Courses
Data Manipulation in SQL
4 ชม.
324.4K
สังเกตไหมว่าแทบทุกประกาศรับสมัครงานที่เกี่ยวกับฐานข้อมูลมักระบุว่าต้องมีทักษะ MySQL อยู่เสมอ ก็มีเหตุผลดีๆ เพราะ MySQL ขับเคลื่อนตั้งแต่แพลตฟอร์มโซเชียลมีเดียยอดนิยมไปจนถึงแอปที่ใช้กันทุกวัน
คู่มือนี้ถูกจัดทำขึ้นเพื่อช่วยรับมือกับคำถามสัมภาษณ์ MySQL ครอบคลุมตั้งแต่พื้นฐานที่นักพัฒนาระดับจูเนียร์ควรรู้ ไปจนถึงประเด็นซับซ้อนที่ตำแหน่งอาวุโสต้องใช้ อีกทั้งยังมีเคล็ดลับที่จะช่วยให้ดูมั่นใจในสัมภาษณ์สายข้อมูลครั้งถัดไปด้วย
MySQL เป็นระบบจัดการฐานข้อมูลเชิงสัมพันธ์ (RDBMS) แบบโอเพนซอร์สที่สร้างบน SQL จัดระเบียบข้อมูลเป็นตารางที่มีโครงสร้าง พัฒนาโดย Oracle Corporation
มันได้รับการจัดอันดับเป็น DBMS แบบโอเพนซอร์สที่ได้รับความนิยมสูงสุดในปี 2024 อย่างไรก็ดี แบบสำรวจนักพัฒนา Stack Overflow ปี 2025 แสดงว่า PostgreSQL กลายเป็นฐานข้อมูลที่ถูกใช้งานมากที่สุดในหมู่นักพัฒนามืออาชีพ แซง MySQL เป็นครั้งแรก
