
Curso
Introducción a la ingeniería de datos
4 h
127.6K
Muchas empresas modernas confían en las capas semánticas para salvar la distancia entre los datos brutos almacenados en almacenes de datos como Snowflake y las percepciones en cuadros de mando o informes.
Una capa semántica es una abstracción que define métricas, medidas y dimensiones coherentes para el análisis y la elaboración de informes.
En este tutorial, exploraremos cómo implementar una capa semántica utilizando dbt (data build tool), un popular marco de transformación y modelado de datos. Esta guía incluye ejemplos prácticos y reflexiones que te ayudarán a dominar el concepto.
Una capa semántica traduce los datos brutos en métricas y dimensiones coherentes y reutilizables, simplificando el análisis de los datos. Es una herramienta para mantener la uniformidad entre equipos y herramientas.
Veamos qué hace que dbt sea la herramienta perfecta para que los ingenieros de datos y analítica construyan una capa semántica.
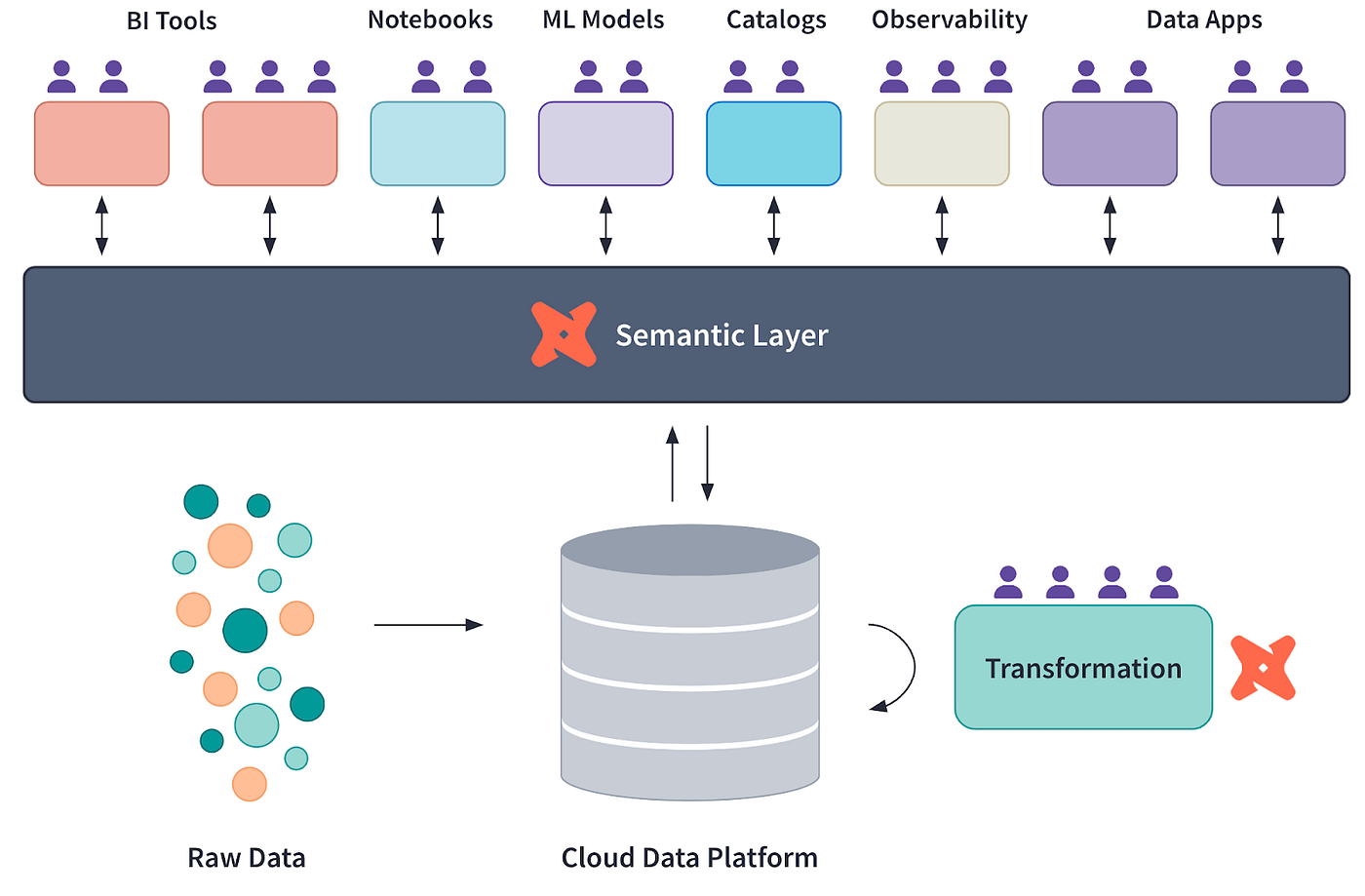
Diagrama conceptual de la Capa Semántica dbt, courtesía de dbt Labs
dbt te permite descomponer transformaciones de datos complejas en modelos modulares reutilizables. Estos modelos se pueden estratificar jerárquicamente, de forma que los modelos de datos fundamentales alimenten a los analíticos de nivel superior.
Este enfoque hace que el pipeline sea mantenible y permite a los equipos colaborar más eficazmente aislando los cambios en modelos específicos sin que afecten a todo el sistema.
Para saber más sobre los conceptos básicos de dbt y las mejores prácticas para el modelado de datos, consulta el Tutorial de dbt de: 7 Conceptos imprescindibles para los ingenieros de datos. Ofrece ideas que complementan las estrategias aquí expuestas.
Con dbt, la lógica empresarial y las métricas se definen en un único lugar, lo que garantiza la coherencia entre varias herramientas de análisis. Con la función de métricas de dbt, puedes definir una vez los KPI, como ingresos, tasas de conversión o rotación, y utilizarlos en cuadros de mando, informes y análisis sin necesidad de redefinirlos. Esto reduce las discrepancias y garantiza la integridad de los datos.
La integración de dbtcon Git facilita un sólido control de versiones, permitiéndote seguir y auditar los cambios a lo largo del tiempo. Junto con su documentación autogenerada, dbt crea una referencia viva y accesible para todas las transformaciones de datosns y métricas. Esto aporta transparencia y permite que los nuevos miembros del equipo se incorporen rápidamente explorando la canalización de datos documentada.
dbt funciona con plataformas de BI como Looker, Tableau y Mode, lo que permite integrar la capa semántica en las herramientas de visualización. Mediante las exposiciones dbt, puedes vincular directamente los modelos dbt a los cuadros de mando BI, garantizando que cualquier actualización en los modelos de datos se refleje en los análisis sin intervención manual.
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
7 min
blog
Mike Shakhomirov
11 min
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma
Tutorial
Oluseye Jeremiah

