
Cursus
Gegevens manipuleren in SQL
4 Hr
328.2K
Is het je ooit opgevallen dat MySQL in bijna elke databasegerelateerde vacature-eis staat? Daar is een goede reden voor — MySQL drijft zo ongeveer alles aan, van je favoriete sociale mediaplatforms tot de apps die je dagelijks gebruikt.
Ik heb deze gids samengesteld om je te helpen met MySQL-sollicitatievragen. Ik behandel alles, van de basis die junior developers moeten kennen tot de complexere onderwerpen die voor senior rollen belangrijk zijn. Ook deel ik een paar tips die je helpen om vol zelfvertrouwen voor de dag te komen bij je volgende data-gerelateerde interviews.
MySQL is een open-source RDBMS (relational database management system) gebaseerd op SQL dat data organiseert in gestructureerde tabellen. Het werd ontwikkeld door Oracle Corporation.
Het stond in de meest populaire DBMS in 2024-ranglijst. Toch liet een Stack Overflow Developer Survey in 2025 zien dat PostgreSQL voor het eerst MySQL voorbijstreefde als meest gebruikte database onder professionele developers.
Begrijp me niet verkeerd: MySQL is nog steeds enorm populair — met 40,5% gebruik onder developers in 2025 — en drijft nog altijd talloze webapplicaties, contentmanagementsystemen en enterprise-tools aan. En zeker als je met webapplicaties of de LAMP-stack werkt, is MySQL een topvaardigheid om te hebben.
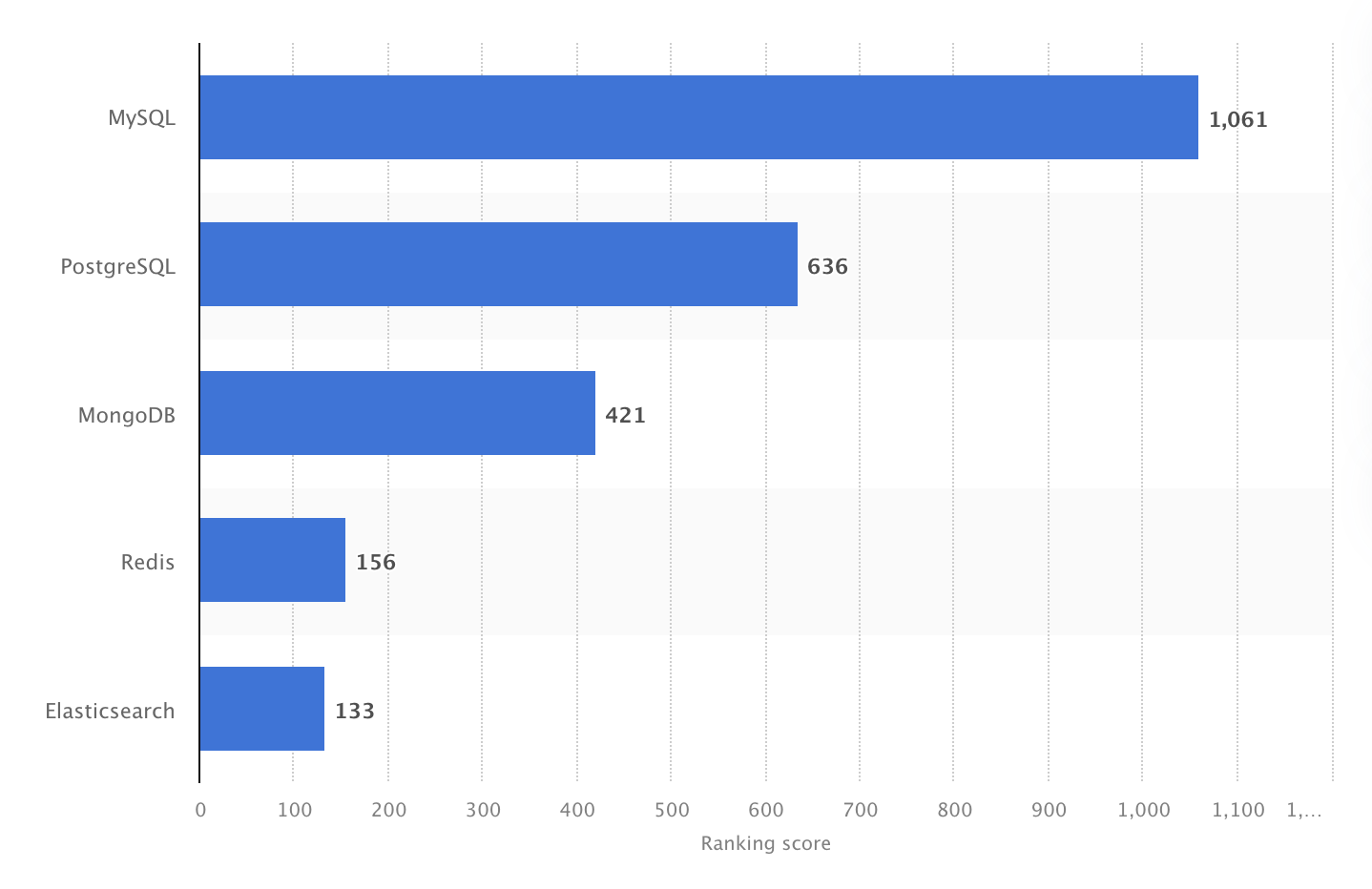
In 2024 was MySQL wereldwijd het populairste open-source DBMS, met een score van 1061. Bron: Statista.
In de eerste interviewfase kan de interviewer basisvragen stellen om je begrip van fundamentele database- en MySQL-concepten te toetsen.
Een database is een opslagcontainer die data bevat die we kunnen raadplegen, wijzigen en analyseren. Zo slaan sociale mediaplatforms bijvoorbeeld in databases op wie onze posts leuk hebben gevonden.