อย่างไรก็ตาม MySQL ก็ยังคงได้รับความนิยมอย่างมาก — มีสัดส่วนการใช้งานถึง 40.5% ในปี 2025 — และยังคงขับเคลื่อนเว็บแอปพลิเคชัน ระบบจัดการเนื้อหา และเครื่องมือระดับองค์กรนับไม่ถ้วน โดยเฉพาะหากทำงานกับเว็บแอปหรือสแตก LAMP ทักษะ MySQL ถือเป็นระดับแนวหน้า
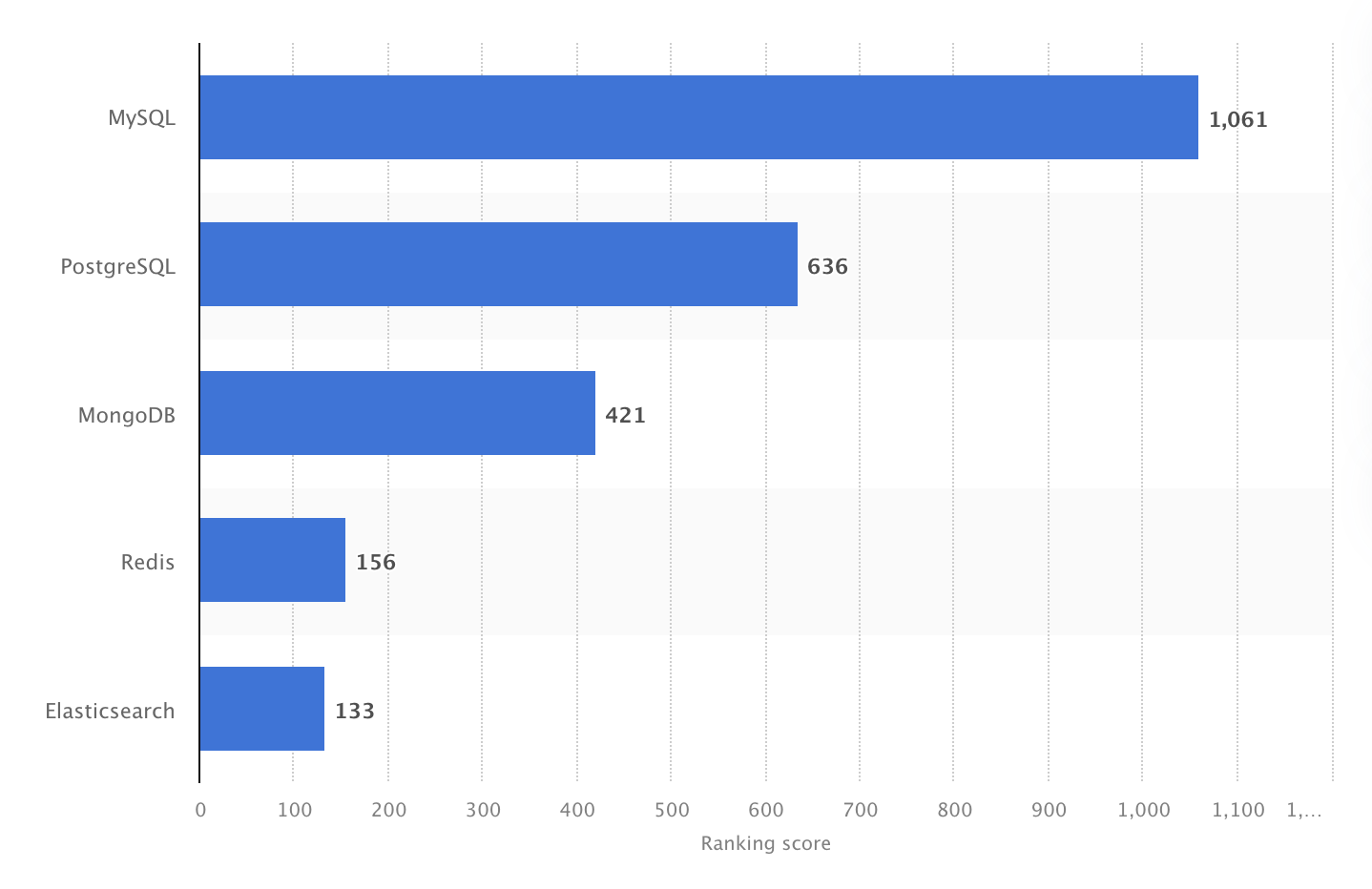
ในปี 2024 MySQL เป็น DBMS แบบโอเพนซอร์สที่ได้รับความนิยมสูงที่สุดของโลก ด้วยคะแนนจัดอันดับ 1061 ที่มา: Statista
ในช่วงแรกของการสัมภาษณ์ ผู้สัมภาษณ์มักถามคำถามพื้นฐานเพื่อประเมินความเข้าใจเกี่ยวกับแนวคิดฐานข้อมูลและ MySQL เบื้องต้น
ฐานข้อมูลคือภาชนะเก็บข้อมูลที่เราสามารถเข้าถึง แก้ไข และวิเคราะห์ได้ เช่น แพลตฟอร์มโซเชียลมีเดียเก็บข้อมูลว่าใครกดถูกใจโพสต์ของเราไว้ในฐานข้อมูล
DBMS (Database Management System) คือซอฟต์แวร์ที่ให้เราโต้ตอบและจัดการข้อมูลนั้นได้ เช่น การสร้างผู้ใช้และจัดการสิทธิ์การเข้าถึง MySQL เป็นหนึ่งใน DBMS ยอดนิยม ตัวอย่างอื่นๆ ได้แก่ PostgreSQL, MongoDB และ Microsoft SQL Server.
