Programa
Fundamentos de SQL
26 h
No mundo atual, orientado por dados, enfrentamos um desafio significativo: como armazenar, gerenciar e extrair com eficiência insights significativos dos dados? Os bancos de dados oferecem uma solução, fornecendo repositórios estruturados para organizar e acessar informações.
Entretanto, para atender aos requisitos exclusivos de várias estruturas de dados e casos de uso, surgiram diferentes tipos de bancos de dados.
Neste artigo, exploraremos os quatro principais tipos que você encontrará no mundo da ciência de dados: bancos de dados relacionais, bancos de dados NoSQL, bancos de dados em nuvem e bancos de dados vetoriais.
Se você quiser aprender sobre design de banco de dados, confira este curso sobre Design de banco de dados.
Os bancos de dados são ferramentas essenciais no mundo digital. Eles são coleções organizadas de dados que facilitam o armazenamento, a recuperação, o gerenciamento e a manipulação de informações.
Em sua essência, os bancos de dados são projetados para manter os dados em um formato estruturado, permitindo que os usuários e aplicativos acessem e atualizem as informações com eficiência, conforme necessário.
A importância dos bancos de dados se estende a quase todos os campos, mas é particularmente crítica na ciência de dados. Os projetos de ciência de dados geralmente envolvem a análise de grandes volumes de dados para obter insights, fazer previsões ou informar a tomada de decisões.
Sem bancos de dados, o gerenciamento desses dados - especialmente à medida que aumentam de tamanho e complexidade - seria complicado e propenso a erros. Os bancos de dados oferecem uma maneira sistemática de armazenar dados e garantir sua integridade, segurança e acessibilidade.
Considere, por exemplo, uma empresa de varejo que programa vendas, interações com clientes, inventário e informações sobre fornecedores. Um banco de dados serve como espinha dorsal das operações da empresa, permitindo que ela analise tendências, preveja a demanda, otimize os níveis de estoque e aprimore as experiências dos clientes.
Sem um banco de dados, a empresa teria dificuldades para lidar com as grandes quantidades de dados gerados diariamente, e muito menos para usar esses dados para tomar decisões de negócios bem informadas.
Os diferentes tipos de bancos de dados refletem as necessidades variadas dos casos de uso e as complexidades dos dados que eles manipulam. Diferentes tipos de bancos de dados são desenvolvidos para otimizar o desempenho, aprimorar a funcionalidade e atender a casos de uso específicos.
Essa variedade não é apenas uma questão de abundância tecnológica, mas também uma necessidade de abordar os desafios e requisitos exclusivos que surgem em diferentes casos de uso. A necessidade de diferentes tipos de bancos de dados decorre das diferenças nas estruturas de dados, nos padrões de acesso, nas demandas de escalabilidade e nos requisitos de consistência.
Por exemplo, os aplicativos comerciais tradicionais geralmente dependem de dados estruturados que se encaixam bem em tabelas com esquemas predefinidos, o que torna os bancos de dados relacionais a escolha ideal.
No entanto, com o surgimento do big data, das redes sociais e da análise em tempo real, ficaram evidentes as limitações dos bancos de dados relacionais para lidar com dados não estruturados, escalonar horizontalmente ou gerenciar dados altamente conectados.
Isso levou ao surgimento dos bancos de dados NoSQL, projetados para oferecer flexibilidade, escalabilidade e vantagens de desempenho para determinados tipos de dados que não se adaptam à estrutura rígida dos bancos de dados tradicionais. Se você quiser saber mais sobre a comparação entre os bancos de dados SQL e NoSQL, confira este tutorial sobre bancos de dados SQL vs. NoSQL.
Da mesma forma, o advento da IoT e de aplicativos sensíveis ao tempo exigiu o desenvolvimento de bancos de dados de séries temporais otimizados para o tratamento eficiente de dados temporais.
Os bancos de dados em nuvem também ganharam destaque, oferecendo escalabilidade e acessibilidade ao hospedar dados em servidores remotos.
