
Corso
Manipolazione dei dati in SQL
4 h
328.2K
Hai mai notato che MySQL è richiesto in quasi tutte le job description legate ai database? C’è un buon motivo — MySQL alimenta praticamente di tutto, dalle tue piattaforme social preferite alle app che usi ogni giorno.
Ho messo insieme questa guida per aiutarti ad affrontare le domande di un colloquio su MySQL. Coprirò tutto, dalle basi che uno sviluppatore junior dovrebbe conoscere agli aspetti più complessi richiesti per ruoli senior. Condividerò anche alcuni suggerimenti per aiutarti a presentarti come un candidato sicuro nei prossimi colloqui legati ai dati.
MySQL è un RDBMS open source (relational database management system) basato su SQL che organizza i dati in tabelle strutturate. È stato sviluppato da Oracle Corporation.
Si è classificato come il DBMS più popolare nel 2024. Tuttavia, un sondaggio di Stack Overflow del 2025 ha mostrato che PostgreSQL si è classificato come il database più utilizzato tra gli sviluppatori professionisti, superando per la prima volta MySQL.
Attenzione: MySQL è ancora enormemente popolare — raggiungendo il 40,5% di utilizzo tra gli sviluppatori nel 2025 — e alimenta ancora innumerevoli applicazioni web, sistemi di gestione dei contenuti e strumenti enterprise. E soprattutto, se lavori con applicazioni web o lo stack LAMP, MySQL è una competenza di primo livello da avere.
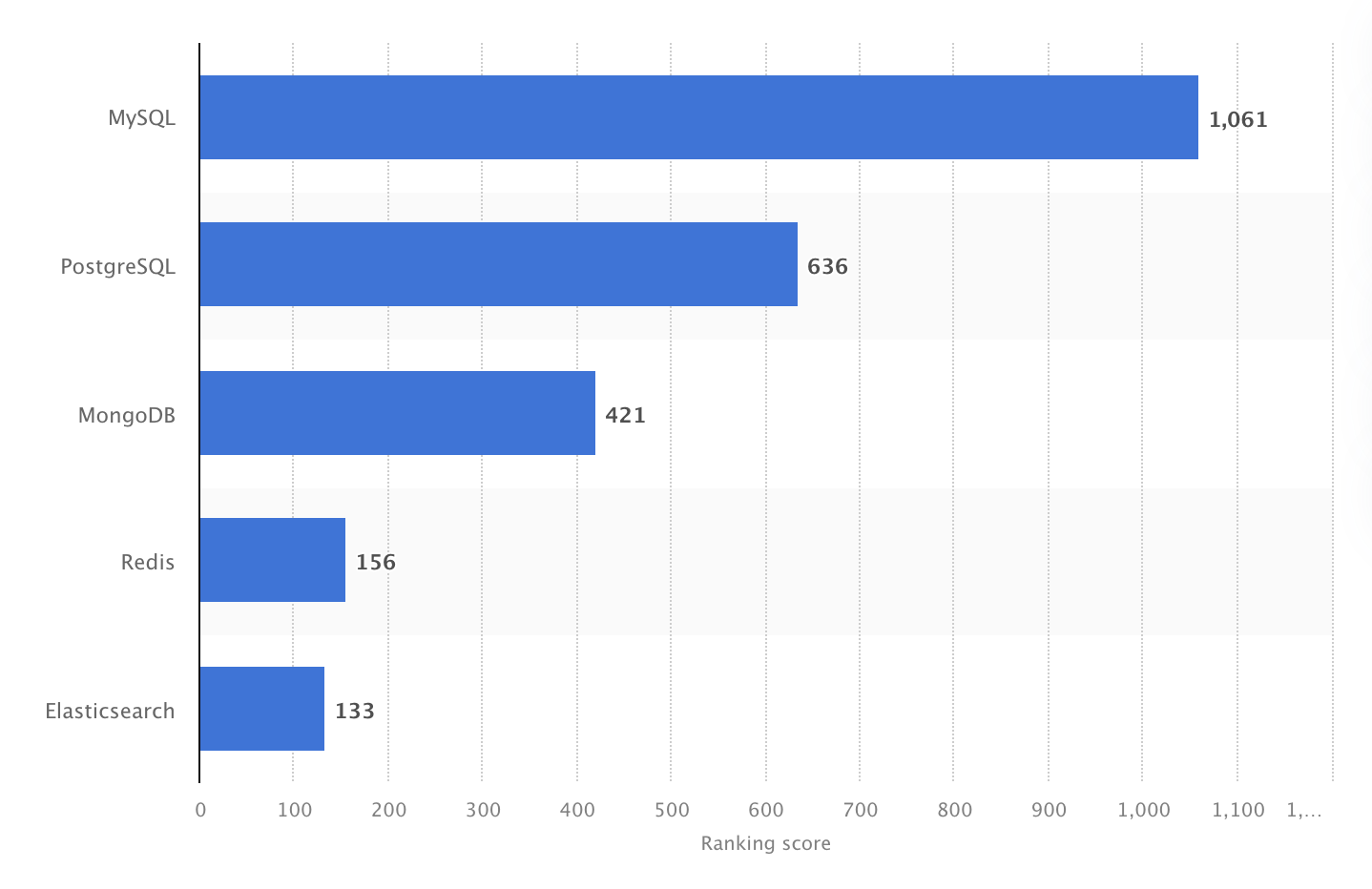
Nel 2024, MySQL è stato il DBMS open source più popolare al mondo, con un punteggio di 1061. Fonte: Statista.
Nella fase iniziale del colloquio, l’intervistatore può porre domande fondamentali per valutare la tua comprensione dei concetti di base dei database e di MySQL.
Un database è un contenitore di archiviazione che contiene dati a cui possiamo accedere, che possiamo modificare e analizzare. Ad esempio, le piattaforme social memorizzano in database i dati su chi ha messo Mi piace ai nostri post.
Un DBMS (Database Management System) è il software che ci permette di interagire con quei dati e gestirli, creando utenti e gestendone gli accessi. MySQL è uno dei DBMS più popolari. Altri esempi includono PostgreSQL, MongoDB e Microsoft SQL Server.
MySQL è un sistema di gestione di database relazionali (RDBMS) open source che usa SQL per gestire i dati. È noto per la sua facilità d’uso, velocità e compatibilità con le applicazioni web.
Ecco come MySQL differisce da altri RDBMS:
MySQL è ideale negli scenari che richiedono velocità e scalabilità; per funzionalità più complesse o di livello enterprise, potrebbe essere preferibile PostgreSQL.
MySQL supporta diversi tipi di dato, categorizzati come:
Numerici: INT, DECIMAL, FLOAT, DOUBLE, ecc.
Stringa: CHAR, VARCHAR, TEXT, BLOB.
Data/ora: DATE, DATETIME, TIMESTAMP, TIME.
JSON: Per archiviare oggetti JSON.
INT memorizza numeri interi senza decimali. Possiamo usarlo quando non servono frazioni. Al contrario, DECIMAL può memorizzare valori finanziari ed è adatto a calcoli precisi con decimali.
La funzione DATE in MySQL memorizza la data in formato anno, mese, giorno:
YYYY-MM-DD
La funzione DATETIME, invece, memorizza la data con l’ora, in questo formato:
YYYY-MM-DD HH:MM:SS
Una chiave esterna è un campo in una tabella che collega la chiave primaria di un’altra tabella.
Per esempio, in una tabella customers che memorizza le informazioni sui clienti, ogni cliente ha un customer_id univoco — in un’altra tabella chiamata transactions (che memorizza gli acquisti), usiamo customer_id come chiave esterna. Il customer_id nella tabella delle transazioni collegherà ogni acquisto a uno specifico cliente nella tabella customers .
Ecco come appare in SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);I join combinano righe di due o più tabelle in base a colonne correlate. Ecco le differenze:
INNER JOIN: restituisce le righe in cui c’è una corrispondenza in entrambe le tabelle.
