


Programa
ChatGPT Fundamentos
3 h
Comece a usar a API OpenAI e muito mais!
O o3 é o modelo de fronteira mais recente da OpenAI, projetado para aprimorar os recursos de raciocínio em uma série de tarefas complexas, como codificação, matemática, ciências e percepção visual.
O modelo de raciocínio o3 é o primeiro modelo de raciocíniocom acesso aousoautônomoda ferramenta . Isso significa que o o3 pode usar a pesquisa, o Python, a geração de imagens e a interpretação para realizar suas tarefas.
Isso se traduziu em um forte desempenho em benchmarks avançados que testam a solução de problemas do mundo real, onde os modelos anteriores tiveram dificuldades. A OpenAI destaca o aprimoramento do o3 em relação ao o1, posicionando-o como seu modelo mais capaz e versátil até o momento.
O o3 se baseia diretamente na fundação estabelecida pelo o1, mas os aprimoramentos são significativos em áreas importantes. A OpenAI posicionou o o3 como um modelo projetado para lidar com tarefas de raciocínio mais complexas, com ganhos de desempenho refletidos em seus benchmarks.
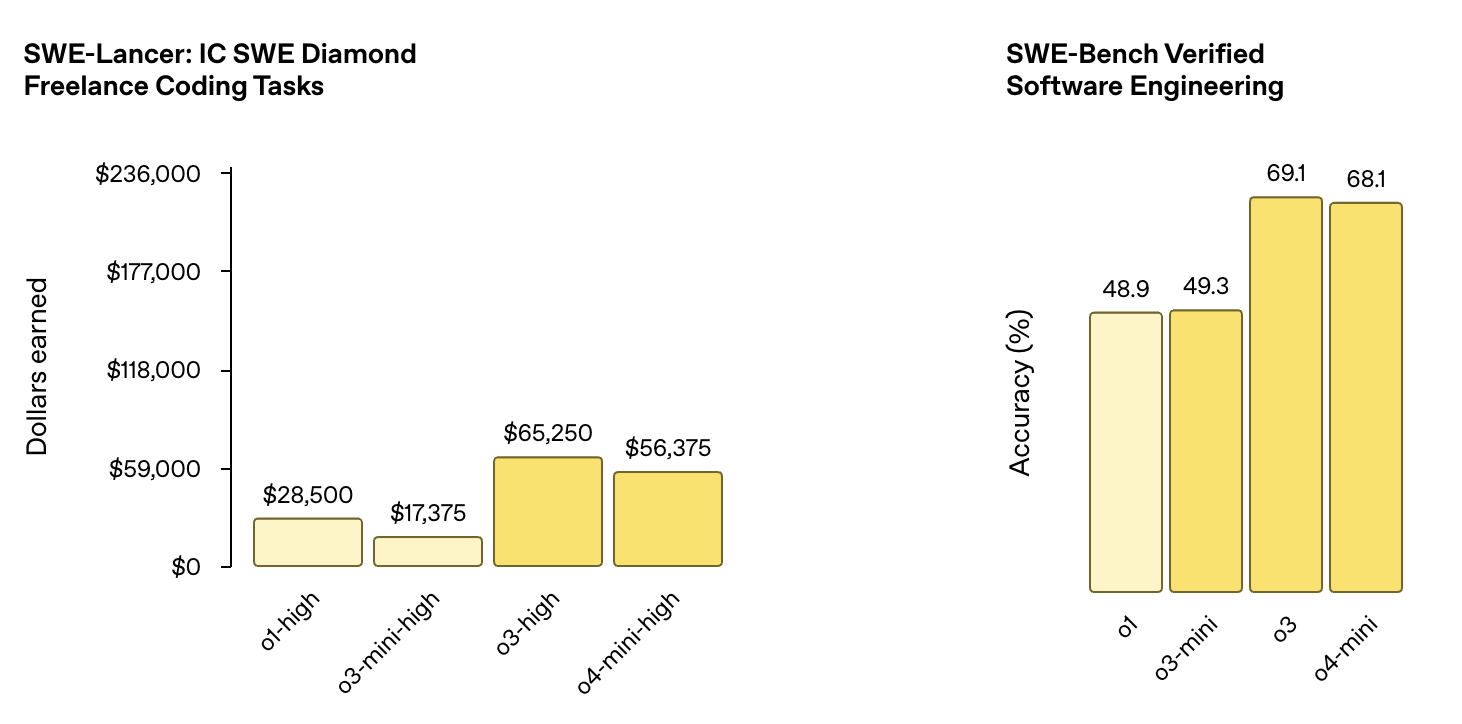
Quando testado em tarefas de engenharia de software, o o3 atingiu 69,1% de precisão no benchmark SWE-Bench Verified Software Engineering, uma melhoria substancial em relação à pontuação do o1 de 48,9%.
