
Track
Developing Large Language Models
16 hr
Retrieval augmented generation (RAG) is a method that combines LLMs with information retrieval systems. This means that when an LLM is asked to generate text, it can pull in relevant information from external sources, making its responses more accurate and informed.
RAG consists of two main components—the retriever and the generator—and an optional component, the reranker:
RankGPT uses LLMs to evaluate the relevance of retrieved documents or text segments, ensuring the most important ones are at the top. With RankGPT, the generator in the RAG pipeline gets the higher-quality inputs, resulting in more accurate responses.
RankGPT goes beyond simple keyword matching by understanding the deeper meaning and context of queries and documents. This allows it to provide more accurate information for LLMs, identifying the most relevant content based on its actual meaning, not just keywords.
When using GPT-4 with zero-shot instructional permutation generation, RankGPT outperforms leading supervised systems on various benchmarks like TREC, BEIR, and Mr.TyDi.
RankGPT uses permutation distillation to transfer the ranking abilities of large models like GPT-4 into smaller, specialized models.
These smaller models maintain high performance while being much more efficient. For example, a distilled 440M model outperformed a 3B supervised model on the BEIR benchmark, reducing computational costs significantly while achieving better results.
RankGPT includes the NovelEval test set to ensure robustness and address data contamination concerns. This set evaluates the model's ability to rank passages based on recent and unknown information.
GPT-4 achieved state-of-the-art performance on this test, demonstrating its ability to effectively handle new and unseen queries.
RankGPT (gpt-4) outperforms all other models across TREC and BEIR, with an average nDCG@10 score of 53.68 as shown in the table below. It scored the highest results in the BEIR datasets, beating strong supervised models like monoT5 (3B) and Cohere Rerank-v2. Even with gpt-3.5-turbo, RankGPT scores competitively, proving that it’s a highly effective reranker.
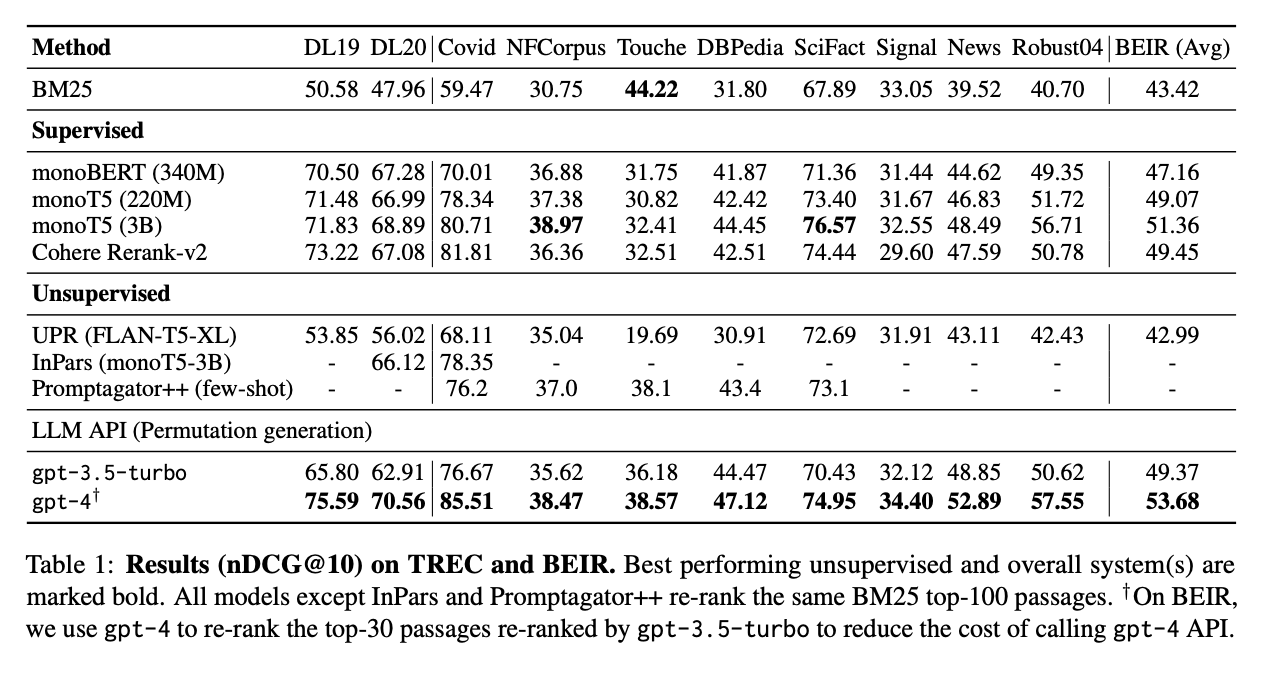
Source: Weiwei Sun et al., 2023
RankGPT (gpt-4) also performs strongly on the Mr.TyDi datasets, leading with an average nDCG@10 score of 62.93, beating both BM25 and mmarcoCE. It consistently outperforms BM25 and even surpasses mmarcoCE in many languages, especially in Indonesian and Swahili.
Overall, RankGPT scored highest in many languages, like Bengali, Indonesian, and Japanese, with only a few cases where it slightly lagged behind mmarcoCE.
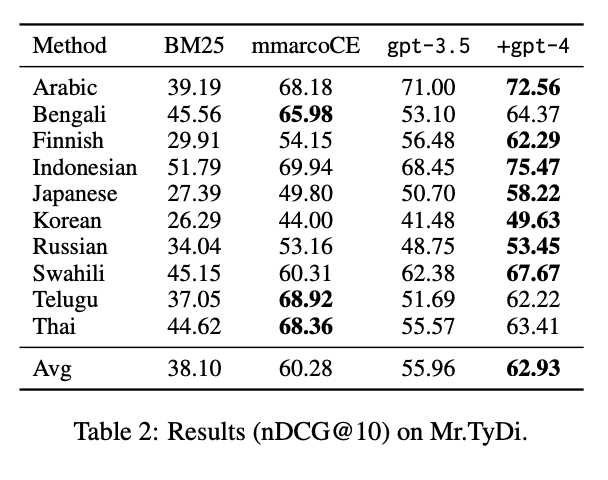
Source: Weiwei Sun et al., 2023
Lastly, RankGPT was tested on the NovelEval dataset, which measures how well a model can rank passages based on recent and unfamiliar information. RankGPT (gpt-4) scored the highest in all evaluation metrics (nDCG@1, nDCG@5, and nDCG@10), especially with the nDCG@10 score of 90.45. It outperformed other strong models like monoT5 (3B) and monoBERT (340M), which highlights its strong performance as a reranker.
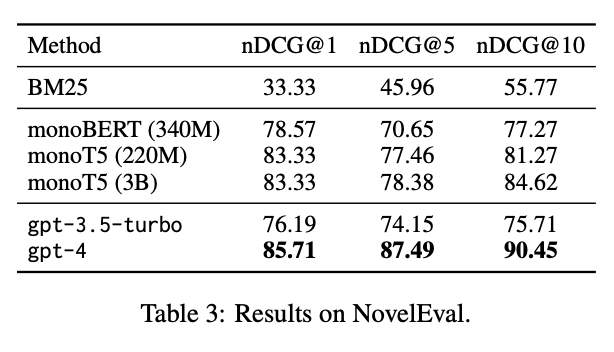
Source: Weiwei Sun et al., 2023
Across all the benchmark results, RankGPT (gpt-4) consistently outperforms other methods, whether it’s supervised or unsupervised, demonstrating its superior ability in reranking.
Here’s how we can integrate RankGPT into a RAG pipeline.
First, you'll need to clone the RankGPT repository. Run the following command in your terminal:
git clone https://github.com/sunnweiwei/RankGPTNavigate to the RankGPT directory and install the required packages. You may want to create a virtual environment and install packages using the provided requirements.txt :
pip install -r requirements.txtHere, we are using the simplistic example query and retrieved documents provided by the original RankGPT repository.
item = {
'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [
{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'}
]
}You can use the provided permutation pipeline to easily rerank the retrieved documents with RankGPT.
from rank_gpt import permutation_pipeline
new_item = permutation_pipeline(
item,
rank_start=0,
rank_end=3,
model_name='gpt-3.5-turbo',
api_key='Your OPENAI Key!'
)
print(new_item)This will result in the following new order of documents:
{
'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [
{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'}
]
}For a more step-by-step implementation of the permutation pipeline, you can directly interact with RankGPT to create and process permutation instructions as follows:
from rank_gpt import (
create_permutation_instruction,
run_llm,
receive_permutation
)
# Create permutation generation instruction
messages = create_permutation_instruction(
item=item,
rank_start=0,
rank_end=3,
model_name='gpt-3.5-turbo'
)[{'role': 'system',
'content': 'You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.'},
{'role': 'user',
'content': 'I will provide you with 3 passages, each indicated by number identifier []. \\nRank the passages based on their relevance to query: How much impact do masks have on preventing the spread of the COVID-19?.'},
{'role': 'assistant', 'content': 'Okay, please provide the passages.'},
{'role': 'user',
'content': '[1] Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'role': 'assistant', 'content': 'Received passage [1].'},
{'role': 'user',
'content': '[2] Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'},
{'role': 'assistant', 'content': 'Received passage [2].'},
{'role': 'user',
'content': '[3] Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'role': 'assistant', 'content': 'Received passage [3].'},
{'role': 'user',
'content': 'Search Query: How much impact do masks have on preventing the spread of the COVID-19?. \\nRank the 3 passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain.'}]# Get ChatGPT predicted permutation
permutation = run_llm(
messages,
api_key='Your OPENAI Key!',
model_name='gpt-3.5-turbo'
)'[1] > [3] > [2]'# Use permutation to re-rank the passage
item = receive_permutation(
item,
permutation,
rank_start=0,
rank_end=3
){'query': 'How much impact do masks have on preventing the spread of the COVID-19?',
'hits': [{'content': 'Title: Universal Masking is Urgent in the COVID-19 Pandemic: SEIR and Agent Based Models, Empirical Validation, Policy Recommendations Content: We present two models for the COVID-19 pandemic predicting the impact of universal face mask wearing upon the spread of the SARS-CoV-2 virus--one employing a stochastic dynamic network based compartmental SEIR (susceptible-exposed-infectious-recovered) approach, and the other employing individual ABM (agent-based modelling) Monte Carlo simulation--indicating (1) significant impact under (near) universal masking when at least 80% of a population is wearing masks, versus minimal impact when only 50% or less of the population is wearing masks, and (2) significant impact when universal masking is adopted early, by Day 50 of a regional outbreak, versus minimal impact when universal masking is adopted late. These effects hold even at the lower filtering rates of homemade masks. To validate these theoretical models, we compare their predictions against a new empirical data set we have collected'},
{'content': 'Title: To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic Content: Face mask use by the general public for limiting the spread of the COVID-19 pandemic is controversial, though increasingly recommended, and the potential of this intervention is not well understood. We develop a compartmental model for assessing the community-wide impact of mask use by the general, asymptomatic public, a portion of which may be asymptomatically infectious. Model simulations, using data relevant to COVID-19 dynamics in the US states of New York and Washington, suggest that broad adoption of even relatively ineffective face masks may meaningfully reduce community transmission of COVID-19 and decrease peak hospitalizations and deaths. Moreover, mask use decreases the effective transmission rate in nearly linear proportion to the product of mask effectiveness (as a fraction of potentially infectious contacts blocked) and coverage rate (as'},
{'content': 'Title: Masking the general population might attenuate COVID-19 outbreaks Content: The effect of masking the general population on a COVID-19 epidemic is estimated by computer simulation using two separate state-of-the-art web-based softwares, one of them calibrated for the SARS-CoV-2 virus. The questions addressed are these: 1. Can mask use by the general population limit the spread of SARS-CoV-2 in a country? 2. What types of masks exist, and how elaborate must a mask be to be effective against COVID-19? 3. Does the mask have to be applied early in an epidemic? 4. A brief general discussion of masks and some possible future research questions regarding masks and SARS-CoV-2. Results are as follows: (1) The results indicate that any type of mask, even simple home-made ones, may be effective. Masks use seems to have an effect in lowering new patients even the protective effect of each mask (here dubbed"one-mask protection") is'}]}If you need to rank more documents than the model can handle at once, use a sliding window strategy. Here’s how to apply a sliding window strategy to re-rank documents:
from rank_gpt import sliding_windows
api_key = "Your OPENAI Key"
new_item = sliding_windows(
item,
rank_start=0,
rank_end=3,
window_size=2,
step=1,
model_name='gpt-3.5-turbo',
api_key=api_key
)
print(new_item)In this example, the sliding window has a size of 2 and a step size of 1, meaning it processes two documents at a time, moving one document forward for the next ranking pass.
By using LLMs to better assess the relevance of information, RankGPT enhances the accuracy of sorting and re-ranking content.
This addresses common issues such as ensuring content is on point, improving efficiency, and reducing the likelihood of generating misleading information.
Overall, RankGPT contributes to building more reliable and accurate RAG applications.
Learn AI with these courses!
Track
Course
Course
blog
Natassha Selvaraj
10 min
Tutorial
Iván Palomares Carrascosa
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
Eugenia Anello
code-along
Yujian Tang