MySQL เป็น RDBMS แบบโอเพนซอร์สที่ใช้ SQL จัดการข้อมูล มีชื่อเสียงด้านการใช้งานง่าย ความเร็ว และความเข้ากันได้ดีกับเว็บแอปพลิเคชัน
ความแตกต่างเมื่อเทียบกับ RDBMS อื่นๆ มีดังนี้:
MySQL เหมาะกับสถานการณ์ที่ต้องการความเร็วและการขยายตัว แต่หากต้องการฟีเจอร์ซับซ้อนระดับองค์กร PostgreSQL อาจเป็นตัวเลือกที่ดีกว่า
MySQL รองรับชนิดข้อมูลหลากหลาย แบ่งเป็นหมวดหมู่ดังนี้:
เชิงตัวเลข: INT, DECIMAL, FLOAT, DOUBLE เป็นต้น
สตริง: CHAR, VARCHAR, TEXT, BLOB.
วัน/เวลา: DATE, DATETIME, TIMESTAMP, TIME.
JSON: สำหรับเก็บออบเจ็กต์ JSON
INT เก็บจำนวนเต็มที่ไม่มีจุดทศนิยม ใช้เมื่อไม่ต้องการเศษส่วน ในทางกลับกัน DECIMAL สามารถเก็บค่าทางการเงิน เหมาะสำหรับการคำนวณที่ต้องการความแม่นยำทศนิยม
ฟังก์ชัน DATE ใน MySQL เก็บวันที่ในรูปแบบปี เดือน วัน:
YYYY-MM-DD
ขณะที่ DATETIME เก็บทั้งวันที่และเวลา โดยมีรูปแบบดังนี้:
YYYY-MM-DD HH:MM:SS
คีย์ต่างประเทศคือฟิลด์ในตารางหนึ่งที่ลิงก์กับคีย์หลักของอีกตารางหนึ่ง
ตัวอย่างเช่น ในตาราง customers ที่เก็บข้อมูลลูกค้า แต่ละคนมี customer_id ที่ไม่ซ้ำกัน — ในอีกตารางชื่อ transactions (เก็บประวัติการซื้อ) เราใช้ customer_id เป็นคีย์ต่างประเทศ โดย customer_id ในตาราง transactions จะลิงก์แต่ละการซื้อเข้ากับลูกค้าเฉพาะรายในตาราง customers นั่นเอง
ตัวอย่าง SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);การ join ใช้รวมแถวจากหลายตารางตามคอลัมน์ที่สัมพันธ์กัน ความแตกต่างมีดังนี้:
INNER JOIN: คืนค่าเฉพาะแถวที่มีการจับคู่กันในทั้งสองตาราง
LEFT JOIN: คืนค่าทุกแถวจากตารางซ้ายและเฉพาะแถวที่จับคู่ได้จากตารางขวา หากไม่มีคู่ที่ตรงกัน คอลัมน์ของตารางขวาจะเป็น NULL
RIGHT JOIN: คล้าย LEFT JOIN แต่คืนค่าทุกแถวจากตารางขวาและเฉพาะแถวที่จับคู่ได้จากตารางซ้าย
FULL JOIN: รวมผลลัพธ์ของ LEFT JOIN และ RIGHT JOIN รวมถึงแถวที่ไม่จับคู่จากทั้งสองตาราง หมายเหตุ: MySQL ไม่รองรับไวยากรณ์ FULL JOIN โดยตรง หากต้องการผลลัพธ์เดียวกัน ให้ใช้ UNION ของ LEFT JOIN และ RIGHT JOIN
คำสั่ง DELETE, TRUNCATE และ DROP ฟังดูคล้ายกัน แต่พฤติกรรมต่างกันดังนี้:
DELETE: ลบแถวจากตารางตามเงื่อนไข สามารถย้อนกลับได้หากอยู่ในทรานแซกชัน ตัวอย่าง:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: ลบทุกแถวจากตาราง แต่โครงสร้างตารางยังคงอยู่ เร็วกว่า DELETE และไม่สามารถย้อนกลับได้ ตัวอย่าง:
TRUNCATE TABLE employees;DROP: ลบทั้งโครงสร้างและข้อมูลของตาราง รวมถึงสิ่งที่เกี่ยวข้อง เช่น ดัชนี ตัวอย่าง:
DROP TABLE employees;ใช้คำสั่ง CREATE TABLE เพื่อสร้างตาราง และมักใช้ ALTER TABLE เพื่อแก้ไขตาราง ตัวอย่าง:
สร้างตาราง:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));แก้ไขเพื่อเพิ่มคอลัมน์:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);ตารางชั่วคราวจะคงอยู่เฉพาะระหว่างเซสชันฐานข้อมูลปัจจุบัน เมื่อปิดเซสชัน ตารางจะถูกลบ ใช้เก็บผลลัพธ์ระหว่างทางชั่วคราว เหมาะสำหรับทดสอบ กรอง หรือเตรียมข้อมูลก่อนใส่ลงตารางถาวร
ตัวอย่าง:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;ซับคิวรี (หรือคิวรีซ้อน) คือคิวรีที่อยู่ภายในคิวรีอีกชั้น ใช้แตกงานที่ซับซ้อนให้เป็นขั้นตอนย่อยๆ เช่น หาอัตราค่าจ้างพนักงานที่สูงกว่าเงินเดือนเฉลี่ย:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);อธิบายทีละส่วน:
คิวรีด้านใน SELECT AVG(salary) FROM employees คำนวณเงินเดือนเฉลี่ยก่อน
คิวรีด้านนอกใช้ค่าเฉลี่ยนี้เพื่อหาพนักงานที่มีรายได้สูงกว่า
ใช้คำสั่ง INSERT เพื่อเพิ่มข้อมูลลงตาราง ไวยากรณ์พื้นฐาน:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); แนวทางปฏิบัติที่ดีเมื่อใช้ INSERT
ระบุรายชื่อคอลัมน์อย่างชัดเจน ทำให้โค้ดอ่านง่ายและลดข้อผิดพลาดหากโครงสร้างตารางเปลี่ยนในอนาคต
สำหรับคอลัมน์ AUTO_INCREMENT เช่น ID ให้ข้ามใน INSERT MySQL จะจัดการให้เองเพื่อป้องกันเลขซ้ำ
ใช้เครื่องหมายอัญประกาศสำหรับสตริงให้สอดคล้องกัน ส่วนตัวนิยมเครื่องหมาย single quote แต่ใช้แบบใดแบบหนึ่งก็ได้
หากเพิ่มหลายแถว ควรทำในคำสั่งเดียวเพื่อประสิทธิภาพที่ดีกว่า
คุณลักษณะ AUTO_INCREMENT ใน MySQL สร้างตัวเลขลำดับที่ไม่ซ้ำกันสำหรับคอลัมน์ โดยมักใช้กับคีย์หลักของตาราง
ตัวอย่างการสร้างตารางที่มีคอลัมน์ AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);และตัวอย่างการเพิ่มแถว:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');วิวคือคิวรีที่บันทึกไว้ซึ่งทำงานเสมือนเป็นตารางเสมือน เราสามารถนำคิวรีซับซ้อนมาตั้งชื่อและใช้เหมือนตารางในการคิวรีครั้งต่อไป โดยไม่ต้องพิมพ์ใหม่ทุกครั้ง
ตัวอย่าง เพื่อให้ง่ายต่อการดึงรายละเอียดพนักงานพร้อมชื่อแผนก สามารถสร้างวิวได้ดังนี้:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;จากนั้นสามารถคิวรีวิว employee_details ได้เหมือนตาราง:
SELECT * FROM employee_details;อย่างไรก็ตาม วิวส่วนมากใช้เพื่ออ่านอย่างเดียว ไม่สามารถใช้เพื่อ insert และ update ข้อมูลได้ และช่วยจำกัดการเข้าถึงฐานข้อมูลเพื่อเพิ่มความปลอดภัย ทั้งนี้ วิวอาจทำให้คิวรีช้าลงได้ เพราะต้องรันคิวรีพื้นฐานทุกครั้งที่เรียกใช้งาน
เรียนรู้เพิ่มเติมเกี่ยวกับ SQL ด้วยคอร์สเหล่านี้!
Courses
Courses
Courses