Além disso, os bancos de dados vetoriais surgiram para atender às necessidades específicas dos aplicativos de machine learning, armazenando e consultando vetores de alta dimensão com eficiência.
A classificação DB-Engines para maio de 2024 lista os principais sistemas de gerenciamento de banco de dados (DBMS) com base em sua popularidade. Essa classificação é atualizada mensalmente e inclui 420 sistemas. Em maio de 2024, os quatro principais bancos de dados serão todos relacionais: Oracle, MySQL, Microsoft SQL e PostgreSQL.
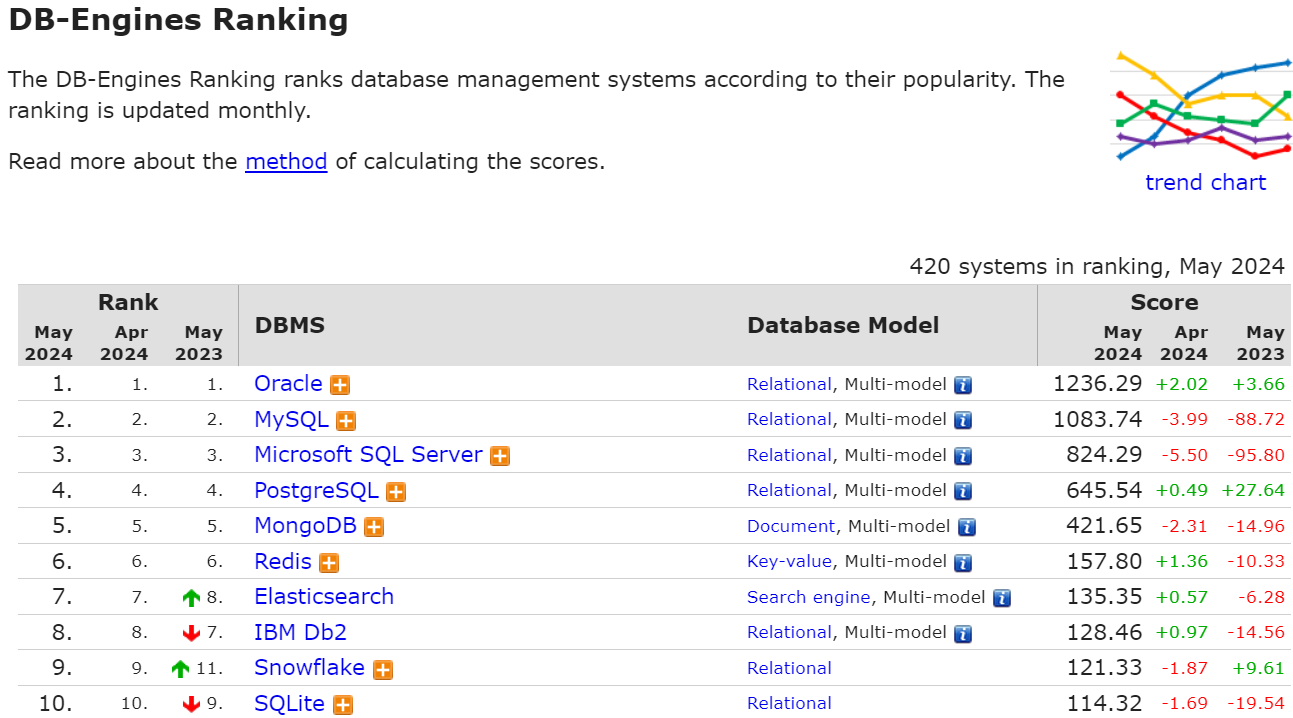
Fonte: db-engines
Vale a pena observar que os bancos de dados NoSQL, como MongoDB e Redis, também ocupam posições fortes na classificação, refletindo a crescente demanda por soluções flexíveis e dimensionáveis capazes de lidar com dados não estruturados e aplicativos de alto tráfego. Esses sistemas NoSQL tiveram um crescimento significativo ano a ano, indicando uma mudança para arquiteturas de banco de dados mais diversificadas.