Fonte: OpenAI
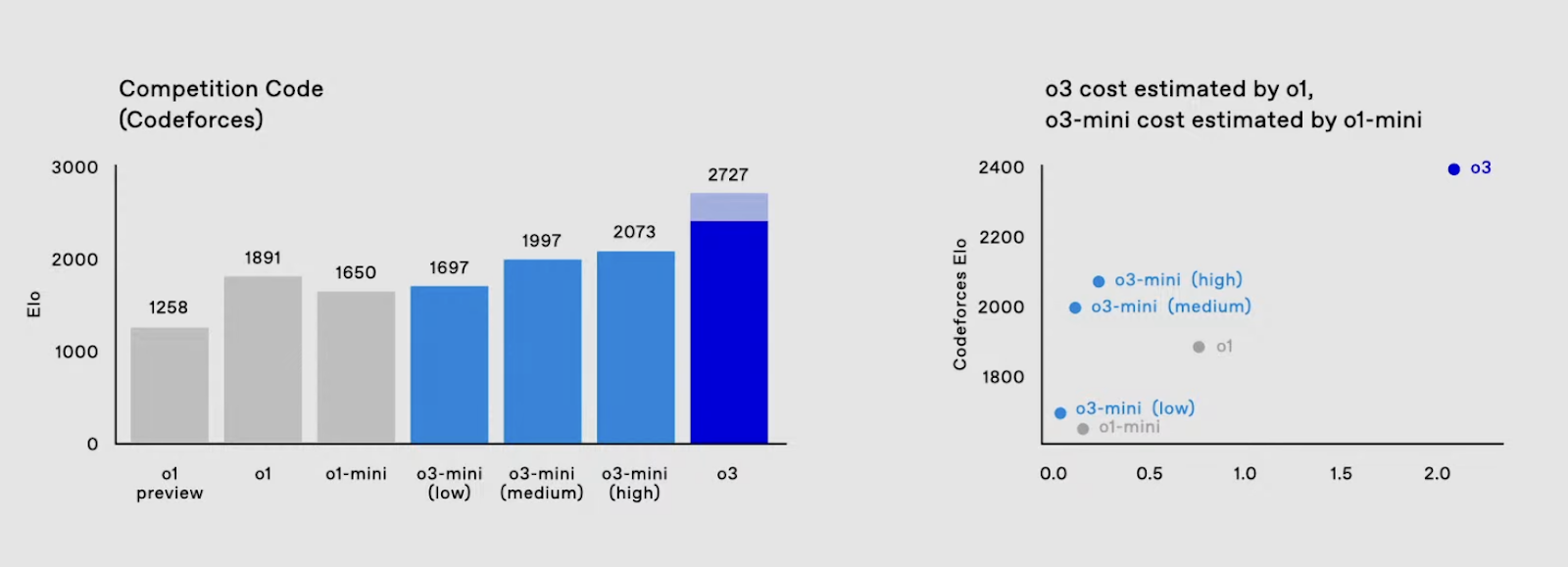
Da mesma forma, na programação competitiva, o3 alcançou uma pontuação ELO de 2.706, superando em muito o recorde anterior de 1.891 do o1. Além disso, o o3 tem um desempenho significativamente melhor em benchmarks de edição de código, com as variantes do o3 superando o o1 em toda a linha no benchmark Aider Polyglot Code Editing.
Fonte: OpenAI
As melhorias não se limitam à codificação. O o3 também se destaca em raciocínio matemático, com 91,6% de precisão no AIME 2024, em comparação com os 74,3% do o1. Ele também obteve uma pontuação de 88,9% no AIME 2025. Esses ganhos sugerem um modelo que pode lidar com problemas mais matizados e difíceis, aproximando-se de padrões de referência tradicionalmente dominados por especialistas humanos.
Fonte: OpenAI
O salto é igualmente evidente nos benchmarks relacionados à ciência. No GPQA Diamond, que mede o desempenho em questões científicas de nível de doutorado, o o3 obteve uma precisão de 83,3%, acima dos 78% do o1. Esses ganhos demonstram um amplo aprimoramento da capacidade do modelo de resolver problemas tecnicamente exigentes em todas as disciplinas.
Fonte: OpenAI
Um dos aspectos mais impressionantes do novo modelo o3 é sua capacidade de raciocinar com imagens diretamente em sua cadeia de pensamento. Isso significa que o o3 pode combinar raciocínio visual e textual ao resolver problemas, e isso se reflete no desempenho do o3 em vários benchmarks de raciocínio visual.
Fonte: OpenAI
Por exemplo, o o3 supera o o1 em vários benchmarks de raciocínio visual, incluindo o benchmark de solução de problemas visuais de nível universitário MMMU (82,9% contra 77,6% do o1), o benchmark de raciocínio matemático visual MathVista (86,8% contra 71,8% do o1) e o benchmark de raciocínio de figuras científicas CharXiv-Reasoning (78,6% contra 55,1% do o1).
Fonte: OpenAI
Uma área em que o progresso do o3 é especialmente notável é no benchmark EpochAI Frontier Math.
Esse é considerado um dos benchmarks mais desafiadores em IA, pois consiste em problemas novos e inéditos que são intencionalmente projetados para serem muito mais difíceis do que os conjuntos de dados padrão. Muitos desses problemas estão no nível da pesquisa matemática, muitas vezes exigindo horas ou até dias de matemáticos profissionais para resolver um único problema. Os sistemas de IA atuais normalmente pontuam menos de 2% nesse benchmark, o que destaca sua dificuldade.
