course
Data Manipulation in SQL
4 godz.
324.1K
Zauważyłeś, że MySQL pojawia się niemal w każdym ogłoszeniu o pracę związanym z bazami danych? Jest ku temu dobry powód — MySQL napędza praktycznie wszystko: od twoich ulubionych platform społecznościowych po aplikacje, z których korzystasz na co dzień.
Przygotowałem ten przewodnik, aby pomóc ci zmierzyć się z pytaniami na rozmowie o MySQL. Omówię wszystko — od podstaw, które powinien znać junior, po bardziej złożone kwestie wymagane na stanowiskach seniorskich. Podzielę się też wskazówkami, jak pokazać się jako pewny siebie kandydat podczas kolejnych rozmów o pracę związanych z danymi.
MySQL to otwartoźródłowy system RDBMS (relacyjny system zarządzania bazą danych) oparty na SQL, który organizuje dane w uporządkowane tabele. Został opracowany przez Oracle Corporation.
Zajął miejsce najpopularniejszego DBMS w 2024 roku. Jednak ankieta Stack Overflow Developer Survey z 2025 roku pokazała, że PostgreSQL po raz pierwszy wyprzedził MySQL i stał się najczęściej używaną bazą danych wśród profesjonalnych deweloperów.
Żeby było jasne: MySQL nadal jest ogromnie popularny — osiągnął 40,5% użycia wśród deweloperów w 2025 roku — i wciąż zasila niezliczone aplikacje webowe, systemy CMS i narzędzia korporacyjne. A jeśli pracujesz z aplikacjami webowymi lub stosujesz LAMP, MySQL to umiejętność z najwyższej półki.
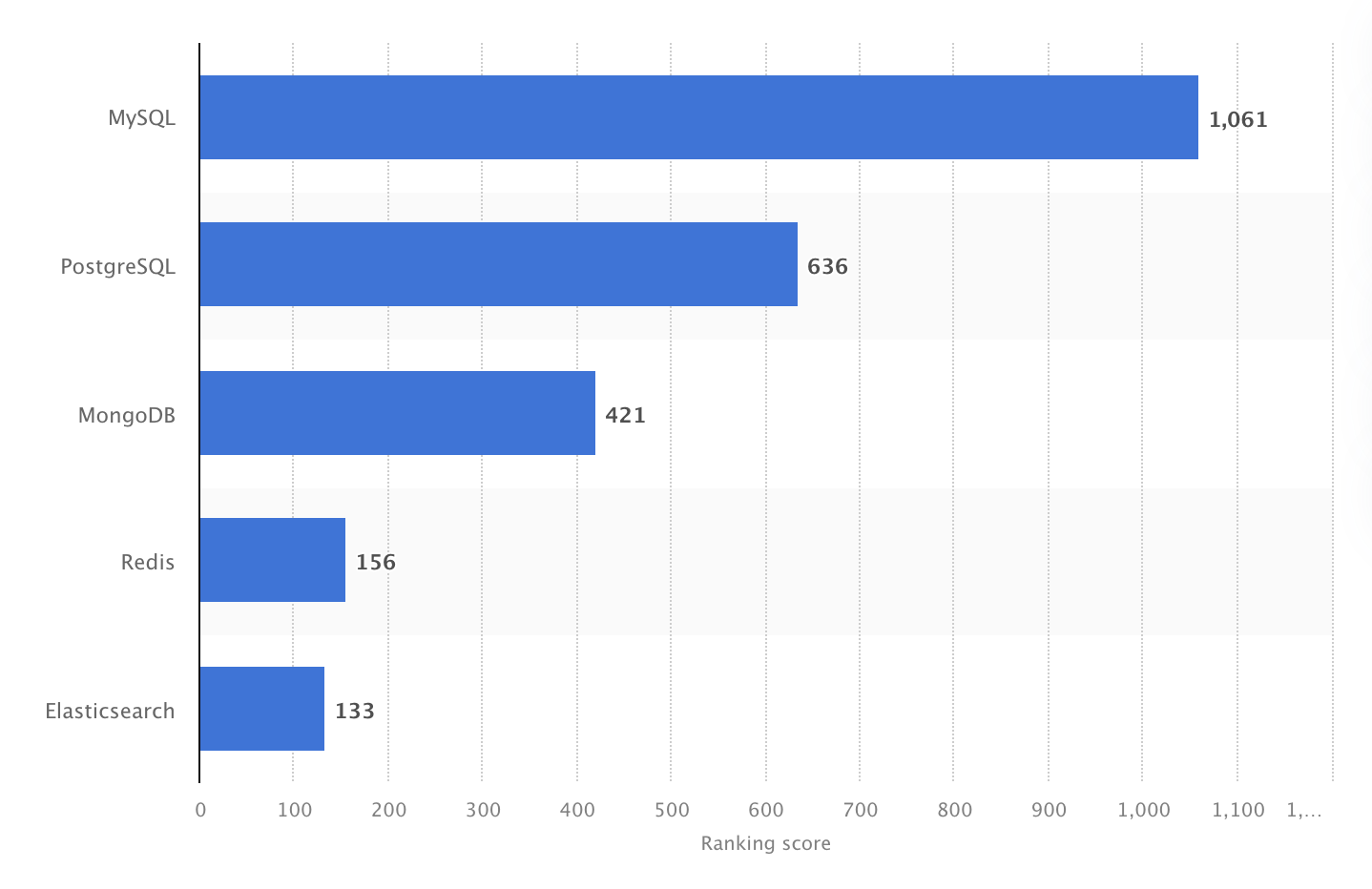
W 2024 roku MySQL był najpopularniejszym na świecie otwartoźródłowym DBMS z wynikiem 1061. Źródło: Statista.
Na wstępnym etapie rozmowy rekruter może zadać pytania bazowe, aby ocenić twoje rozumienie podstawowych pojęć dotyczących baz danych i MySQL.
Baza danych to kontener do przechowywania danych, do których możemy mieć dostęp, modyfikować je i analizować. Na przykład platformy społecznościowe przechowują w bazach dane o tym, kto polubił nasze posty.
DBMS (Database Management System) to oprogramowanie, które pozwala nam wchodzić w interakcję z tymi danymi i nimi zarządzać, np. tworząc użytkowników i kontrolując ich dostęp. MySQL to jedna z najpopularniejszych opcji DBMS. Inne przykłady to PostgreSQL, MongoDB i Microsoft SQL Server.
MySQL to otwartoźródłowy relacyjny system zarządzania bazą danych (RDBMS), który używa SQL do zarządzania danymi. Słynie z łatwości użycia, szybkości i kompatybilności z aplikacjami webowymi.
Oto jak MySQL różni się od innych RDBMS:
MySQL jest idealny w scenariuszach wymagających szybkości i skalowalności, ale w przypadku bardziej złożonych lub korporacyjnych funkcji lepszym wyborem może być PostgreSQL.
MySQL obsługuje różne typy danych, kategoryzowane jako:
Numeryczne: INT, DECIMAL, FLOAT, DOUBLE itd.
Tekstowe: CHAR, VARCHAR, TEXT, BLOB.
Data/czas: DATE, DATETIME, TIMESTAMP, TIME.
JSON: Do przechowywania obiektów JSON.
INT przechowuje liczby całkowite bez części dziesiętnej. Używamy go, gdy nie potrzebujemy ułamków. Z kolei DECIMAL może przechowywać wartości finansowe i nadaje się do precyzyjnych obliczeń z miejscami po przecinku.
Funkcja DATE w MySQL przechowuje datę w formacie rok, miesiąc, dzień:
YYYY-MM-DD
Natomiast DATETIME przechowuje datę wraz z czasem i wygląda tak:
YYYY-MM-DD HH:MM:SS
Klucz obcy to pole w jednej tabeli, które odwołuje się do klucza głównego w innej tabeli.
Na przykład w tabeli customers, która przechowuje informacje o klientach, każdy klient ma unikalne customer_id — w innej tabeli o nazwie transactions (przechowującej rekordy zakupów) używamy customer_id jako klucza obcego. customer_id w tabeli transactions połączy każdy zakup z konkretnym klientem z tabeli customers .
Tak to wygląda w SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Złączenia łączą wiersze z dwóch lub więcej tabel na podstawie powiązanych kolumn. Oto różnice:
INNER JOIN: Zwraca wiersze, dla których istnieje dopasowanie w obu tabelach.
LEFT JOIN: Zwraca wszystkie wiersze z lewej tabeli i pasujące z prawej. Jeśli nie ma dopasowania, dla kolumn prawej tabeli zwraca NULL.
RIGHT JOIN: Podobnie jak LEFT JOIN, zwraca wszystkie wiersze z prawej tabeli i pasujące z lewej.
FULL JOIN: Łączy wyniki LEFT JOIN i RIGHT JOIN, uwzględniając niepasujące wiersze z obu tabel. Uwaga: MySQL nie wspiera natywnie składni FULL JOIN. Aby uzyskać taki sam efekt, użyj UNION z LEFT JOIN i RIGHT JOIN
Polecenia DELETE, TRUNCATE i DROP mogą brzmieć podobnie, ale zachowują się inaczej:
DELETE: Usuwa wiersze z tabeli na podstawie warunku. Może zostać wycofane, jeśli jest wewnątrz transakcji. Przykład:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Usuwa wszystkie wiersze z tabeli, ale pozostawia jej strukturę. Jest szybsze niż DELETE i nie można go wycofać. Przykład:
TRUNCATE TABLE employees;DROP: Całkowicie usuwa strukturę tabeli i dane, wraz z zależnościami, takimi jak indeksy. Przykład:
DROP TABLE employees;Do tworzenia tabel używasz instrukcji CREATE TABLE, a do modyfikacji zwykle ALTER TABLE. Oto przykłady:
Utworzenie tabeli:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Modyfikacja — dodanie kolumny:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Tabela tymczasowa istnieje tylko w trakcie bieżącej sesji z bazą. Po jej zamknięciu tabela jest usuwana. Ten typ tabeli może tymczasowo przechowywać wyniki pośrednie. Możesz użyć jej do testowania, filtrowania lub przygotowania danych przed wstawieniem ich do tabeli trwałej.
Oto przykład:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Podzapytanie (znane też jako zapytanie zagnieżdżone) jest umieszczone wewnątrz innego zapytania. Rozbija złożone operacje bazodanowe na bardziej przystępne kroki. Na przykład możesz użyć podzapytania, aby znaleźć pracowników zarabiających powyżej średniej:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Rozbijmy to na kroki:
Wewnętrzne zapytanie SELECT AVG(salary) FROM employees najpierw liczy średnią pensję.
Zewnętrzne zapytanie używa tej średniej, aby znaleźć pracowników zarabiających powyżej niej.
Używamy instrukcji INSERT, aby dodać dane do tabeli. Podstawowa składnia to:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Oto kilka dobrych praktyk przy korzystaniu z instrukcji INSERT
Jawnie wypisuj kolumny. To zwiększa czytelność kodu i zapobiega błędom przy zmianach struktury tabeli w przyszłości.
Kolumny AUTO_INCREMENT, takie jak ID, pomijaj w INSERT. MySQL obsłuży je automatycznie, zapobiegając duplikatom ID.
Stosuj spójne cudzysłowy dla łańcuchów. Osobiście wolę pojedyncze, ale oba zadziałają.
Jeśli wstawiasz wiele wierszy, zrób to jedną instrukcją — będzie wydajniej.
Atrybut AUTO_INCREMENT w MySQL generuje unikalne, sekwencyjne liczby dla kolumny — zwykle klucza głównego tabeli.
Oto przykład tworzenia tabeli z kolumną AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);A tak wstawiasz do niej wiersze:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Widok to zapisane zapytanie działające jak wirtualna tabela. Dzięki niemu możemy nadać nazwę złożonemu zapytaniu i używać go jak tabeli w kolejnych zapytaniach. Nie trzeba za każdym razem przepisywać całego zapytania.
Aby uprościć zapytania o szczegóły pracowników wraz z nazwami działów, możesz utworzyć widok:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Teraz możesz odpytywać widok employee_details tak jak tabelę:
SELECT * FROM employee_details;Nie możemy jednak używać widoków do wstawiania i aktualizowania danych. Większość z nich obsługuje tryb tylko do odczytu i ogranicza użytkownikom dostęp do bazy, zwiększając bezpieczeństwo danych. Widoki mogą też czasem spowalniać zapytania, ponieważ za każdym razem wykonują bazowe zapytanie.
Poznaj SQL na tych kursach!
course
course
course