A classificação também revela a crescente popularidade dos bancos de dados baseados em nuvem, como o Snowflake, que oferece uma solução de data warehouse totalmente gerenciada e dimensionável. O Elasticsearch, um poderoso mecanismo de busca e plataforma de análise, também subiu na classificação, ressaltando a importância dos recursos de busca e análise no gerenciamento moderno de dados.
Vejamos agora o gráfico de linhas abaixo, que ilustra o cenário dinâmico da popularidade do banco de dados de 2014 a 2024.
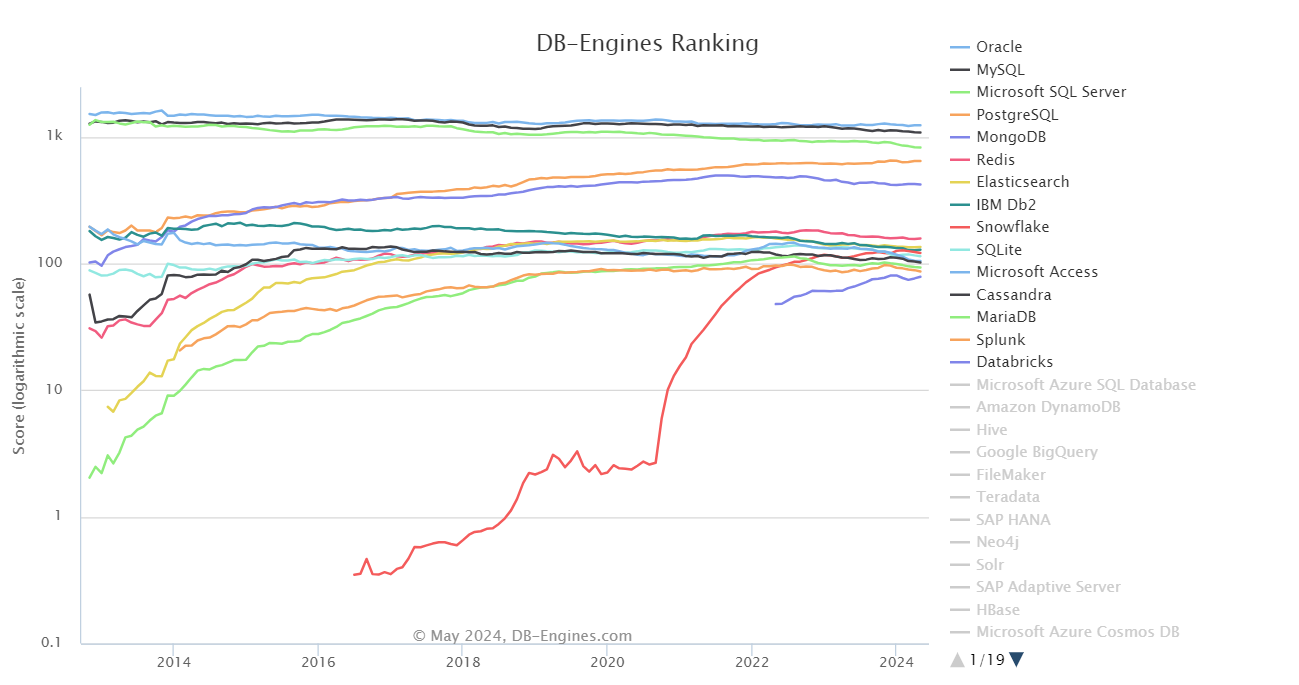
Fonte: db-engines
Uma das principais conclusões é o domínio duradouro dos sistemas de gerenciamento de banco de dados relacionais (RDBMS), como Oracle, MySQL, Microsoft SQL Server e PostgreSQL. Eles mantiveram consistentemente suas posições de destaque ao longo da década, destacando sua importância no tratamento de dados estruturados e no suporte a consultas complexas em vários aplicativos.
