
Course
Introduction to Data Engineering
4 hr
127.6K
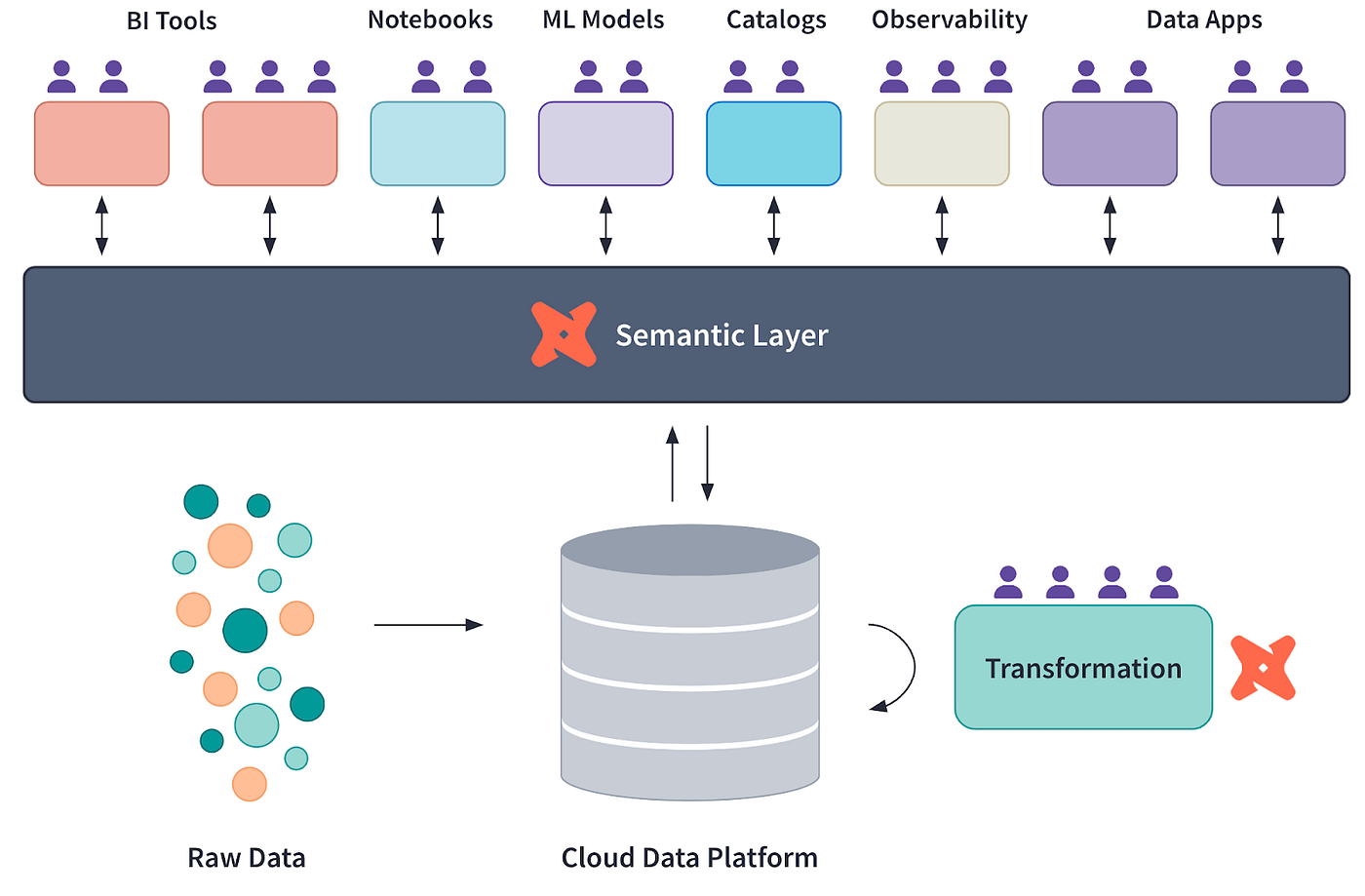
Many modern companies rely on semantic layers to bridge the gap between raw data stored in data warehouses like Snowflake and insights in dashboards or reports.
A semantic layer is an abstraction that defines consistent metrics, measures, and dimensions for analytics and reporting.
In this tutorial, we will explore how to implement a semantic layer using dbt (data build tool), a popular data transformation and modeling framework. This guide includes practical examples and insights to help you master the concept.
A semantic layer translates raw data into consistent, reusable metrics and dimensions, simplifying data analysis. It is a tool for maintaining uniformity across teams and tools.
Let’s see what makes dbt the perfect tool for enabling data and analytics engineers to build a semantic layer.
dbt Semantic Layer conceptual diagram, courtesy of dbt Labs
dbt allows you to break down complex data transformations into reusable, modular models. These models can be layered hierarchically, where foundational data models feed into higher-level analytical ones.
This approach makes the pipeline maintainable and enables teams to collaborate more effectively by isolating changes to specific models without impacting the entire system.
To learn more about dbt’s foundational concepts and best practices for data modeling, check out the dbt Tutorial: 7 Must-Know Concepts for Data Engineers. It offers insights that complement the strategies outlined here.
With dbt, business logic and metrics are defined in one place, ensuring consistency across various analytics tools. By using dbt’s metrics feature, you can define KPIs like revenue, conversion rates, or churn once and use them across dashboards, reports, and analyses without redefinition. This reduces discrepancies and ensures data integrity.
dbt’s integration with Git facilitates robust version control, enabling you to track and audit changes over time. Coupled with its auto-generated documentation, dbt creates a living, accessible reference for all data transformations and metrics. This results in transparency and allows new team members to onboard quickly by exploring the documented data pipeline.
dbt works with BI platforms such as Looker, Tableau, and Mode, allowing for integration of the semantic layer into visualization tools. Using dbt exposures, you can directly link dbt models to BI dashboards, ensuring that any updates in the data models are reflected in the analytics without manual intervention.
Learn more about data engineering with these courses!
Course
Course
Course
blog
Laiba Siddiqui
8 min
blog
Joleen Bothma
7 min
blog
Austin Chia
12 min
Tutorial
Mike Shakhomirov
Tutorial
Allan Ouko
Tutorial
Bex Tuychiev

