
Courses
SQL のデータ操作
4時間
324.2K
データベース関連の求人票の多くで MySQL が要件になっていることに気づいたことはありませんか?それには理由があります。MySQL は、身近なソーシャルメディアから日々使うアプリまで、ほとんどあらゆるものを支えています。
このガイドでは、MySQL の面接質問に取り組めるようサポートします。ジュニア開発者が押さえておくべき基礎から、シニア職で求められる高度な内容まで、一通りをカバーします。さらに、次のデータ関連の面接で自信を持って臨むためのコツも共有します。
MySQL は、SQL を基盤とし、データを構造化されたテーブルに整理するオープンソースの RDBMS(リレーショナル・データベース管理システム)です。Oracle Corporation によって開発されました。
2024年には最も人気のある DBMSとしてランクインしました。ただし、2025年の Stack Overflow Developer Survey では、PostgreSQL がプロの開発者の間で最も広く使われるデータベースとして初めて MySQL を上回りました。
誤解のないように言うと、MySQL は依然として非常に人気が高く、2025年には開発者の 40.5% が利用しており、今も数え切れないほどの Web アプリケーション、コンテンツ管理システム、エンタープライズツールを支えています。特に Web アプリケーションや LAMP スタックに関わるなら、MySQL は一級のスキルです。
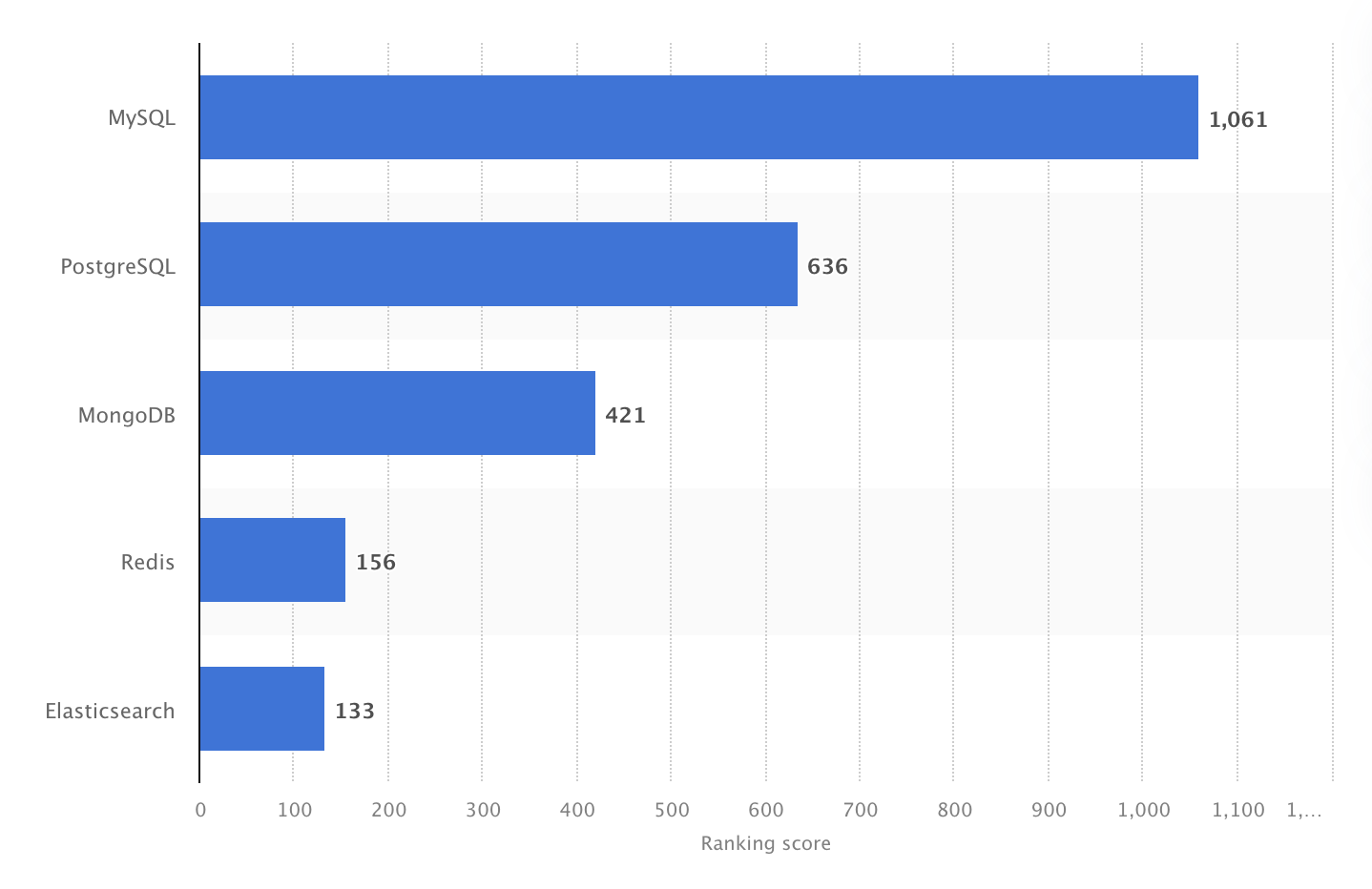
2024年、MySQL は世界で最も人気のあるオープンソース DBMS で、ランキングスコアは 1061。出典:Statista。
一次面接では、基本的なデータベースおよび MySQL の概念理解を測るための基礎的な質問が出ることがあります。
データベースは、アクセス・更新・分析が可能なデータを保持するストレージの入れ物です。たとえば、ソーシャルメディアは投稿に「いいね」した人の情報をデータベースに保存します。
DBMS(データベース管理システム)は、そのデータに対してユーザーを作成したりアクセス権を管理したりして、やり取りを可能にするソフトウェアです。MySQL は最も人気のある DBMS のひとつです。その他の例には PostgreSQL、MongoDB、Microsoft SQL Server などがあります。
MySQL は、SQL を使ってデータを管理するオープンソースの RDBMS です。使いやすさ、速度、Web アプリケーションとの高い親和性で知られています。
他の RDBMS との違いは次のとおりです。
MySQL はスピードとスケーラビリティが求められる場面に最適ですが、より複雑またはエンタープライズ向けの機能が必要なら PostgreSQL が適している場合もあります。
MySQL は以下のカテゴリのデータ型をサポートします。
数値: INT、DECIMAL、FLOAT、DOUBLE など
文字列: CHAR、VARCHAR、TEXT、BLOB
日付/時刻: DATE、DATETIME、TIMESTAMP、TIME
JSON: JSON オブジェクトの保存用
INT は小数点を持たない整数を保存します。端数が不要な場合に使います。対して DECIMAL は金額など、小数点を含む厳密な計算に適しています。
DATE は年・月・日の形式で日付を保存します。
YYYY-MM-DD
一方、DATETIME は日付に時刻を加えて、次のように保存します。
YYYY-MM-DD HH:MM:SS
外部キーは、あるテーブルのフィールドが別のテーブルの主キーと関連付けられているものです。
たとえば、顧客情報を保存する customers テーブルでは、各顧客に一意の customer_id があります。購入履歴を保存する transactions テーブルでは、この customer_id を外部キーとして使用します。transactions テーブルの customer_id は、各購入を customers テーブル内の特定の顧客に関連付けます。
SQL では次のようになります。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);結合は、関連する列に基づいて複数のテーブルの行を結合します。違いは次のとおりです。
INNER JOIN: 両方のテーブルで一致がある行のみを返します。
LEFT JOIN: 左側のテーブルの全行と、右側で一致する行を返します。一致しない場合、右側の列は NULL になります。
