course
Manipularea datelor în SQL
4 oră
324.1K
Ai observat vreodată că MySQL este cerut în aproape orice fișă de post legată de baze de date? Există un motiv bun pentru asta — MySQL alimentează practic totul, de la platformele tale preferate de social media până la aplicațiile pe care le folosești zilnic.
Am creat acest ghid ca să te ajut să abordezi întrebările din interviurile MySQL. Acopăr totul, de la elementele de bază pe care ar trebui să le cunoască dezvoltatorii juniori până la aspectele complexe cerute pentru rolurile de senior. De asemenea, împărtășesc câteva sfaturi care te vor ajuta să te prezinți ca un candidat încrezător în următoarele tale interviuri legate de date.
MySQL este un SGBD relațional open-source (relational database management system) construit pe SQL, care organizează datele în tabele structurate. A fost dezvoltat de Oracle Corporation.
A fost clasat drept cel mai popular SGBD în 2024. Totuși, un sondaj Stack Overflow Developer din 2025 a arătat că PostgreSQL s-a clasat drept cea mai utilizată bază de date în rândul dezvoltatorilor profesioniști, depășind pentru prima dată MySQL.
Nu mă înțelege greșit: MySQL este în continuare extrem de popular — ajungând la 40,5% utilizare în rândul dezvoltatorilor în 2025 — și alimentează încă nenumărate aplicații web, sisteme de gestionare a conținutului și instrumente pentru companii. Iar mai ales dacă lucrezi cu aplicații web sau cu stack-ul LAMP, MySQL este o abilitate de top.
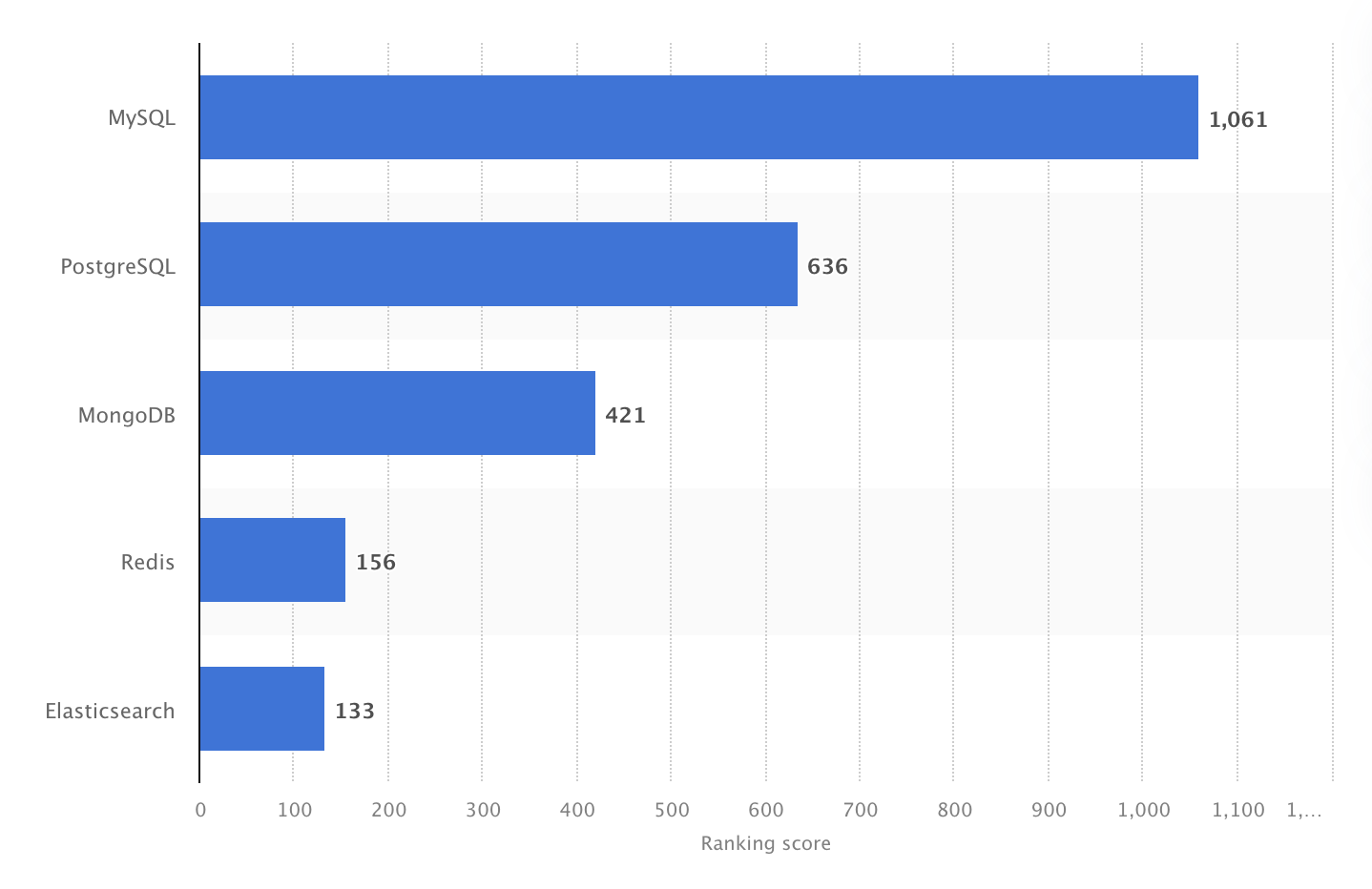
În 2024, MySQL a fost cel mai popular SGBD open-source din lume, cu un scor de 1061. Sursa: Statista.
În faza inițială a interviului, intervievatorul îți poate pune întrebări fundamentale ca să îți evalueze înțelegerea conceptelor de bază despre baze de date și MySQL.
O bază de date este un container de stocare care conține date la care putem accesa, pe care le putem modifica și analiza. De exemplu, platformele de social media stochează în baze de date informații despre cine a apreciat postările noastre.
Un SGBD (Sistem de Gestiune a Bazelor de Date) este software-ul care ne permite să interacționăm cu acele date și să le gestionăm, prin crearea de utilizatori și administrarea accesului lor. MySQL este una dintre cele mai populare opțiuni de SGBD. Alte exemple includ PostgreSQL, MongoDB și Microsoft SQL Server.
MySQL este un sistem de gestiune a bazelor de date relaționale (RDBMS) open-source care folosește SQL pentru a gestiona datele. Este cunoscut pentru ușurința în utilizare, viteză și compatibilitate cu aplicațiile web.
Iată cum diferă MySQL de alte RDBMS-uri:
MySQL este ideal în scenarii care cer viteză și scalabilitate, însă pentru funcționalități mai complexe sau de nivel enterprise, PostgreSQL poate fi o alegere mai potrivită.
MySQL suportă o varietate de tipuri de date, grupate astfel:
Numerice: INT, DECIMAL, FLOAT, DOUBLE etc.
Șiruri de caractere: CHAR, VARCHAR, TEXT, BLOB.
Dată/timp: DATE, DATETIME, TIMESTAMP, TIME.
JSON: Pentru stocarea obiectelor JSON.
INT stochează numere întregi fără zecimale. Îl putem folosi dacă nu avem nevoie de fracții. În schimb, DECIMAL poate stoca valori financiare și este potrivit pentru calcule precise cu zecimale.
Funcția DATE în MySQL stochează data în format an, lună, zi:
YYYY-MM-DD
În schimb, funcția DATETIME stochează data împreună cu ora, astfel:
YYYY-MM-DD HH:MM:SS
O cheie externă este un câmp dintr-un tabel care face legătura cu cheia primară a altui tabel.
De exemplu, într-un tabel customers care stochează informații despre clienți, fiecare client are un customer_id unic — într-un alt tabel numit transactions (care stochează înregistrări de achiziții), folosim customer_id ca cheie externă. customer_id din tabelul transactions va lega fiecare achiziție de un anumit client din tabelul customers .
Iată cum arată în SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Join-urile combină rânduri din două sau mai multe tabele pe baza unor coloane înrudite. Iată diferențele:
INNER JOIN: Returnează rândurile unde există o potrivire în ambele tabele.
LEFT JOIN: Returnează toate rândurile din tabelul din stânga și rândurile potrivite din tabelul din dreapta. Dacă nu există potrivire, se returnează NULL pentru coloanele tabelului din dreapta.
RIGHT JOIN: Similar cu LEFT JOIN, returnează toate rândurile din tabelul din dreapta și rândurile potrivite din stânga.
FULL JOIN: Combină rezultatele LEFT JOIN și RIGHT JOIN, incluzând rândurile fără potriviri din ambele tabele. Notă: MySQL nu suportă nativ sintaxa FULL JOIN. Pentru a obține același rezultat, folosește un UNION între un LEFT JOIN și un RIGHT JOIN
Comenzile DELETE, TRUNCATE și DROP pot suna similar, dar au comportamente diferite:
DELETE: Elimină rânduri dintr-un tabel pe baza unei condiții. Poate fi anulată dacă este într-o tranzacție. Exemplu:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Șterge toate rândurile dintr-un tabel, dar păstrează structura tabelului. Este mai rapid decât DELETE și nu poate fi anulat. Exemplu:
TRUNCATE TABLE employees;DROP: Elimină complet structura și datele tabelului, împreună cu orice dependențe, cum ar fi indexurile. Exemplu:
DROP TABLE employees;Pentru a crea tabele, poți folosi instrucțiunea CREATE TABLE, iar pentru modificări, de obicei ALTER TABLE. Iată câteva exemple:
Creare tabel:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Modificare pentru a adăuga o coloană:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Un tabel temporar există doar în timpul sesiunii curente de bază de date. După închiderea sesiunii, tabelul este șters. Acest tip de tabel poate stoca temporar rezultate intermediare. Îl putem folosi pentru testare, filtrare sau pregătirea datelor înainte de inserarea lor într-un tabel permanent.
Iată un exemplu:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;O subinterogare (cunoscută și ca interogare imbricată) este plasată în interiorul altei interogări. Ea descompune operațiunile complexe asupra bazei de date în pași mai ușor de gestionat. De exemplu, poți crea o subinterogare pentru a găsi angajații care câștigă peste media salarială:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Hai să descompunem:
Interogarea internă SELECT AVG(salary) FROM employees calculează mai întâi salariul mediu.
Interogarea externă folosește apoi această medie pentru a găsi angajații care câștigă peste ea.
Putem folosi instrucțiunea INSERT pentru a adăuga date într-un tabel. Sintaxa de bază este:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Iată câteva bune practici de urmat când folosești instrucțiunea INSERT
Listează explicit coloanele. Asta face codul mai clar și previne erorile dacă structura tabelului se schimbă ulterior.
Pentru coloanele AUTO_INCREMENT, precum ID-urile, omite-le în instrucțiunea INSERT. MySQL le gestionează automat ca să prevină ID-uri duplicate.
Fii consecvent cu ghilimelele pentru șiruri. Personal prefer ghilimelele simple, dar ambele opțiuni funcționează.
Dacă inserezi mai multe rânduri, o poți face într-o singură instrucțiune pentru performanță mai bună.
Atributul AUTO_INCREMENT în MySQL generează numere unice, secvențiale, pentru o coloană, de obicei cheia primară a unui tabel.
Iată un exemplu de creare a unui tabel cu o coloană AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);Și pentru a insera rânduri în el:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');O vizualizare este o interogare salvată care funcționează ca un tabel virtual. Cu ea, putem lua o interogare complexă, să-i dăm un nume și s-o folosim ca pe un tabel pentru interogări viitoare. Astfel, nu trebuie să tastezi întreaga interogare de fiecare dată.
De exemplu, pentru a simplifica interogarea detaliilor angajaților împreună cu denumirile departamentelor, poți crea o vizualizare:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Acum poți interoga vizualizarea employee_details ca pe un tabel:
SELECT * FROM employee_details;Totuși, nu putem folosi vizualizările pentru a insera și actualiza date. Majoritatea sunt doar pentru citire și împiedică utilizatorii să acceseze direct baza de date, sporind securitatea datelor. Vizualizările pot uneori încetini interogările, deoarece rulează interogarea de bază de fiecare dată când sunt accesate.
Află mai multe despre SQL cu aceste cursuri!
course
course
course