No entanto, o gráfico também revela uma mudança notável nos últimos anos. Embora os sistemas RDBMS tenham sofrido um declínio gradual de popularidade, os bancos de dados NoSQL, como MongoDB e Redis, tiveram um crescimento significativo. Essa trajetória ascendente reflete a crescente adoção dessas soluções flexíveis e dimensionáveis para gerenciar dados não estruturados e acomodar aplicativos de alto tráfego.
Outra tendência interessante é o aumento dos bancos de dados baseados em nuvem. A Databricks, uma plataforma de engenharia de dados e machine learning baseada em nuvem, disparou em popularidade, mostrando a crescente demanda por soluções baseadas em nuvem que oferecem escalabilidade, facilidade de uso e recursos analíticos poderosos.
Da mesma forma, o Snowflake, um data warehouse em nuvem totalmente gerenciado, teve um crescimento significativo, destacando o apelo de sua arquitetura escalável e fácil de usar.
Os bancos de dados relacionais armazenam dados em tabelas estruturadas em linhas e colunas. Cada linha representa um registro exclusivo, e cada coluna representa um atributo específico desse registro.
Imagine-os como planilhas meticulosamente organizadas, em que os dados são armazenados em tabelas compostas de linhas (registros) e colunas (atributos). Cada linha representa uma entidade distinta, como um cliente ou um produto, enquanto cada coluna captura uma característica específica, como nome, endereço ou preço.
O verdadeiro poder dos bancos de dados relacionais está em sua capacidade de vincular essas tabelas usando relacionamentos. Essas relações, estabelecidas por meio de chaves estrangeiras, permitem que você conecte dados de diferentes tabelas, criando uma visão unificada das informações.
Por exemplo, em um sistema de gerenciamento de relacionamento com o cliente (CRM), uma tabela de clientes pode estar vinculada a uma tabela de pedidos, o que nos permite rastrear o histórico de compras de um cliente.
Para interagir com bancos de dados relacionais, usamos a SQL (Structured Query Language, linguagem de consulta estruturada). Essa linguagem poderosa permite que você consulte, insira, atualize e exclua dados, além de realizar operações complexas, como unir dados de várias tabelas. A natureza estruturada do SQL garante a integridade e a consistência dos dados por meio das propriedades ACID:
Se você quiser saber mais sobre SQL, confira este programa de sete cursos sobre SQL Fundamentals.
Os bancos de dados relacionais são ótimos quando você precisa:
No entanto, eles podem não ser a melhor opção para você:
Algumas opções populares de RDBMS incluem:
Se você quiser aprender a usar bancos de dados relacionais em Python, confira este curso gratuito sobre Introdução a bancos de dados em Python.
Os bancos de dados NoSQL, abreviação de "not only SQL" (não apenas SQL), surgiram como uma alternativa poderosa aos bancos de dados relacionais, especialmente em cenários em que flexibilidade, escalabilidade e alto desempenho são fundamentais.
Diferentemente de suas contrapartes relacionais, os bancos de dados NoSQL podem lidar com dados não estruturados ou semiestruturados sem as restrições de um esquema fixo. Isso significa que podemos armazenar dados em vários formatos, como documentos JSON, pares de valores-chave ou estruturas de gráficos, sem precisar definir uma estrutura rígida antecipadamente.
Esses bancos de dados geralmente oferecem recursos para escalonamento em vários servidores e clusters, o que os torna adequados para ambientes de dados distribuídos.
Ao contrário dos bancos de dados relacionais, que usam SQL (Structured Query Language, linguagem de consulta estruturada), os bancos de dados NoSQL não têm uma linguagem de consulta universal. Em vez disso, cada tipo de banco de dados NoSQL normalmente tem sua própria linguagem de consulta ou API adaptada ao seu modelo e estrutura de dados específicos.
Embora os bancos de dados NoSQL priorizem a flexibilidade e a escalabilidade, eles geralmente relaxam algumas das propriedades ACID encontradas nos bancos de dados relacionais. Por exemplo, alguns bancos de dados NoSQL priorizam a consistência eventual em relação à consistência imediata, o que significa que as alterações podem não ser refletidas em todos os nós instantaneamente. Essa compensação permite melhor desempenho e escalabilidade, mas exige uma consideração cuidadosa ao projetar aplicativos que dependem de consistência estrita de dados.
Se você quiser aprender a consultar bancos de dados NoSQL, confira este curso de Introdução ao NoSQL.
Os bancos de dados NoSQL são particularmente adequados para cenários em que você pode:
Os casos de uso comuns incluem:
Embora ofereçam vantagens significativas, os bancos de dados NoSQL podem não ser ideais para aplicativos que exigem fortes garantias transacionais ou consultas relacionais complexas. Muitas organizações adotam uma abordagem híbrida, usando bancos de dados relacionais e NoSQL para aproveitar seus respectivos pontos fortes.
Alguns dos bancos de dados NoSQL mais populares incluem:
Se você quiser saber mais sobre os quatro principais bancos de dados NoSQL, confira este curso sobre Conceitos de NoSQL.
Os bancos de dados em nuvem revolucionaram o gerenciamento de dados ao aproveitar os vastos recursos e a escalabilidade das plataformas de computação em nuvem. Esses bancos de dados residem em servidores remotos e são acessados pela Internet, eliminando a necessidade de as organizações investirem e manterem seu próprio hardware e infraestrutura.
Os bancos de dados em nuvem operam em um modelo de pagamento conforme o uso, no qual pagamos apenas pelos recursos que realmente usamos. Isso elimina os custos iniciais e as despesas de manutenção contínuas associadas aos bancos de dados tradicionais no local. Os provedores de nuvem lidam com a infraestrutura subjacente, incluindo servidores, armazenamento e rede, enquanto você se concentra na criação e no gerenciamento de seus aplicativos.
Se você quiser saber mais sobre computação em nuvem, confira este curso sobre Understanding Cloud Computing.
A consulta a bancos de dados na nuvem normalmente envolve o uso das mesmas ferramentas e linguagens que usaríamos com bancos de dados locais. Para bancos de dados relacionais na nuvem, usaríamos SQL para interagir com os dados. Normalmente, os bancos de dados NoSQL na nuvem têm suas próprias linguagens de consulta ou APIs, semelhantes às suas contrapartes locais.
Os provedores de nuvem geralmente oferecem ferramentas e serviços adicionais para simplificar o gerenciamento e a consulta do banco de dados. Isso pode incluir consoles baseados na Web, interfaces de linha de comando e SDKs para várias linguagens de programação.
Os bancos de dados em nuvem são uma excelente opção quando você precisa:
Os principais provedores de nuvem oferecem uma variedade de serviços de banco de dados, cada um com seus próprios pontos fortes e especialidades:
Você pode saber mais sobre bancos de dados na nuvem neste curso sobre a tecnologia e os serviços de nuvem da AWS.
Os bancos de dados vetoriais surgiram como uma ferramenta especializada para lidar com as demandas exclusivas de aplicativos de inteligência artificial e machine learning.
Os bancos de dados vetoriais são projetados para armazenar, indexar e gerenciar embeddings vetoriais, que são representações de dados de alta dimensão usadas com frequência em modelos de machine learning. Isso permite uma pesquisa de similaridade eficiente, em que o banco de dados pode identificar rapidamente os vetores que estão "próximos" de um determinado vetor de consulta com base em métricas de distância, como similaridade de cosseno ou distância euclidiana.
Esses recursos os tornam adequados para aplicações como reconhecimento de imagens, sistemas de recomendação e processamento de linguagem natural. Eles utilizam estruturas de indexação que otimizam a recuperação de vetores semelhantes com base em métricas de distância.
Se quiser saber mais sobre bancos de dados vetoriais, você pode ler este artigo: Uma introdução aos bancos de dados vetoriais para machine learning.
Normalmente, a consulta a um banco de dados de vetores envolve as seguintes etapas:
Diferentes bancos de dados de vetores podem oferecer várias opções e parâmetros de consulta, como a especificação do número de vizinhos mais próximos a serem retornados ou a definição de um limite de distância. Alguns bancos de dados também suportam filtragem com base em metadados ou combinam a pesquisa vetorial com a filtragem escalar tradicional.
Os bancos de dados vetoriais são particularmente adequados para cenários em que:
Se você quiser saber mais sobre quais são os bancos de dados populares, consulte este artigo sobre os 5 melhores bancos de dados vetoriais.
Embora os bancos de dados relacionais, NoSQL, em nuvem e vetoriais cubram uma ampla gama de casos de uso, existem vários outros tipos de banco de dados, cada um adaptado a modelos de dados e padrões de acesso específicos. Vamos explorar brevemente algumas dessas soluções especializadas.
Os bancos de dados de séries temporais são otimizados para armazenar e analisar dados com registro de data e hora, como leituras de sensores, preços de ações ou registros de servidores. Eles são excelentes para lidar com a ingestão de grandes volumes de dados e consultar pontos de dados com eficiência com base em intervalos de tempo. As opções mais populares incluem o InfluxDB, o TimescaleDB e o Prometheus.
Os bancos de dados orientados a objetos (OODBs) armazenam dados como objetos, de forma semelhante à programação orientada a objetos. Isso pode simplificar a modelagem de estruturas de dados e relacionamentos complexos. No entanto, os OODBs não foram amplamente adotados devido a desafios com a padronização e a otimização de consultas. As opções mais populares incluem o ObjectDB e o Versant Object Database.
Os bancos de dados de gráficos são excelentes para representar e consultar relacionamentos entre entidades. Eles armazenam dados como nós (entidades) e bordas (relacionamentos), o que os torna adequados para redes sociais, mecanismos de recomendação, sistemas de detecção de fraudes e gráficos de conhecimento. As opções mais populares incluem Neo4j, Amazon Neptune e JanusGraph.
Os bancos de dados hierárquicos organizam os dados em uma estrutura semelhante a uma árvore, com relacionamentos pai-filho entre os registros. Essa estrutura é adequada para alguns aplicativos especializados, mas pode ser inflexível para modelos de dados complexos. Embora historicamente significativos, os bancos de dados hierárquicos são menos comuns nos aplicativos modernos.
Os bancos de dados em rede são semelhantes aos bancos de dados hierárquicos, mas permitem relacionamentos mais complexos entre os registros. Embora ofereçam flexibilidade, também podem ser mais difíceis de gerenciar e consultar. Os bancos de dados de rede foram amplamente substituídos por bancos de dados relacionais e de gráficos na maioria dos aplicativos.
Nesta visão geral, exploramos o cenário diversificado de bancos de dados, cada tipo adaptado para enfrentar desafios específicos de dados. Desde dados estruturados em bancos de dados relacionais até a flexibilidade do NoSQL, a escalabilidade das soluções em nuvem e os recursos especializados dos bancos de dados vetoriais, vimos como essas ferramentas sustentam o gerenciamento de dados moderno.
A escolha do banco de dados correto é uma decisão crítica, que depende da compreensão dos pontos fortes e das vantagens e desvantagens exclusivas de cada tipo. Ao avaliar cuidadosamente suas necessidades e restrições específicas, você pode selecionar o banco de dados que melhor capacita seus aplicativos e iniciativas orientados por dados.
Se quiser saber mais detalhes sobre bancos de dados, você pode experimentar este programa de quatro cursos sobre SQL para administradores de banco de dados.
Saiba mais sobre bancos de dados!
Programa
Curso
Curso
blog
Zoumana Keita
12 min
blog
Kurtis Pykes
11 min
blog
Summer Worsley
13 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal

