
Curso
Introdução à Engenharia de Dados
4 h
127.6K
Muitas empresas modernas dependem de camadas semânticas para preencher a lacuna entre os dados brutos armazenados em data warehouses como o Snowflake e os insights em painéis ou relatórios.
Uma camada semântica é uma abstração que define métricas, medidas e dimensões consistentes para análises e relatórios.
Neste tutorial, exploraremos como implementar uma camada semântica usando o dbt (data build tool), uma estrutura popular de transformação e modelagem de dados. Este guia inclui exemplos práticos e insights para ajudar você a dominar o conceito.
Uma camada semântica converte dados brutos em métricas e dimensões consistentes e reutilizáveis, simplificando a análise de dados. É uma ferramenta para manter a uniformidade entre equipes e ferramentas.
Vamos ver o que torna o dbt a ferramenta perfeita para permitir que os engenheiros de dados e análise criem uma camada semântica.
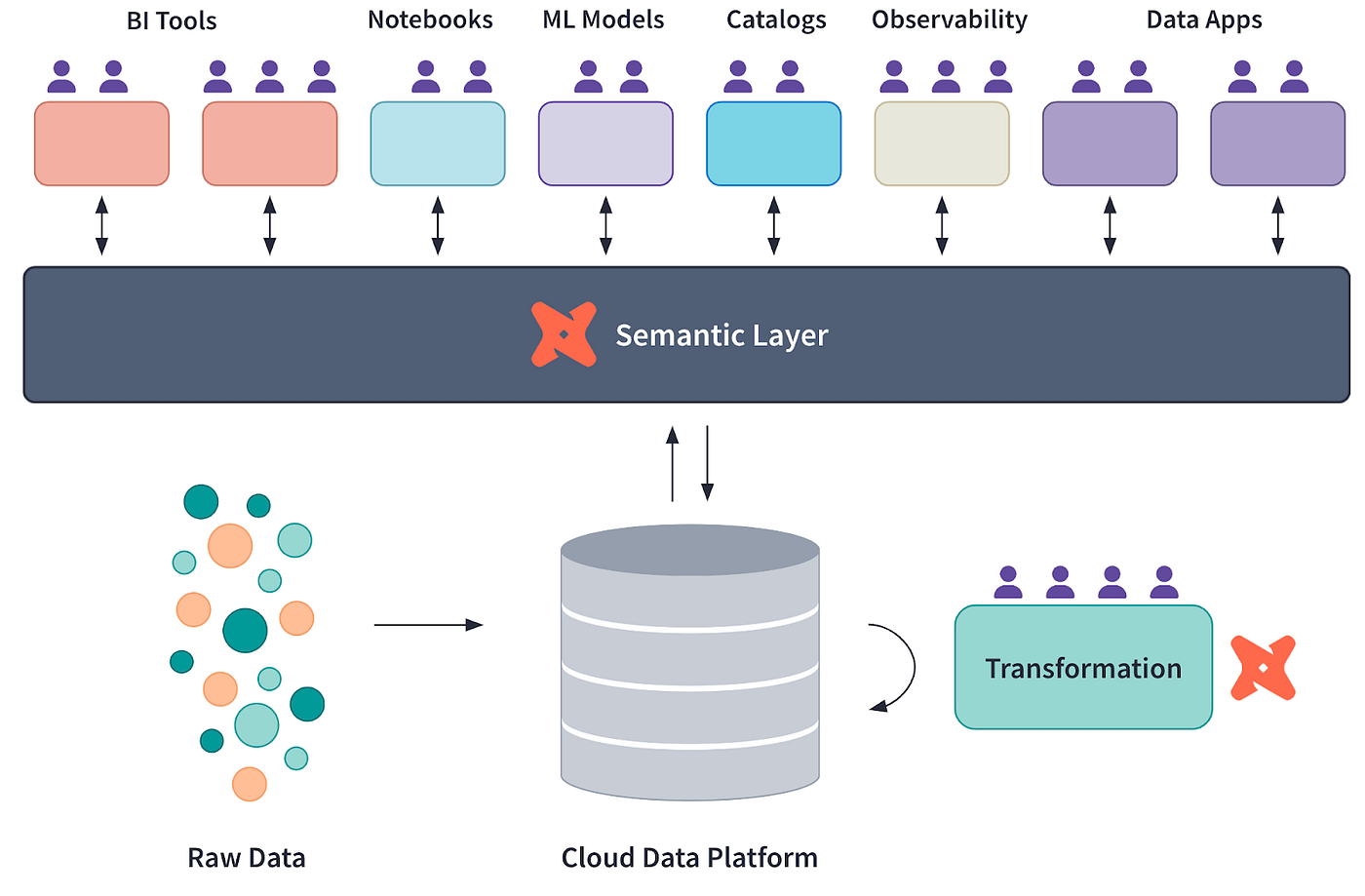
Diagrama conceitual da camada semântica da dbt, cuprtesy of dbt Labs
O dbt permite que você divida transformações complexas de dados em modelos modulares reutilizáveis. Esses modelos podem ser dispostos em camadas hierárquicas, onde os modelos de dados fundamentais alimentam os modelos analíticos de nível superior.
Essa abordagem torna o pipeline sustentável e permite que as equipes colaborem com mais eficiência, isolando as alterações em modelos específicos sem afetar todo o sistema.
Para saber mais sobre os conceitos básicos e as práticas recomendadas do dbt para modelagem de dados, consulte o tutorial dbt: 7 Conceitos que você deve saber para engenheiros de dados. Ele oferece percepções que complementam as estratégias descritas aqui.
Com o dbt, a lógica comercial e as métricas são definidas em um único local, garantindo a consistência em várias ferramentas de análise. Ao usar o recurso de métricas do dbt, você pode definir KPIs como receita, taxas de conversão ou rotatividade uma vez e usá-los em painéis, relatórios e análises sem redefinição. Isso reduz as discrepâncias e garante a integridade dos dados.
A integração do dbtcom o Git facilita o controle de versão robusto, permitindo que você rastreie e audite as alterações ao longo do tempo. Juntamente com a documentação gerada automaticamente, o dbt cria uma referência viva e acessível para todas as transformaçõese métricas de dados. Isso resulta em transparência e permite que novos membros da equipe se integrem rapidamente, explorando o pipeline de dados documentado.
O dbt funciona com plataformas de BI, como Looker, Tableau e Mode, permitindo a integração da camada semântica em ferramentas de visualização. Usando as exposições dbt, você pode vincular diretamente os modelos dbt aos painéis de BI, garantindo que todas as atualizações nos modelos de dados sejam refletidas na análise sem intervenção manual.
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Joleen Bothma
7 min
blog
Kurtis Pykes
11 min
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Joleen Bothma
Tutorial
Oluseye Jeremiah