Een DBMS (Database Management System) is de software waarmee we met die data kunnen werken en deze beheren, bijvoorbeeld door gebruikers aan te maken en hun toegang te beheren. MySQL is een van de populairste DBMS-opties. Andere voorbeelden zijn PostgreSQL, MongoDB en Microsoft SQL Server.
MySQL is een open-source relationeel databasebeheersysteem (RDBMS) dat SQL gebruikt om data te beheren. Het staat bekend om zijn gebruiksgemak, snelheid en compatibiliteit met webgebaseerde applicaties.
Zo verschilt MySQL van andere RDBMS'en:
MySQL is ideaal in scenario's waar snelheid en schaalbaarheid vereist zijn, maar voor complexere of enterprise-grade features kan PostgreSQL een betere keuze zijn.
MySQL ondersteunt verschillende datatypen, gecategoriseerd als:
Numeriek: INT, DECIMAL, FLOAT, DOUBLE, enz.
String: CHAR, VARCHAR, TEXT, BLOB.
Datum/tijd: DATE, DATETIME, TIMESTAMP, TIME.
JSON: Voor het opslaan van JSON-objecten.
INT slaat gehele getallen op zonder decimalen. Gebruik dit als er geen fracties nodig zijn. Daarentegen kan DECIMAL financiële waarden opslaan en is het geschikt voor precieze berekeningen met decimalen.
De DATE-functie in MySQL slaat de datum op in jaar-, maand- en dagformaat:
YYYY-MM-DD
De DATETIME-functie slaat de datum met tijd op en ziet er zo uit:
YYYY-MM-DD HH:MM:SS
Een foreign key is een veld in de ene tabel dat verwijst naar de primary key van een andere tabel.
Bijvoorbeeld, in een customers-tabel met klantinformatie heeft elke klant een unieke customer_id — in een andere tabel transactions (met aankooprecords) gebruiken we customer_id als foreign key. De customer_id in de transactions-tabel koppelt elke aankoop aan een specifieke klant in de customers -tabel.
Zo ziet dat eruit in SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins combineren rijen uit twee of meer tabellen op basis van gerelateerde kolommen. Dit zijn de verschillen:
INNER JOIN: Geeft rijen terug waar in beide tabellen een match is.
LEFT JOIN: Geeft alle rijen van de linkertabel en de matchende rijen van de rechtertabel. Als er geen match is, wordt NULL teruggegeven voor de kolommen van de rechtertabel.
RIGHT JOIN: Vergelijkbaar met LEFT JOIN, geeft alle rijen van de rechtertabel en de matchende rijen van de linkertabel.
FULL JOIN: Combineert de resultaten van LEFT JOIN en RIGHT JOIN, inclusief niet-gematchte rijen uit beide tabellen. Let op: MySQL ondersteunt FULL JOIN niet native. Gebruik een UNION van een LEFT JOIN en een RIGHT JOIN om hetzelfde resultaat te bereiken.
Opdrachten als DELETE, TRUNCATE en DROP klinken vergelijkbaar, maar gedragen zich anders:
DELETE: Verwijdert rijen uit een tabel op basis van een voorwaarde. Kan worden teruggedraaid als het binnen een transactie gebeurt. Voorbeeld:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Verwijdert alle rijen uit een tabel, maar laat de tabelstructuur intact. Is sneller dan DELETE en kan niet worden teruggedraaid. Voorbeeld:
TRUNCATE TABLE employees;DROP: Verwijdert de tabelstructuur en data volledig, inclusief afhankelijkheden zoals indexen. Voorbeeld:
DROP TABLE employees;Om tabellen te maken gebruik je CREATE TABLE, en om te wijzigen meestal ALTER TABLE. Enkele voorbeelden:
Tabel maken:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Wijzigen om een kolom toe te voegen:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Een tijdelijke tabel bestaat alleen tijdens de huidige databasesessie. Zodra we de sessie sluiten, wordt de tabel verwijderd. Dit type tabel kan tijdelijk tussentijdse resultaten opslaan. Je kunt het gebruiken voor testen, filteren of het voorbereiden van data voordat je deze in een permanente tabel zet.
Hier is een voorbeeld:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Een subquery (ook wel geneste query) is een query binnen een andere query. Het verdeelt complexe databasebewerkingen in behapbare stappen. Zo kun je bijvoorbeeld een subquery maken om medewerkers te vinden die boven het gemiddelde verdienen:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Laten we dit uiteenzetten:
De binnenste query SELECT AVG(salary) FROM employees berekent eerst het gemiddelde salaris.
De buitenste query gebruikt dit gemiddelde om medewerkers te vinden die er boven zitten.
We gebruiken het INSERT-statement om data aan een tabel toe te voegen. De basis-syntax is:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Hier zijn een paar best practices bij het gebruik van INSERT:
Specificeer je kolommen expliciet. Dit maakt de code duidelijker en voorkomt fouten als de tabelstructuur later verandert.
Sla voor AUTO_INCREMENT-kolommen zoals ID's deze kolom over in het INSERT-statement. MySQL handelt dit automatisch af om dubbele ID's te voorkomen.
Wees consistent met aanhalingstekens voor strings. Zelf geef ik de voorkeur aan enkele aanhalingstekens, maar beide werken.
Als je meerdere rijen invoegt, kan dat in één statement voor betere performance.
Het attribuut AUTO_INCREMENT in MySQL genereert unieke, oplopende nummers voor een kolom, meestal de primary key van een tabel.
Zo maak je een tabel met een AUTO_INCREMENT-kolom:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);En zo voeg je er rijen aan toe:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Een view is een opgeslagen query die werkt als een virtuele tabel. Hiermee kun je een complexe query een naam geven en deze als een tabel gebruiken voor toekomstige queries. Zo hoef je niet telkens de volledige query uit te typen.
Om bijvoorbeeld het opvragen van medewerkergegevens met bijbehorende afdelingsnamen te vereenvoudigen, kun je een view maken:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Je kunt de view employee_details nu opvragen alsof het een tabel is:
SELECT * FROM employee_details;We kunnen via views echter niet de data invoegen en updaten. De meeste zijn alleen-lezen en voorkomen directe toegang tot de database, wat de dataveiligheid vergroot. Views kunnen soms queries vertragen, omdat bij elke toegang de onderliggende query wordt uitgevoerd.
Leer meer over SQL met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