RIGHT JOIN: LEFT JOIN と同様ですが、右側のテーブルを基準にします。
FULL JOIN: LEFT JOIN と RIGHT JOIN の結果を合わせ、両テーブルの不一致行も含めます。注意: MySQL は FULL JOIN 構文をネイティブにサポートしていません。同等の結果を得るには、LEFT JOIN と RIGHT JOIN の UNION を使用します。
DELETE、TRUNCATE、DROP は似て聞こえますが、挙動は異なります。
DELETE: 条件に基づいてテーブルから行を削除します。トランザクション内であればロールバック可能です。例:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: テーブルの全行を削除しますが、テーブル構造は残ります。DELETE より高速で、ロールバックできません。例:
TRUNCATE TABLE employees;DROP: テーブル構造とデータを完全に削除し、インデックスなどの依存関係も含めて取り除きます。例:
DROP TABLE employees;作成には CREATE TABLE、変更には通常 ALTER TABLE を使います。例:
テーブル作成:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));列の追加:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);一時テーブルは、現在のデータベースセッションの間だけ存在するテーブルです。セッションを閉じると削除されます。中間結果の一時保存に利用でき、テストやフィルタリング、恒久テーブルに挿入する前の準備に役立ちます。
例:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;サブクエリ(入れ子クエリ)は、別のクエリの内側に含まれるクエリです。複雑な処理を段階に分けて扱いやすくします。たとえば、平均給与より高い従業員を見つけるサブクエリは次のとおりです。
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);仕組みはこうです。
内側のクエリ SELECT AVG(salary) FROM employees が先に平均給与を計算します。
外側のクエリがその平均を用いて、それより高い給与の従業員を抽出します。
テーブルにデータを追加するには INSERT 文を使います。基本構文は次のとおりです。
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); INSERT のベストプラクティス:
列名は明示的に列挙する。コードが明確になり、後でテーブル構造が変わってもエラーを防げます。
AUTO_INCREMENT の ID などは INSERT から省略する。重複 ID を避けるため MySQL が自動処理します。
文字列のクォートは一貫させる。シングルクォートを好む人が多いですが、どちらでも構いません。
複数行を挿入する場合は、1 文でまとめるとパフォーマンスが向上します。
AUTO_INCREMENT は、通常は主キー用の列に対して、一意で連番の値を自動生成します。
AUTO_INCREMENT 列を持つテーブルの作成例:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);行の挿入例:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');ビューは、保存されたクエリで、仮想テーブルのように機能します。複雑なクエリに名前を付けて保存し、以後テーブルのように利用できます。毎回クエリ全文を打ち直す必要がありません。
たとえば、従業員情報と部署名を簡単に照会するために、次のようにビューを作成できます。
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;作成した employee_details ビューはテーブルのように問い合わせできます。
SELECT * FROM employee_details;ただし、ビュー経由での挿入や更新はできない場合があります。多くは読み取り専用を想定し、ユーザーの直接アクセスを制限することでデータのセキュリティを高めます。ビューはアクセスのたびに基になるクエリを実行するため、クエリが遅くなることもあります。
これらのコースで SQL をもっと学びましょう!
Courses
Courses
Courses