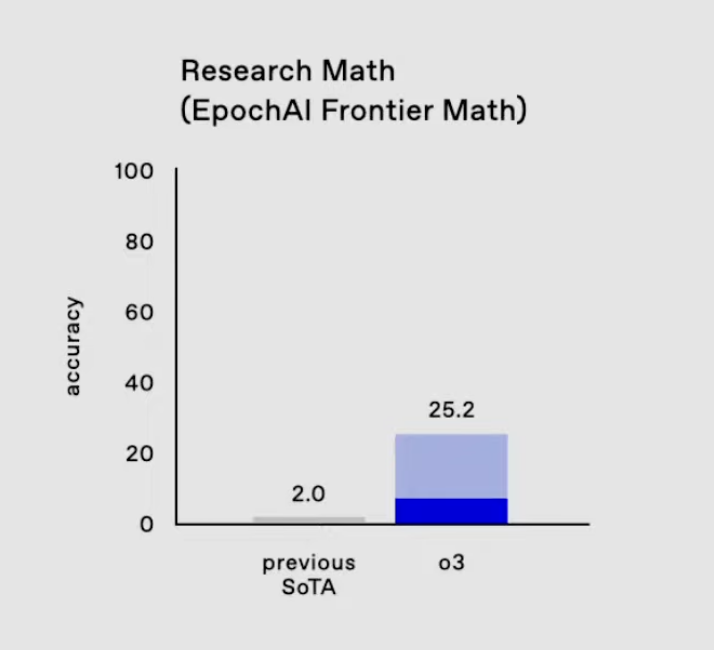
O3 no EpochAI Frontier Math. Fonte: OpenAI
O Frontier Math da Epic AI é importante porque leva os modelos além da memorização mecânica ou da otimização de padrões familiares. Em vez disso, ele testa a capacidade de generalização, raciocínio abstrato e resolução de problemas nunca antes encontrados - características essenciais para o avanço dos recursos de raciocínio de IA. A pontuação da o3 de 25,2% nesse benchmark é um salto em relação ao desempenho anterior do estado da arte. .
Uma das conquistas mais impressionantes do o3 é seu desempenho no benchmark ARC AGI, um teste amplamente considerado como padrão ouro para avaliar a inteligência geral em IA.
Desenvolvido em 2019 por François Chollet, o ARC (Abstraction and Reasoning Corpus) se concentra em avaliar a capacidade de uma IA de aprender e generalizar novas habilidades a partir de exemplos mínimos. Ao contrário dos benchmarks tradicionais, que geralmente testam o conhecimento pré-treinado ou o reconhecimento de padrões, as tarefas do ARC são projetadas para desafiar os modelos a inferir regras e transformações em tempo real - tarefas que os seres humanos podem resolver intuitivamente, mas com as quais a IA tem tido dificuldades historicamente.
O que torna o ARC AGI particularmente difícil é que cada tarefa exige habilidades de raciocínio distintas. Os modelos não podem confiar em soluções ou modelos memorizados; em vez disso, eles devem se adaptar a desafios totalmente novos em cada teste. Por exemplo, uma tarefa pode envolver a identificação de padrões em transformações geométricas, enquanto outra pode exigir raciocínio sobre sequências numéricas. Essa diversidade faz da ARC AGI uma medida poderosa de quão bem uma IA pode realmente pensar e aprender como um ser humano.
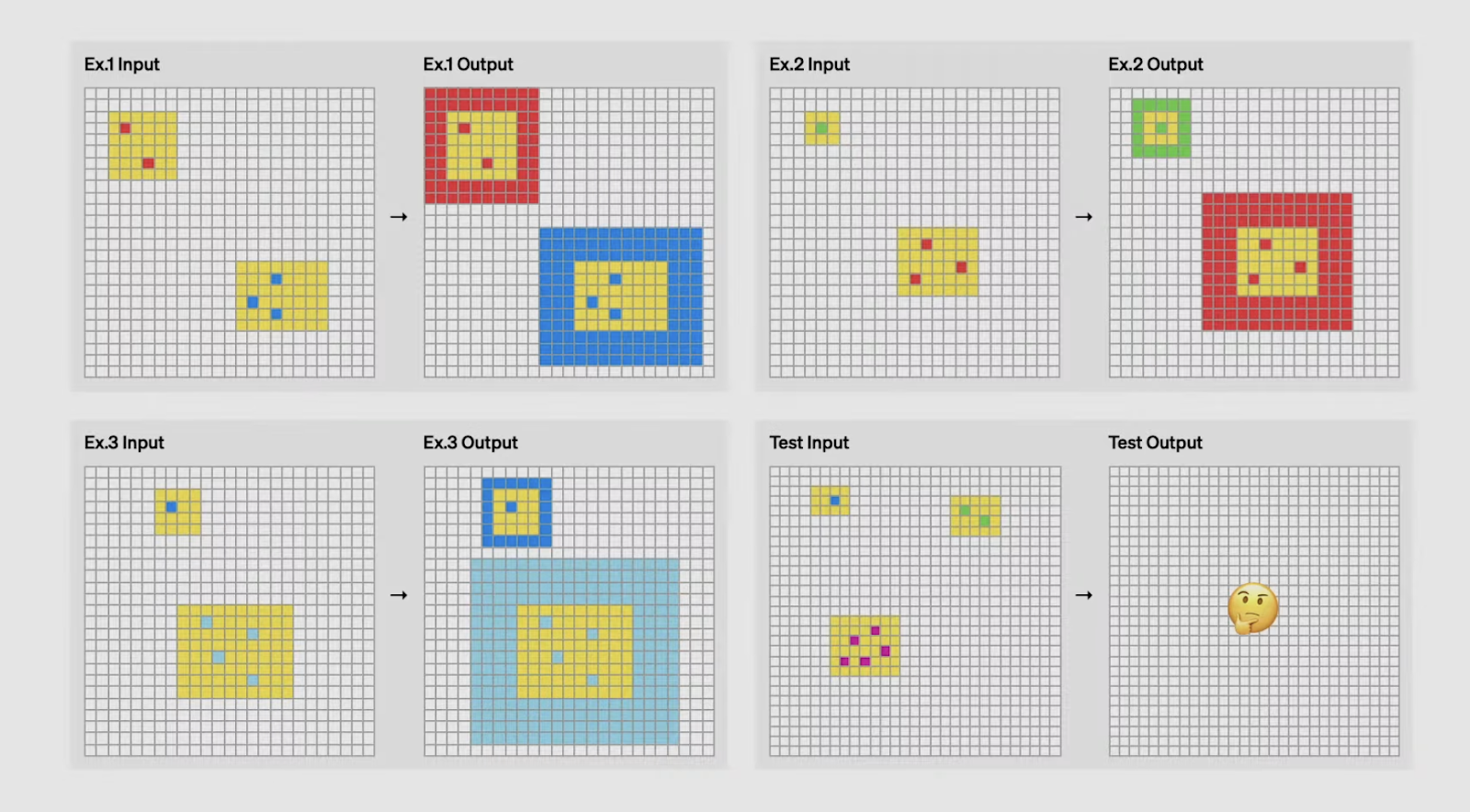
Você consegue adivinhar a lógica pela qual a entrada é transformada em saída? Fonte: OpenAI
O desempenho da o3 no ARC AGI é um marco significativo. Em configurações de baixa computação, o o3 obteve 76% no conjunto de holdout semiprivado - um número muito acima de qualquer modelo anterior.
Quando testado com configurações de alta computação, ele alcançou um índice ainda mais impressionante de 88%, ultrapassando o limite de 85% frequentemente citado como desempenho de nível humano. Essa é a primeira vez que uma IA supera os humanos nesse benchmark, estabelecendo um novo padrão para tarefas baseadas em raciocínio.
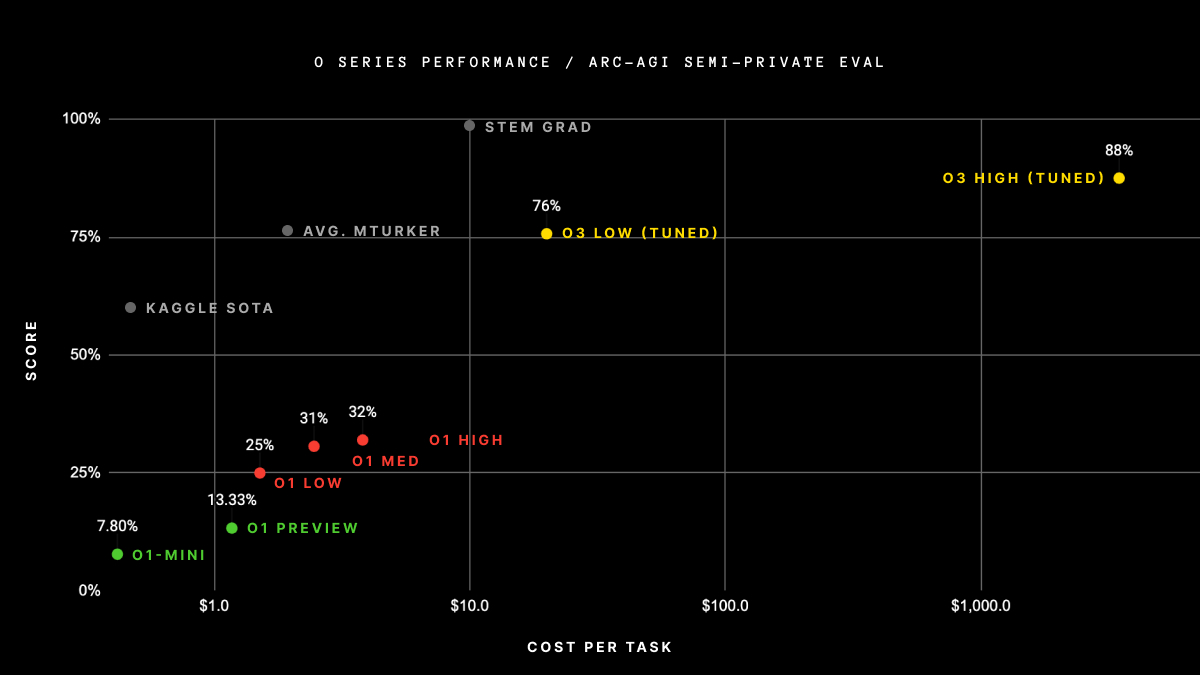
Fonte: ArcPrize
Acreditamos que esses resultados são particularmente notáveis, pois demonstram a capacidade do o3 de lidar com tarefas que exigem adaptabilidade e generalização, em vez de conhecimento mecânico ou computação de força bruta. É uma indicação clara de que a o3 está se aproximando da verdadeira inteligência geral, indo além dos recursos específicos do domínio e entrando em áreas que antes eram consideradas território exclusivamente humano.
Dito isso, os resultados acima se baseiam na versão do o3 compartilhada no evento 12 Days of Christmas da OpenAI em dezembro, e a OpenAI confirmou que a versão recém-lançada do o3 é diferente da mostrada nos testes acima. A ARC AGI divulgará em breve os resultados atualizados de desempenho do o3.
Essa grande melhoria de desempenho não acontece por acaso. A equipe da OpenAI descobriu alguns avanços para atingir esses tipos de números:
A OpenAI descobriu que o aumento do orçamento de computação durante o treinamento de aprendizagem por reforço melhora o desempenho do modelo - espelhando o comportamento de escala que vimos com o pré-treinamento supervisionado em modelos GPT. Mas, desta vez, em vez de otimizar a previsão da próxima palavra, o o3 aprende maximizando as recompensas do aprendizado por reforço, muitas vezes por meio de ambientes aumentados por ferramentas.
Em outras palavras, a OpenAI está tratando o aprendizado por reforço mais como um pré-treinamento - ampliando-o tanto em termos de duração quanto de computação - e isso parece funcionar. Isso libera habilidades que se beneficiam do planejamento de longo prazo e do raciocínio sequencial, como programação competitiva e provas matemáticas de várias etapas. Quando combinados com o uso de ferramentas, os ganhos de desempenho se tornam ainda mais evidentes.
O o3 também apresenta melhorias significativas no raciocínio visual. Ele não apenas entende as imagens, mas as integra diretamente em seu ciclo de raciocínio. Isso inclui interpretar, manipular e reinspecionar imagens enquanto você resolve problemas. Esse é um dos motivos pelos quais o o3 tem um bom desempenho em tarefas que envolvem figuras científicas, diagramas matemáticos e até mesmo agendamento de fotos.
Uma inovação importante é a forma como o o3 retém a imagem bruta na memória durante todo o processo de raciocínio. Em vez de processar uma legenda estática e descartar a imagem, ele pode aplicar zoom, girar ou revisitar diferentes partes da imagem sob demanda usando ferramentas. Isso torna seu raciocínio mais dinâmico e permite que ele lide com entradas visuais mais confusas, como um quadro branco borrado, um diagrama desenhado à mão ou uma foto de uma programação de conferência.
Em um exemplo, a OpenAI usou a o3 para ler uma imagem de baixa qualidade de uma programação de shows e planejar um itinerário que se encaixasse em todos os eventos com intervalos de dez minutos entre eles - algo que exigiria a análise do layout visual e a aplicação de restrições em tempo real.

Queríamos testar as habilidades visuais com um teste rápido feito por nós mesmos. Primeiro, demos a o1 um desenho rudimentar e perguntamos a ele: "Qual fractal estamos começando a desenhar?"
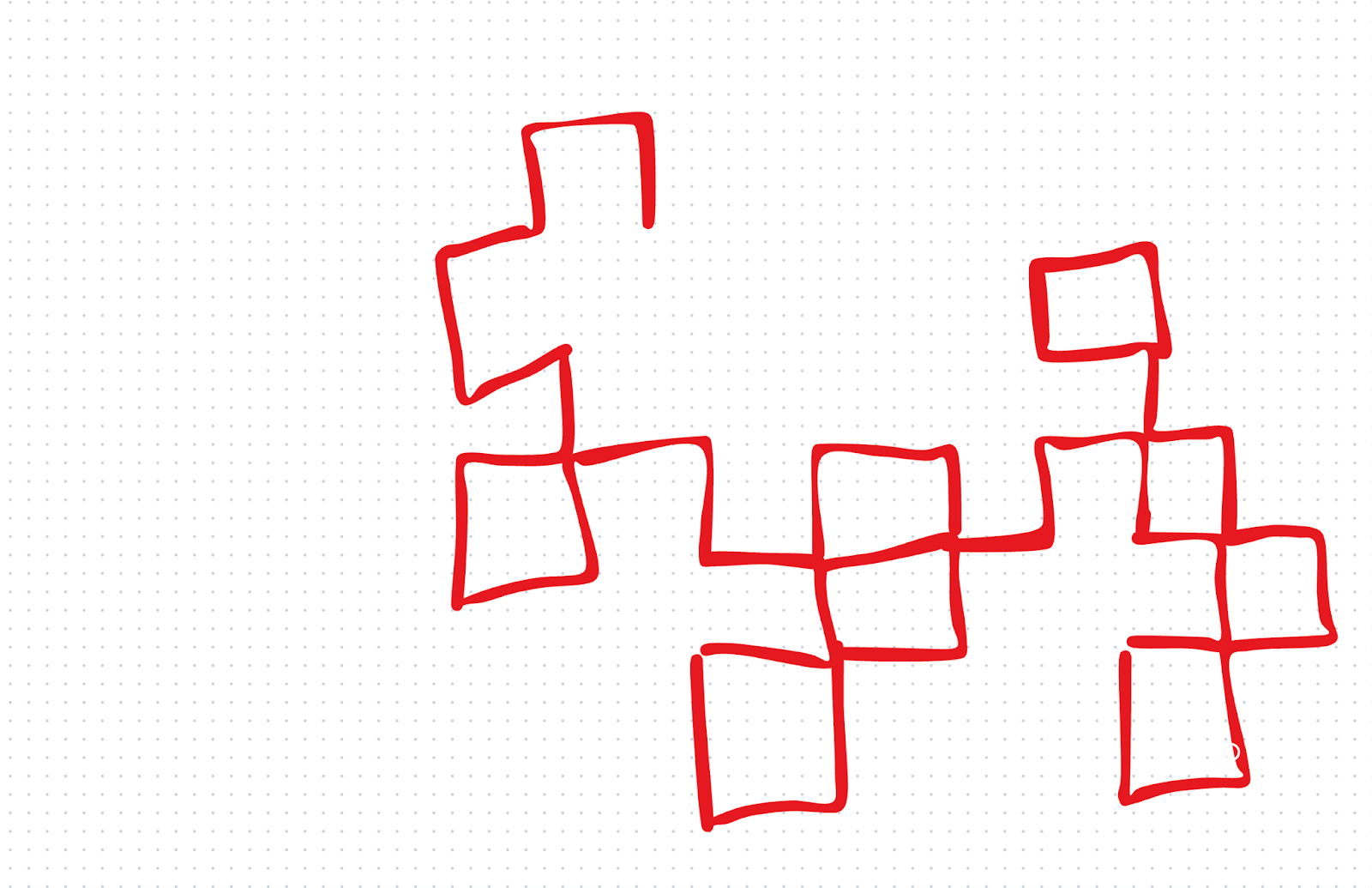
o1 respondeu incorretamente. o3, por outro lado, acertou: Ele nos disse que estávamos começando a desenhar a curva do dragão. Esse foi um teste pequeno, mas ficamos impressionados com o resultado porque não demos muito ao o3 para continuar.

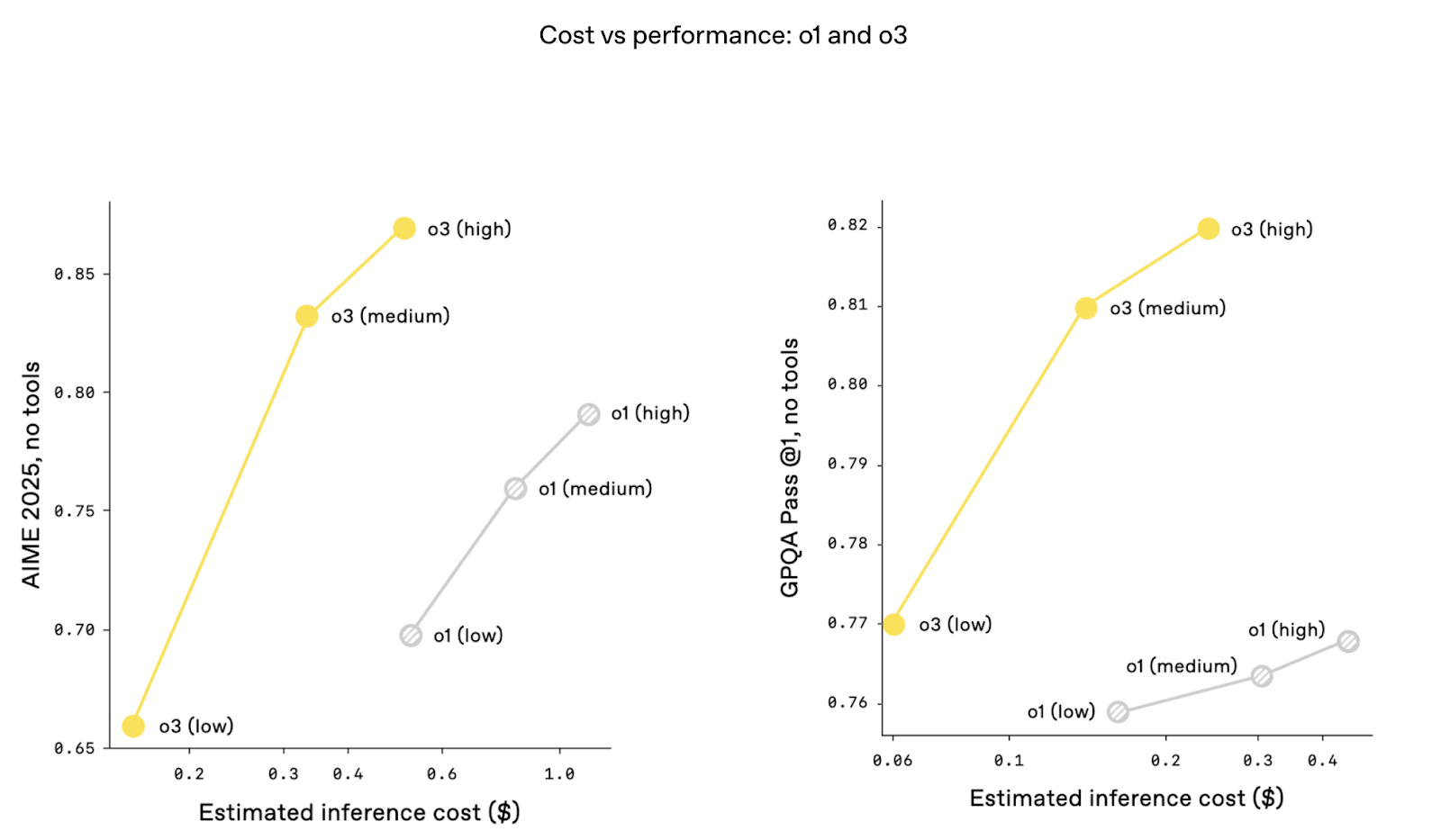
É interessante notar que as métricas de custo versus desempenho são melhores com o o3. Ou seja, o desempenho é maior nos mesmos níveis de custo de inferência. Isso pode ocorrer graças a otimizações de arquitetura que melhoram o rendimento do token e reduzem a latência. O custo tem sido um grande tópico de discussão desde que Deepseek-R1 anunciou um desempenho super alto por uma fração do custo do ChatGPT.
A partir de abril de 2025, o o3-mini foi totalmente substituído pelo o4-mini no ChatGPT e na API. O o4-mini oferece melhor desempenho na maioria dos benchmarks, adiciona entrada multimodal nativa e mantém a compatibilidade de ferramentas - tudo isso enquanto permanece mais rápido e mais acessível do que o o3. Na verdade, o o4-mini agora assume a função que o o3-mini foi projetado para preencher. O conteúdo abaixo, no entanto, permanece válido para o o3-mini.
O o3-mini foi apresentado juntamente com o o3 como uma alternativa econômica projetada para levar recursos avançados de raciocínio a mais usuários, mantendo o desempenho. A OpenAI descreveu o o3-mini como uma redefinição da "fronteira de custo-desempenho" em modelos de raciocínio, tornando-o acessível para tarefas que exigem alta precisão, mas precisam equilibrar as restrições de recursos.
Um dos recursos de destaque do o3-mini é o tempo de raciocínio adaptável, que permite aos usuários ajustar o esforço de raciocínio do modelo com base na complexidade da tarefa. Para problemas mais simples, os usuários podem selecionar raciocínio de baixo esforço para maximizar a velocidade e a eficiência.
Para tarefas mais desafiadoras, as opções de maior esforço de raciocínio permitem que o modelo funcione em níveis comparáveis aos do próprio o3, mas por uma fração do custo. Essa flexibilidade é particularmente interessante para desenvolvedores e pesquisadores que trabalham em diversos casos de uso.
Fonte: OpenAI
A demonstração ao vivo mostrou como a o3-mini cumpre sua promessa. Por exemplo, em uma tarefa de codificação, o3-mini foi encarregado de gerar um script Python para criar um servidor local com uma interface de usuário interativa para testes. Apesar da complexidade da tarefa, o modelo teve um bom desempenho, demonstrando sua capacidade de lidar com desafios de programação.
Fonte: OpenAI
Vemos o o3-mini como uma solução prática para cenários em que a relação custo-benefício e o desempenho devem estar alinhados.
Demorou um pouco mais para que o O3 se tornasse disponível, e alguns dos motivos podem estar relacionados a inovações em segurança.
A OpenAI disse que reconstruiu seus conjuntos de dados de treinamento de segurança e introduziu milhares de solicitações de recusa direcionadas. Eles destacaram categorias específicas: ameaças biológicas, geração de malware e técnicas de jailbreak. Esses dados de treinamento atualizados permitiram que a o3 demonstrasse uma forte precisão de recusa em benchmarks internos, como manuseio de hierarquia de instruções e resistência a jailbreak. Para conseguir isso, segundo informações, a OpenAI fez com que os membros da equipe passassem mil horas sinalizando conteúdo inseguro.
A OpenAI também implementou um monitor LLM baseado em raciocínio (o que eles chamam de "monitor de raciocínio focado na segurança"). Portanto, além de treinar o modelo para dizer "não" a solicitações inseguras, a OpenAI introduziu uma camada de segurança adicional, que é um LLM baseado em raciocínio. Pense nisso como um modelo de cão de guarda executado em paralelo, treinado especificamente para analisar a intenção e os riscos potenciais das entradas do usuário, usando regras de segurança escritas por humanos como guia.
A OpenAI adotou uma abordagem proativa para os testes de segurança do o3 e do o3 mini, abrindo o acesso a pesquisadores para avaliações de segurança pública antes do lançamento completo dos modelos.
Um recurso central da estratégia de segurança da OpenAI para o o3 é o alinhamento deliberativo, um método que vai além das abordagens tradicionais de segurança. O gráfico abaixo destaca como o alinhamento deliberativo difere de outros métodos, como o RLHF (Reinforcement Learning with Human Feedback), RLAIF (Reinforcement Learning with AI Feedback) e técnicas de refinamento em tempo de inferência, como o Self-REFINE.
