preservar e analisar os detalhes de nossos experimentos. Os artefatos podem fornecer uma imagem completa do desempenho do nosso modelo e ajudar a reproduzir os resultados.
Entre os artefatos que podemos registrar, podemos encontrar:
joblib para scikit-learn ou formato SavedModel do TensorFlow).Aqui está um exemplo:
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
with mlflow.start_run() as run:
# Log the model
mlflow.pytorch.save_model(model, "model")
# Log the model weights
joblib.dump(model, "model_weights.pkl")
mlflow.log_artifact("model", artifact_path="model")
# Log the confusion matrix as image
confusion_matrix = pd.DataFrame(confusion_matrix(y_test, predictions))
cm = ConfusionMatrixDisplay(confusion_matrix=cm)
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
# Generate predictions
outputs = dataset['test']
outputs['prediction'] = model.predict(dataset['test'])
with open("generated_outputs.txt", "w") as f:
for output in outputs:
f.write(output + "\n")
# Log the file
mlflow.log_artifact("generated_outputs.txt")O ajuste de hiperparâmetros é uma parte fundamental da otimização do desempenho do LLM. Em nossos experimentos, podemos usar o MLflow para registrar diferentes configurações de hiperparâmetros. Isso nos permite comparar os efeitos de várias configurações e encontrar a configuração ideal.
from transformers import Trainer, TrainingArguments
def train_and_log_model(model, lr, bs):
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=learning_rate,
evaluation_strategy="epoch")
trainer = Trainer(model=model,
args=training_args,
train_dataset=(X_train, y_train)
eval_dataset=(X_test, y_test))
with mlflow.start_run() as run:
# Log hyperparameters
mlflow.log_param("learning_rate", lr)
mlflow.log_param("batch_size", bs)
trainer.train()
eval_result = trainer.evaluate()
mlflow.log_metric("eval_accuracy",
eval_result['eval_accuracy'])
hyperparameter_grid = [{"learning_rate": 5e-5, "batch_size": 8},
{"learning_rate": 3e-5, "batch_size": 16}]
for params in hyperparameter_grid:
train_and_log_model(params["learning_rate"],
params["batch_size"])Outra vantagem do MLflow é que ele pode ser usado com bibliotecas de otimização de hiperparâmetros, como Optuna ou Ray Tune, para automatizar o processo de ajuste.
Uma avaliação precisa dos LLMs envolve mais do que a execução de testes e o registro de métricas. Isso requer uma abordagem estratégica para garantir consistência, precisão e eficiência. A adoção de práticas recomendadas pode aumentar a confiabilidade e a eficácia do processo de avaliação.
O uso de conjuntos de dados estáveis e representativos é uma das primeiras coisas que contribuem para uma avaliação eficaz. Ao garantir que nossos conjuntos de dados de avaliação sejam estáveis e representativos das tarefas para as quais nosso LLM foi projetado, obteremos comparações significativas ao longo do tempo e entre diferentes modelos ou versões. Se o conjunto de dados for alterado, pode ser difícil atribuir as alterações de desempenho ao modelo e não ao próprio conjunto de dados.
Não apenas o conjunto de dados, mas também a forma como pré-processamos é importante. We precisamos aplicar as mesmas etapas de pré-processamento a todos os conjuntos de dados de avaliação para garantir resultados comparáveis. Isso inclui tokenização, normalização e tratamento de casos especiais. O pré-processamento consistente garante que as variações no desempenho do modelo não se devam a diferenças na forma como os dados são tratados.
Como visto acima, o uso do registro de modelos do MLflow para permitir o controle de versão nos ajuda a rastrear diferentes versões dos nossos LLMs. Isso facilita a comparação do desempenho do modelo e a reversão para versões anteriores, se necessário. Devemos registrar todos os detalhes e acompanhar as alterações feitas nos modelos, inclusive modificações na arquitetura, nos hiperparâmetros ou nos dados de treinamento.
Por fim, automatizar o processo de avaliação integrando-o aos pipelines de integração contínua/implantação contínua (CI/CD) pode nos ajudar a garantir que os modelos sejam avaliados de forma consistente e imediata sempre que forem feitas atualizações. Devemos estabelecer avaliações programadas para avaliar periodicamente o desempenho do modelo. Isso nos ajuda a monitorar o desvio do modelo e a garantir que os modelos atendam aos padrões de desempenho ao longo do tempo.
A avaliação eficaz dos LLMs exige uma abordagem estruturada e sistemática, e o MLflow oferece uma estrutura para apoiar esse processo.
Neste tutorial, instalamos o MLflow e configuramos um servidor de rastreamento. Em seguida, avaliamos nosso LLM registrando métricas importantes, rastreamos várias execuções para compará-las e usamos a interface do usuário do MLflow para visualizar e analisar essas comparações de forma eficaz.
Se você quiser levar seu conhecimento sobre MLflow para o próximo nível, confira nosso curso de Introdução ao MLflow!
Saiba mais sobre LLMs com estes cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