LEFT JOIN: restituisce tutte le righe della tabella di sinistra e le righe corrispondenti della tabella di destra. Se non c’è corrispondenza, viene restituito NULL per le colonne della tabella di destra.
RIGHT JOIN: simile a LEFT JOIN, restituisce tutte le righe della tabella di destra e le righe corrispondenti di quella di sinistra.
FULL JOIN: combina i risultati di LEFT JOIN e RIGHT JOIN, includendo le righe senza corrispondenza di entrambe le tabelle. Nota: MySQL non supporta nativamente la sintassi FULL JOIN. Per ottenere lo stesso risultato, usa una UNION di un LEFT JOIN e un RIGHT JOIN
Comandi come DELETE, TRUNCATE e DROP possono sembrare simili, ma in realtà si comportano in modo diverso:
DELETE: rimuove righe da una tabella in base a una condizione. Può essere annullato se all’interno di una transazione. Esempio:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: cancella tutte le righe di una tabella, ma la struttura resta intatta. È più veloce di DELETE e non può essere annullato. Esempio:
TRUNCATE TABLE employees;DROP: rimuove completamente struttura e dati della tabella, insieme a eventuali dipendenze come gli indici. Esempio:
DROP TABLE employees;Per creare tabelle, puoi usare l’istruzione CREATE TABLE e, per modificarle, di solito ALTER TABLE. Ecco alcuni esempi:
Creare una tabella:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Modificare per aggiungere una colonna:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Una tabella temporanea esiste solo durante la sessione di database corrente. Una volta chiusa la sessione, la tabella viene eliminata. Questo tipo di tabella può archiviare temporaneamente risultati intermedi. Possiamo usarla per test, filtraggio o preparazione dei dati prima di inserirli in una tabella permanente.
Ecco un esempio:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Una sottoquery (nota anche come query annidata) è annidata all’interno di un’altra query. Scompone operazioni complesse sul database in passaggi più gestibili. Ad esempio, puoi creare una sottoquery per trovare i dipendenti che guadagnano oltre la media:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Vediamo nel dettaglio:
La query interna SELECT AVG(salary) FROM employees calcola prima lo stipendio medio.
La query esterna usa poi questa media per trovare i dipendenti che guadagnano più di essa.
Possiamo usare l’istruzione INSERT per aggiungere dati a una tabella. La sintassi di base è:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Ecco alcune best practice da seguire quando usi INSERT
Elenca esplicitamente le colonne. Rende il codice più chiaro e previene errori se la struttura della tabella cambia in seguito.
Per colonne con AUTO_INCREMENT come gli ID, saltale nell’istruzione INSERT. MySQL le gestisce automaticamente per evitare ID duplicati.
Sii coerente con gli apici per le stringhe. Personalmente preferisco gli apici singoli, ma entrambi funzionano.
Se stai inserendo più righe, puoi farlo in un’unica istruzione per migliori prestazioni.
L’attributo AUTO_INCREMENT in MySQL genera numeri univoci e sequenziali per una colonna, di solito la chiave primaria di una tabella.
Ecco un esempio di creazione di una tabella con una colonna AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);E per inserire righe al suo interno:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Una vista è una query salvata che funziona come una tabella virtuale. Con questa, possiamo prendere una query complessa, darle un nome e usarla come tabella per query future. In questo modo non devi riscrivere l’intera query ogni volta.
Per esempio, per semplificare l’interrogazione dei dettagli dei dipendenti insieme ai nomi dei reparti, puoi creare una vista:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Ora puoi interrogare la vista employee_details proprio come una tabella:
SELECT * FROM employee_details;Tuttavia, non possiamo usare le viste per inserire e aggiornare i dati. La maggior parte supporta l’opzione di sola lettura e impedisce agli utenti di accedere direttamente al database, migliorando la sicurezza dei dati. Le viste a volte possono rallentare le query, poiché eseguono la query sottostante ogni volta che vengono richiamate.
Approfondisci SQL con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