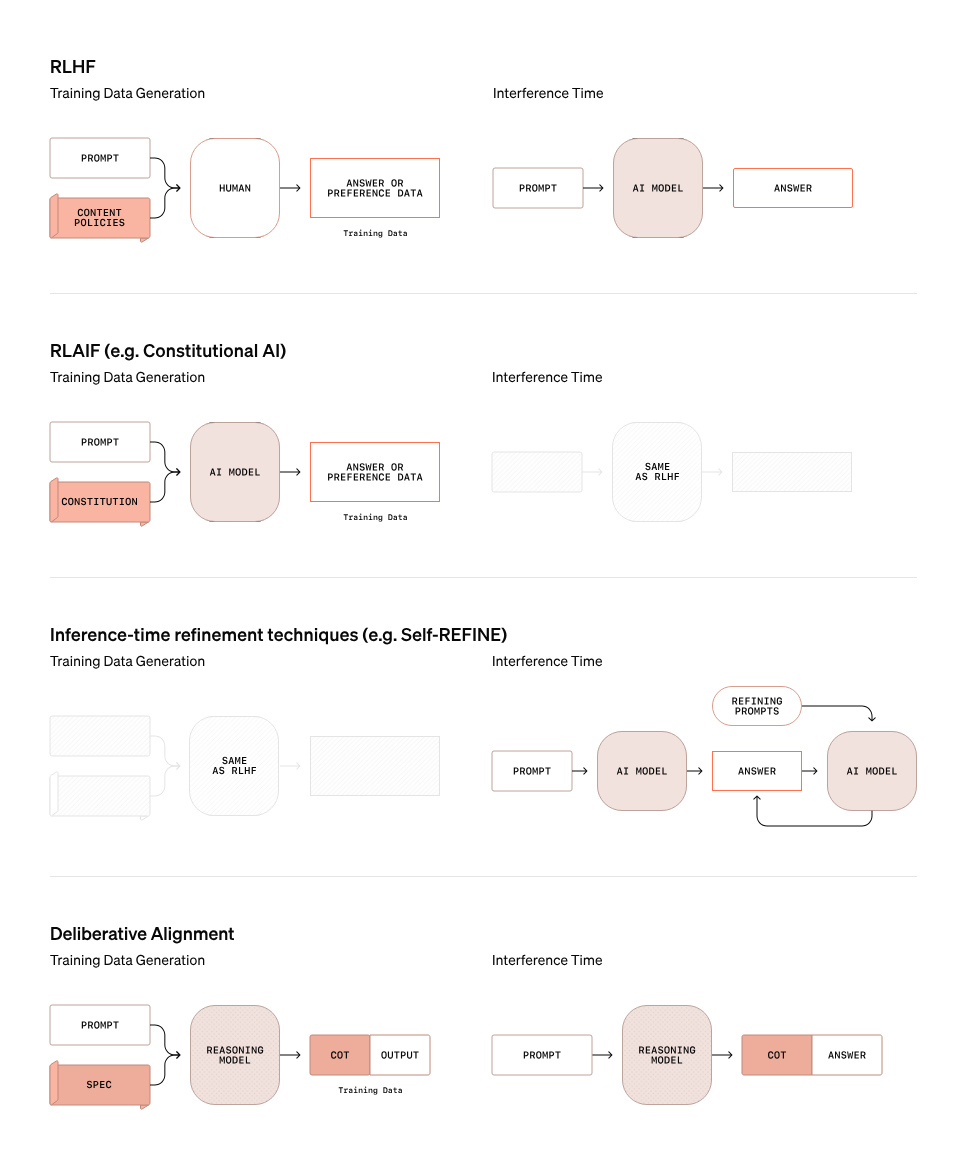
Fonte: OpenAI
No alinhamento deliberativo, o modelo não se baseia simplesmente em regras estáticas ou conjuntos de dados de preferências para determinar se um prompt é seguro ou inseguro. Em vez disso, ele usa seus recursos de raciocínio para avaliar as solicitações em tempo real. O gráfico acima ilustra esse processo:
A OpenAI espera que você queira continuar lendo sobre segurança. Em antecipação a isso, eles lançaram sua Estrutura de preparação com suas ideias sobre medição e proteção contra danos graves.
No seletor de modelos do ChatGPT, você verá agora o3 e o4-mini disponíveis. De acordo com o anúncio da OpenAI, espera-se que a o3-pro seja lançada nas próximas semanas. Ele incluirá os mesmos recursos de uso de ferramentas - como Python, navegação e análise de imagens - que os outros modelos da série o.
Se você estiver interessado em receber atualizações sobre quando o o3-pro estiver disponível, inscreva-se no boletim informativo da DataCamp, The Median, e nós o informaremos assim que ele for lançado.
O3 e o3 mini destacam a crescente complexidade dos sistemas de IA e os desafios de liberá-los de forma responsável. Embora os benchmarks sejam impressionantes, estamos mais interessados nas questões que esses modelos levantam: Qual será o desempenho deles em cenários do mundo real? As medidas de segurança são robustas o suficiente para lidar com casos extremos em escala?
Para nós, o o3 e o o3 mini são os primeiros sinais de que os sistemas de IA estão se aproximando de uma maior autonomia. Seu raciocínio e adaptabilidade impressionantes sugerem uma mudança de ferramentas que operamos para agentes que agem em nosso nome. O que acontece quando esses sistemas navegam em tarefas abertas sem orientação humana? Como avaliamos modelos que geram suas próprias metas, e não apenas seus resultados?
Se você estiver interessado em explorar mais tópicos de IA, recomendamos:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Richie Cotton
7 min
blog
Richie Cotton
8 min
blog
Josep Ferrer
8 min
blog
Richie Cotton
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan



