Programa
Desenvolvimento de modelos de idiomas grandes
16 h
O RAG (Retrieval Augmented Generation) é um método que combina LLMs com sistemas de recuperação de informações. Isso significa que, quando um LLM é solicitado a gerar texto, ele pode extrair informações relevantes de fontes externas, tornando suas respostas mais precisas e informadas.
O RAG consiste em dois componentes principais, o retriever e o gerador, e um componente opcional, o reranker:
O RankGPT usa LLMs para avaliar a relevância de documentos ou segmentos de texto recuperados, garantindo que os mais importantes estejam no topo. Com o RankGPT, o gerador no pipeline RAG obtém as entradas de maior qualidade, resultando em respostas mais precisas.
O RankGPT vai além da simples correspondência de palavras-chave, compreendendo o significado e o contexto mais profundos das consultas e dos documentos. Isso permite que ele forneça informações mais precisas para os LLMs, identificando o conteúdo mais relevante com base em seu significado real, e não apenas em palavras-chave.
Ao usar o GPT-4 com geração de permutação instrucional de disparo zero, o RankGPT supera o desempenho dos principais sistemas supervisionados em vários benchmarks como TREC, BEIR e Mr.TyDi.
O RankGPT usa permutação destilação para transferir as capacidades de classificação de modelos grandes, como o GPT-4, para modelos menores e especializados.
Esses modelos menores mantêm o alto desempenho e são muito mais eficientes. Por exemplo, um modelo 440M destilado superou um modelo supervisionado 3B no benchmark BEIR, reduzindo os custos computacionais reduzindo significativamente os custos computacionais e obtendo melhores resultados.
O RankGPT inclui o conjunto de testes NovelEval para garantir a robustez e resolver problemas de contaminação de dados. Esse conjunto avalia a capacidade do modelo de classificar passagens com base em informações recentes e desconhecidas.
O GPT-4 obteve um desempenho de ponta nesse teste, demonstrando sua capacidade de lidar efetivamente com consultas novas e inéditas.
O RankGPT (gpt-4) supera todos os outros modelos no TREC e no BEIR, com uma pontuação média de nDCG@10 de 53,68, conforme mostrado na tabela abaixo. Ele obteve os melhores resultados nos conjuntos de dados BEIR, superando modelos supervisionados fortes, como o monoT5 (3B) e o Cohere Rerank-v2. Mesmo com o gpt-3.5-turbo, o RankGPT tem uma pontuação competitiva, provando que é um reranker altamente eficaz.
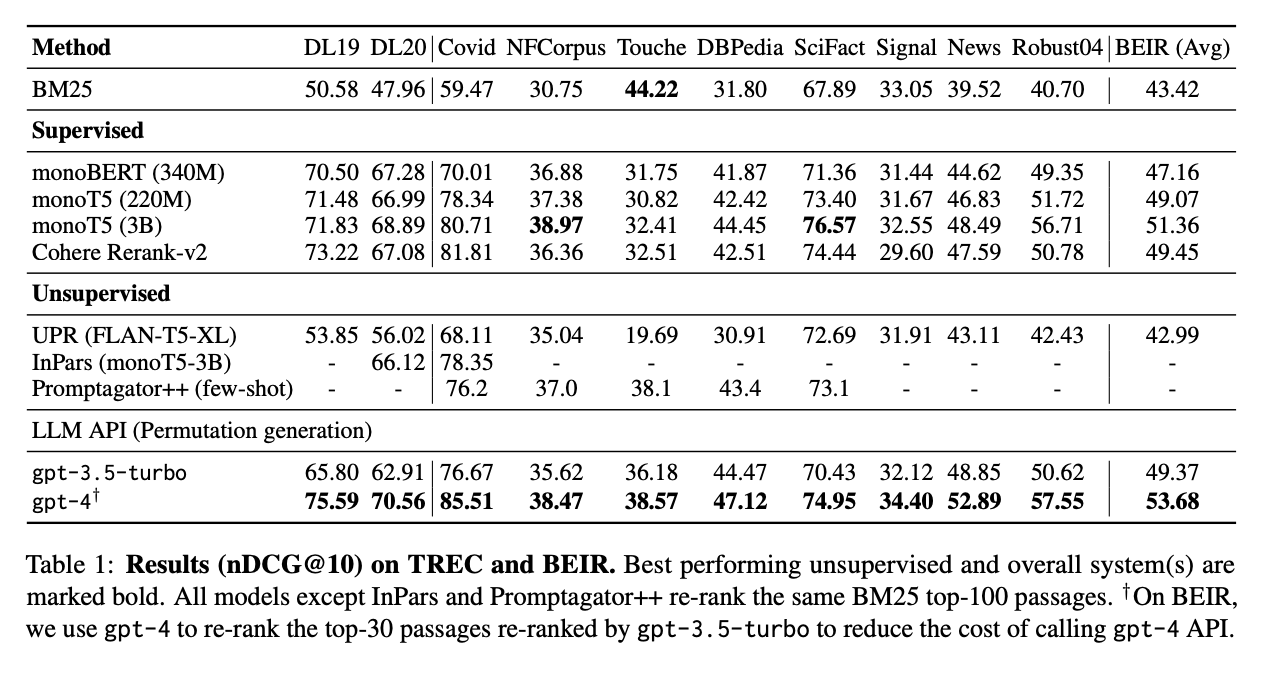
Fonte: Weiwei Sun et al., 2023
O RankGPT (gpt-4) também apresenta um bom desempenho nos conjuntos de dados Mr.TyDi, liderando com uma pontuação média nDCG@10 de 62,93, superando o BM25 e o mmarcoCE. Ele supera consistentemente o BM25 e até mesmo o mmarcoCE em muitos idiomas, especialmente em indonésio e swahili.
No geral, o RankGPT obteve a melhor pontuação em muitos idiomas, como bengali, indonésio e japonês, com apenas alguns casos em que ficou um pouco atrás do mmarcoCE.
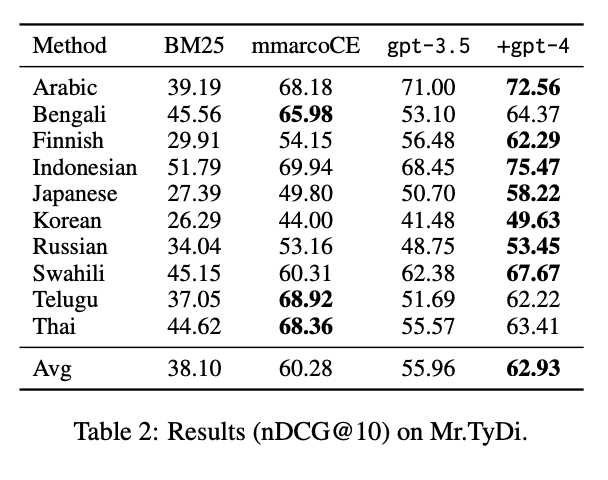
Fonte: Weiwei Sun et al., 2023
Por fim, o RankGPT foi testado no conjunto de dados NovelEval, que mede a capacidade de um modelo de classificar passagens com base em informações recentes e desconhecidas. O RankGPT (gpt-4) obteve a maior pontuação em todas as métricas de avaliação (nDCG@1, nDCG@5 e nDCG@10), especialmente com a pontuação nDCG@10 de 90,45. Ele superou outros modelos fortes, como o monoT5 (3B) e o monoBERT (340M), o que destaca seu bom desempenho como reranker.
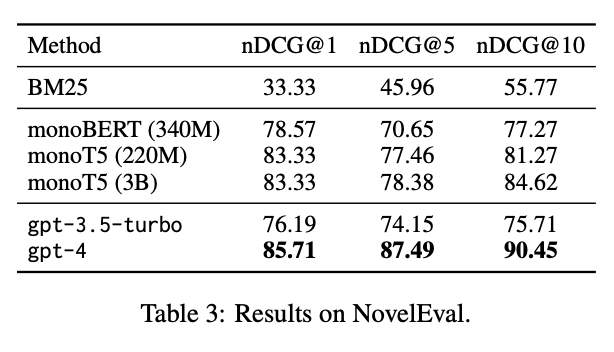
Fonte: Weiwei Sun et al., 2023
Em todos os resultados de benchmark, o RankGPT (gpt-4) supera consistentemente outros métodos, sejam eles supervisionados ou não supervisionados, demonstrando sua capacidade superior de reranking.
Veja como podemos integrar o RankGPT em um pipeline RAG.
Primeiro, você precisará clonar o repositório RankGPT. Execute o seguinte comando em seu terminal:
git clone https://github.com/sunnweiwei/RankGPTNavegue até o diretório do RankGPT e instale os pacotes necessários. Talvez você queira criar um ambiente virtual e instalar pacotes usando osrequisitos fornecidos em .txt:
pip install -r requirements.txtAqui, estamos usando o exemplo simplista de consulta e documentos recuperados fornecidos pelo repositório RankGPT original.
item = {
'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [
{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'}
]
}Você pode usar o pipeline de permutação fornecido para ranquear facilmente os documentos recuperados com o RankGPT.
from rank_gpt import permutation_pipeline
new_item = permutation_pipeline(
item,
rank_start=0,
rank_end=3,
model_name='gpt-3.5-turbo',
api_key='Your OPENAI Key!'
)
print(new_item)Isso resultará na seguinte nova ordem de documentos:
{
'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [
{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'}
]
}Para obter uma implementação mais detalhada do pipeline de permutação, você pode interagir diretamente com o RankGPT para criar e processar instruções de permutação da seguinte forma:
from rank_gpt import (
create_permutation_instruction,
run_llm,
receive_permutation
)
# Create permutation generation instruction
messages = create_permutation_instruction(
item=item,
rank_start=0,
rank_end=3,
model_name='gpt-3.5-turbo'
)[{'role': 'system',
'content': 'You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.'},
{'role': 'user',
'content': 'I will provide you with 3 passages, each indicated by number identifier []. \\nRank the passages based on their relevance to query: How much impact do masks have on preventing the spread of the COVID-19?.'},
{'role': 'assistant', 'content': 'Okay, please provide the passages.'},
{'role': 'user',
'content': '[1] Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'role': 'assistant', 'content': 'Received passage [1].'},
{'role': 'user',
'content': '[2] Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'},
{'role': 'assistant', 'content': 'Received passage [2].'},
{'role': 'user',
'content': '[3] Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'role': 'assistant', 'content': 'Received passage [3].'},
{'role': 'user',
'content': 'Search Query: How much impact do masks have on preventing the spread of the COVID-19?. \\nRank the 3 passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain.'}]# Get ChatGPT predicted permutation
permutation = run_llm(
messages,
api_key='Your OPENAI Key!',
model_name='gpt-3.5-turbo'
)'[1] > [3] > [2]'# Use permutation to re-rank the passage
item = receive_permutation(
item,
permutation,
rank_start=0,
rank_end=3
){'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'}]}Se você precisar classificar mais documentos do que o modelo pode processar de uma só vez, use uma estratégia de janela deslizante. Veja como aplicar uma estratégia de janela deslizante para classificar novamente os documentos:
from rank_gpt import sliding_windows
api_key = "Your OPENAI Key"
new_item = sliding_windows(
item,
rank_start=0,
rank_end=3,
window_size=2,
step=1,
model_name='gpt-3.5-turbo',
api_key=api_key
)
print(new_item)Neste exemplo, a janela deslizante tem um tamanho de 2 e um tamanho de etapa de 1, o que significa que ela processa dois documentos de cada vez, avançando um documento para a próxima passagem de classificação.
Ao usar LLMs para avaliar melhor a relevância das informações, o RankGPT aumenta a precisão da classificação e da reclassificação do conteúdo.
Isso aborda problemas comuns, como garantir que o conteúdo esteja no ponto, melhorar a eficiência e reduzir a probabilidade de gerar informações enganosas.
De modo geral, o RankGPT contribui para a criação de aplicativos RAG mais confiáveis e precisos.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Javier Canales Luna
14 min
blog
Nisha Arya Ahmed
10 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali


